Il modo più veloce per calcolare una mediana utilizza SQL Server 2012 OFFSET estensione al ORDER BY clausola. Eseguendo un secondo vicino, la soluzione successiva più veloce utilizza un cursore dinamico (possibilmente annidato) che funziona su tutte le versioni. Questo articolo esamina un comune ROW_NUMBER precedente al 2012 soluzione al problema del calcolo della mediana per vedere perché funziona meno bene e cosa si può fare per farlo andare più veloce.
Test della mediana singola
I dati di esempio per questo test sono costituiti da una singola tabella di dieci milioni di righe (riprodotta dall'articolo originale di Aaron Bertrand):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); La soluzione OFFSET
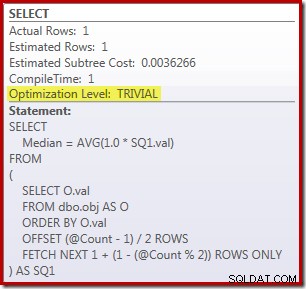
Per impostare il benchmark, ecco la soluzione OFFSET di SQL Server 2012 (o successiva) creata da Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); La query per contare le righe nella tabella viene commentata e sostituita con un valore hardcoded in modo da concentrarsi sulle prestazioni del codice principale. Con una cache calda e la raccolta del piano di esecuzione disattivate, questa query viene eseguita per 910 ms in media sulla mia macchina di prova. Il piano di esecuzione è mostrato di seguito:

Come nota a margine, è interessante notare che questa query moderatamente complessa si qualifica per un piano banale:
La soluzione ROW_NUMBER
Per i sistemi che eseguono SQL Server 2008 R2 o versioni precedenti, le soluzioni alternative con le migliori prestazioni utilizzano un cursore dinamico come menzionato in precedenza. Se non sei in grado (o non vuoi) di considerarla un'opzione, viene naturale pensare di emulare l'OFFSET 2012 piano di esecuzione utilizzando ROW_NUMBER .
L'idea di base è numerare le righe nell'ordine appropriato, quindi filtrare solo per una o due righe necessarie per calcolare la mediana. Esistono diversi modi per scriverlo in Transact SQL; una versione compatta che cattura tutti gli elementi chiave è la seguente:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
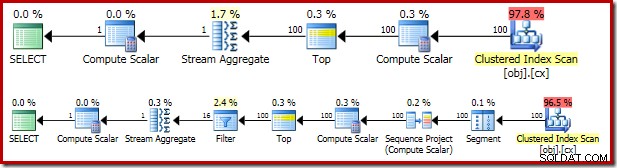
Il piano di esecuzione risultante è abbastanza simile a OFFSET versione:

Vale la pena esaminare a turno ciascuno degli operatori del piano per comprenderli appieno:
- L'operatore del segmento è ridondante in questo piano. Sarebbe richiesto se il
ROW_NUMBERla funzione di classificazione aveva unPARTITION BYclausola, ma non è così. Anche così, rimane nel piano finale. - Il progetto Sequence aggiunge un numero di riga calcolato al flusso di righe.
- Compute Scalar definisce un'espressione associata alla necessità di convertire implicitamente il
valcolonna in numerico in modo che possa essere moltiplicato per la costante letterale1.0nella domanda. Questo calcolo viene differito fino a quando non sarà necessario da un operatore successivo (che risulta essere lo Stream Aggregate). Questa ottimizzazione di runtime significa che la conversione implicita viene eseguita solo per le due righe elaborate da Stream Aggregate, non per le 5.000.001 di righe indicate per Compute Scalar. - L'operatore Top viene introdotto da Query Optimizer. Riconosce che al massimo, solo il primo
(@Count + 2) / 2le righe sono necessarie per la query. Avremmo potuto aggiungere unTOP ... ORDER BYnella sottoquery per renderlo esplicito, ma questa ottimizzazione lo rende in gran parte superfluo. - Il filtro implementa la condizione nel
WHEREclausola, filtrando tutte tranne le due righe "centrali" necessarie per calcolare la mediana (anche la Top introdotta si basa su questa condizione). - Lo Stream Aggregate calcola la
SUMeCOUNTdelle due file mediane. - Il calcolo scalare finale calcola la media dalla somma e dal conteggio.
Prestazioni grezze
Rispetto a OFFSET piano, potremmo aspettarci che gli operatori aggiuntivi Segmento, Progetto Sequenza e Filtro avranno qualche effetto negativo sulle prestazioni. Vale la pena prendersi un momento per confrontare la stima costi dei due piani:
Il OFFSET piano ha un costo stimato di 0,0036266 unità, mentre il ROW_NUMBER il piano è stimato a 0,0036744 unità. Questi sono numeri molto piccoli e c'è poca differenza tra i due.
Quindi, forse è sorprendente che il ROW_NUMBER la query viene effettivamente eseguita per 4000 ms in media, rispetto a 910 ms media per il OFFSET soluzione. Parte di questo aumento può sicuramente essere spiegato dalle spese generali degli operatori del piano extra, ma un fattore quattro sembra eccessivo. Ci deve essere di più.
Probabilmente avrai anche notato che le stime di cardinalità per entrambi i piani stimati sopra sono irrimediabilmente sbagliate. Ciò è dovuto all'effetto degli operatori Top, che hanno un'espressione che fa riferimento a una variabile come limiti di conteggio delle righe. Query Optimizer non è in grado di visualizzare il contenuto delle variabili in fase di compilazione, quindi ricorre all'ipotesi predefinita di 100 righe. Entrambi i piani incontrano effettivamente 5.000.001 di righe in fase di esecuzione.
Tutto ciò è molto interessante, ma non spiega direttamente perché il ROW_NUMBER la query è più di quattro volte più lenta di OFFSET versione. Dopotutto, la stima della cardinalità di 100 righe è altrettanto errata in entrambi i casi.
Miglioramento delle prestazioni della soluzione ROW_NUMBER
Nel mio precedente articolo, abbiamo visto come la performance della mediana raggruppata OFFSET test potrebbe essere quasi raddoppiato semplicemente aggiungendo un PAGLOCK suggerimento. Questo suggerimento annulla la normale decisione del motore di archiviazione di acquisire e rilasciare i blocchi condivisi con la granularità della riga (a causa della bassa cardinalità prevista).
Come ulteriore promemoria, il PAGLOCK suggerimento non era necessario nella singola mediana OFFSET test a causa di un'ottimizzazione interna separata che può ignorare i blocchi condivisi a livello di riga, con il risultato che solo un piccolo numero di blocchi condivisi dall'intento viene preso a livello di pagina.
Potremmo aspettarci il ROW_NUMBER unica soluzione mediana per beneficiare della stessa ottimizzazione interna, ma non è così. Monitoraggio dell'attività di blocco durante il ROW_NUMBER viene eseguita la query, vediamo oltre mezzo milione di singoli blocchi condivisi a livello di riga preso e rilasciato.
Quindi, ora sappiamo qual è il problema, possiamo migliorare le prestazioni di blocco nello stesso modo in cui abbiamo fatto in precedenza:o con un PAGLOCK lock granularity hint o aumentando la stima della cardinalità utilizzando il flag di traccia documentato 4138.
Disabilitare il "riga obiettivo" utilizzando il flag di traccia è la soluzione meno soddisfacente per diversi motivi. Innanzitutto, è efficace solo in SQL Server 2008 R2 o versioni successive. Molto probabilmente preferiremmo OFFSET soluzione in SQL Server 2012, quindi questo limita efficacemente la correzione del flag di traccia solo a SQL Server 2008 R2. In secondo luogo, l'applicazione del flag di traccia richiede autorizzazioni a livello di amministratore, a meno che non vengano applicate tramite una guida del piano. Un terzo motivo è che la disabilitazione degli obiettivi di riga per l'intera query può avere altri effetti indesiderati, soprattutto in piani più complessi.
Al contrario, il PAGLOCK hint è efficace, disponibile in tutte le versioni di SQL Server senza autorizzazioni speciali e non ha effetti collaterali importanti oltre al blocco della granularità.
Applicazione del PAGLOCK suggerimento al ROW_NUMBER query aumenta notevolmente le prestazioni:da 4000 ms a 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
I 1500 ms il risultato è ancora significativamente più lento di 910 ms per il OFFSET soluzione, ma almeno ora è nello stesso campo di gioco. Il restante differenziale di prestazioni è semplicemente dovuto al lavoro extra nel piano di esecuzione:

Nel OFFSET piano, cinque milioni di righe vengono elaborate fino al Top (con le espressioni definite al Compute Scalar differite come discusso in precedenza). Nel ROW_NUMBER piano, lo stesso numero di righe deve essere elaborato da Segmento, Progetto sequenza, Inizio e Filtro.