Introduzione agli indici di SQL Server
Microsoft SQL Server è considerato uno dei sistemi di gestione di database relazionali (RDBMS ), in cui i dati sono organizzati logicamente in righe e colonne che vengono archiviate in contenitori di dati chiamati tabelle. Fisicamente, le tabelle sono archiviate come pagine da 8 KB che possono essere organizzati in tabelle Heap o B-Tree Clustered. Nell'Heap tabella, non esiste un ordinamento che controlli l'ordine dei dati all'interno delle pagine di dati e la sequenza di pagine all'interno di quella tabella, poiché non esiste un indice cluster definito su quella tabella per imporre il meccanismo di ordinamento. Se un indice cluster è definito su una colonna del gruppo di colonne della tabella, i dati verranno ordinati all'interno delle pagine di dati in base ai valori delle colonne della chiave dell'indice cluster e le pagine verranno collegate tra loro in base a questi valori della chiave dell'indice. Questa tabella ordinata è chiamata tabella in cluster .
In SQL Server, l'indice è considerato una chiave importante ed efficace nel processo di ottimizzazione delle prestazioni. Lo scopo della creazione di un indice è velocizzare l'accesso alla tabella di base e recuperare i dati richiesti senza dover scansionare tutte le righe della tabella per restituire i dati richiesti. Puoi pensare all'indice del database come a un indice di un libro che ti aiuta a trovare rapidamente le parole nel libro, senza dover leggere l'intero libro per trovare quella parola. Si supponga, ad esempio, di dover recuperare informazioni su un cliente specifico utilizzando un ID cliente. Se in questa tabella non è definito alcun indice per la colonna ID cliente, il motore di SQL Server verifica tutte le righe della tabella, una per una, per recuperare il cliente con l'ID fornito. Se viene definito un indice per la colonna ID cliente in questa tabella, il motore di SQL Server cercherà i valori di ID cliente richiesti nell'indice ordinato, anziché nella tabella di base, per recuperare le informazioni sul cliente, riducendo il numero di scansioni righe per recuperare i dati.
In SQL Server, l'indice è strutturato logicamente come pagine di 8.000, o nodi di indice, sotto forma di un albero B. La struttura B-Tree contiene tre livelli:un Livello radice che include una pagina indice nella parte superiore dell'albero B, un Livello foglia che si trova nella parte inferiore dell'albero B e contiene pagine di dati e un Livello Intermedio che include tutti i nodi che si trovano tra il livello radice e foglia, con valori di chiave di indice e puntatori alle pagine successive. Questa forma ad albero B fornisce un modo rapido per navigare nelle pagine di dati da sinistra a destra e dall'alto verso il basso, in base alla chiave dell'indice.
In SQL Server esistono due tipi principali di indici, un indice cluster in cui i dati effettivi vengono archiviati nelle pagine a livello di foglia dell'indice, con la possibilità di creare un solo indice cluster per ogni tabella, poiché i dati all'interno delle pagine dati e l'ordine delle pagine verranno ordinati in base all'indice cluster chiave. Se si definisce un vincolo di chiave primaria nella tabella, verrà creato automaticamente un indice cluster se non è stato precedentemente definito alcun indice cluster per quella tabella. Il secondo tipo di indici è un indice non cluster che include una copia ordinata delle colonne della chiave dell'indice e un puntatore al resto delle colonne nella tabella di base o nell'indice cluster, con la possibilità di creare fino a 999 indici non cluster per ciascuna tabella.
SQL Server ci fornisce altri tipi speciali di indici, come un indice unico che viene creato automaticamente quando viene definito un vincolo univoco per imporre l'unicità di valori di colonna specifici, un Indice composito in cui più di una colonna chiave parteciperà alla chiave dell'indice, un indice di copertura in cui tutte le colonne richieste da una specifica query parteciperanno alla chiave di indice, un indice filtrato ovvero un indice ottimizzato non cluster con un predicato di filtro per l'indicizzazione solo di una piccola parte delle righe della tabella, un indice spaziale che viene creato sulle colonne che memorizzano i dati spaziali, un indice XML che viene creato su BLOB (Binary Large Object) XML nelle colonne del tipo di dati XML, un indice Columnstore in cui i dati sono organizzati in formato dati a colonne, un indice full-text creato da SQL Server Full-Text Engine e un indice hash utilizzato nelle tabelle con ottimizzazione per la memoria.
Come chiamavo l'indice di SQL Server, questa è un'arma a doppio taglio , in cui Query Optimizer di SQL Server può trarre vantaggio dall'indice progettato per migliorare le prestazioni delle applicazioni accelerando il processo di recupero dei dati. Al contrario, un indice progettato in modo errato non verrà scelto da Query Optimizer di SQL Server e degraderà le prestazioni delle tue applicazioni rallentando le operazioni di modifica dei dati e consumerà spazio di archiviazione senza trarne vantaggio nei dati processi di recupero. Pertanto, è meglio seguire prima le best practice e le linee guida per la creazione dell'indice, verificare l'effetto della creazione di un sull'ambiente di sviluppo e trovare un compromesso tra la velocità delle operazioni di recupero dei dati e il sovraccarico dell'aggiunta di tale indice sulle operazioni di modifica dei dati e i requisiti di spazio di tale indice, prima di applicarlo all'ambiente di produzione.
Prima di creare un indice, è necessario studiare i diversi aspetti che influenzano la creazione e l'utilizzo dell'indice. Ciò include il tipo del carico di lavoro del database, Online Transaction Processing (OLTP) o Online Analytical Processing (OLAP), la dimensione della tabella , le caratteristiche delle colonne della tabella , l'ordinamento delle colonne della query, il tipo di indice che corrisponde alla query e alle proprietà di archiviazione come FILLFACTOR e PAD_INDEX opzioni che controllano la percentuale di spazio su ogni livello foglia e le pagine di livello intermedio da riempire con i dati.
Frammentazione dell'indice di SQL Server
Il tuo lavoro come DBA non si limita alla creazione dell'indice giusto. Una volta creato l'indice, è necessario monitorare l'utilizzo dell'indice e le statistiche, ad esempio, è necessario sapere se questo indice viene utilizzato male o non viene utilizzato affatto. Pertanto, puoi fornire la soluzione corretta per mantenere questi indici o sostituirli con altri più efficienti. In questo modo, manterrai le massime prestazioni applicabili al tuo sistema. Potresti chiederti:perché Query Optimizer di SQL Server non utilizza più il mio indice, anche se lo faceva prima?
La risposta è principalmente correlata alle continue modifiche ai dati e allo schema eseguite sulla tabella di base che dovrebbero riflettersi negli indici. Nel corso del tempo e con tutte queste modifiche, le pagine dell'indice diventano non ordinate, causando la frammentazione dell'indice. Un altro motivo per la frammentazione è un tentativo di inserire un nuovo valore o aggiornare il valore corrente e il nuovo valore non rientra nello spazio libero attualmente disponibile. In questo caso, la pagina verrà divisa in due pagine, dove la nuova pagina verrà creata fisicamente dopo l'ultima pagina. E puoi immaginare di leggere da un indice frammentato e il numero di pagine da scansionare e, naturalmente, il numero di operazioni di I/O eseguite per recuperare diversi record a causa della distanza tra queste pagine. E a causa di questo costo aggiuntivo per l'utilizzo di questo indice frammentato, Query Optimizer di SQL Server ignorerà questo indice.
Diversi modi per ottenere la frammentazione dell'indice
SQL Server ci offre diversi modi per ottenere la percentuale di frammentazione dell'indice. Il primo modo è controllare la percentuale di frammentazione dell'indice nell'Indice Proprietà finestra, sotto la Frammentazione scheda, come mostrato di seguito:
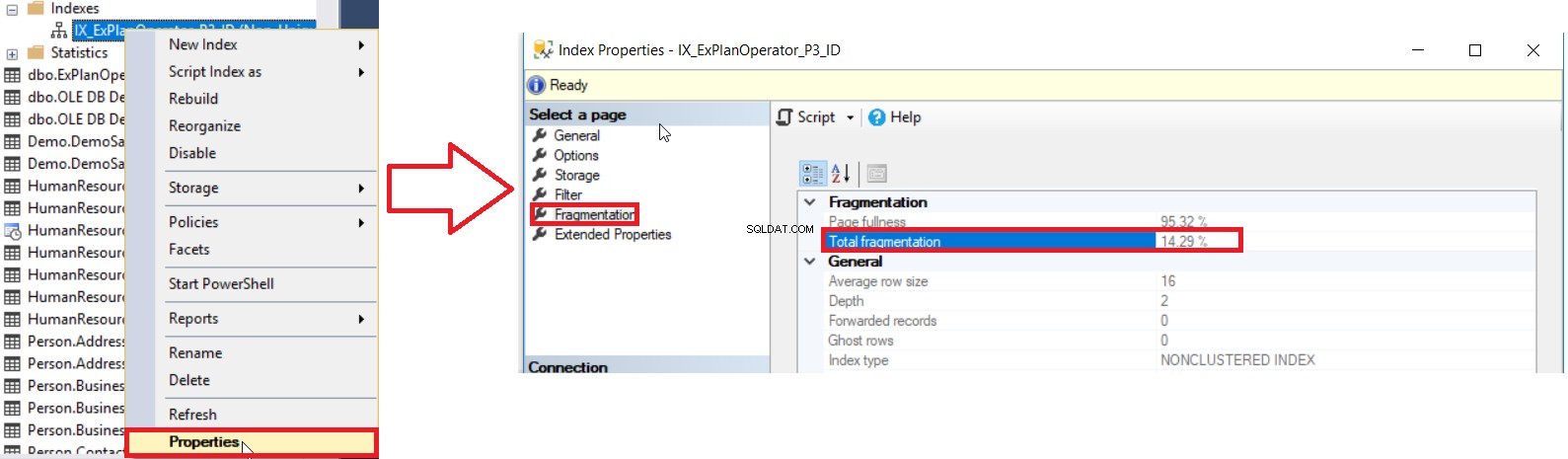
Ma per controllare il livello di frammentazione di più indici, devi prima eseguire il controllo del metodo dell'interfaccia utente per tutti gli indici, uno per uno, che è un'operazione che fa perdere tempo. Il secondo metodo disponibile per verificare il livello di frammentazione di tutti gli indici del database è interrogare il DMF sys.dm_db_index_physical_stats e unirlo al DMV sys.indexes per recuperare tutte le informazioni su questi indici, tenendo in considerazione che queste statistiche verranno aggiornate quando il Il servizio SQL Server viene riavviato utilizzando una query simile alla seguente:
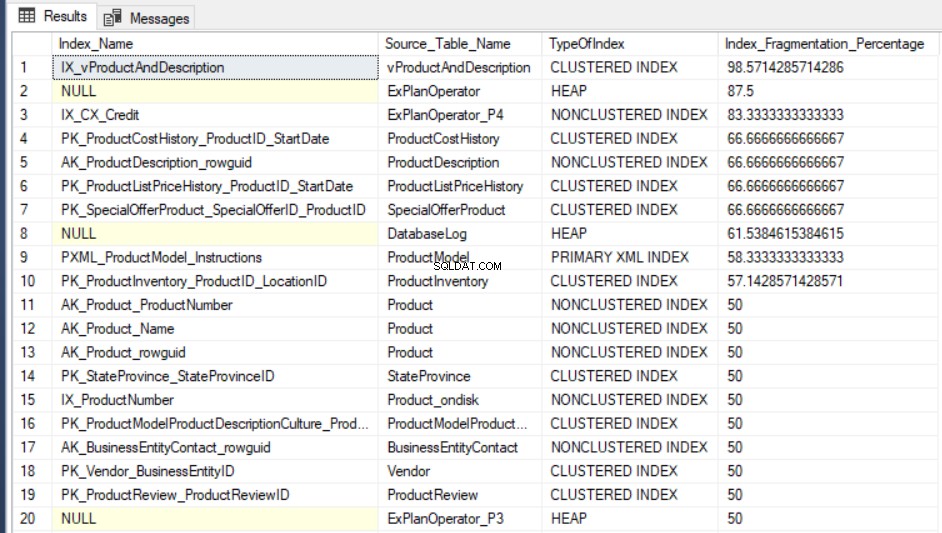
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Il risultato di output della query su AdventureWorks2016CTP3 il database di test sarà simile al seguente:
Il terzo metodo per ottenere la percentuale di frammentazione consiste nell'usare il report standard integrato di SQL Server denominato Index Physical Statistics. Questo report restituisce informazioni utili sulle partizioni dell'indice, la percentuale di frammentazione, il numero di pagine su ciascuna partizione dell'indice e consigli su come risolvere il problema della frammentazione dell'indice ricostruendo o riorganizzando l'indice. Per visualizzare il rapporto, fai clic con il pulsante destro del mouse sul database, seleziona l'opzione Rapporti, Rapporti standard e seleziona Statistiche fisiche dell'indice come di seguito:
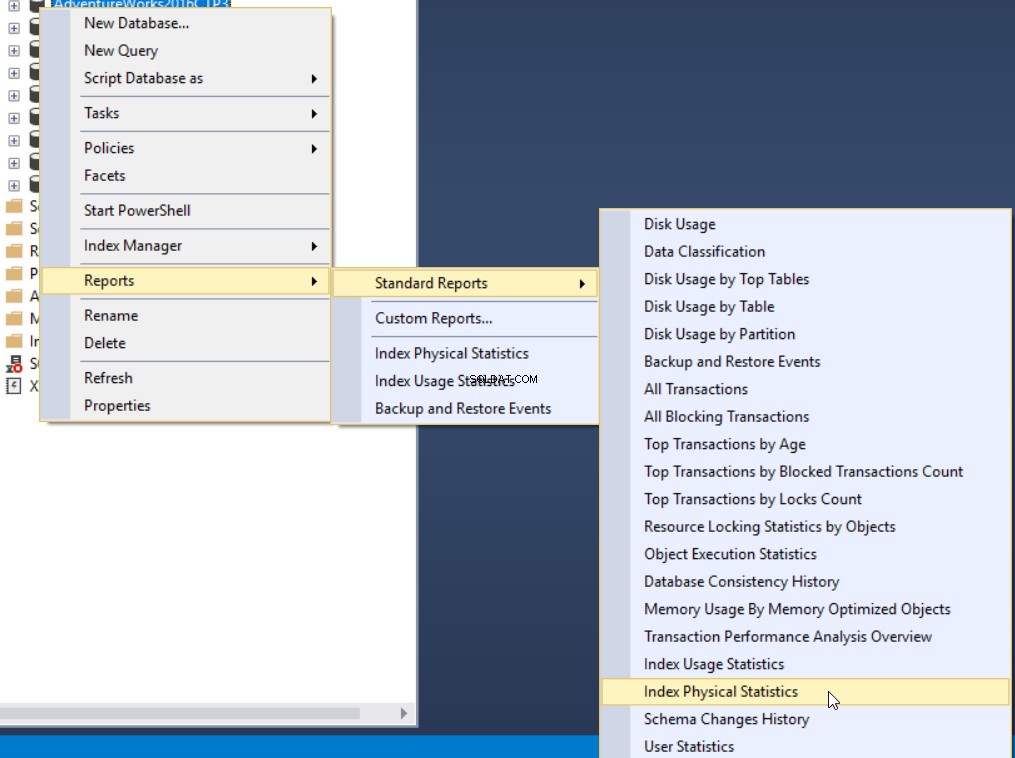
Nel nostro caso, il rapporto generato sarà simile al seguente:
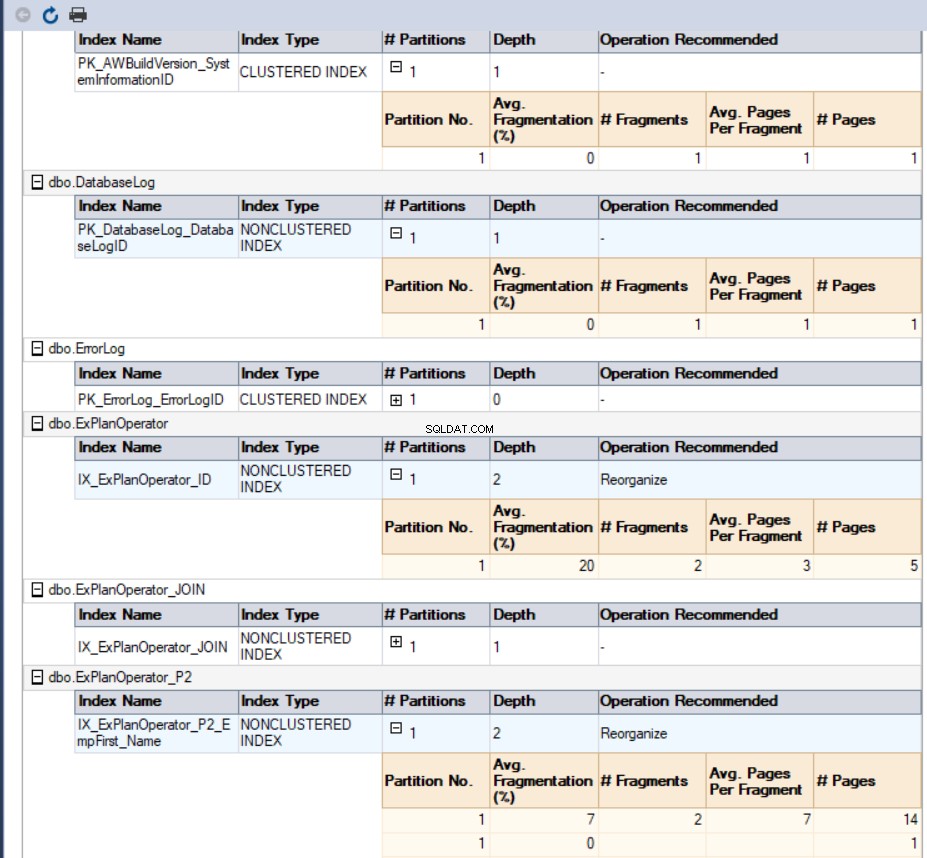
L'ultimo e il modo più semplice per recuperare la percentuale di frammentazione di tutti gli indici di database è lo strumento dbForge Index Manager. Il gestore dell'indice dbForge strumento è un componente aggiuntivo che può essere aggiunto a SQL Server Management Studio per analizzare gli indici dei database di SQL Server, fornendo un report molto utile con lo stato degli indici del database selezionati e suggerimenti di manutenzione per risolvere questi problemi di frammentazione degli indici.
Dopo aver installato il componente aggiuntivo dbForge Index Manager sul tuo SSMS, puoi eseguirlo facendo clic con il pulsante destro del mouse sul database da scansionare, selezionando Gestione indice , quindi Gestisci frammentazione dell'indice come mostrato di seguito:
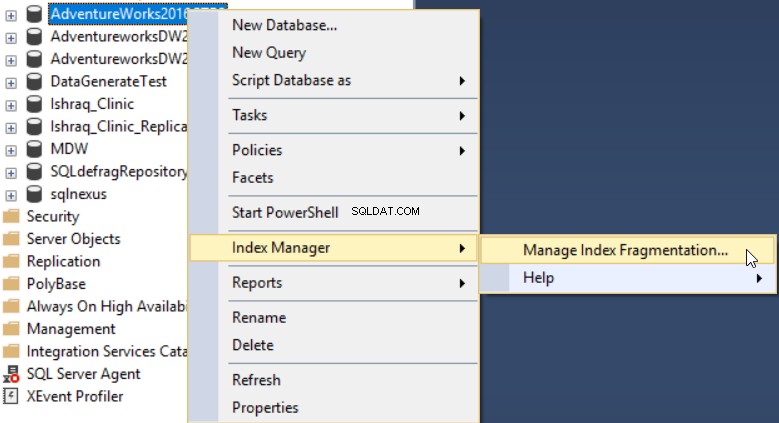
Lo strumento dbForge Index Manager ti consente di avere un quadro generale della frammentazione degli indici del database selezionati, con consigli per le azioni appropriate per risolvere questo problema, come mostrato di seguito:

Lo strumento dbForge Index Manager ti consente anche di passare da un database all'altro, fornendoti un nuovo rapporto dopo aver scansionato questo database come mostrato di seguito:
Il rapporto sulla frammentazione dell'indice generato dallo strumento dbForge Index Manager può essere esportato in un file CSV per analizzare lo stato di frammentazione degli indici, come mostrato di seguito:
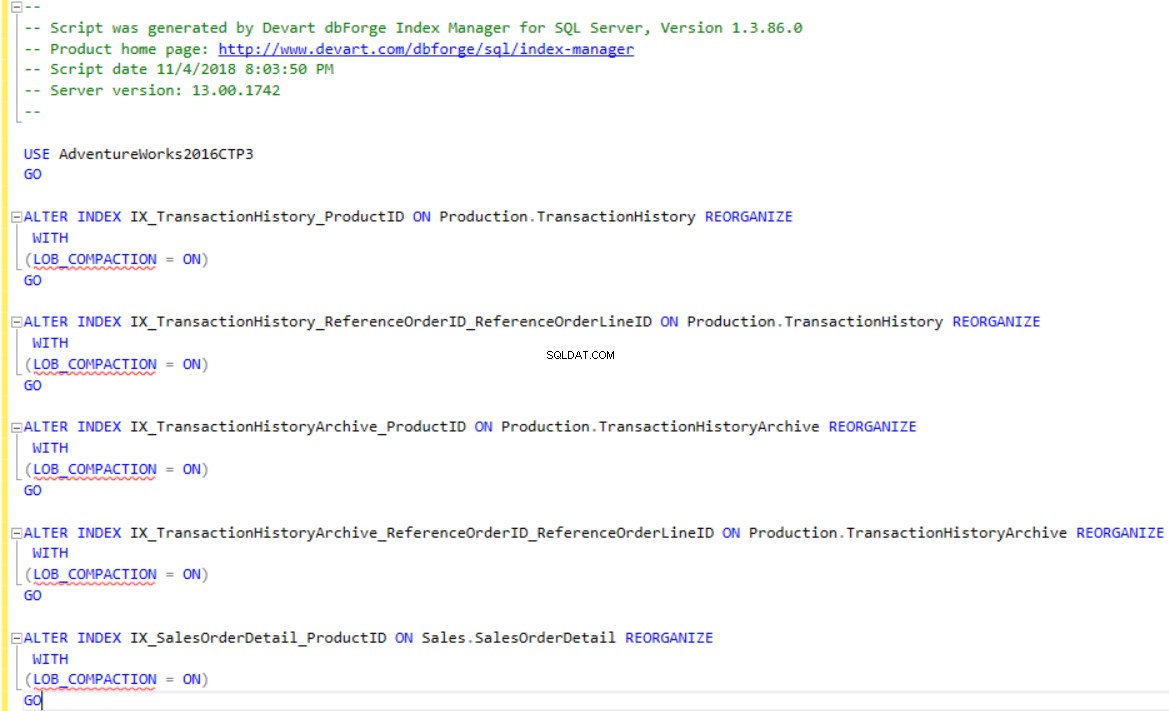
dbForge Index Manager consente di generare script T-SQL per ricostruire o riorganizzare gli indici secondo la raccomandazione dello strumento. Usa le Modifiche allo script opzione per mostrare o salvare lo script per gli indici frammentati, come mostrato di seguito:
Lo strumento dbForge Index Manager ti offre la possibilità di risolvere il problema di frammentazione dell'indice direttamente facendo clic su Correggi pulsante che eseguirà l'azione consigliata direttamente sugli indici selezionati, mostrando lo stato del fix sul Risultato colonna come mostrato di seguito:

Se fai clic su Rianalizza , eseguirà nuovamente la scansione della frammentazione dell'indice sul database dopo aver eseguito correttamente l'operazione di correzione. Ciò che è elencato qui in questo articolo è solo un'introduzione a come lo strumento dbForge Index Manager ci aiuterà a identificare e risolvere i problemi di frammentazione dell'indice. Il mio consiglio per te è di scaricarlo e controllare cosa può offrirti questo strumento.
Link utili:
- Nozioni di base sull'indice
- Tipi di indici
- Descritti indici cluster e non cluster
- Strutture di indici a grappolo
Strumento utile:
dbForge Index Manager – pratico componente aggiuntivo SSMS per analizzare lo stato degli indici SQL e risolvere i problemi con la frammentazione degli indici.