Potresti pensare che la manutenzione del database non sia affar tuo. Ma se progetti i tuoi modelli in modo proattivo, ottieni database che semplificano la vita a coloro che devono mantenerli.
Una buona progettazione di database richiede proattività, una qualità apprezzata in qualsiasi ambiente di lavoro. Nel caso in cui non si abbia familiarità con il termine, la proattività è la capacità di anticipare i problemi e avere soluzioni pronte quando si verificano i problemi o, meglio ancora, pianificare e agire in modo che i problemi non si verifichino in primo luogo.
I datori di lavoro comprendono che la proattività dei propri dipendenti o appaltatori equivale a un risparmio sui costi. Ecco perché lo apprezzano e perché incoraggiano le persone a praticarlo.
Nel tuo ruolo di modellatore di dati, il modo migliore per dimostrare la proattività è progettare modelli che anticipino ed evitino i problemi che affliggono regolarmente la manutenzione del database. O, almeno, che semplificano sostanzialmente la soluzione a quei problemi.
Anche se non sei responsabile della manutenzione del database, la modellazione per una facile manutenzione del database raccoglie molti vantaggi. Ad esempio, ti impedisce di essere chiamato in qualsiasi momento per risolvere emergenze di dati che portano via tempo prezioso che potresti dedicare alle attività di progettazione o modellazione che ti piacciono così tanto!
Semplificare la vita ai ragazzi IT
Quando progettiamo i nostri database, dobbiamo pensare oltre la consegna di un DER e la generazione di script di aggiornamento. Una volta che un database entra in produzione, i tecnici della manutenzione devono affrontare tutti i tipi di potenziali problemi e parte del nostro compito come modellatori di database è ridurre al minimo le possibilità che si verifichino tali problemi.
Iniziamo osservando cosa significa creare una buona progettazione del database e in che modo tale attività è correlata alle normali attività di manutenzione del database.
Che cos'è la modellazione dei dati?
La modellazione dei dati è il compito di creare una rappresentazione astratta, solitamente grafica, di un repository di informazioni. L'obiettivo della modellazione dei dati è esporre gli attributi e le relazioni tra le entità i cui dati sono archiviati nel repository.
I modelli di dati sono costruiti attorno alle esigenze di un problema aziendale. Regole e requisiti sono definiti in anticipo attraverso il contributo di esperti aziendali in modo che possano essere incorporati nella progettazione di un nuovo repository di dati o adattati nell'iterazione di uno esistente.
Idealmente, i modelli di dati sono documenti viventi che si evolvono con le mutevoli esigenze aziendali. Svolgono un ruolo importante nel supportare le decisioni aziendali e nella pianificazione dell'architettura e della strategia dei sistemi. I modelli di dati devono essere mantenuti sincronizzati con i database che rappresentano in modo che siano utili alle routine di manutenzione di tali database.
Sfide comuni relative alla manutenzione del database
Il mantenimento di un database richiede un monitoraggio costante, automatizzato o meno, per garantire che non perda le sue virtù. Le best practice per la manutenzione dei database garantiscono che i database mantengano sempre:
- Integrità e qualità delle informazioni
- Prestazioni
- Disponibilità
- Scalabilità
- Adattabilità alle modifiche
- Tracciabilità
- Sicurezza
Sono disponibili molti suggerimenti per la modellazione dei dati per aiutarti a creare ogni volta una buona progettazione del database. Quelli discussi di seguito mirano specificamente a garantire o facilitare il mantenimento delle qualità del database sopra menzionate.
Integrità e qualità dell'informazione
Un obiettivo fondamentale delle migliori pratiche di manutenzione del database è garantire che le informazioni nel database mantengano la propria integrità. Questo è fondamentale per gli utenti che mantengono la loro fiducia nelle informazioni.
Esistono due tipi di integrità:integrità fisica e integrità logica .
Integrità fisica
Il mantenimento dell'integrità fisica di un database avviene proteggendo le informazioni da fattori esterni come hardware o interruzioni di corrente. L'approccio più comune e ampiamente accettato è attraverso un'adeguata strategia di backup che consenta il ripristino di un database in un tempo ragionevole se una catastrofe lo distrugge.
Per i DBA e gli amministratori di server che gestiscono l'archiviazione dei database, è utile sapere se i database possono essere partizionati in sezioni con frequenze di aggiornamento diverse. Ciò consente loro di ottimizzare l'utilizzo dello spazio di archiviazione e i piani di backup.
I modelli di dati possono riflettere tale partizionamento identificando aree di diversa "temperatura" dei dati e raggruppando le entità in tali aree. “Temperatura” si riferisce alla frequenza con cui le tabelle ricevono nuove informazioni. Le tabelle che vengono aggiornate molto frequentemente sono le più “calde”; quelli che non vengono mai o raramente aggiornati sono i "più freddi".

Modello di dati di un sistema di e-commerce che differenzia i dati caldi, caldi e freddi.
Un DBA o un amministratore di sistema può utilizzare questo raggruppamento logico per partizionare i file di database e creare piani di backup diversi per ciascuna partizione.
Integrità logica
Il mantenimento dell'integrità logica di un database è essenziale per l'affidabilità e l'utilità delle informazioni che fornisce. Se un database manca di integrità logica, le applicazioni che lo utilizzano rivelano prima o poi incoerenze nei dati. Di fronte a queste incongruenze, gli utenti diffidano delle informazioni e cercano semplicemente fonti di dati più affidabili.
Tra le attività di manutenzione del database, il mantenimento dell'integrità logica delle informazioni è un'estensione dell'attività di modellazione del database, solo che inizia dopo che il database è stato messo in produzione e continua per tutta la sua durata. La parte più critica di quest'area di manutenzione è l'adattamento ai cambiamenti.
Gestione del cambiamento
Le modifiche alle regole o ai requisiti aziendali rappresentano una minaccia costante all'integrità logica dei database. Potresti essere soddisfatto del modello di dati che hai costruito, sapendo che è perfettamente adattato al business, che risponde con le informazioni giuste a qualsiasi domanda e che tralascia qualsiasi anomalia di inserimento, aggiornamento o cancellazione. Goditi questo momento di soddisfazione, perché è di breve durata!
La manutenzione di un database implica affrontare la necessità di apportare modifiche al modello quotidianamente. Ti obbliga ad aggiungere nuovi oggetti o alterare quelli esistenti, modificare la cardinalità delle relazioni, ridefinire le chiavi primarie, cambiare i tipi di dati e fare altre cose che fanno rabbrividire noi modellatori.
I cambiamenti accadono continuamente. È possibile che alcuni requisiti siano stati spiegati in modo errato sin dall'inizio, che siano emersi nuovi requisiti o che tu abbia introdotto involontariamente qualche difetto nel tuo modello (dopotutto, noi modellatori di dati siamo solo esseri umani).
I tuoi modelli devono essere facili da modificare quando si presenta la necessità di modifiche. È fondamentale utilizzare uno strumento di progettazione di database per la modellazione che consenta di creare versioni dei modelli, generare script per migrare un database da una versione all'altra e documentare correttamente ogni decisione di progettazione.
Senza questi strumenti, ogni modifica apportata alla progettazione crea rischi per l'integrità che vengono alla luce nei momenti più inopportuni. Vertabelo ti offre tutte queste funzionalità e si occupa di mantenere la cronologia delle versioni di un modello senza che tu debba nemmeno pensarci.
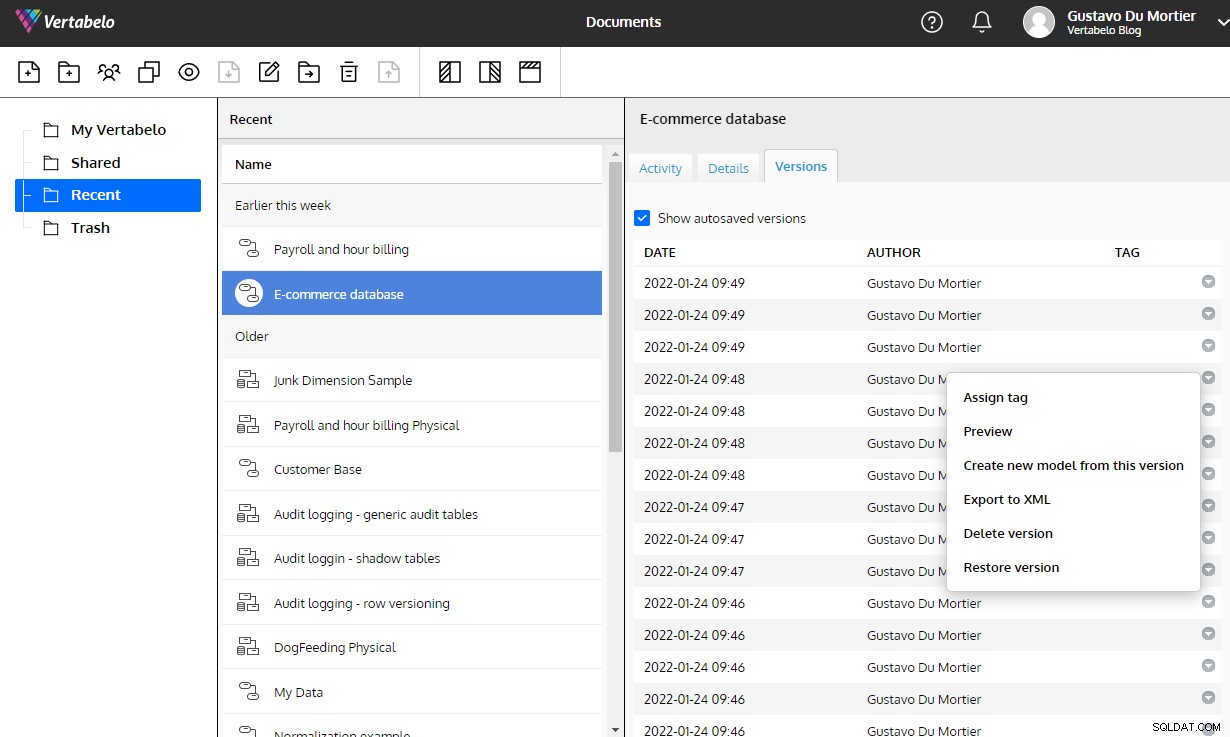
Il controllo delle versioni automatico integrato in Vertabelo è di grande aiuto per mantenere le modifiche a un modello di dati.
Anche la gestione delle modifiche e il controllo delle versioni sono fattori cruciali per l'integrazione delle attività di modellazione dei dati nel ciclo di vita dello sviluppo del software.
Refactoring
Quando applichi modifiche a un database in uso, devi essere sicuro al 100% che nessuna informazione vada persa e che la sua integrità non venga compromessa come conseguenza delle modifiche. Per fare ciò, puoi utilizzare le tecniche di refactoring. Vengono normalmente applicati quando si desidera migliorare un progetto senza intaccarne la semantica, ma possono essere utilizzati anche per correggere errori di progettazione o adattare un modello a nuovi requisiti.
Esistono numerose tecniche di refactoring. Di solito vengono impiegati per dare nuova vita ai database legacy e ci sono procedure da manuale che assicurano che le modifiche non danneggino le informazioni esistenti. Sono stati scritti interi libri su di esso; Ti consiglio di leggerli.
Ma per riassumere, possiamo raggruppare le tecniche di refactoring nelle seguenti categorie:
- Qualità dei dati: Apportare modifiche che garantiscano la coerenza e la coerenza dei dati. Gli esempi includono l'aggiunta di una tabella di ricerca e la migrazione di dati ripetuti in un'altra tabella e l'aggiunta di un vincolo su una colonna.
- Strutturale: Apportare modifiche alle strutture delle tabelle che non alterano la semantica del modello. Gli esempi includono la combinazione di due colonne in una, l'aggiunta di una chiave sostitutiva e la divisione di una colonna in due.
- Integrità referenziale: Applicazione di modifiche per garantire che una riga di riferimento esista all'interno di una tabella correlata o che una riga senza riferimento possa essere eliminata. Gli esempi includono l'aggiunta di un vincolo di chiave esterna su una colonna e l'aggiunta di un vincolo di valore non nullo a una tabella.
- Architettura: Apportare modifiche volte a migliorare l'interazione delle applicazioni con il database. Gli esempi includono la creazione di un indice, la creazione di una tabella di sola lettura e l'incapsulamento di una o più tabelle in una vista.
Le tecniche che modificano la semantica del modello, così come quelle che non alterano in alcun modo il modello dati, non sono considerate tecniche di refactoring. Questi includono l'inserimento di righe in una tabella, l'aggiunta di una nuova colonna, la creazione di una nuova tabella o vista e l'aggiornamento dei dati in una tabella.
Mantenimento della qualità delle informazioni
La qualità delle informazioni in un database è il grado in cui i dati soddisfano le aspettative dell'organizzazione in termini di accuratezza, validità, completezza e coerenza. Mantenere la qualità dei dati durante tutto il ciclo di vita di un database è fondamentale per i suoi utenti per prendere decisioni corrette e informate utilizzando i dati in esso contenuti.
La tua responsabilità come modellatore di dati è garantire che i tuoi modelli mantengano la qualità delle informazioni al più alto livello possibile. Per fare questo:
- Il design deve seguire almeno la 3a forma normale in modo che non si verifichino anomalie di inserimento, aggiornamento o cancellazione. Questa considerazione si applica principalmente ai database per uso transazionale, in cui i dati vengono aggiunti, aggiornati ed eliminati regolarmente. Non si applica rigorosamente nei database per uso analitico (ad es. data warehouse), poiché l'aggiornamento e la cancellazione dei dati vengono eseguiti raramente, se non mai.
- I tipi di dati di ogni campo in ogni tabella devono essere appropriati all'attributo che rappresentano nel modello logico. Questo va oltre la definizione corretta se un campo è di tipo numerico, data o alfanumerico. È anche importante definire correttamente l'intervallo e la precisione dei valori supportati da ciascun campo. Un esempio:un attributo di tipo Data implementato in un database come campo Data/Ora può causare problemi nelle query, poiché un valore memorizzato con la sua parte temporale diversa da zero potrebbe non rientrare nell'ambito di una query che utilizza un intervallo di date.
- Le dimensioni ei fatti che definiscono la struttura di un data warehouse devono essere in linea con le esigenze del business. Quando si progetta un data warehouse, le dimensioni ei fatti del modello devono essere definiti correttamente sin dall'inizio. Apportare modifiche una volta che il database è operativo comporta costi di manutenzione molto elevati.
Gestire la crescita
Un'altra sfida importante nella manutenzione di un database è impedire che la sua crescita raggiunga inaspettatamente il limite di capacità di archiviazione. Per aiutare con la gestione dello spazio di archiviazione, puoi applicare lo stesso principio utilizzato nelle procedure di backup:raggruppa le tabelle nel tuo modello in base alla velocità con cui crescono.
Di solito è sufficiente una divisione in due aree. Posizionare le tabelle con frequenti aggiunte di righe in un'area, quelle in cui le righe vengono raramente inserite in un'altra. Avere il modello segmentato in questo modo consente agli amministratori di archiviazione di partizionare i file di database in base al tasso di crescita di ciascuna area. Possono distribuire le partizioni tra diversi supporti di memorizzazione con diverse capacità o possibilità di crescita.
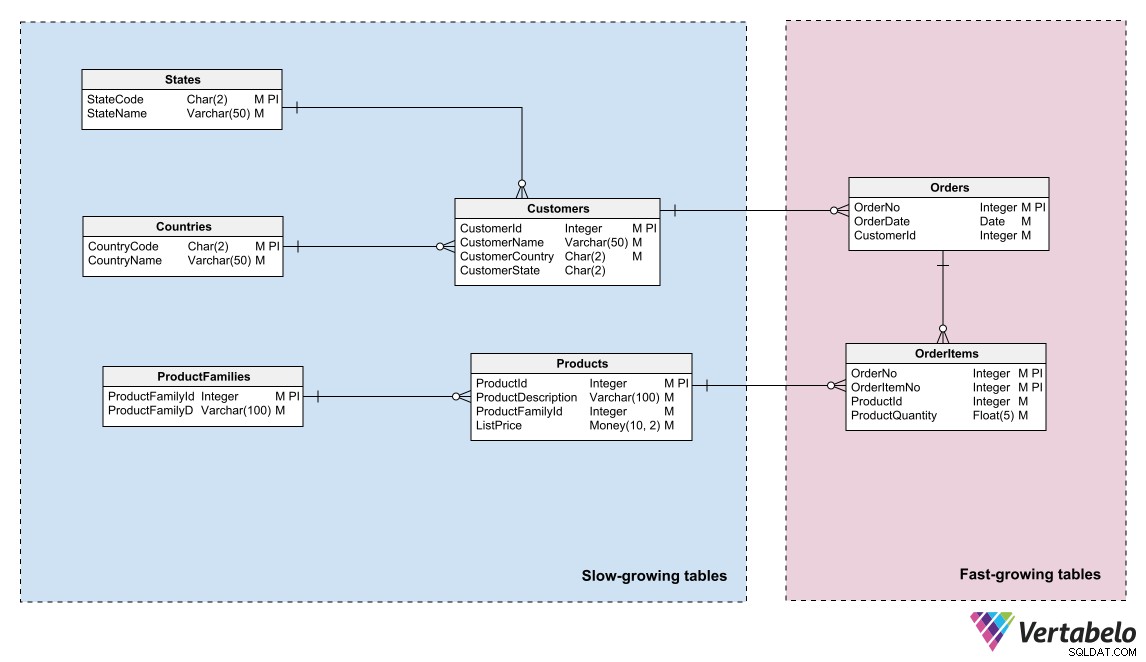
Il raggruppamento di tabelle in base al relativo tasso di crescita aiuta a determinare i requisiti di archiviazione e a gestirne la crescita.
Registrazione
Creiamo un modello di dati in attesa che fornisca le informazioni così come sono al momento della query. Tuttavia, tendiamo a trascurare la necessità di un database per ricordare tutto ciò che è accaduto in passato a meno che gli utenti non lo richiedano specificamente.
Parte della manutenzione di un database è sapere come, quando, perché e da chi è stato alterato un particolare dato. Questo può essere per cose come scoprire quando il prezzo di un prodotto è cambiato o rivedere le modifiche nella cartella clinica di un paziente in ospedale. La registrazione può essere utilizzata anche per correggere errori dell'utente o dell'applicazione poiché consente di ripristinare lo stato delle informazioni a un punto nel passato senza la necessità di ricorrere a complicate procedure di ripristino del backup.
Ancora una volta, anche se gli utenti non ne hanno bisogno in modo esplicito, considerare la necessità di una registrazione proattiva è un mezzo molto prezioso per facilitare la manutenzione del database e dimostrare la tua capacità di anticipare i problemi. Avere i dati di registrazione consente risposte immediate quando qualcuno ha bisogno di rivedere le informazioni storiche.
Esistono diverse strategie per un modello di database per supportare la registrazione, e tutte aggiungono complessità al modello. Un approccio è chiamato registrazione sul posto, che aggiunge colonne a ogni tabella per registrare le informazioni sulla versione. Questa è un'opzione semplice che non implica la creazione di schemi separati o tabelle specifiche per la registrazione. Tuttavia, ha un impatto sulla progettazione del modello perché le chiavi primarie originali delle tabelle non sono più valide come chiavi primarie:i loro valori vengono ripetuti in righe che rappresentano versioni diverse degli stessi dati.
Un'altra opzione per conservare le informazioni di registro consiste nell'utilizzare le tabelle shadow. Le tabelle shadow sono repliche delle tabelle del modello con l'aggiunta di colonne per registrare i dati del log trail. Questa strategia non richiede la modifica delle tabelle nel modello originale, ma è necessario ricordarsi di aggiornare le tabelle shadow corrispondenti quando si modifica il modello di dati.
Un'altra strategia ancora consiste nell'utilizzare un sottoschema di tabelle generiche che registrano ogni inserimento, eliminazione o modifica a qualsiasi altra tabella.
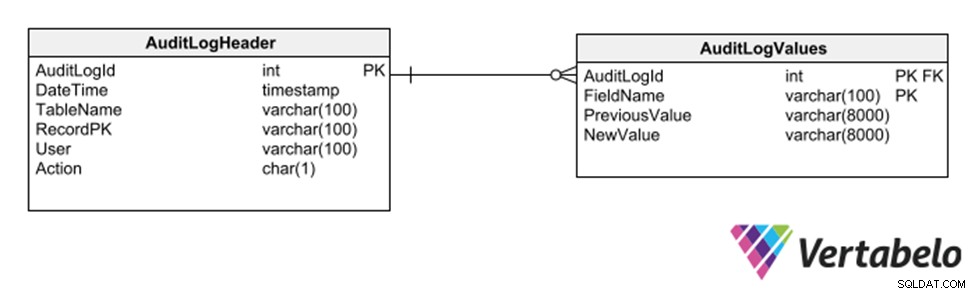
Tabelle generiche per mantenere un audit trail di un database.
Questa strategia ha il vantaggio di non richiedere modifiche al modello per la registrazione di un audit trail. Tuttavia, poiché utilizza colonne generiche del tipo varchar, limita i tipi di dati che possono essere registrati nel log trail.
Manutenzione delle prestazioni e creazione dell'indice
Praticamente qualsiasi database ha buone prestazioni quando è appena iniziato a essere utilizzato e le sue tabelle contengono solo poche righe. Ma non appena le applicazioni iniziano a popolarlo con i dati, le prestazioni potrebbero degradarsi molto rapidamente se non vengono prese precauzioni nella progettazione del modello. Quando ciò accade, i DBA e gli amministratori di sistema ti chiedono di aiutarli a risolvere i problemi di prestazioni.
La creazione/suggerimento automatico degli indici sui database di produzione è uno strumento utile per risolvere i problemi di performance “nella foga del momento”. I motori di database possono analizzare le attività del database per vedere quali operazioni richiedono più tempo e dove ci sono opportunità per accelerare creando indici.
Tuttavia, è molto meglio essere proattivi e anticipare la situazione definendo gli indici come parte del modello di dati. Ciò riduce notevolmente gli sforzi di manutenzione per migliorare le prestazioni del database. Se non hai familiarità con i vantaggi degli indici di database, ti suggerisco di leggere tutto sugli indici, iniziando dalle basi.
Esistono regole pratiche che forniscono indicazioni sufficienti per creare gli indici più importanti per query efficienti. Il primo consiste nel generare indici per la chiave primaria di ogni tabella. Praticamente ogni RDBMS genera automaticamente un indice per ogni chiave primaria, quindi puoi dimenticare questa regola.
Un'altra regola consiste nel generare indici per chiavi alternative di una tabella, in particolare nelle tabelle per le quali viene creata una chiave surrogata. Se una tabella ha una chiave naturale che non viene utilizzata come chiave primaria, le query per unire quella tabella con altre molto probabilmente lo fanno con la chiave naturale, non con il surrogato. Queste query non funzionano bene a meno che tu non crei un indice sulla chiave naturale.
La prossima regola pratica per gli indici è generarli per tutti i campi che sono chiavi esterne. Questi campi sono ottimi candidati per stabilire join con altre tabelle. Se sono inclusi negli indici, vengono utilizzati dai parser di query per velocizzare l'esecuzione e migliorare le prestazioni del database.
Infine, è una buona idea utilizzare uno strumento di profilazione su un database di staging o QA durante i test delle prestazioni per rilevare eventuali opportunità di creazione dell'indice che non sono evidenti. Incorporare gli indici suggeriti dagli strumenti di profilazione nel modello di dati è estremamente utile per raggiungere e mantenere le prestazioni del database una volta che è in produzione.
Sicurezza
Nel tuo ruolo di modellatore di dati, puoi contribuire a mantenere la sicurezza del database fornendo una base solida e sicura in cui archiviare i dati per l'autenticazione dell'utente. Tieni presente che queste informazioni sono altamente sensibili e non devono essere esposte ad attacchi informatici.
Affinché la tua progettazione semplifichi il mantenimento della sicurezza del database, segui le migliori pratiche per la memorizzazione dei dati di autenticazione, la principale tra le quali è non memorizzare le password nel database anche in forma crittografata. La memorizzazione solo dell'hash anziché della password per ciascun utente consente a un'applicazione di autenticare l'accesso di un utente senza creare alcun rischio di esposizione della password.
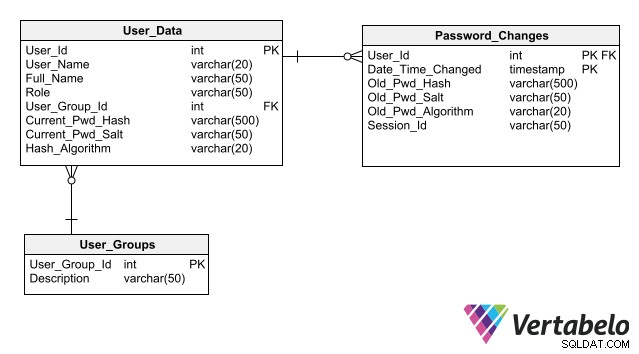
Uno schema completo per l'autenticazione utente che include colonne per la memorizzazione degli hash delle password.
Visione per il futuro
Quindi, crea i tuoi modelli per una facile manutenzione del database con buoni progetti di database tenendo conto dei suggerimenti sopra indicati. Con modelli di dati più gestibili, il tuo lavoro ha un aspetto migliore e ottieni l'apprezzamento di DBA, tecnici della manutenzione e amministratori di sistema.
Investi anche in tranquillità. La creazione di database facilmente gestibili significa che puoi dedicare le tue ore lavorative alla progettazione di nuovi modelli di dati, invece di correre intorno all'applicazione di patch ai database che non forniscono informazioni corrette in tempo.