Questo post ha "stringhe allegate:per una buona ragione. Esploreremo in profondità SQL VARCHAR, il tipo di dati che gestisce le stringhe.
Inoltre, questo è "solo per i tuoi occhi" perché senza vincoli, non ci saranno post di blog, pagine Web, istruzioni di gioco, ricette con segnalibri e molto altro da leggere e divertire per i nostri occhi. Abbiamo a che fare con un miliardo di stringhe ogni giorno. Quindi, come sviluppatori, tu ed io siamo responsabili di rendere questo tipo di dati efficiente da archiviare e da cui accedere.
Con questo in mente, tratteremo ciò che conta di più per l'archiviazione e le prestazioni. Inserisci le cose da fare e da non fare per questo tipo di dati.
Ma prima, VARCHAR è solo uno dei tipi di stringa in SQL. Cosa lo rende diverso?
Cos'è VARCHAR in SQL? (Con esempi)
VARCHAR è un tipo di dati stringa o carattere di dimensioni variabili. Puoi memorizzare lettere, numeri e simboli con esso. A partire da SQL Server 2019, puoi utilizzare l'intera gamma di caratteri Unicode quando utilizzi regole di confronto con supporto UTF-8.
Puoi dichiarare colonne o variabili VARCHAR usando VARCHAR[(n)], dove n sta per la dimensione della stringa in byte. L'intervallo di valori per n va da 1 a 8000. Sono molti dati sui caratteri. Ma ancora di più, puoi dichiararlo usando VARCHAR(MAX) se hai bisogno di una stringa gigantesca fino a 2 GB. È abbastanza grande per la tua lista di segreti e cose private nel tuo diario! Tuttavia, tieni presente che puoi anche dichiararlo senza la dimensione e il valore predefinito è 1 se lo fai.
Facciamo un esempio.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
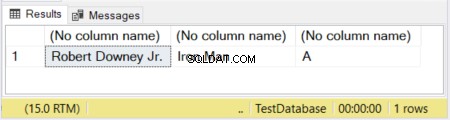
Nella Figura 1, le prime 2 colonne hanno le dimensioni definite. La terza colonna viene lasciata senza una dimensione. Quindi, la parola "Avengers" viene troncata perché un VARCHAR senza una dimensione dichiarata ha per impostazione predefinita 1 carattere.
Ora, proviamo qualcosa di enorme. Ma tieni presente che l'esecuzione di questa query richiederà del tempo:23 secondi sul mio laptop.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
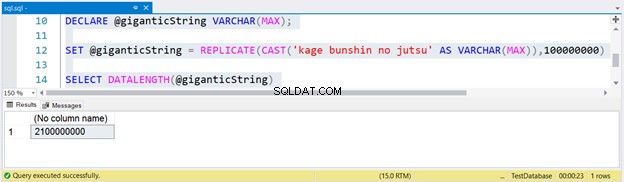
Per generare una stringa enorme, abbiamo replicato kage bunshin no jutsu 100 milioni di volte. Nota il CAST all'interno di REPLICA. Se non esegui CAST dell'espressione stringa su VARCHAR(MAX), il risultato verrà troncato fino a un massimo di 8000 caratteri.
Ma come si confronta SQL VARCHAR con altri tipi di dati stringa?
Differenza tra CHAR e VARCHAR in SQL
Rispetto a VARCHAR, CHAR è un tipo di dati di carattere a lunghezza fissa. Non importa quanto piccolo o grande sia il valore che metti in una variabile CHAR, la dimensione finale è la dimensione della variabile. Controlla i confronti qui sotto.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
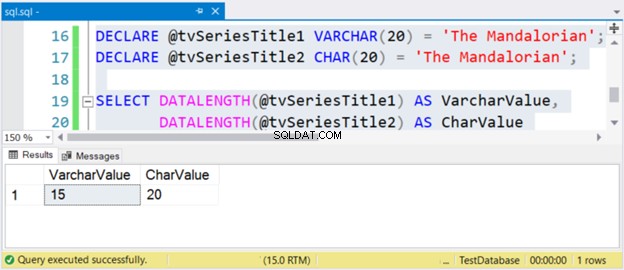
La dimensione della stringa "The Mandalorian" è di 15 caratteri. Quindi, il VarcharValue la colonna lo riflette correttamente. Tuttavia, CharValue mantiene la dimensione di 20 – è imbottito con 5 spazi a destra.
SQL VARCHAR vs NVARCHAR
Quando si confrontano questi tipi di dati vengono in mente due cose fondamentali.
Innanzitutto, è la dimensione in byte. Ogni carattere in NVARCHAR ha una dimensione doppia rispetto a VARCHAR. NVARCHAR(n) è solo da 1 a 4000.
Quindi, i caratteri che può memorizzare. NVARCHAR può memorizzare caratteri multilingue come coreano, giapponese, arabo, ecc. Se prevedi di archiviare testi K-Pop coreani nel tuo database, questo tipo di dati è una delle tue opzioni.
Facciamo un esempio. Useremo il gruppo K-pop 세븐틴 o Seventeen in inglese.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
Il codice precedente genererà il valore della stringa, la sua dimensione in byte e il numero di caratteri. Se si tratta di caratteri non Unicode, il numero di caratteri è uguale alla dimensione in byte. Ma questo non è il caso. Dai un'occhiata alla Figura 4 di seguito.
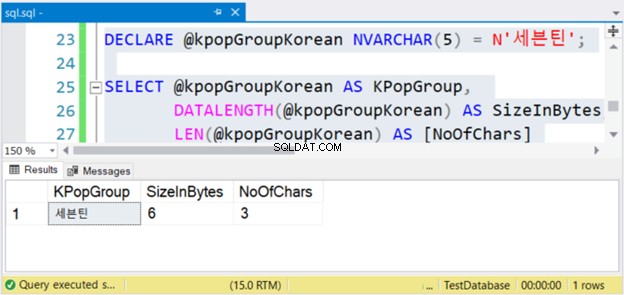
Vedere? Se NVARCHAR ha 3 caratteri, la dimensione in byte è doppia. Ma non con VARCHAR. Lo stesso vale anche se utilizzi caratteri inglesi.
Ma che ne dici di NCHAR? NCHAR è la controparte di CHAR per i caratteri Unicode.
SQL Server VARCHAR con supporto UTF-8
VARCHAR con supporto UTF-8 è possibile a livello di server, database o colonna di tabella modificando le informazioni di confronto. Le regole di confronto da utilizzare dovrebbero supportare UTF-8.
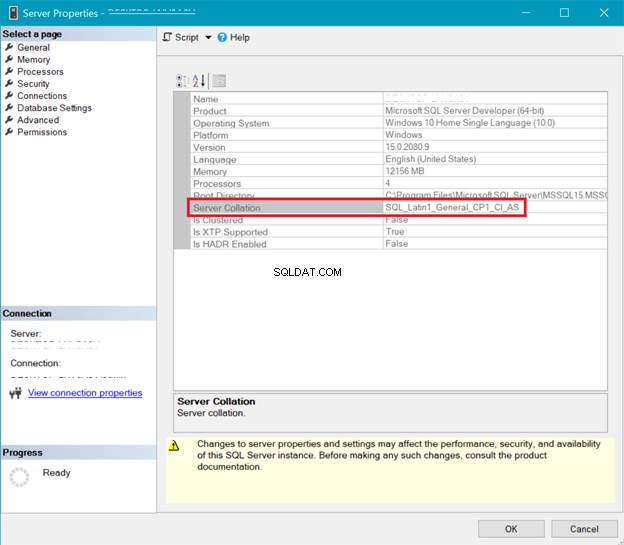
COLLEGAMENTO SQL SERVER
La figura 5 presenta la finestra in SQL Server Management Studio che mostra le regole di confronto del server.
RACCOLTA DATABASE
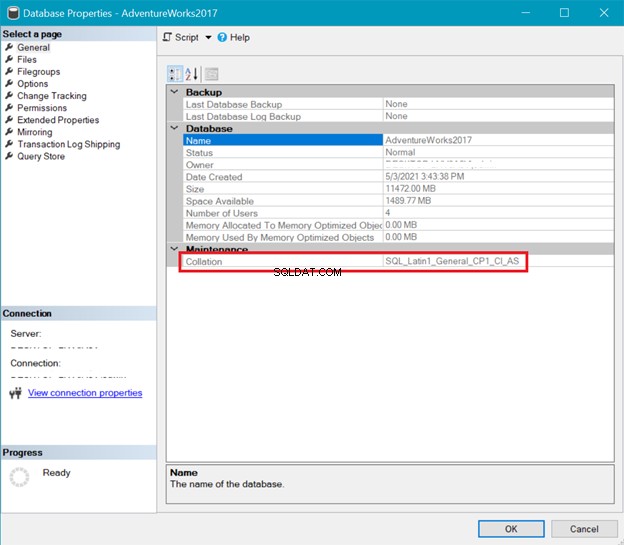
Nel frattempo, la Figura 6 mostra la raccolta di AdventureWorks banca dati.
RACCOLTA COLONNA TABELLA
Sia il server che il database di confronto sopra mostrano che UTF-8 non è supportato. La stringa di confronto dovrebbe contenere un _UTF8 per il supporto UTF-8. Ma puoi comunque utilizzare il supporto UTF-8 a livello di colonna di una tabella. Vedi l'esempio.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
Il codice sopra ha Latin1_General_100_BIN2_UTF8 confronto per il KoreanName colonna. Sebbene VARCHAR e non NVARCHAR, questa colonna accetterà i caratteri della lingua coreana. Inseriamo alcuni record e poi li visualizziamo.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
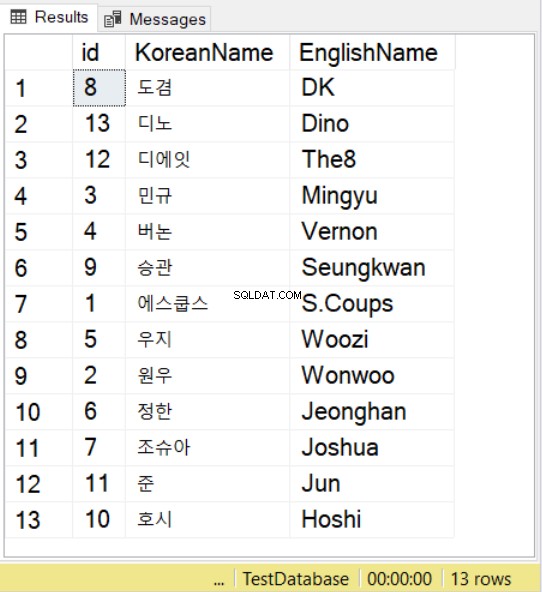
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Stiamo usando nomi del gruppo Seventeen K-pop usando controparti coreane e inglesi. Per i caratteri coreani, nota che devi comunque anteporre al valore N , proprio come fai con i valori NVARCHAR.
Quindi, quando usi SELECT con ORDER BY, puoi anche usare le regole di confronto. Puoi osservarlo nell'esempio sopra. Questo seguirà le regole di ordinamento per le regole di confronto specificate.
STORAGE DI VARCHAR CON SUPPORTO UTF-8
Ma com'è la conservazione di questi personaggi? Se ti aspetti 2 byte per carattere, allora ti aspetta una sorpresa. Dai un'occhiata alla Figura 8.
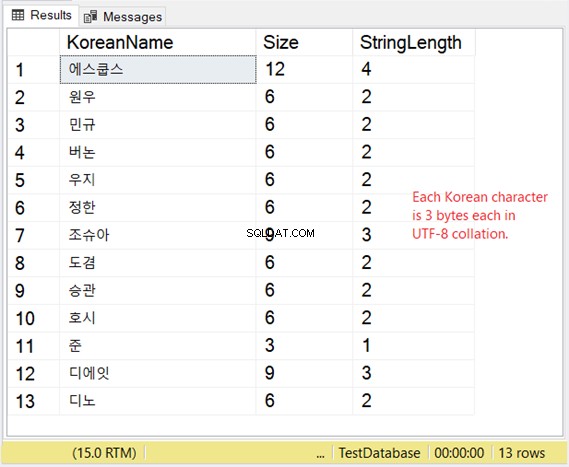
Quindi, se lo spazio di archiviazione è molto importante per te, considera la tabella seguente quando usi VARCHAR con il supporto UTF-8.
| Personaggi | Dimensioni in byte |
| Ascii 0 – 127 | 1 |
| L'alfabeto latino e greco, cirillico, copto, armeno, ebraico, arabo, siriaco, Tāna e N'Ko | 2 |
| Scrittura dell'Asia orientale come cinese, coreano e giapponese | 3 |
| Caratteri nell'intervallo 010000–10FFFF | 4 |
Il nostro esempio coreano è uno script dell'Asia orientale, quindi sono 3 byte per carattere.
Ora che abbiamo finito di descrivere e confrontare VARCHAR con altri tipi di stringhe, esaminiamo ora le cose da fare e da non fare
Cose da fare usando VARCHAR in SQL Server
1. Specifica la taglia
Cosa potrebbe andare storto senza specificare la taglia?
TRONCO STRINGA
Se diventi pigro specificando la dimensione, si verificherà il troncamento della stringa. Ne hai già visto un esempio prima.
IMPATTO SULLA STOCCAGGIO E SULLE PRESTAZIONI
Un'altra considerazione riguarda l'archiviazione e le prestazioni. Devi solo impostare la dimensione giusta per i tuoi dati, non di più. Ma come potresti saperlo? Per evitare il troncamento in futuro, potresti semplicemente impostarlo sulla dimensione più grande. Questo è VARCHAR(8000) o anche VARCHAR(MAX). E 2 byte verranno archiviati così come sono. Stessa cosa con 2GB. Importa?
La risposta che ci porterà al concetto di come SQL Server archivia i dati. Ho un altro articolo che lo spiega in dettaglio con esempi e illustrazioni.
In breve, i dati vengono archiviati in pagine da 8 KB. Quando una riga di dati supera questa dimensione, SQL Server la sposta in un'altra unità di allocazione della pagina denominata ROW_OVERFLOW_DATA.
Si supponga di disporre di dati VARCHAR a 2 byte che potrebbero adattarsi all'unità di allocazione della pagina originale. Quando si archivia una stringa di dimensioni superiori a 8000 byte, i dati verranno spostati nella pagina di overflow delle righe. Quindi rimpiccioliscilo di nuovo a una dimensione inferiore e verrà spostato di nuovo alla pagina originale. Il movimento avanti e indietro causa molto I/O e un collo di bottiglia delle prestazioni. Recuperare questo da 2 pagine invece di 1 richiede anche I/O extra.
Un altro motivo è l'indicizzazione. VARCHAR(MAX) è un grande NO come chiave di indice. Nel frattempo, VARCHAR(8000) supererà la dimensione massima della chiave di indice. Cioè 1700 byte per gli indici non in cluster e 900 byte per gli indici in cluster.
IMPATTO DELLA CONVERSIONE DEI DATI
Ma c'è un'altra considerazione:la conversione dei dati. Provalo con un CAST senza la taglia come il codice qui sotto.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Questo codice eseguirà una conversione di una data/ora con informazioni sul fuso orario in VARCHAR.
Quindi, se diventiamo pigri specificando la dimensione durante CAST o CONVERT, il risultato è limitato a soli 30 caratteri.
Che ne dici di convertire NVARCHAR in VARCHAR con il supporto UTF-8? C'è una spiegazione dettagliata di questo più avanti, quindi continua a leggere.
2. Usa VARCHAR se la dimensione della stringa varia notevolmente
Nomi da AdventureWorks database di dimensioni variabili. Uno dei nomi più brevi è Min Su, mentre il nome più lungo è Osarumwense Uwaifiokun Agbonile. È compreso tra 6 e 31 caratteri inclusi gli spazi. Importiamo questi nomi in 2 tabelle e confrontiamo tra VARCHAR e CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Quale dei 2 è meglio? Verifichiamo le letture logiche utilizzando il codice seguente e ispezionando l'output di STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
Letture logiche:
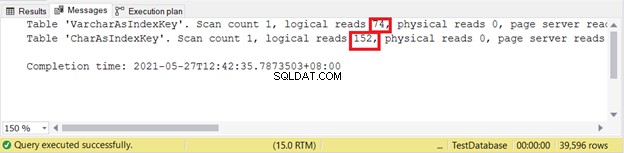
Meno logiche sono le letture, meglio è. Qui, la colonna CHAR utilizzava più del doppio della controparte VARCHAR. Pertanto, VARCHAR vince in questo esempio.
3. Usa VARCHAR come chiave di indice invece di CHAR quando i valori variano nelle dimensioni
Cosa è successo quando sono state utilizzate come chiavi di indice? CHAR andrà meglio di VARCHAR? Usiamo gli stessi dati della sezione precedente e rispondiamo a questa domanda.
Esamineremo alcuni dati e controlleremo le letture logiche. In questo esempio, il filtro utilizza la chiave di indice.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
Letture logiche:
Pertanto, le chiavi di indice VARCHAR sono migliori delle chiavi di indice CHAR quando la chiave ha dimensioni variabili. Ma che ne dici di INSERT e UPDATE che altereranno le voci dell'indice?
QUANDO SI UTILIZZA INSERT E UPDATE
Testiamo 2 casi e poi controlliamo le letture logiche come facciamo di solito.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
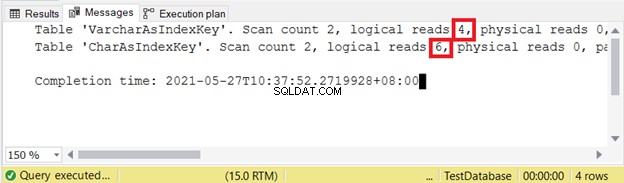
Letture logiche:
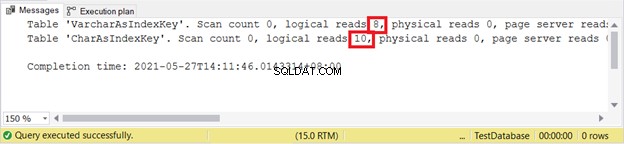
VARCHAR è ancora migliore quando si inseriscono record. Che ne dici di AGGIORNAMENTO?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Letture logiche:
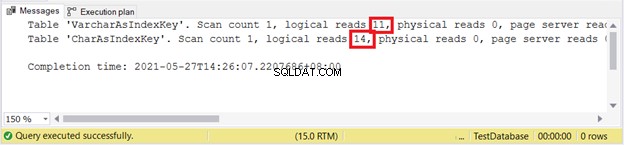
Sembra che VARCHAR vinca di nuovo.
Alla fine, vince il nostro test, anche se potrebbe essere piccolo. Hai un test case più grande che dimostri il contrario?
4. Prendi in considerazione VARCHAR con supporto UTF-8 per dati multilingue (SQL Server 2019+)
Se nella tabella è presente un mix di caratteri Unicode e non Unicode, puoi considerare VARCHAR con supporto UTF-8 su NVARCHAR. Se la maggior parte dei caratteri rientra nell'intervallo ASCII da 0 a 127, può offrire un risparmio di spazio rispetto a NVARCHAR.
Per capire cosa intendo, facciamo un confronto.
NVARCHAR TO VARCHAR CON SUPPORTO UTF-8
Hai già migrato i tuoi database a SQL Server 2019? Stai pianificando di migrare i tuoi dati di stringa in regole di confronto UTF-8? Avremo un esempio di un valore misto di caratteri giapponesi e non giapponesi per darti un'idea.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Ora che i dati sono impostati, esamineremo la dimensione in byte dei 2 valori:

Sorpresa! Con NVARCHAR, la dimensione è di 30 byte. Sono 15 volte più di 2 caratteri. Ma quando convertito in VARCHAR con supporto UTF-8, la dimensione è di soli 27 byte. Perché 27? Controlla come viene calcolato.

Pertanto, 9 dei caratteri sono 1 byte ciascuno. Questo è interessante perché, con NVARCHAR, anche le lettere inglesi sono 2 byte. Il resto dei caratteri giapponesi sono 3 byte ciascuno.
Se fossero stati tutti caratteri giapponesi, la stringa di 15 caratteri sarebbe 45 byte e consumerebbe anche la dimensione massima di VarcharUTF8 colonna. Si noti che la dimensione di NVarcharValue la colonna è inferiore a VarcharUTF8 .
Le dimensioni non possono essere uguali durante la conversione da NVARCHAR o i dati potrebbero non adattarsi. Puoi fare riferimento alla precedente Tabella 1.
Considera l'impatto sulle dimensioni durante la conversione di NVARCHAR in VARCHAR con il supporto UTF-8.
Non usare VARCHAR in SQL Server
1. Quando la dimensione della stringa è fissa e non annullabile, utilizzare invece CHAR.
La regola generale quando è richiesta una stringa di dimensioni fisse è usare CHAR. Lo seguo quando ho un requisito di dati che necessita di spazi imbottiti a destra. Altrimenti, userò VARCHAR. Ho avuto alcuni casi d'uso in cui dovevo scaricare stringhe di lunghezza fissa senza delimitatori in un file di testo per un client.
Inoltre, utilizzo le colonne CHAR solo se le colonne non saranno annullabili. Come mai? Perché la dimensione in byte delle colonne CHAR quando NULL è uguale alla dimensione definita della colonna. Eppure VARCHAR quando NULL ha una dimensione di 1, non importa quanto sia la dimensione definita. Esegui il codice qui sotto e guardalo di persona.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Non utilizzare VARCHAR(n) Se n Supererà gli 8000 byte. Usa invece VARCHAR(MAX).
Hai una stringa che supererà gli 8000 byte? Questo è il momento di usare VARCHAR(MAX). Ma per le forme di dati più comuni come nomi e indirizzi, VARCHAR(MAX) è eccessivo e avrà un impatto sulle prestazioni. Nella mia esperienza personale, non ricordo un requisito per l'utilizzo di VARCHAR(MAX).
3. Quando si utilizzano caratteri multilingue con SQL Server 2017 e versioni precedenti. Usa invece NVARCHAR.
Questa è una scelta ovvia se utilizzi ancora SQL Server 2017 e versioni precedenti.
Il risultato finale
Il tipo di dati VARCHAR ci ha servito bene per così tanti aspetti. Lo ha fatto per me da SQL Server 7. Tuttavia, a volte, facciamo ancora scelte sbagliate. In questo post, SQL VARCHAR è definito e confrontato con altri tipi di dati di stringa con esempi. E ancora, ecco le cose da fare e da non fare per un database più veloce:
Cose da fare:
- Specifica la taglia n in VARCHAR[(n)] anche se è facoltativo.
- Usalo quando la dimensione della stringa varia considerevolmente.
- Considera le colonne VARCHAR come chiavi di indice invece di CHAR.
- E se ora stai utilizzando SQL Server 2019, prendi in considerazione VARCHAR per stringhe multilingue con supporto UTF-8.
Non fare:
- Non utilizzare VARCHAR quando la dimensione della stringa è fissa e non annullabile.
- Non utilizzare VARCHAR(n) quando la dimensione della stringa supererà gli 8000 byte.
- E non utilizzare VARCHAR per dati multilingue quando si utilizza SQL Server 2017 e versioni precedenti.
Hai qualcos'altro da aggiungere? Facci sapere nella sezione commenti. Se pensi che questo possa aiutare i tuoi amici sviluppatori, condividilo sulle tue piattaforme di social media preferite.



