Il tipo e il numero di blocchi acquisiti e rilasciati durante l'esecuzione della query possono avere un effetto sorprendente sulle prestazioni (quando si usa un livello di isolamento del blocco come il read commit predefinito) anche quando non si verificano attese o blocchi. Non ci sono informazioni nei piani di esecuzione per indicare la quantità di attività di blocco durante l'esecuzione, il che rende più difficile individuare quando un blocco eccessivo sta causando un problema di prestazioni.
Per esplorare alcuni comportamenti di blocco meno noti in SQL Server, riutilizzerò le query e analizzerò i dati del mio ultimo post sul calcolo delle mediane. In quel post, ho menzionato che il OFFSET la soluzione mediana raggruppata richiedeva un PAGLOCK esplicito suggerimento di blocco per evitare di perdere male al cursore nidificato soluzione, quindi iniziamo dando un'occhiata ai motivi in dettaglio.
La soluzione mediana raggruppata OFFSET
Il test della mediana raggruppato ha riutilizzato i dati campione del precedente articolo di Aaron Bertrand. Lo script seguente ricrea questa configurazione di milioni di righe, composta da diecimila record per ciascuno dei cento venditori immaginari:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
OFFSET di SQL Server 2012 (e versioni successive). la soluzione creata da Peter Larsson è la seguente (senza alcun suggerimento di blocco):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
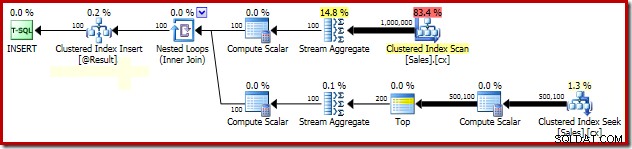
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Di seguito sono riportate le parti importanti del piano post-esecuzione:

Con tutti i dati richiesti in memoria, questa query viene eseguita in 580 ms in media sul mio laptop (con SQL Server 2014 Service Pack 1). Le prestazioni di questa query possono essere migliorate a 320 ms semplicemente aggiungendo un suggerimento di blocco della granularità della pagina alla tabella Sales nella sottoquery apply:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Il piano di esecuzione è invariato (beh, a parte il testo del suggerimento di blocco in showplan XML ovviamente):
Analisi del blocco mediano raggruppato
La spiegazione del notevole miglioramento delle prestazioni dovuto al PAGLOCK suggerimento è abbastanza semplice, almeno inizialmente.
Se monitoriamo manualmente l'attività di blocco durante l'esecuzione di questa query, vediamo che senza l'hint di granularità del blocco della pagina, SQL Server acquisisce e rilascia oltre mezzo milione di blocchi a livello di riga durante la ricerca dell'indice cluster. Non c'è nessun blocco da incolpare; la semplice acquisizione e rilascio di questo numero di blocchi aggiunge un sovraccarico sostanziale all'esecuzione di questa query. La richiesta di blocchi a livello di pagina riduce notevolmente l'attività di blocco, con conseguente miglioramento delle prestazioni.
Il problema delle prestazioni di blocco di questo particolare piano è limitato alla ricerca dell'indice cluster nel piano sopra. La scansione completa dell'indice cluster (usato per calcolare il numero di righe presenti per ogni addetto alle vendite) utilizza automaticamente i blocchi a livello di pagina. Questo è un punto interessante. Il comportamento di blocco dettagliato del motore di SQL Server non è documentato in gran parte nella documentazione in linea, ma vari membri del team di SQL Server hanno formulato alcune osservazioni generali nel corso degli anni, incluso il fatto che le scansioni senza restrizioni tendono a iniziare a prendere pagina blocchi, mentre le operazioni più piccole tendono a iniziare con blocchi di riga.
Query Optimizer rende disponibili alcune informazioni al motore di archiviazione, comprese le stime della cardinalità, suggerimenti interni per il livello di isolamento e la granularità di blocco, quali ottimizzazioni interne possono essere applicate in sicurezza e così via. Anche in questo caso, questi dettagli non sono documentati nella documentazione in linea. Alla fine, il motore di archiviazione utilizza una serie di informazioni per decidere quali blocchi sono necessari in fase di esecuzione e con quale granularità devono essere presi.
Come nota a margine, e ricordando che stiamo parlando di una query eseguita con il blocco predefinito lettura del livello di isolamento della transazione con commit, si noti che i blocchi di riga presi senza l'hint di granularità non si trasformeranno in un blocco di tabella in questo caso. Ciò è dovuto al fatto che il comportamento normale in caso di read commit è di rilasciare il blocco precedente appena prima di acquisire il blocco successivo, il che significa che in un determinato momento verrà mantenuto solo un blocco di riga condiviso (con i relativi blocchi condivisi di intenti di livello superiore associati). Poiché il numero di blocchi di riga mantenuti contemporaneamente non raggiunge mai la soglia, non viene tentata alcuna escalation del blocco.
La soluzione mediana singola OFFSET
Il test delle prestazioni per un singolo calcolo della mediana utilizza un diverso insieme di dati campione, ancora una volta riprodotto dal precedente articolo di Aaron. Lo script seguente crea una tabella con dieci milioni di righe di dati pseudocasuali:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Il OFFSET la soluzione è:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Il piano post-esecuzione è:

Questa query viene eseguita in 910 ms in media sulla mia macchina di prova. Le prestazioni sono invariate se un PAGLOCK viene aggiunto un suggerimento, ma il motivo non è quello che potresti pensare...
Analisi del bloccaggio della singola mediana
Potresti aspettarti che il motore di archiviazione scelga comunque i blocchi condivisi a livello di pagina, a causa della scansione dell'indice cluster, spiegando perché un PAGLOCK suggerimento non ha effetto. In effetti, il monitoraggio dei blocchi presi durante l'esecuzione di questa query rivela che nessun blocco condiviso (S) viene preso, a qualsiasi granularità . Gli unici blocchi presi sono l'intento condiviso (IS) a livello di oggetto e pagina.
La spiegazione di questo comportamento è suddivisa in due parti. La prima cosa da notare è che Clustered Index Scan è al di sotto di un operatore Top nel piano di esecuzione. Ciò ha un effetto importante sulle stime di cardinalità, come mostrato nel piano di pre-esecuzione (stimato):

Il OFFSET e FETCH le clausole nella query fanno riferimento a un'espressione e a una variabile, quindi Query Optimizer indovina il numero di righe che saranno necessarie in fase di esecuzione. L'ipotesi standard per Top è di cento righe. Ovviamente questa è un'ipotesi terribile, ma è sufficiente per convincere il motore di archiviazione a bloccare la granularità di riga anziché a livello di pagina.
Se disabilitiamo l'effetto "obiettivo riga" dell'operatore Top utilizzando il flag di traccia documentato 4138, il numero stimato di righe alla scansione cambia a dieci milioni (che è ancora errato, ma nella direzione opposta). Questo è sufficiente per modificare la decisione sulla granularità del blocco del motore di archiviazione, in modo che vengano presi i blocchi condivisi a livello di pagina (nota, non i blocchi condivisi dall'intento):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Il piano di esecuzione stimato prodotto con il flag di traccia 4138 è:

Tornando all'esempio principale, la stima di cento righe dovuta all'obiettivo di riga ipotizzato indica che il motore di archiviazione sceglie di bloccare a livello di riga. Tuttavia, osserviamo solo i blocchi di intent-shared (IS) a livello di tabella e pagina. Questi blocchi di livello superiore sarebbero abbastanza normali se vedessimo blocchi condivisi (S) a livello di riga, quindi dove sono finiti?
La risposta è che il motore di archiviazione contiene un'altra ottimizzazione che può saltare i blocchi condivisi a livello di riga in determinate circostanze. Quando viene applicata questa ottimizzazione, i blocchi di condivisione dell'intento di livello superiore vengono comunque acquisiti.
Per riassumere, per la query a mediana singola:
- L'uso di una variabile e di un'espressione nel
OFFSETclausola significa che l'ottimizzatore indovina la cardinalità. - La stima bassa indica che il motore di archiviazione decide una strategia di blocco a livello di riga.
- Un'ottimizzazione interna significa che i blocchi S a livello di riga vengono ignorati in fase di esecuzione, lasciando solo i blocchi IS a livello di pagina e oggetto.
La singola query mediana avrebbe avuto lo stesso problema di prestazioni di blocco delle righe della mediana raggruppata (a causa della stima imprecisa di Query Optimizer), ma è stata salvata da un'ottimizzazione del motore di archiviazione separata che ha comportato solo l'adozione di blocchi di pagine e tabelle condivisi per intenzione in fase di esecuzione.
Il test della mediana raggruppata rivisitato
Ci si potrebbe chiedere perché il Clustered Index Seek nel test della mediana raggruppata non ha sfruttato la stessa ottimizzazione del motore di archiviazione per saltare i blocchi condivisi a livello di riga. Perché sono stati utilizzati così tanti blocchi di riga condivisi, creando il PAGLOCK suggerimento necessario?
La risposta breve è che questa ottimizzazione non è disponibile per INSERT...SELECT interrogazioni. Se eseguiamo il SELECT da solo (cioè senza scrivere i risultati su una tabella) e senza un PAGLOCK suggerimento, l'ottimizzazione del salto del blocco riga è applicato:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Vengono utilizzati solo i blocchi IS (intent-shared) a livello di tabella e pagina e le prestazioni aumentano allo stesso livello di quando utilizziamo il PAGLOCK suggerimento. Ovviamente non troverai questo comportamento nella documentazione e potrebbe cambiare in qualsiasi momento. Tuttavia, è bene esserne consapevoli.
Inoltre, nel caso te lo stavi chiedendo, il flag di traccia 4138 non ha alcun effetto sulla scelta della granularità di blocco del motore di archiviazione in questo caso perché il numero stimato di righe alla ricerca è troppo basso (per iterazione dell'applicazione) anche con l'obiettivo di riga disabilitato.
Prima di trarre conclusioni sulle prestazioni di una query, assicurati di controllare il numero e il tipo di blocchi che sta prendendo durante l'esecuzione. Sebbene SQL Server di solito scelga la granularità "giusta", a volte può sbagliare, a volte con effetti drammatici sulle prestazioni.