A volte durante la nostra esecuzione come DBA, ci imbattiamo in almeno una tabella caricata con record duplicati. Anche se la tabella ha una chiave primaria (nella maggior parte dei casi una chiave incrementale), il resto dei campi potrebbe avere valori duplicati.
Tuttavia, SQL Server consente molti modi per eliminare quei record duplicati (ad es. utilizzando CTE, funzione SQL Rank, sottoquery con Raggruppa per e così via).
Ricordo che una volta, durante un'intervista, mi è stato chiesto come eliminare i record duplicati in una tabella lasciando solo 1 di ciascuno. In quel momento non sono stato in grado di rispondere, ma ero molto curioso. Dopo aver cercato un po', ho trovato molte opzioni per risolvere questo problema.
Ora, anni dopo, sono qui per presentarvi una stored procedure che mira a rispondere alla domanda "come eliminare i record duplicati nella tabella SQL?". Qualsiasi DBA può semplicemente usarlo per fare alcune pulizie senza preoccuparsi troppo.
Crea stored procedure:considerazioni iniziali
L'account che utilizzi deve disporre di privilegi sufficienti per creare una stored procedure nel database previsto.
L'account che esegue questa stored procedure deve disporre di privilegi sufficienti per eseguire le operazioni SELECT ed DELETE sulla tabella del database di destinazione.
Questa stored procedure è destinata alle tabelle del database che non hanno una chiave primaria (né un vincolo UNIQUE) definita. Tuttavia, se la tabella dispone di una chiave primaria, la stored procedure non terrà conto di tali campi. Eseguirà la ricerca e l'eliminazione in base al resto dei campi (quindi usalo con molta attenzione in questo caso).
Come utilizzare la procedura archiviata in SQL
Copia e incolla il codice SP T-SQL disponibile in questo articolo. L'SP prevede 3 parametri:
@NomeSchema – il nome dello schema della tabella del database, se applicabile. In caso contrario, utilizzare dbo .
@NomeTabella – il nome della tabella del database in cui sono archiviati i valori duplicati.
@displayOnly – se impostato su 1 , i record duplicati effettivi non verranno eliminati , ma solo visualizzato (se presente). Per impostazione predefinita, questo valore è impostato su 0 il che significa che l'eliminazione effettiva avverrà se esistono duplicati.
Stored procedure di SQL Server test di esecuzione
Per dimostrare la stored procedure, ho creato due tabelle diverse:una senza chiave primaria e l'altra con chiave primaria. Ho inserito alcuni record fittizi in queste tabelle. Verifichiamo quali risultati ottengo prima/dopo l'esecuzione della stored procedure.
Tabella SQL con chiave primaria
CREATE TABLE [dbo].[test](
[column1] [varchar](16) NOT NULL,
[column2] [varchar](16) NOT NULL,
[column3] [varchar](16) NOT NULL,
CONSTRAINT [PK_Test] PRIMARY KEY CLUSTERED
(
[column1] ASC,
[column2] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
Procedura archiviata SQL Record di esempio
INSERT INTO test VALUES('A','A',1),('A','B',1),('A','C',1),('B','A',2),('B','B',3),('B','C',4)
Esegui stored procedure con solo visualizzazione
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'test',@displayOnly = 1
Poiché colonna1 e colonna2 costituiscono la chiave primaria, i duplicati vengono valutati rispetto alle colonne chiave non primaria, in questo caso colonna3. Il risultato è corretto.
Esegui stored procedure senza solo visualizzazione
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'test',@displayOnly = 0
I record duplicati sono spariti.
Tuttavia, devi stare attento con questo approccio perché la prima occorrenza del record è quella che verrà tagliata. Quindi, se per qualsiasi motivo hai bisogno di eliminare un record molto specifico, devi affrontare il tuo caso particolare separatamente.
Tabella SQL senza chiave primaria
CREATE TABLE [dbo].[duplicates](
[column1] [varchar](16) NOT NULL,
[column2] [varchar](16) NOT NULL,
[column3] [varchar](16) NOT NULL
) ON [PRIMARY]
GO
Procedura archiviata SQL Record di esempio
INSERT INTO duplicates VALUES
('John','Smith','Y'),
('John','Smith','Y'),
('John','Smith','N'),
('Peter','Parker','N'),
('Bruce','Wayne','Y'),
('Steve','Rogers','Y'),
('Steve','Rogers','Y'),
('Tony','Stark','N')

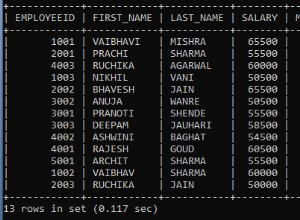
Esegui stored procedure con solo visualizzazione
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'duplicates',@displayOnly = 1
L'output è corretto, quelli sono i record duplicati nella tabella.
Esegui stored procedure senza solo visualizzazione
EXEC DBA_DeleteDuplicates @schemaName = 'dbo',@tableName = 'duplicates',@displayOnly = 0
La stored procedure ha funzionato come previsto e i duplicati sono stati eliminati correttamente.
Casi speciali per questa stored procedure in SQL
Se lo schema o la tabella che stai specificando non esiste nel tuo database, la Stored Procedure ti avviserà e lo script terminerà la sua esecuzione.

Se lasci vuoto il nome dello schema, lo script ti avviserà e ne terminerà l'esecuzione.

Se lasci vuoto il nome della tabella, lo script ti avviserà e terminerà la sua esecuzione.

Se esegui la stored procedure su una tabella che non ha duplicati e attivi il bit @displayOnly , otterrai un set di risultati vuoto.

Procedura archiviata di SQL Server:codice completo
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author : Alejandro Cobar
-- Create date: 2021-06-01
-- Description: SP to delete duplicate rows in a table
-- =============================================
CREATE PROCEDURE DBA_DeleteDuplicates
@schemaName VARCHAR(128),
@tableName VARCHAR(128),
@displayOnly BIT = 0
AS
BEGIN
SET NOCOUNT ON;
IF LEN(@schemaName) = 0
BEGIN
PRINT 'You must specify the schema of the table!'
RETURN
END
IF LEN(@tableName) = 0
BEGIN
PRINT 'You must specify the name of the table!'
RETURN
END
IF EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = @schemaName AND TABLE_NAME = @tableName)
BEGIN
DECLARE @pkColumnName VARCHAR(128);
DECLARE @columnName VARCHAR(128);
DECLARE @sqlCommand VARCHAR(MAX);
DECLARE @columnsList VARCHAR(MAX);
DECLARE @pkColumnsList VARCHAR(MAX);
DECLARE @pkColumns TABLE(pkColumn VARCHAR(128));
DECLARE @limit INT;
INSERT INTO @pkColumns
SELECT K.COLUMN_NAME
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS AS C
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE AS K ON C.TABLE_NAME = K.TABLE_NAME AND C.CONSTRAINT_SCHEMA = K.CONSTRAINT_SCHEMA
WHERE C.CONSTRAINT_TYPE = 'PRIMARY KEY'
AND C.CONSTRAINT_SCHEMA = @schemaName AND C.TABLE_NAME = @tableName
IF((SELECT COUNT(*) FROM @pkColumns) > 0)
BEGIN
DECLARE pk_cursor CURSOR FOR
SELECT * FROM @pkColumns
OPEN pk_cursor
FETCH NEXT FROM pk_cursor INTO @pkColumnName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @pkColumnsList = CONCAT(@pkColumnsList,'',@pkColumnName,',')
FETCH NEXT FROM pk_cursor INTO @pkColumnName
END
CLOSE pk_cursor
DEALLOCATE pk_cursor
SET @pkColumnsList = SUBSTRING(@pkColumnsList,1,LEN(@pkColumnsList)-1)
END
DECLARE columns_cursor CURSOR FOR
SELECT COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_SCHEMA = @schemaName AND TABLE_NAME = @tableName AND COLUMN_NAME NOT IN (SELECT pkColumn FROM @pkColumns)
ORDER BY ORDINAL_POSITION;
OPEN columns_cursor
FETCH NEXT FROM columns_cursor INTO @columnName
WHILE @@FETCH_STATUS = 0
BEGIN
SET @columnsList = CONCAT(@columnsList,'',@columnName,',')
FETCH NEXT FROM columns_cursor INTO @columnName
END
CLOSE columns_cursor
DEALLOCATE columns_cursor
SET @columnsList = SUBSTRING(@columnsList,1,LEN(@columnsList)-1)
IF((SELECT COUNT(*) FROM @pkColumns) > 0)
BEGIN
IF(CHARINDEX(',',@columnsList) = 0)
SET @limit = LEN(@columnsList)+1
ELSE
SET @limit = CHARINDEX(',',@columnsList)
SET @sqlCommand = CONCAT('WITH CTE (',@columnsList,',DuplicateCount',')
AS (SELECT ',@columnsList,',',
'ROW_NUMBER() OVER(PARTITION BY ',@columnsList,' ',
'ORDER BY ',SUBSTRING(@columnsList,1,@limit-1),') AS DuplicateCount
FROM [',@schemaName,'].[',@tableName,'])
')
IF @displayOnly = 0
SET @sqlCommand = CONCAT(@sqlCommand,'DELETE FROM CTE WHERE DuplicateCount > 1;')
IF @displayOnly = 1
SET @sqlCommand = CONCAT(@sqlCommand,'SELECT ',@columnsList,',MAX(DuplicateCount) AS DuplicateCount FROM CTE WHERE DuplicateCount > 1 GROUP BY ',@columnsList)
END
ELSE
BEGIN
SET @sqlCommand = CONCAT('WITH CTE (',@columnsList,',DuplicateCount',')
AS (SELECT ',@columnsList,',',
'ROW_NUMBER() OVER(PARTITION BY ',@columnsList,' ',
'ORDER BY ',SUBSTRING(@columnsList,1,CHARINDEX(',',@columnsList)-1),') AS DuplicateCount
FROM [',@schemaName,'].[',@tableName,'])
')
IF @displayOnly = 0
SET @sqlCommand = CONCAT(@sqlCommand,'DELETE FROM CTE WHERE DuplicateCount > 1;')
IF @displayOnly = 1
SET @sqlCommand = CONCAT(@sqlCommand,'SELECT * FROM CTE WHERE DuplicateCount > 1;')
END
EXEC (@sqlCommand)
END
ELSE
BEGIN
PRINT 'Table doesn't exist within this database!'
RETURN
END
END
GO
Conclusione
Se non sai come eliminare i record duplicati nella tabella SQL, strumenti come questo ti saranno utili. Qualsiasi DBA può verificare se ci sono tabelle di database che non hanno chiavi primarie (né vincoli univoci) per loro, che potrebbero accumulare una pila di record non necessari nel tempo (potenzialmente sprecando spazio di archiviazione). Collega e riproduci la stored procedure e sei a posto.
Puoi andare un po' oltre e creare un meccanismo di avviso per avvisarti se ci sono duplicati per una tabella specifica (dopo aver implementato un po' di automazione usando questo strumento, ovviamente), il che è abbastanza utile.
Come per qualsiasi cosa relativa alle attività DBA, assicurati di testare sempre tutto in un ambiente sandbox prima di premere il grilletto in produzione. E quando lo fai, assicurati di avere un backup della tabella su cui ti concentri.