Gli indici sono acceleratori di velocità nei database SQL. Possono essere raggruppati o non raggruppati. Ma cosa significa e dove dovresti applicarli?
Conosco questa sensazione. Ci sono stato. I principianti sono spesso confusi su quale indice utilizzare su quali colonne. Tuttavia, anche gli esperti devono riflettere su questo problema prima di prendere una decisione e situazioni diverse richiedono decisioni diverse. Come vedrai più avanti, ci sono query in cui un indice cluster risplenderà rispetto a un indice non cluster e viceversa.
Tuttavia, in primo luogo, dobbiamo conoscere ciascuno di loro. Se stai cercando le stesse informazioni, oggi è il tuo giorno fortunato.
Questo articolo ti dirà cosa sono questi indici e quando usarli. Naturalmente, ci saranno esempi di codice da provare in pratica. Quindi, prendi le tue patatine o la pizza e una bibita o un caffè e preparati a immergerti in questo viaggio perspicace.
Pronto?
Cos'è l'indice cluster
Un indice cluster è un indice che definisce l'ordinamento fisico delle righe in una tabella o vista.
Per vederlo nella forma reale, prendiamo il Dipendente tabella in AdventureWorks2017 banca dati.
La chiave primaria è anche un indice cluster e la chiave è basata su BusinessEntityID colonna. Quando esegui un SELECT su questa tabella senza ORDER BY, vedrai che è ordinato in base alla chiave primaria.
Provalo tu stesso usando il codice qui sotto:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Ora, guarda il risultato nella Figura 1:
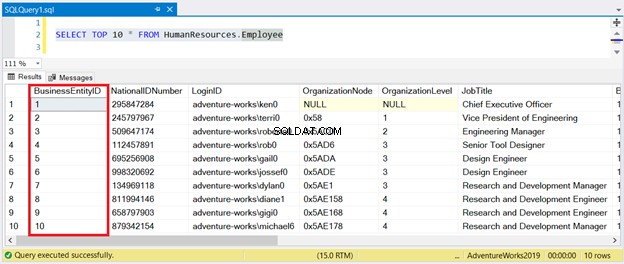
Come puoi vedere, non è necessario ordinare il set di risultati con BusinessEntityID . L'indice cluster si occupa di questo.
A differenza degli indici non cluster, puoi avere solo 1 indice cluster per tabella. E se provassimo questo sul Dipendente tavolo?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Abbiamo un errore simile di seguito:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
Quando utilizzare un indice cluster?
Una colonna è il miglior candidato per un indice cluster se si verifica una delle seguenti condizioni:
- Viene utilizzato in un gran numero di query nella clausola WHERE e si unisce.
- Verrà utilizzata come chiave esterna per un'altra tabella e, infine, per i join.
- Valori di colonna univoci.
- È meno probabile che il valore cambi.
- Quella colonna viene utilizzata per interrogare un intervallo di valori. Operatori come>, <,>=, <=o BETWEEN vengono utilizzati con la colonna nella clausola WHERE.
Ma gli indici cluster non vanno bene se la colonna o le colonne
- cambia frequentemente
- sono chiavi larghe o una combinazione di colonne con una chiave di grandi dimensioni.
Esempi
Gli indici cluster possono essere creati utilizzando il codice T-SQL o qualsiasi strumento GUI di SQL Server. Puoi farlo in T-SQL al momento della creazione della tabella, in questo modo:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
Oppure puoi farlo usando ALTER TABLE dopo creazione della tabella senza un indice cluster:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Un altro modo è usare CREATE CLUSTERED INDEX:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Un'altra alternativa è l'utilizzo di uno strumento SQL Server come SQL Server Management Studio o dbForge Studio per SQL Server.
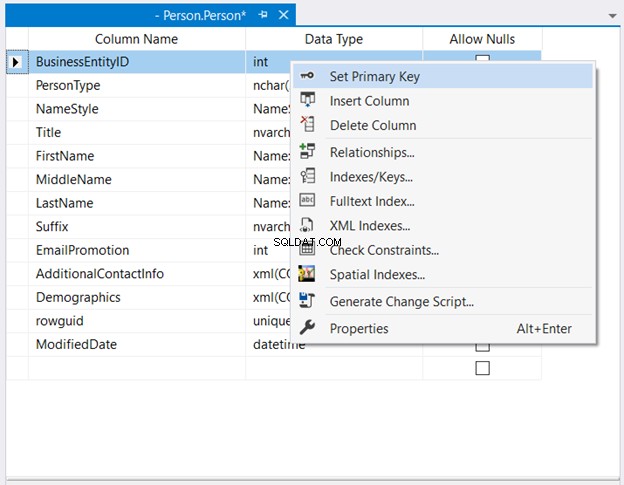
In Esplora oggetti , espandere il database e i nodi della tabella. Quindi, fai clic con il pulsante destro del mouse sulla tabella desiderata e seleziona Design . Infine, fai clic con il pulsante destro del mouse sulla colonna che vuoi che sia la chiave primaria> Imposta chiave primaria > Salva le modifiche alla tabella.
La figura 2 di seguito mostra dove BusinessEntityID è impostato come chiave primaria.
Oltre a creare un indice cluster a colonna singola, puoi utilizzare più colonne. Vedi un esempio in T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Dopo aver creato questo indice cluster, la Persona la tabella sarà ordinata fisicamente per Cognome , Nome e MiddleName .
Uno dei vantaggi di questo approccio è il miglioramento delle prestazioni delle query in base al nome. Inoltre, ordina i risultati per nome senza specificare ORDER BY. Ma nota che se il nome cambia, la tabella dovrà essere riorganizzata. Sebbene ciò non accada tutti i giorni, l'impatto può essere enorme se il tavolo è molto grande.
Che cos'è l'indice non cluster
Un indice non cluster è un indice con una chiave e un puntatore alle righe o alle chiavi dell'indice cluster. Questo indice può essere applicato sia alle tabelle che alle viste.
A differenza degli indici cluster, qui la struttura è separata dalla tabella. Poiché è separato, ha bisogno di un puntatore alle righe della tabella chiamato anche localizzatore di riga. Pertanto, ogni voce in un indice non cluster contiene un locator e un valore chiave.
Gli indici non cluster non ordinano fisicamente la tabella in base alla chiave.
Le chiavi di indice per gli indici non cluster hanno una dimensione massima di 1700 byte. Puoi aggirare questo limite aggiungendo le colonne incluse. Questo metodo è utile se la tua query deve coprire più colonne senza aumentare la dimensione della chiave.
Puoi anche creare indici filtrati non cluster. Ciò ridurrà i costi di manutenzione e archiviazione dell'indice, migliorando al contempo le prestazioni delle query.
Quando utilizzare un indice non cluster?
Una o più colonne sono buoni candidati per indici non cluster se è vero quanto segue:
- La colonna o le colonne vengono utilizzate in una clausola WHERE o in un join.
- La query non restituirà un set di risultati di grandi dimensioni.
- È necessaria la corrispondenza esatta nella clausola WHERE che utilizza l'operatore di uguaglianza.
Esempi
Questo comando creerà un indice univoco, non in cluster nel Dipendente tabella:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Oltre a una tabella, puoi creare un indice non cluster per una vista:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Altre domande comuni e risposte soddisfacenti
Quali sono le differenze tra indice cluster e non cluster?
Da quello che hai visto in precedenza, puoi già creare idee su come sono diversi gli indici cluster e non cluster. Ma mettiamola su un tavolo per una facile consultazione.
| Informazioni | Indice cluster | Indice non cluster |
| Si applica a | Tabelle e viste | Tabelle e viste |
| Consentito per tabella | 1 | 999 |
| Dimensione chiave | 900 byte | 1700 byte |
| Colonne per chiave di indice | 32 | 32 |
| Buono per | Query sull'intervallo (>,<,>=, <=, BETWEEN) | Corrispondenze esatte (=) |
| Colonne incluse non chiave | Non consentito | Consentito |
| Filtra con condizione | Non consentito | Consentito |
Le chiavi primarie dovrebbero essere un indice cluster o non cluster?
Una chiave primaria è un vincolo. Dopo aver reso una colonna una chiave primaria, viene creato automaticamente un indice cluster, a meno che non sia già presente un indice cluster esistente.
Non confondere una chiave primaria con un indice cluster! Una chiave primaria può anche essere la chiave dell'indice cluster. Ma una chiave di indice cluster può essere un'altra colonna diversa dalla chiave primaria.
Facciamo un altro esempio. Nella Persona tabella di AdventureWorks201 7, abbiamo il BusinessEntityID chiave primaria. È anche la chiave dell'indice cluster. Puoi eliminare quell'indice cluster. Quindi, crea un indice cluster basato su Cognome , Nome e secondo nome . La chiave primaria è ancora BusinessEntityID colonna.
Ma le tue chiavi primarie dovrebbero essere sempre raggruppate?
Dipende. Rivedi la domanda su quando utilizzare un indice cluster.
Se una o più colonne vengono visualizzate nella clausola WHERE in molte query, questo è un candidato per un indice cluster. Ma un'altra considerazione riguarda l'ampiezza della chiave dell'indice cluster. Troppo ampio e la dimensione di ciascun indice non cluster aumenterà se esiste. Ricorda che gli indici non cluster utilizzano anche la chiave dell'indice cluster come puntatore. Pertanto, mantieni la chiave dell'indice cluster il più ristretto possibile.
Se un numero elevato di query utilizza la chiave primaria nella clausola WHERE, lasciarla anche come chiave dell'indice cluster. In caso contrario, crea la tua chiave primaria come indice non cluster.
Ma cosa succede se non sei ancora sicuro? Quindi, puoi valutare il vantaggio in termini di prestazioni di una colonna quando è in cluster o non in cluster. Quindi, sintonizzati sulla prossima sezione a riguardo.
Qual è il più veloce:indice cluster o non cluster?
Buona domanda. Non esiste una regola generale. Devi controllare le letture logiche e il piano di esecuzione delle tue query.
Il nostro breve esperimento includerà copie delle seguenti tabelle da AdventureWorks2017 banca dati:
- Persona
- Indirizzo Entità Aziendale
- Indirizzo
- Tipo di indirizzo
Ecco lo script:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Utilizzando la struttura sopra, confronteremo le velocità delle query per indici cluster e non cluster.
Abbiamo 2 copie di Persona tavolo. Il primo utilizzerà BusinessEntityID come chiave di indice primaria e cluster. Il secondo utilizza ancora BusinessEntityID come chiave primaria. L'indice cluster si basa su Cognome , Nome , secondo nome e Suffisso .
Cominciamo.
QUERY CORRISPONDENZE ESATTE IN BASE AL COGNOME
Per prima cosa, facciamo una semplice query. Inoltre, è necessario attivare STATISTICS IO. Quindi, incolliamo i risultati in Statisticsparser.com per una presentazione tabellare.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
L'aspettativa è che il primo SELECT sarà più lento perché la clausola WHERE non corrisponde alla chiave dell'indice cluster. Ma controlliamo le letture logiche.
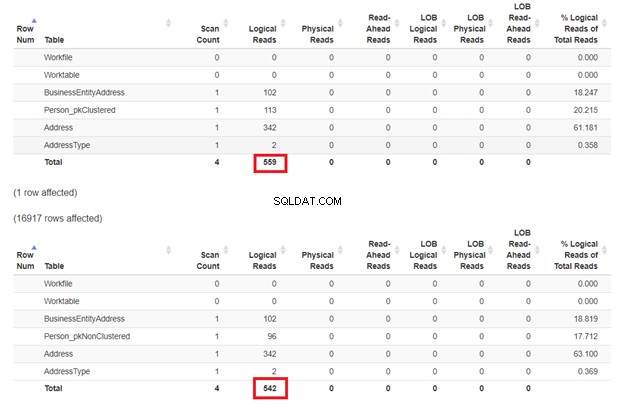
Come previsto nella Figura 3, Person_pkClustered aveva letture più logiche. Pertanto, la query necessita di più I/O. La ragione? La tabella è ordinata per BusinessEntityID . Tuttavia, la seconda tabella ha l'indice cluster basato sul nome. Poiché la query vuole un risultato basato sul nome, Person_pkNonClustered vince. Meno letture logiche, più veloce sarà la query.
Cos'altro sta succedendo? Dai un'occhiata alla Figura 4.
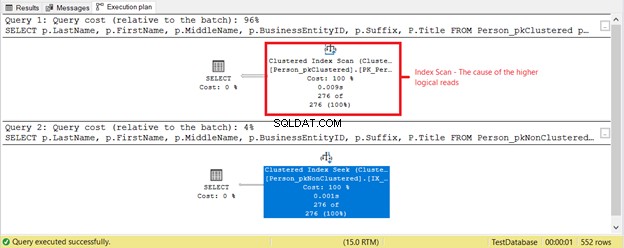
È successo qualcos'altro in base al piano di esecuzione nella Figura 4. Perché una scansione dell'indice in cluster è nel primo SELECT invece di una ricerca dell'indice? Il colpevole è il Titolo colonna nella SELEZIONA. Non è coperto da nessuno degli indici esistenti. L'ottimizzatore di SQL Server ha ritenuto più veloce l'utilizzo dell'indice cluster basato su BusinessEntityID. Quindi, SQL Server lo ha scansionato per i cognomi corretti e ha ottenuto il nome, il secondo nome e il titolo.
Rimuovi il Titolo colonna e l'operatore utilizzato sarà Ricerca indice . Come mai? Perché il resto dei campi è coperto dall'indice non cluster basato su Cognome , Nome , secondo nome e Suffisso . Include anche BusinessEntityID come localizzatore di chiavi dell'indice cluster.
QUERY RANGE BASATA SU BUSINESS ENTITY ID
Gli indici cluster possono essere utili per le query di intervallo. È sempre così? Scopriamolo utilizzando il codice qui sotto.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
La scheda necessita di righe basate su un intervallo di BusinessEntityIDs da 285 a 290. Anche in questo caso, gli indici cluster e non cluster delle 2 tabelle sono intatti. Ora, diamo le letture logiche nella Figura 5. Il vincitore previsto è Person_pkClustered perché la chiave primaria è anche la chiave dell'indice cluster.

Vedi letture logiche inferiori su Person_pkClustered ? Gli indici raggruppati hanno dimostrato il loro valore sulle query di intervallo in questo scenario. Vediamo cos'altro rivelerà il piano di esecuzione nella Figura 6.
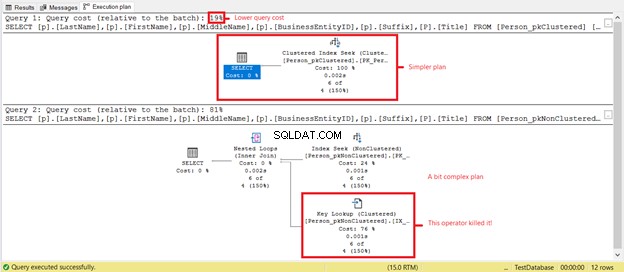
Il primo SELECT ha un piano più semplice e un costo di query inferiore in base alla Figura 7. Ciò supporta anche letture logiche inferiori. Nel frattempo, il secondo SELECT ha un operatore Key Lookup che rallenta la query. Il colpevole? Ancora una volta, è il Titolo colonna. Rimuovere la colonna nella query o aggiungerla come colonna inclusa nell'indice non cluster. Quindi, avrai un piano migliore e letture logiche inferiori.
QUERY CORRISPONDENZE ESATTE CON UN UNIONE
Molte istruzioni SELECT includono join. Facciamo alcuni test. Iniziamo con le corrispondenze esatte:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Ci aspettiamo che il secondo SELECT da Person_pkNonClustered con un indice cluster sul nome avrà meno letture logiche. Ma lo è? Vedi figura 7.
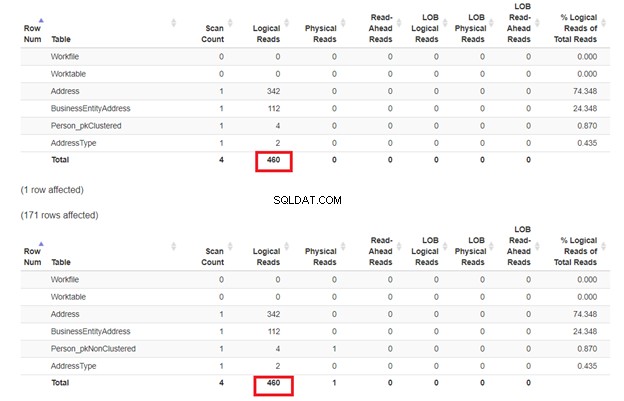
Sembra che l'indice non cluster sul nome sia andato bene. Le letture logiche sono le stesse. Se controlli il piano di esecuzione, la differenza negli operatori è il Clustered Index Seek su Person_pkNonClustered e la ricerca dell'indice su Person_pkClustered .
Quindi, per essere sicuri, dobbiamo controllare le letture logiche e il piano di esecuzione.
RICHIESTA DI RAGGIO CON UNIONE
Poiché le nostre aspettative possono essere diverse dalla realtà, proviamo con le query di intervallo. Gli indici cluster sono generalmente buoni con esso. Ma cosa succede se includi un join?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
Ora, esamina le letture logiche di queste 2 query nella Figura 8:
Che è successo? Nella Figura 9, la realtà morde Person_pkClustered . È stato osservato un costo di I/O maggiore rispetto a Person_pkNonClustered . È diverso da quello che ci aspettiamo. Ma sulla base di questa risposta del forum, una ricerca di un indice non in cluster può essere più veloce della ricerca di un indice in cluster quando tutte le colonne della query sono coperte al 100% nell'indice. Nel nostro caso, la query per Person_pkNonClustered coperto le colonne utilizzando l'indice non cluster (BusinessEntityID - chiave; Cognome , Nome , secondo nome , Suffisso – puntatore alla chiave dell'indice cluster).
INSERIRE PRESTAZIONI
Quindi, prova a testare le prestazioni di INSERT sulle stesse tabelle.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
La figura 9 mostra le letture logiche INSERT:

Entrambi hanno generato lo stesso I/O. Pertanto, entrambi si sono comportati allo stesso modo.
ELIMINA PRESTAZIONI
Il nostro ultimo test prevede DELETE:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
La Figura 10 mostra le letture logiche. Nota la differenza.

Perché abbiamo letture logiche più elevate su Person_pkClustered ? Il fatto è che la condizione dell'istruzione DELETE si basa su una corrispondenza esatta di un nome. L'ottimizzatore dovrà prima ricorrere all'indice non cluster. Significa più I/O. Confermiamo utilizzando il piano di esecuzione in Figura 11.
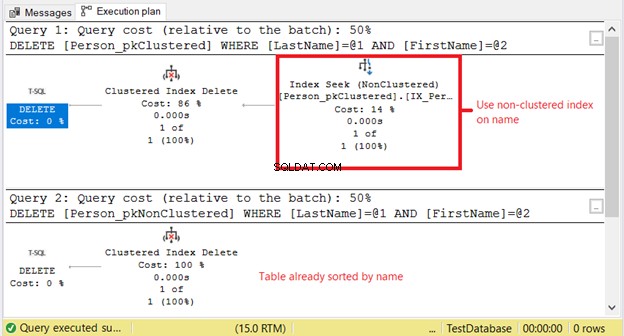
Il primo SELECT necessita di una ricerca dell'indice sull'indice non cluster. Il motivo è la clausola WHERE su Cognome e Nome . Nel frattempo, Person_pkNonClustered è già ordinato fisicamente per nome a causa dell'indice cluster.
Da asporto
Formare query ad alte prestazioni non riguarda la fortuna. Non puoi semplicemente inserire un indice cluster e uno non cluster e quindi improvvisamente le tue query hanno la forza della velocità. Devi continuare a utilizzare gli strumenti come obiettivo per concentrarti sui piccoli dettagli diversi dal set di risultati.
Ma a volte non hai tempo per fare tutto questo. Penso che sia normale. Ma finché non sbagli così tanto, hai il tuo lavoro il giorno successivo e puoi risolverlo. All'inizio non sarà facile. Sarà davvero confuso. Avrai anche molte domande. Ma con la pratica costante, puoi raggiungerlo. Quindi, tieni il mento alto.
Ricorda, sia gli indici cluster che quelli non cluster servono a potenziare le query. Conoscere le differenze principali, gli scenari di utilizzo e gli strumenti ti aiuterà nella tua ricerca per la codifica di query ad alte prestazioni.
Spero che questo post risponda alle tue domande più urgenti sugli indici cluster e non. Hai qualcos'altro da aggiungere per i nostri lettori? La sezione Commenti è aperta.
E se trovi questo post illuminante, condividilo sulle tue piattaforme di social media preferite.
Ulteriori informazioni sugli indici e sulle prestazioni delle query si trovano negli articoli seguenti:
- 22 ingegnosi esempi di indici SQL per velocizzare le tue query
- Ottimizzazione delle query SQL:5 fatti fondamentali per potenziare le tue query