Karen Ly, analista di reddito fisso Jr. presso RBC, mi ha proposto una sfida T-SQL che consiste nel trovare la corrispondenza più vicina, invece di trovare una corrispondenza esatta. In questo articolo tratterò una forma generalizzata e semplicistica della sfida.
La sfida
La sfida consiste nell'abbinare le righe di due tabelle, T1 e T2. Utilizzare il codice seguente per creare un database di esempio chiamato testdb e al suo interno le tabelle T1 e T2:
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
); Come puoi vedere, sia T1 che T2 hanno una colonna numerica (tipo INT in questo esempio) chiamata val. La sfida è abbinare ad ogni riga da T1 la riga da T2 dove la differenza assoluta tra T2.val e T1.val è la più bassa. In caso di parità (più righe corrispondenti in T2), abbina la riga superiore in base a val crescente, keycol ordine crescente. Cioè, la riga con il valore più basso nella colonna val e, se hai ancora legami, la riga con il valore keycol più basso. Lo spareggio serve a garantire il determinismo.
Utilizza il codice seguente per popolare T1 e T2 con piccoli set di dati di esempio in modo da poter verificare la correttezza delle tue soluzioni:
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19); Controlla il contenuto di T1:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T1 ORDER BY val, keycol;
Questo codice genera il seguente output:
keycol val othercols ----------- ----------- --------- 1 1 0xAA 2 1 0xAA 3 3 0xAA 4 3 0xAA 5 5 0xAA 6 8 0xAA 7 13 0xAA 8 16 0xAA 9 18 0xAA 10 20 0xAA 11 21 0xAA
Controlla i contenuti di T2:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T2 ORDER BY val, keycol;
Questo codice genera il seguente output:
keycol val othercols ----------- ----------- --------- 1 2 0xBB 2 2 0xBB 4 3 0xBB 5 3 0xBB 3 7 0xBB 6 11 0xBB 7 11 0xBB 8 13 0xBB 9 17 0xBB 10 19 0xBB
Ecco il risultato desiderato per i dati di esempio forniti:
keycol1 val1 othercols1 keycol2 val2 othercols2 ----------- ----------- ---------- ----------- ----------- ---------- 1 1 0xAA 1 2 0xBB 2 1 0xAA 1 2 0xBB 3 3 0xAA 4 3 0xBB 4 3 0xAA 4 3 0xBB 5 5 0xAA 4 3 0xBB 6 8 0xAA 3 7 0xBB 7 13 0xAA 8 13 0xBB 8 16 0xAA 9 17 0xBB 9 18 0xAA 9 17 0xBB 10 20 0xAA 10 19 0xBB 11 21 0xAA 10 19 0xBB
Prima di iniziare a lavorare sulla sfida, esamina il risultato desiderato e assicurati di aver compreso la logica di abbinamento, inclusa la logica di spareggio. Ad esempio, considera la riga in T1 dove keycol è 5 e val è 5. Questa riga ha più corrispondenze più vicine in T2:
keycol val othercols ----------- ----------- --------- 4 3 0xBB 5 3 0xBB 3 7 0xBB
In tutte queste righe la differenza assoluta tra T2.val e T1.val (5) è 2. Usando la logica di tiebreaking basata sull'ordine val ascendente, keycol ascendente della riga più in alto qui è quella in cui val è 3 e keycol è 4.
Utilizzerai i piccoli set di dati campione per verificare la validità delle tue soluzioni. Per controllare le prestazioni, hai bisogno di set più grandi. Usa il codice seguente per creare una funzione di supporto denominata GetNums, che genera una sequenza di numeri interi in un intervallo richiesto:
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Usa il codice seguente per popolare T1 e T2 con grandi set di dati di esempio:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Le variabili @numrowsT1 e @numrowsT2 controllano il numero di righe con cui si desidera che le tabelle vengano popolate. Le variabili @maxvalT1 e @maxvalT2 controllano l'intervallo di valori distinti nella colonna val e quindi influiscono sulla densità della colonna. Il codice precedente riempie le tabelle con 1.000.000 di righe ciascuna e utilizza l'intervallo da 1 a 10.000.000 per la colonna val in entrambe le tabelle. Ciò si traduce in una bassa densità nella colonna (numero elevato di valori distinti, con un numero ridotto di duplicati). L'utilizzo di valori massimi più bassi risulterà in una densità maggiore (numero minore di valori distinti e quindi più duplicati).
Soluzione 1, utilizzando una sottoquery TOP
La soluzione più semplice e ovvia è probabilmente quella che interroga T1 e, utilizzando l'operatore CROSS APPLY, applica una query con un filtro TOP (1), ordinando le righe in base alla differenza assoluta tra T1.val e T2.val, utilizzando T2.val , T2.keycol come spareggio. Ecco il codice della soluzione:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) T2.*
FROM dbo.T2
ORDER BY ABS(T2.val - T1.val), T2.val, T2.keycol ) AS A; Ricorda, ci sono 1.000.000 di righe in ciascuna delle tabelle. E la densità della colonna val è bassa in entrambe le tabelle. Sfortunatamente, poiché non esiste un predicato di filtraggio nella query applicata e l'ordinamento coinvolge un'espressione che manipola le colonne, qui non è possibile creare indici di supporto. Questa query genera il piano in Figura 1.
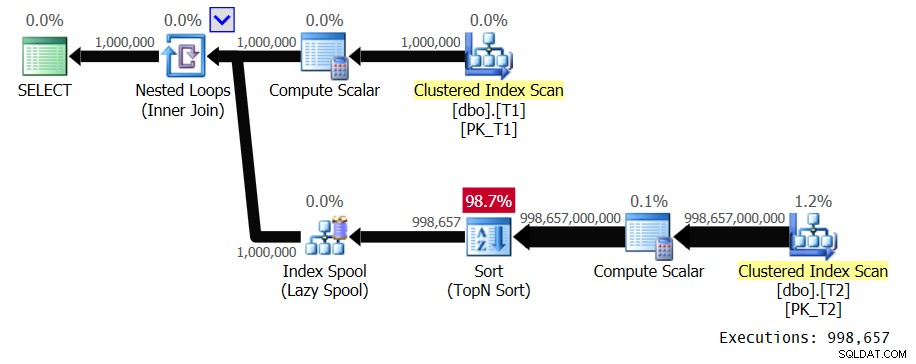 Figura 1:piano per la soluzione 1
Figura 1:piano per la soluzione 1
L'input esterno del ciclo esegue la scansione di 1.000.000 di righe da T1. L'input interno del ciclo esegue una scansione completa di T2 e un ordinamento TopN per ogni valore T1.val distinto. Nel nostro piano ciò accade 998.657 volte poiché abbiamo una densità molto bassa. Posiziona le righe in uno spool di indice, con chiave T1.val, in modo che possa riutilizzarle per occorrenze duplicate di valori T1.val, ma abbiamo pochissimi duplicati. Questo piano ha complessità quadratica. Tra tutte le esecuzioni previste del ramo interno del ciclo, si prevede che elabori quasi un trilione di righe. Quando si parla di un gran numero di righe per l'elaborazione di una query, una volta che inizi a menzionare miliardi di righe, le persone sanno già che hai a che fare con una query costosa. Normalmente, le persone non pronunciano termini come trilioni, a meno che non stiano discutendo del debito nazionale degli Stati Uniti o dei crolli del mercato azionario. Di solito non gestisci tali numeri nel contesto dell'elaborazione delle query. Ma i piani con complessità quadratica possono rapidamente ottenere tali numeri. L'esecuzione della query in SSMS con Include Live Query Statistics abilitato ha richiesto 39,6 secondi per elaborare solo 100 righe da T1 sul mio laptop. Ciò significa che il completamento di questa query dovrebbe richiedere circa 4,5 giorni. La domanda è:ti piacciono davvero i piani di query dal vivo per il binge watching? Potrebbe essere un interessante Guinness record da provare e stabilire.
Soluzione 2, utilizzando due subquery TOP
Supponendo che tu stia cercando una soluzione che richiede pochi secondi, non giorni, per essere completata, ecco un'idea. Nell'espressione della tabella applicata, unifica due query TOP (1) interne, una che filtra una riga in cui T2.val
Ecco gli indici consigliati per supportare questa soluzione:
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols); CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols); CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);
Ecco il codice completo della soluzione:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Ricorda che abbiamo 1.000.000 di righe in ogni tabella, con la colonna val con valori nell'intervallo 1 – 10.000.000 (bassa densità) e indici ottimali in atto.
Il piano per questa query è mostrato nella Figura 2.
Figura 2:piano per la soluzione 2
Osservare l'uso ottimale degli indici su T2, risultando in un piano con ridimensionamento lineare. Questo piano utilizza uno spool di indice allo stesso modo del piano precedente, ovvero per evitare di ripetere il lavoro nel ramo interno del ciclo per valori T1.val duplicati. Ecco le statistiche sulle prestazioni che ho ottenuto per l'esecuzione di questa query sul mio sistema:
Elapsed: 27.7 sec, CPU: 27.6 sec, logical reads: 17,304,674
Soluzione 2, con spooling disabilitato
Non puoi fare a meno di chiederti se la bobina dell'indice sia davvero vantaggiosa qui. Il punto è evitare di ripetere il lavoro per valori T1.val duplicati, ma in una situazione come la nostra in cui abbiamo una densità molto bassa, ci sono pochissimi duplicati. Ciò significa che molto probabilmente il lavoro coinvolto nello spooling è maggiore della semplice ripetizione del lavoro per i duplicati. C'è un modo semplice per verificarlo:usando il flag di traccia 8690 puoi disabilitare lo spooling nel piano, in questo modo:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Ho ottenuto il piano mostrato nella Figura 3 per questa esecuzione:
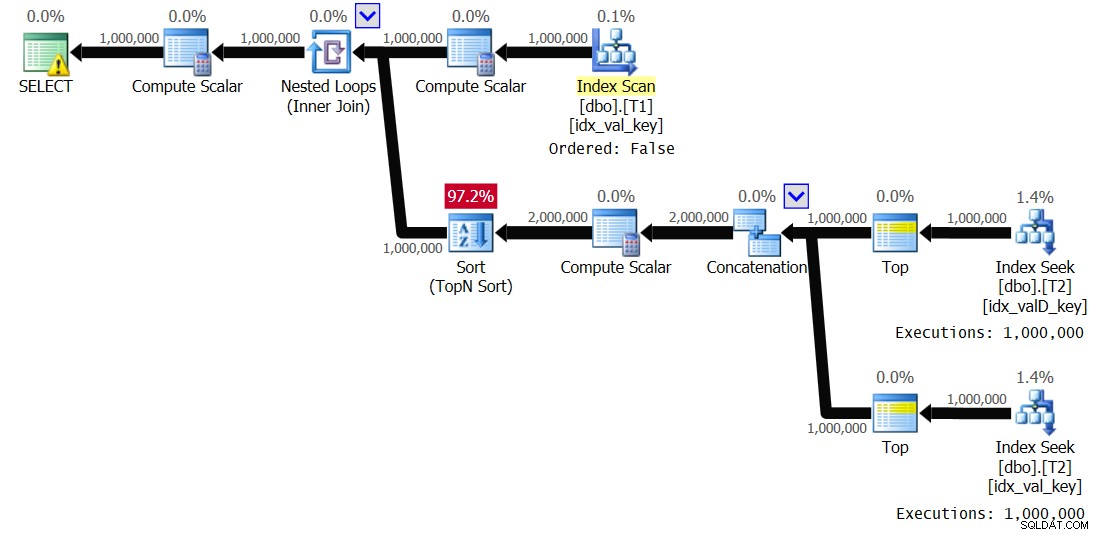 Figura 3:Piano per la Soluzione 2, con lo spooling disabilitato
Figura 3:Piano per la Soluzione 2, con lo spooling disabilitato
Osservare che lo spool dell'indice è scomparso e questa volta il ramo interno del ciclo viene eseguito 1.000.000 di volte. Ecco le statistiche sulle prestazioni che ho ottenuto per questa esecuzione:
Elapsed: 19.18 sec, CPU: 19.17 sec, logical reads: 6,042,148
Questa è una riduzione del 44 percento del tempo di esecuzione.
Soluzione 2, con intervallo di valori modificato e indicizzazione
La disabilitazione dello spooling ha molto senso quando si ha una bassa densità nei valori T1.val; tuttavia, lo spooling può essere molto utile quando hai un'alta densità. Ad esempio, esegui il codice seguente per ripopolare T1 e T2 con l'impostazione dei dati di esempio @maxvalT1 e @maxvalT2 su 1000 (1000 valori distinti massimi):
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 1000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 1000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Riesegui la Soluzione 2, prima senza il flag di traccia:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Il piano per questa esecuzione è mostrato nella Figura 4:
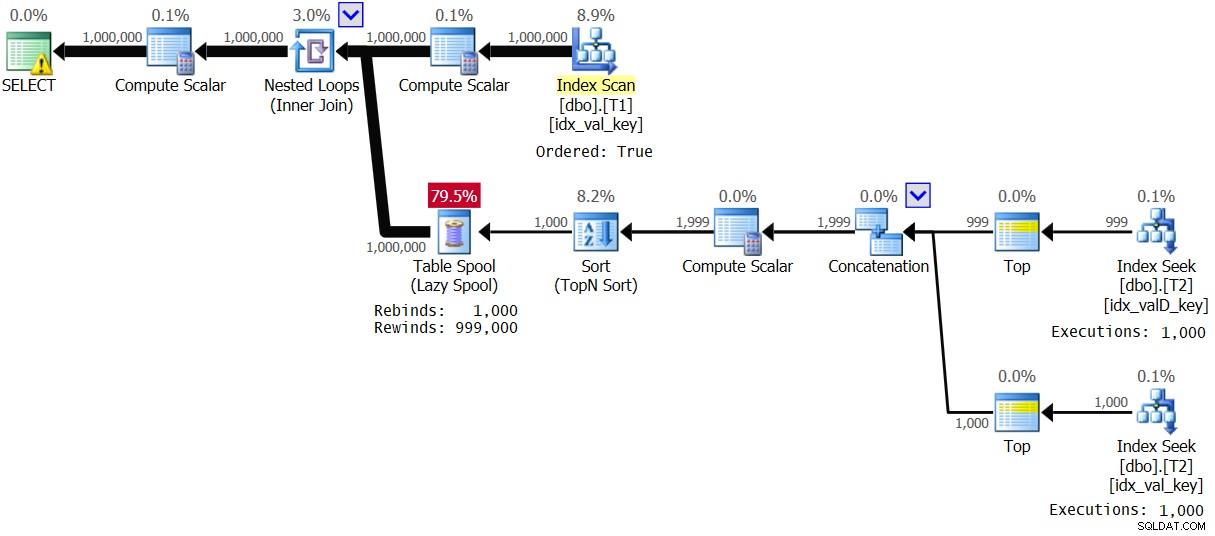 Figura 4:Piano per la Soluzione 2, con intervallo di valori 1 – 1000
Figura 4:Piano per la Soluzione 2, con intervallo di valori 1 – 1000
L'ottimizzatore ha deciso di utilizzare un piano diverso a causa dell'elevata densità in T1.val. Osservare che l'indice su T1 viene scansionato nell'ordine delle chiavi. Quindi, per ogni prima occorrenza di un valore T1.val distinto, viene eseguito il ramo interno del ciclo e il risultato viene inviato in spooling in un normale spooling di tabella (rebind). Quindi, per ogni non prima occorrenza del valore, viene applicato un riavvolgimento. Con 1.000 valori distinti, il ramo interno viene eseguito solo 1.000 volte. Ciò si traduce in eccellenti statistiche sulle prestazioni:
Elapsed: 1.16 sec, CPU: 1.14 sec, logical reads: 23,278
Ora prova a eseguire la soluzione con lo spooling disabilitato:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Ho ottenuto il piano mostrato nella Figura 5.
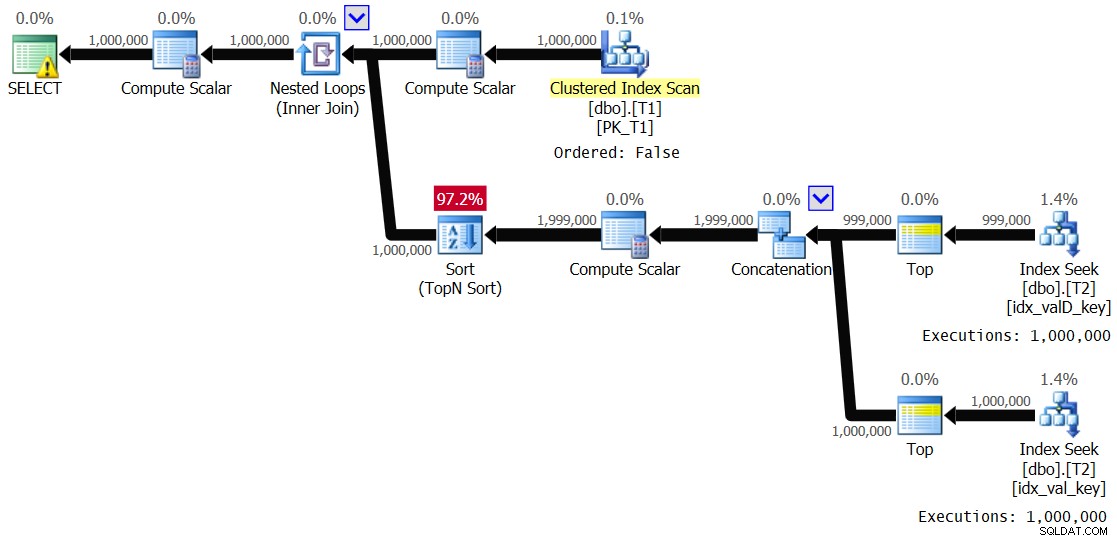 Figura 5:Piano per la Soluzione 2, con intervallo di valori 1 – 1.000 e spooling disabilitato
Figura 5:Piano per la Soluzione 2, con intervallo di valori 1 – 1.000 e spooling disabilitato
È essenzialmente lo stesso piano mostrato in precedenza nella Figura 3. Il ramo interno del ciclo viene eseguito 1.000.000 di volte. Ecco le statistiche sulle prestazioni che ho ottenuto per questa esecuzione:
Elapsed: 24.5 sec, CPU: 24.2 sec, logical reads: 8,012,548
Chiaramente, dovresti fare attenzione a non disabilitare lo spooling quando hai un'alta densità in T1.val.
La vita è bella quando la tua situazione è abbastanza semplice da poter creare indici di supporto. La realtà è che in alcuni casi, in pratica, c'è abbastanza logica aggiuntiva nella query, che preclude la possibilità di creare indici di supporto ottimali. In questi casi, la Soluzione 2 non funzionerà bene.
Per dimostrare le prestazioni della Soluzione 2 senza supportare gli indici, ripopolare T1 e T2 con l'impostazione dei dati di esempio @maxvalT1 e @maxvalT2 su 10000000 (intervallo di valori 1 – 10M) e rimuovere anche gli indici di supporto:
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Riesegui la soluzione 2, con Includi statistiche query in tempo reale abilitato in SSMS:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Ho ottenuto il piano mostrato nella Figura 6 per questa query:
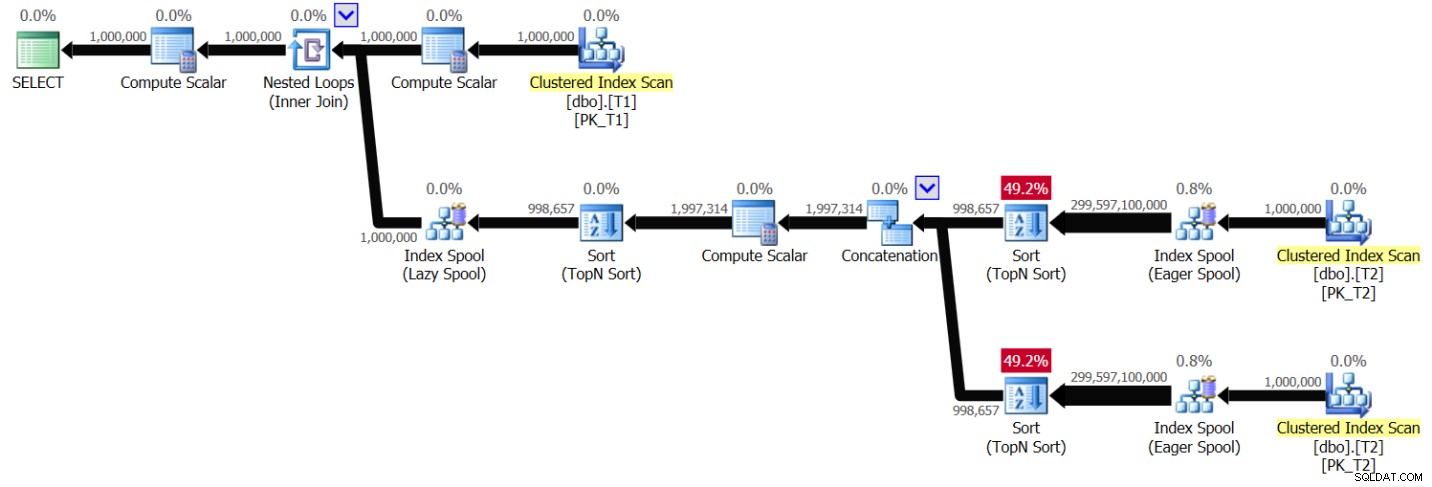 Figura 6:Piano per la Soluzione 2, senza indicizzazione, con intervallo di valori 1 – 1.000.000
Figura 6:Piano per la Soluzione 2, senza indicizzazione, con intervallo di valori 1 – 1.000.000
È possibile visualizzare uno schema molto simile a quello mostrato in precedenza nella Figura 1, solo che questa volta il piano esegue la scansione di T2 due volte per valore T1.val distinto. Anche in questo caso, la complessità del piano diventa quadratica. L'esecuzione della query in SSMS con Includi statistiche query in tempo reale abilitata ha richiesto 49,6 secondi per elaborare 100 righe da T1 sul mio laptop, il che significa che dovrebbero essere necessari circa 5,7 giorni per completare questa query. Questo potrebbe ovviamente significare una buona notizia se stai cercando di battere il Guinness dei primati per il binge-watching di un piano di query dal vivo.
Conclusione
Vorrei ringraziare Karen Ly di RBC per avermi presentato questa bella sfida per il match più vicino. Sono rimasto piuttosto colpito dal suo codice per gestirlo, che includeva molta logica extra specifica per il suo sistema. In questo articolo ho mostrato soluzioni ragionevolmente performanti quando sei in grado di creare indici di supporto ottimali. Ma come puoi vedere, nei casi in cui questa non è un'opzione, ovviamente i tempi di esecuzione che ottieni sono terribili. Riuscite a pensare a soluzioni che funzioneranno bene anche senza indici di supporto ottimali? Continua...