Nel 2013, ho scritto di un bug nell'ottimizzatore in cui il 2° e il 3° argomento di DATEDIFF() può essere scambiato, il che può portare a stime errate del conteggio delle righe e, a sua volta, a una scarsa selezione del piano di esecuzione:
- Sorprese e presupposti della performance:DATEDIFF
Lo scorso fine settimana, ho appreso di una situazione simile e ho immediatamente ipotizzato che si trattasse dello stesso problema. Dopotutto, i sintomi sembravano quasi identici:
- C'era una funzione data/ora in
WHEREclausola.- Questa volta era
DATEADD()invece diDATEDIFF().
- Questa volta era
- C'era una stima del conteggio delle righe ovviamente errata di 1, rispetto a un conteggio delle righe effettivo di oltre 3 milioni.
- Questa era in realtà una stima di 0, ma SQL Server arrotonda sempre tali stime a 1.
- È stata effettuata una selezione del piano scadente (in questo caso è stato scelto un loop join) a causa della stima bassa.
Lo schema offensivo era simile a questo:
WHERE [datetime2(7) column] >= DATEADD(DAY, -365, SYSUTCDATETIME());
L'utente ha provato diverse varianti, ma non è cambiato nulla; alla fine sono riusciti a aggirare il problema modificando il predicato in:
WHERE DATEDIFF(DAY, [column], SYSUTCDATETIME()) <= 365;
Questo ha ottenuto una stima migliore (la tipica ipotesi di disuguaglianza del 30%); quindi non del tutto giusto. E mentre ha eliminato il loop join, ci sono due problemi principali con questo predicato:
- Non lo è non la stessa query, poiché ora sta cercando il superamento dei limiti di 365 giorni, invece di essere maggiore di un momento specifico di 365 giorni fa. Statisticamente significante? Forse no. Ma sill, tecnicamente, non è lo stesso.
- L'applicazione della funzione sulla colonna rende l'intera espressione non sargable, portando a una scansione completa. Quando la tabella contiene solo poco più di un anno di dati, non è un grosso problema, ma man mano che la tabella diventa più grande o il predicato si restringe, questo diventerà un problema.
Ancora una volta, sono giunto alla conclusione che DATEADD() l'operazione era il problema e consigliava un approccio che non si basasse su DATEADD() – costruendo un datetime da tutte le parti dell'ora corrente, permettendomi di sottrarre un anno senza usare DATEADD() :
WHERE [column] >= DATETIMEFROMPARTS(
DATEPART(YEAR, SYSUTCDATETIME())-1,
DATEPART(MONTH, SYSUTCDATETIME()),
DATEPART(DAY, SYSUTCDATETIME()),
DATEPART(HOUR, SYSUTCDATETIME()),
DATEPART(MINUTE, SYSUTCDATETIME()),
DATEPART(SECOND, SYSUTCDATETIME()), 0); Oltre ad essere ingombrante, questo aveva alcuni problemi, vale a dire che sarebbe stato necessario aggiungere un po 'di logica per tenere adeguatamente conto degli anni bisestili. Primo, in modo che non fallisca se accade il 29 febbraio, e secondo, per includere esattamente 365 giorni in tutti i casi (invece di 366 durante l'anno successivo a un giorno bisestile). Correzioni facili, ovviamente, ma rendono la logica molto più brutta, soprattutto perché la query doveva esistere all'interno di una vista, dove non sono possibili variabili intermedie e passaggi multipli.
Nel frattempo, l'OP ha archiviato un articolo Connect, costernato dalla stima di 1 riga:
- Collega #2567628 :Vincolo con DateAdd() che non fornisce buone stime
Poi è arrivato Paul White (@SQL_Kiwi) e, come molte altre volte, ha fatto luce sul problema. Ha condiviso un articolo Connect correlato archiviato da Erland Sommarskog nel 2011:
- Connect #685903 :Stima errata quando sysdatetime appare in un'espressione dateadd()
In sostanza, il problema è che è possibile fare una stima scadente non semplicemente quando SYSDATETIME() (o SYSUTCDATETIME() ) appare, come riportato originariamente da Erland, ma quando qualsiasi datetime2 espressione è coinvolta nel predicato (e forse solo quando DATEADD() si usa anche). E può andare in entrambi i modi, se scambiamo >= per <= , la stima diventa l'intera tabella, quindi sembra che l'ottimizzatore stia guardando il SYSDATETIME() value come costante e ignorando completamente qualsiasi operazione come DATEADD() che vengono eseguiti contro di esso.
Paul ha condiviso che la soluzione alternativa consiste semplicemente nell'usare un datetime equivalente durante il calcolo della data, prima di convertirla nel tipo di dati corretto. In questo caso, possiamo sostituire SYSUTCDATETIME() e cambialo in GETUTCDATE() :
WHERE [column] >= CONVERT(datetime2(7), DATEADD(DAY, -365, GETUTCDATE()));
Sì, questo si traduce in una piccola perdita di precisione, ma anche una particella di polvere potrebbe rallentare il tuo dito mentre preme il

Le letture sono simili perché la tabella contiene dati quasi esclusivamente dell'anno passato, quindi anche una ricerca diventa una scansione dell'intervallo della maggior parte della tabella. I conteggi delle righe non sono identici perché (a) la seconda query si interrompe a mezzanotte e (b) la terza query include un giorno in più di dati a causa del giorno bisestile all'inizio di quest'anno. In ogni caso, questo dimostra ancora come possiamo avvicinarci a stime corrette eliminando DATEADD() , ma la soluzione corretta è rimuovere la combinazione diretta di DATEADD() e datetime2 .
Per illustrare ulteriormente come le stime stiano sbagliando, puoi vedere che se passiamo argomenti e direzioni diversi alla query originale e la riscrittura di Paul, il numero di righe stimate per la prima è sempre basato sull'ora corrente:non 'non cambia con il numero di giorni trascorsi (mentre quello di Paul è ogni volta relativamente preciso):
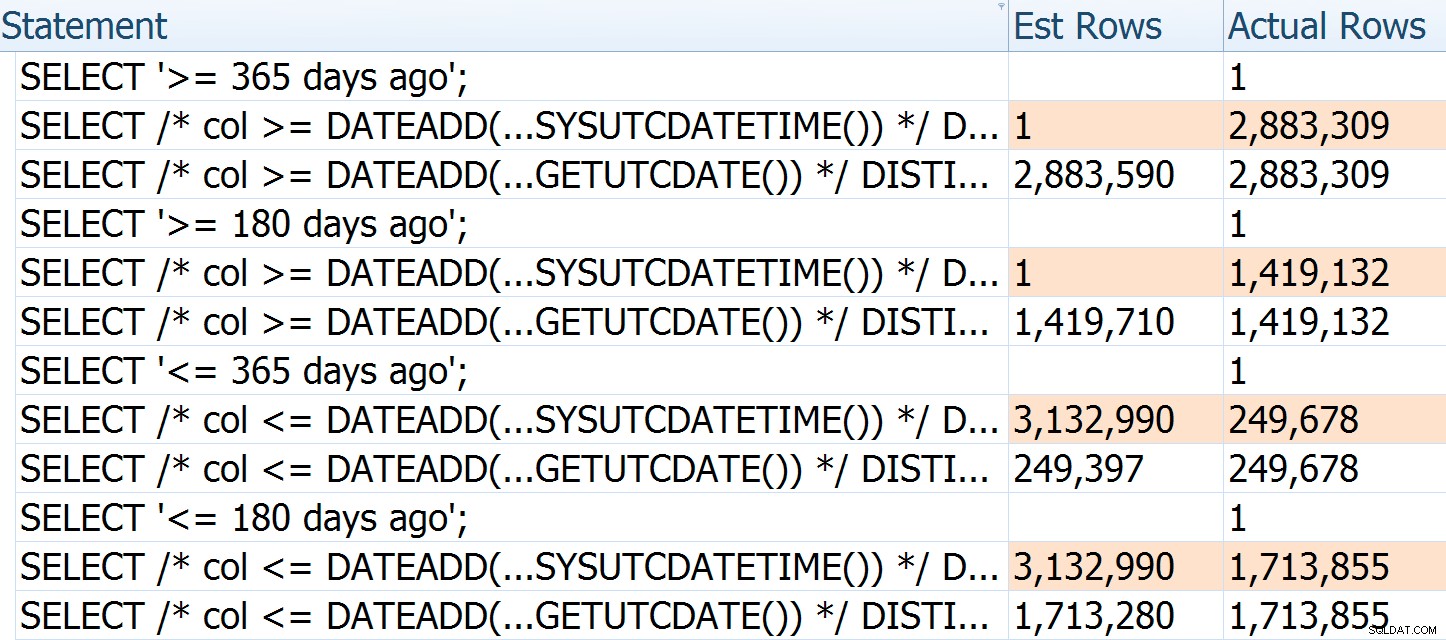 Le righe effettive per la prima query sono leggermente inferiori perché questa è stata eseguita dopo un lungo pisolino
Le righe effettive per la prima query sono leggermente inferiori perché questa è stata eseguita dopo un lungo pisolino
Le stime non saranno sempre così buone; la mia tabella ha solo una distribuzione relativamente stabile. L'ho popolato con la seguente query e quindi ho aggiornato le statistiche con la scansione completa, nel caso tu voglia provarlo da solo:
-- OP's table definition:
CREATE TABLE dbo.DateaddRepro
(
SessionId int IDENTITY(1, 1) NOT NULL PRIMARY KEY,
CreatedUtc datetime2(7) NOT NULL DEFAULT SYSUTCDATETIME()
);
GO
CREATE NONCLUSTERED INDEX [IX_User_Session_CreatedUtc]
ON dbo.DateaddRepro(CreatedUtc) INCLUDE (SessionId);
GO
INSERT dbo.DateaddRepro(CreatedUtc)
SELECT dt FROM
(
SELECT TOP (3150000) dt = DATEADD(HOUR, (s1.[precision]-ROW_NUMBER()
OVER (PARTITION BY s1.[object_id] ORDER BY s2.[object_id])) / 15, GETUTCDATE())
FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2
) AS x;
UPDATE STATISTICS dbo.DateaddRepro WITH FULLSCAN;
SELECT DISTINCT SessionId FROM dbo.DateaddRepro
WHERE /* pick your WHERE clause to test */; Ho commentato il nuovo elemento Connect e probabilmente tornerò indietro e ritoccherò la mia risposta di Stack Exchange.
La morale della favola
Cerca di evitare di combinare DATEADD() con espressioni che producono datetime2 , in particolare su versioni precedenti di SQL Server (questo era su SQL Server 2012). Può anche essere un problema, anche in SQL Server 2016, quando si usa il modello di stima della cardinalità precedente (a causa del livello di compatibilità inferiore o dell'uso esplicito del flag di traccia 9481). Problemi come questo sono sottili e non sempre immediatamente evidenti, quindi spero che questo serva da promemoria (forse anche per me la prossima volta che mi imbatterò in uno scenario simile). Come ho suggerito nell'ultimo post, se hai modelli di query come questo, controlla di ricevere stime corrette e prendi nota da qualche parte per ricontrollarle ogni volta che qualcosa di importante cambia nel sistema (come un aggiornamento o un service pack).