Di recente ho scritto un post su DISTINCT e GROUP BY. È stato un confronto che ha mostrato che GROUP BY è generalmente un'opzione migliore di DISTINCT. È su un sito diverso, ma assicurati di tornare su sqlperformance.com subito dopo..
Uno dei confronti di query che ho mostrato in quel post era tra GROUP BY e DISTINCT per una sottoquery, mostrando che DISTINCT è molto più lento, perché deve recuperare il nome del prodotto per ogni riga nella tabella Sales, piuttosto che solo per ogni diverso ProductID. Questo è abbastanza chiaro dai piani di query, dove puoi vedere che nella prima query, Aggregate opera sui dati di una sola tabella, piuttosto che sui risultati del join. Oh, ed entrambe le query danno le stesse 266 righe.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

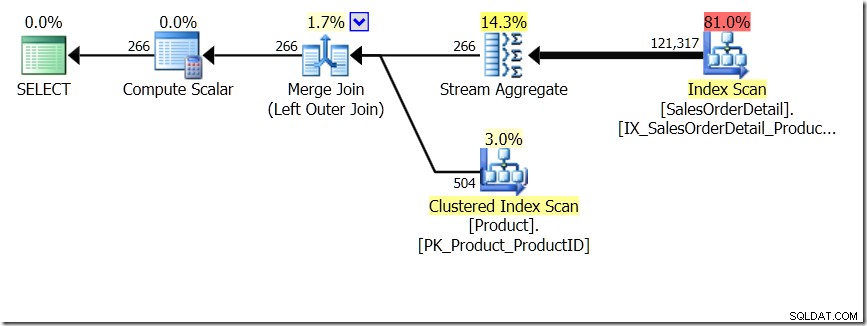
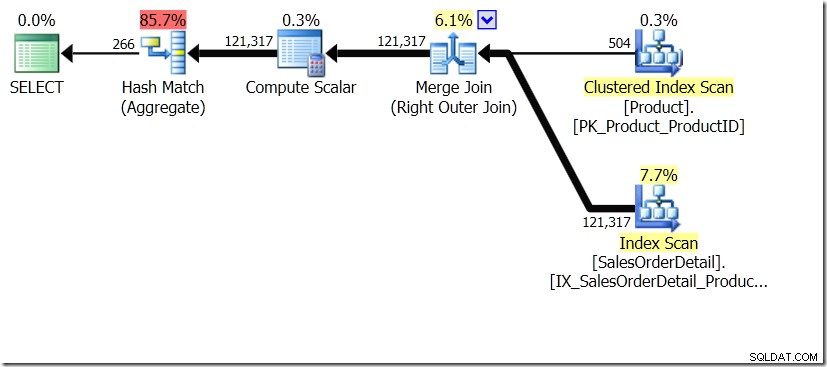
Ora, è stato sottolineato, anche da Adam Machanic (@adammachanic) in un tweet che fa riferimento al post di Aaron su GROUP BY v DISTINCT che le due query sono essenzialmente diverse, che in realtà si chiede l'insieme di combinazioni distinte sui risultati del sottoquery, piuttosto che eseguire la sottoquery sui valori distinti che vengono passati. È ciò che vediamo nel piano ed è il motivo per cui le prestazioni sono così diverse.
Il fatto è che tutti noi assumiamo che i risultati saranno identici.
Ma questa è un'ipotesi e non è buona.
Immagino per un momento che Query Optimizer abbia escogitato un piano diverso. Ho usato suggerimenti per questo, ma come saprai, Query Optimizer può scegliere di creare piani in tutti i tipi di forme per tutti i tipi di motivi.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
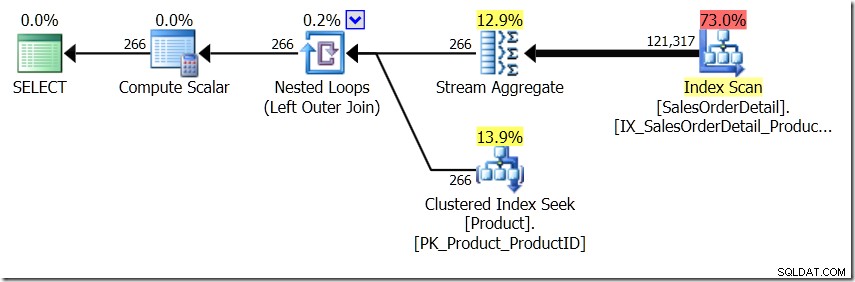
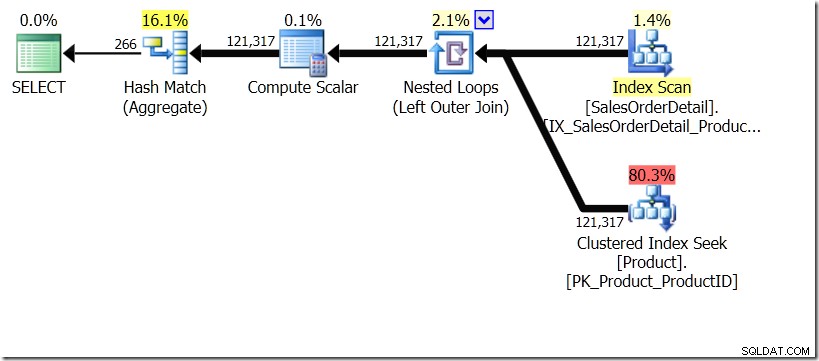
In questa situazione, eseguiamo 266 ricerche nella tabella Product, una per ogni ProductID diverso a cui siamo interessati, oppure 121.317 ricerche. Quindi, se stiamo pensando a un particolare ProductID, sappiamo che otterremo un singolo nome dal primo. E assumiamo che otterremo un singolo nome per quel ProductID, anche se dobbiamo chiederlo centinaia di volte. Partiamo dal presupposto che otterremo gli stessi risultati.
Ma cosa succede se non lo facciamo?
Sembra una cosa del livello di isolamento, quindi usiamo NOLOCK quando raggiungiamo la tabella dei prodotti. E lanciamo (in una finestra diversa) uno script che cambia il testo nelle colonne Nome. Lo farò più e più volte, per cercare di ottenere alcune delle modifiche tra le mie query.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Ora, i miei risultati sono diversi. I piani sono gli stessi (tranne per il numero di righe che escono dall'Hash Aggregate nella seconda query), ma i miei risultati sono diversi.
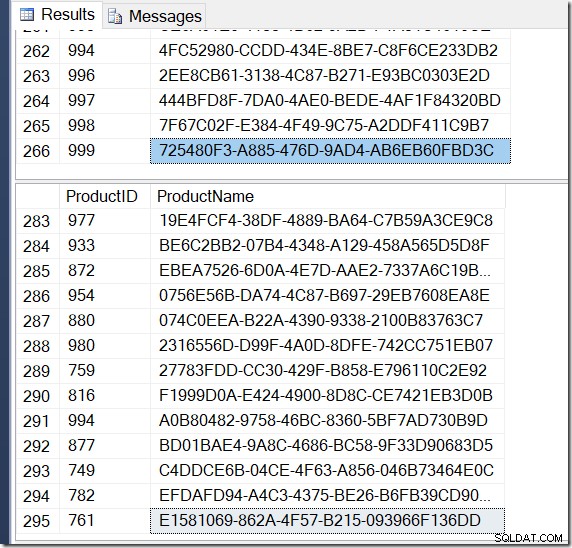
Abbastanza sicuro, ho più righe con DISTINCT, perché trova valori Name diversi per lo stesso ProductID. E non ho necessariamente 295 righe. Un altro lo eseguo, potrei ottenere 273 o 300 o forse 121.317.
Non è difficile trovare un esempio di ProductID che mostri più valori di nome, a conferma di cosa sta succedendo.

Chiaramente, per assicurarci di non vedere queste righe nei risultati, dovremmo NON utilizzare DISTINCT, oppure utilizzare un livello di isolamento più rigoroso.
Il fatto è che, sebbene abbia menzionato l'utilizzo di NOLOCK per questo esempio, non ne avevo bisogno. Questa situazione si verifica anche con READ COMMITTED, che è il livello di isolamento predefinito su molti sistemi SQL Server.
Vedete, abbiamo bisogno del livello di isolamento REPEATABLE READ per evitare questa situazione, per mantenere i blocchi su ogni riga una volta che è stata letta. In caso contrario, un thread separato potrebbe modificare i dati, come abbiamo visto.
Ma... non posso mostrarti che i risultati sono stati corretti, perché non sono riuscito a evitare un deadlock sulla query.
Quindi cambiamo le condizioni, assicurandoci che l'altra nostra query sia meno problematica. Invece di aggiornare l'intera tabella alla volta (cosa molto meno probabile nel mondo reale), aggiorniamo semplicemente una singola riga alla volta.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Ora, possiamo ancora dimostrare il problema con un livello di isolamento minore, come READ COMMITTED o READ UNCOMMITTED (sebbene potrebbe essere necessario eseguire la query più volte se si ottiene 266 la prima volta, perché la possibilità di aggiornare una riga durante la query è inferiore), e ora possiamo dimostrare che REPEATABLE READ lo risolve (non importa quante volte eseguiamo la query).
LETTURA RIPETIBILE fa quello che dice sulla latta. Dopo aver letto una riga all'interno di una transazione, è bloccata per assicurarti di poter ripetere la lettura e ottenere gli stessi risultati. I livelli di isolamento minori non eliminano quei blocchi finché non si tenta di modificare i dati. Se il tuo piano di query non ha mai bisogno di ripetere una lettura (come nel caso della forma dei nostri piani GROUP BY), non avrai bisogno di LETTURA RIPETIBILE.
Probabilmente, dovremmo sempre usare i livelli di isolamento più elevati, come LETTURA RIPETIBILE o SERIALIZABLE, ma tutto si riduce a capire di cosa hanno bisogno i nostri sistemi. Questi livelli possono introdurre un blocco indesiderato e i livelli di isolamento SNAPSHOT richiedono un controllo delle versioni che ha anche un prezzo. Per me, penso che sia un compromesso. Se sto chiedendo una query che potrebbe essere influenzata dalla modifica dei dati, potrebbe essere necessario aumentare il livello di isolamento per un po'.
Idealmente, semplicemente non aggiorni i dati che sono stati appena letti e potrebbero dover essere letti di nuovo durante la query, in modo da non aver bisogno di REPEATABLE READ. Ma vale sicuramente la pena capire cosa può succedere e riconoscere che questo è il tipo di scenario in cui DISTINCT e GROUP BY potrebbero non essere la stessa cosa.
@rob_farley