Quando si esaminano le prestazioni delle query, ci sono molte ottime fonti di informazioni all'interno di SQL Server e uno dei miei preferiti è il piano di query stesso. Nelle ultime versioni, in particolare a partire da SQL Server 2012, ogni nuova versione ha incluso maggiori dettagli nei piani di esecuzione. Mentre l'elenco dei miglioramenti continua a crescere, ecco alcuni attributi che ho trovato preziosi:
- NonParallelPlanReason (SQL Server 2012)
- Diagnostica pushdown predicato residuo (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Diagnostica di spill tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Flag di traccia abilitati (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Statistiche sull'esecuzione delle query dell'operatore (SQL Server 2014 SP2, SQL Server 2016)
- Memoria massima abilitata per una singola query (SQL Server 2014 SP2, SQL Server 2016 SP1)
Per visualizzare ciò che esiste per ciascuna versione di SQL Server, visitare la pagina Schema Showplan, dove è possibile trovare lo schema per ciascuna versione da SQL Server 2005.
Per quanto ami tutti questi dati extra, è importante notare che alcune informazioni sono più rilevanti per un piano di esecuzione effettivo, rispetto a uno stimato (ad es. informazioni di spill tempdb). Alcuni giorni possiamo acquisire e utilizzare il piano effettivo per la risoluzione dei problemi, altre volte dobbiamo utilizzare il piano stimato. Molto spesso otteniamo quel piano stimato, il piano che è stato utilizzato potenzialmente per esecuzioni problematiche, dalla cache dei piani di SQL Server. E tirare i piani individuali è appropriato quando si sintonizza una query o un set o query specifici. Ma che dire di quando vuoi idee su dove concentrare i tuoi sforzi di ottimizzazione in termini di modelli?
La cache del piano di SQL Server è una fonte di informazioni prodigiosa quando si tratta di ottimizzazione delle prestazioni e non intendo semplicemente la risoluzione dei problemi e il tentativo di capire cosa è stato eseguito in un sistema. In questo caso, sto parlando di informazioni di mining dai piani stessi, che si trovano in sys.dm_exec_query_plan, archiviate come XML nella colonna query_plan.
Quando combini questi dati con le informazioni di sys.dm_exec_sql_text (in modo da poter visualizzare facilmente il testo della query) e sys.dm_exec_query_stats (statistiche di esecuzione), puoi improvvisamente iniziare a cercare non solo quelle query che colpiscono pesantemente o eseguono più frequentemente, ma quei piani che contengono un particolare tipo di join, o scansione dell'indice, o quelli che hanno il costo più alto. Questo è comunemente indicato come mining della cache del piano e ci sono diversi post sul blog che parlano di come farlo. Il mio collega, Jonathan Kehayias, dice che odia scrivere XML, ma ha diversi post con domande per il mining della cache del piano:
- Ottimizzazione della "soglia di costo per il parallelismo" dalla Plan Cache
- Trovare conversioni di colonne implicite nella cache dei piani
- Trovare quali query nella cache del piano utilizzano un indice specifico
- Analisi nella cache del piano SQL:ricerca di indici mancanti
- Trovare ricerche chiave all'interno della cache dei piani
Se non hai mai esplorato cosa c'è nella cache del tuo piano, le query in questi post sono un buon inizio. Tuttavia, la cache del piano ha i suoi limiti. Ad esempio, è possibile eseguire una query senza che il piano vada nella cache. Se, ad esempio, hai abilitato l'opzione di ottimizzazione per carichi di lavoro ad hoc, alla prima esecuzione lo stub del piano compilato viene archiviato nella cache del piano, non il piano compilato completo. Ma la sfida più grande è che la cache del piano è temporanea. Esistono molti eventi in SQL Server che possono svuotare completamente la cache dei piani o cancellarla per un database e i piani possono essere obsoleti dalla cache se non utilizzati o rimossi dopo una ricompilazione. Per combattere questo, in genere è necessario interrogare regolarmente la cache del piano o eseguire uno snapshot del contenuto in una tabella su base pianificata.
Ciò cambia in SQL Server 2016 con Query Store.
Quando un database utente ha Query Store abilitato, il testo e i piani per le query eseguite su quel database vengono acquisiti e conservati nelle tabelle interne. Piuttosto che una visione temporanea di ciò che è attualmente in esecuzione, abbiamo un quadro a lungo termine di ciò che è stato eseguito in precedenza. La quantità di dati conservati è determinata dall'impostazione CLEANUP_POLICY, che per impostazione predefinita è 30 giorni. Rispetto a una cache dei piani che può rappresentare solo poche ore di esecuzione di query, i dati di Query Store sono un punto di svolta.
Considera uno scenario in cui stai eseguendo un'analisi dell'indice:alcuni indici non vengono utilizzati e alcuni consigli dai DMV dell'indice mancanti. Le DMV dell'indice mancanti non forniscono alcun dettaglio su quale query ha generato la raccomandazione sull'indice mancante. Puoi interrogare la cache del piano, usando la query del post di Jonathan Finding Missing Indexes. Se lo eseguo sulla mia istanza di SQL Server locale, ottengo un paio di righe di output relative ad alcune query eseguite in precedenza.

Posso aprire il piano in Plan Explorer e vedo che c'è un avviso sull'operatore SELECT, che è per l'indice mancante:
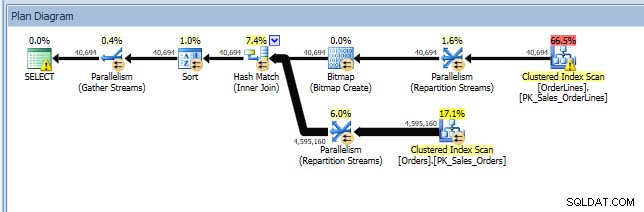
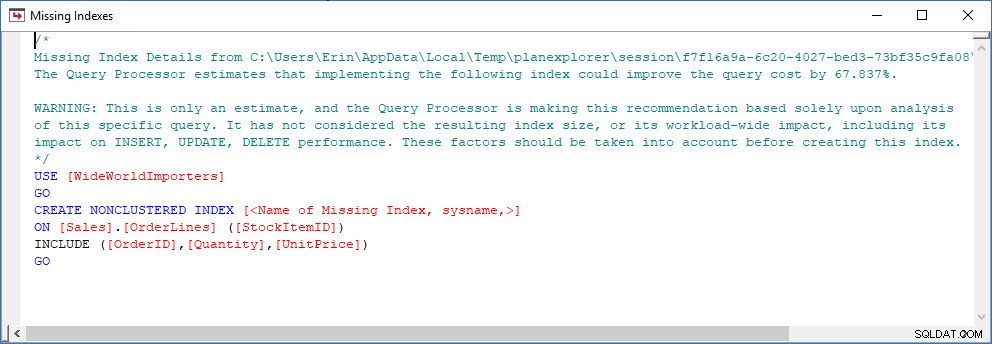
Questo è un ottimo inizio, ma ancora una volta, il mio output dipende da tutto ciò che è nella cache. Posso prendere la query di Jonathan e modificarla per Query Store, quindi eseguirla sul mio database demo WideWorldImporters:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
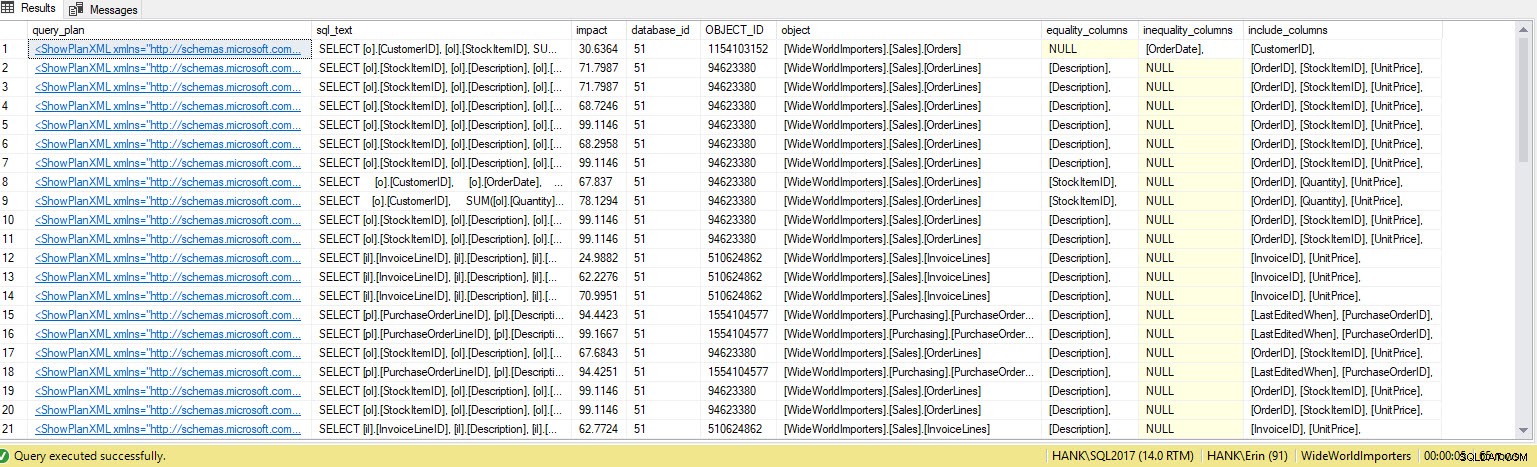
Ottengo molte più righe nell'output. Anche in questo caso, i dati di Query Store rappresentano una visione più ampia delle query eseguite sul sistema e l'utilizzo di questi dati fornisce un metodo completo per determinare non solo quali indici mancano, ma anche quali query sarebbero supportate da tali indici. Da qui, possiamo approfondire il Query Store ed esaminare le metriche delle prestazioni e la frequenza di esecuzione per comprendere l'impatto della creazione dell'indice e decidere se la query viene eseguita abbastanza spesso da giustificare l'indice.
Se non stai utilizzando Query Store, ma stai utilizzando SentryOne, puoi estrarre queste stesse informazioni dal database SentryOne. Il piano di query è archiviato nella tabella dbo.PerformanceAnalysisPlan in un formato compresso, quindi la query che utilizziamo è una variazione simile a quella sopra, ma noterai che viene utilizzata anche la funzione DECOMPRESS:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; Su un sistema SentryOne ho avuto il seguente output (e ovviamente facendo clic su uno qualsiasi dei valori di query_plan si aprirà il piano grafico):

Un paio di vantaggi offerti da SentryOne rispetto a Query Store è che non è necessario abilitare questo tipo di raccolta per database e il database monitorato non deve supportare i requisiti di archiviazione, poiché tutti i dati sono archiviati nel repository. Puoi anche acquisire queste informazioni in tutte le versioni supportate di SQL Server, non solo in quelle che supportano Query Store. Si noti tuttavia che SentryOne raccoglie solo query che superano soglie come durata e letture. È possibile modificare queste soglie predefinite, ma è un elemento da tenere presente durante l'estrazione del database SentryOne:non tutte le query potrebbero essere raccolte. Inoltre, la funzione DECOMPRESS non è disponibile fino a SQL Server 2016; per le versioni precedenti di SQL Server, vorrai:
- Esegui il backup del database SentryOne e ripristinalo su SQL Server 2016 o versioni successive per eseguire le query;
- bcp i dati fuori dalla tabella dbo.PerformanceAnalysisPlan e importali in una nuova tabella su un'istanza di SQL Server 2016;
- interroga il database SentryOne tramite un server collegato da un'istanza di SQL Server 2016; o,
- interroga il database dal codice dell'applicazione che può analizzare cose specifiche dopo la decompressione.
Con SentryOne, hai la possibilità di estrarre non solo la cache del piano, ma anche i dati conservati all'interno del repository SentryOne. Se stai utilizzando SQL Server 2016 o versioni successive e hai attivato Query Store, puoi trovare queste informazioni anche in sys.query_store_plan . Non sei limitato a questo esempio di ricerca di indici mancanti; tutte le query dagli altri post della cache del piano di Jonathan possono essere modificate per essere utilizzate per estrarre dati da SentryOne o da Query Store. Inoltre, se hai abbastanza familiarità con XQuery (o hai voglia di imparare), puoi utilizzare lo Schema Showplan per capire come analizzare il piano per trovare le informazioni che desideri. Ciò ti dà la possibilità di trovare modelli e anti-modelli nei piani di query che il tuo team può risolvere prima che diventino un problema.