Quando SQL Server ottimizza una query, durante una fase di esplorazione produce piani candidati e sceglie tra essi quello con il costo più basso. Il piano scelto dovrebbe avere il tempo di esecuzione più basso tra i piani esplorati. Il fatto è che l'ottimizzatore può scegliere solo tra le strategie che sono state codificate in esso. Ad esempio, quando si ottimizza il raggruppamento e l'aggregazione, alla data in cui scrivo, l'ottimizzatore può scegliere solo tra le strategie Stream Aggregate e Hash Aggregate. Ho trattato le strategie disponibili nelle parti precedenti di questa serie. Nella Parte 1 ho trattato la strategia Stream Aggregate preordinata, nella Parte 2 la strategia Sort + Stream Aggregate, nella Parte 3 la strategia Hash Aggregate e nella Parte 4 considerazioni sul parallelismo.
Ciò che l'ottimizzatore di SQL Server attualmente non supporta è la personalizzazione e l'intelligenza artificiale. Cioè, se riesci a capire una strategia che in determinate condizioni è più ottimale di quelle supportate dall'ottimizzatore, non puoi potenziare l'ottimizzatore per supportarlo e l'ottimizzatore non può imparare a usarlo. Tuttavia, ciò che puoi fare è riscrivere la query utilizzando elementi di query alternativi che possono essere ottimizzati con la strategia che hai in mente. In questa quinta e ultima parte della serie dimostrerò questa tecnica di ottimizzazione delle query utilizzando le revisioni delle query.
Grazie mille a Paul White (@SQL_Kiwi) per aver aiutato con alcuni dei calcoli dei costi presentati in questo articolo!
Come nelle parti precedenti della serie, utilizzerò il database di esempio PerformanceV3. Utilizza il codice seguente per eliminare gli indici non necessari dalla tabella Ordini:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Strategia di ottimizzazione predefinita
Considera le seguenti attività di raggruppamento e aggregazione di base:
Restituisci la data massima dell'ordine per ciascun mittente, dipendente e cliente.
Per prestazioni ottimali, crei i seguenti indici di supporto:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate); CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate); CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
Di seguito sono elencate le tre query che utilizzeresti per gestire queste attività, insieme ai costi stimati dei sottoalbero, nonché alle statistiche di I/O, CPU e tempo trascorso:
-- Query 1 -- Estimated Subtree Cost: 3.5344 -- logical reads: 2484, CPU time: 281 ms, elapsed time: 279 ms SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid; -- Query 2 -- Estimated Subtree Cost: 3.62798 -- logical reads: 2610, CPU time: 250 ms, elapsed time: 283 ms SELECT empid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY empid; -- Query 3 -- Estimated Subtree Cost: 4.27624 -- logical reads: 3479, CPU time: 406 ms, elapsed time: 506 ms SELECT custid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY custid;
La figura 1 mostra i piani per queste query:
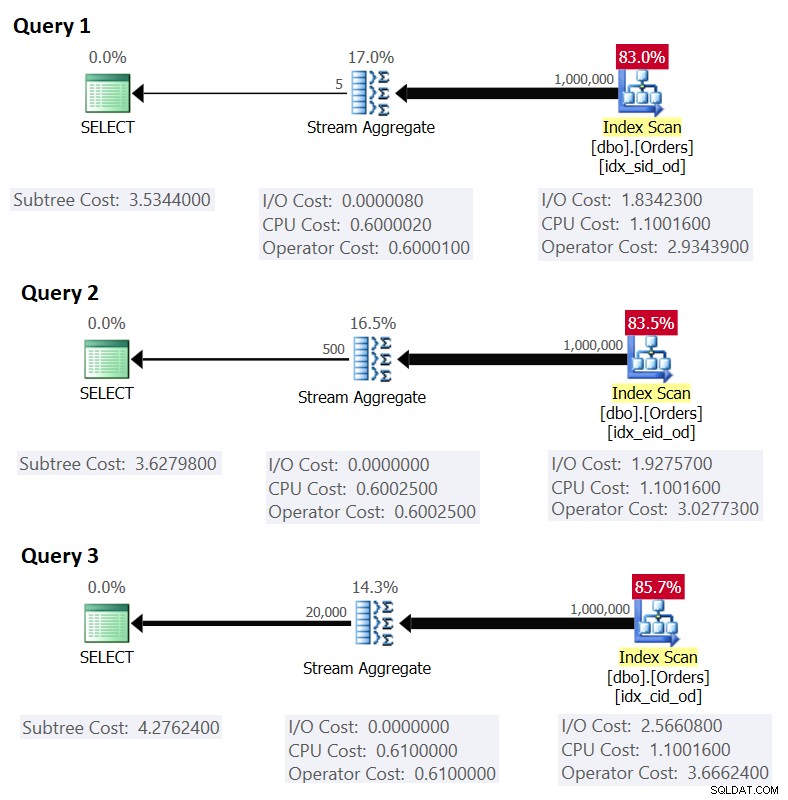 Figura 1:piani per query raggruppate
Figura 1:piani per query raggruppate
Ricordiamo che se si dispone di un indice di copertura, con le colonne del gruppo di impostazioni come colonne chiave iniziali, seguite dalla colonna di aggregazione, è probabile che SQL Server scelga un piano che esegua un'analisi ordinata dell'indice di copertura che supporta la strategia Stream Aggregate . Come è evidente nei piani della Figura 1, l'operatore Index Scan è responsabile della maggior parte del costo del piano e al suo interno la parte I/O è la più importante.
Prima di presentare una strategia alternativa e spiegare le circostanze in cui è più ottimale della strategia predefinita, valutiamo il costo della strategia esistente. Poiché la parte di I/O è la più dominante nel determinare il costo del piano di questa strategia predefinita, per prima cosa stimiamo solo quante letture di pagine logiche saranno necessarie. Successivamente stimeremo anche il costo del piano.
Per stimare il numero di letture logiche richieste dall'operatore di scansione dell'indice, è necessario sapere quante righe sono presenti nella tabella e quante righe si adattano a una pagina in base alla dimensione della riga. Una volta che hai questi due operandi, la tua formula per il numero di pagine richiesto nel livello foglia dell'indice è CEILING(1e0 * @numrows / @rowsperpage). Se tutto ciò che hai è solo la struttura della tabella e nessun dato di esempio esistente con cui lavorare, puoi usare questo articolo per stimare il numero di pagine che avresti nel livello foglia dell'indice di supporto. Se disponi di buoni dati di esempio rappresentativi, anche se non nella stessa scala dell'ambiente di produzione, puoi calcolare il numero medio di righe che si adattano a una pagina eseguendo query sugli oggetti catalogo e gestione dinamica, in questo modo:
SELECT I.name, row_count, in_row_data_page_count,
CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage
FROM sys.indexes AS I
INNER JOIN sys.dm_db_partition_stats AS P
ON I.object_id = P.object_id
AND I.index_id = P.index_id
WHERE I.object_id = OBJECT_ID('dbo.Orders')
AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Questa query genera il seguente output nel nostro database di esempio:
name row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Ora che hai il numero di righe che si adattano a una pagina foglia dell'indice, puoi stimare il numero totale di pagine foglia nell'indice in base al numero di righe che ti aspetti che la tua tabella di produzione abbia. Questo sarà anche il numero previsto di letture logiche da applicare dall'operatore di scansione dell'indice. In pratica, c'è di più nel numero di letture che potrebbero aver luogo oltre al semplice numero di pagine nel livello foglia dell'indice, come letture extra prodotte dal meccanismo di lettura in anticipo, ma le ignorerò per mantenere semplice la nostra discussione .
Ad esempio, il numero stimato di letture logiche per la query 1 rispetto al numero previsto di righe è CEILING(1e0 * @numorws / 404). Con 1.000.000 di righe, il numero previsto di letture logiche è 2476. La differenza tra 2476 e il conteggio delle pagine di riga riportato di 2473 può essere attribuita all'arrotondamento che ho eseguito durante il calcolo del numero medio di righe per pagina.
Per quanto riguarda il costo del piano, ho spiegato come decodificare il costo dell'operatore Stream Aggregate nella Parte 1 della serie. In modo simile, puoi decodificare il costo dell'operatore Index Scan. Il costo del piano è quindi la somma dei costi degli operatori Index Scan e Stream Aggregate.
Per calcolare il costo dell'operatore Index Scan, vuoi iniziare con il reverse engineering di alcune delle importanti costanti del modello di costo:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Dopo aver individuato le costanti del modello di costo sopra, puoi procedere al reverse engineering delle formule per il costo di I/O, il costo della CPU e il costo totale dell'operatore per l'operatore di scansione dell'indice:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.003125 + (@numpages - 1e0) * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011 Operator cost: 0.002541259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000011
Ad esempio, il costo dell'operatore Scansione indice per la query 1, con 2473 pagine e 1.000.000 di righe, è:
0.002541259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000011 = 2.93439
Di seguito è riportata la formula di reverse engineering per il costo dell'operatore Stream Aggregate:
0.000008 + @numrows * 0.0000006 + @numgroups * 0.0000005
Ad esempio, per la query 1 abbiamo 1.000.000 di righe e 5 gruppi, quindi il costo stimato è 0,6000105.
Combinando i costi dei due operatori, ecco la formula per l'intero costo del piano:
0.002549259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Per la query 1, con 2473 pagine, 1.000.000 di righe e 5 gruppi, ottieni:
0.002549259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5344
Ciò corrisponde a quanto mostrato nella Figura 1 come costo stimato per la query 1.
Se facessi affidamento su un numero stimato di righe per pagina, la tua formula sarebbe:
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Ad esempio, per la query 1, con 1.000.000 di righe, 404 righe per pagina e 5 gruppi, il costo stimato è:
0.002549259259259 + CEILING(1e0 * 1000000 / 404) * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5366
Come esercizio, puoi applicare i numeri per Query 2 (1.000.000 righe, 385 righe per pagina, 500 gruppi) e Query 3 (1.000.000 righe, 289 righe per pagina, 20.000 gruppi) nella nostra formula e vedere che i risultati corrispondono a quanto La figura 1 mostra.
Ottimizzazione delle query con riscritture delle query
La strategia Stream Aggregate predefinita per il calcolo di un aggregato MIN/MAX per gruppo si basa su una scansione ordinata di un indice di copertura di supporto (o su qualche altra attività preliminare che emette le righe ordinate). Una strategia alternativa, con un indice di copertura di supporto presente, sarebbe quella di eseguire una ricerca dell'indice per gruppo. Ecco una descrizione di uno pseudo piano basato su tale strategia per una query che raggruppa per grpcol e applica un MAX(aggcol):
set @curgrpcol = grpcol from first row obtained by a scan of the index, ordered forward;
while end of index not reached
begin
set @curagg = aggcol from row obtained by a seek to the last point
where grpcol = @curgrpcol, ordered backward;
emit row (@curgrpcol, @curagg);
set @curgrpcol = grpcol from row to the right of last row for current group;
end; Se ci pensi, la strategia predefinita basata sulla scansione è ottimale quando il gruppo di raggruppamento ha una densità bassa (numero elevato di gruppi, con un numero medio di righe per gruppo piccolo). La strategia basata sulle ricerche è ottimale quando l'insieme di raggruppamenti ha un'elevata densità (numero ridotto di gruppi, con un numero medio di righe per gruppo elevato). La figura 2 illustra entrambe le strategie che mostrano quando ciascuna è ottimale.
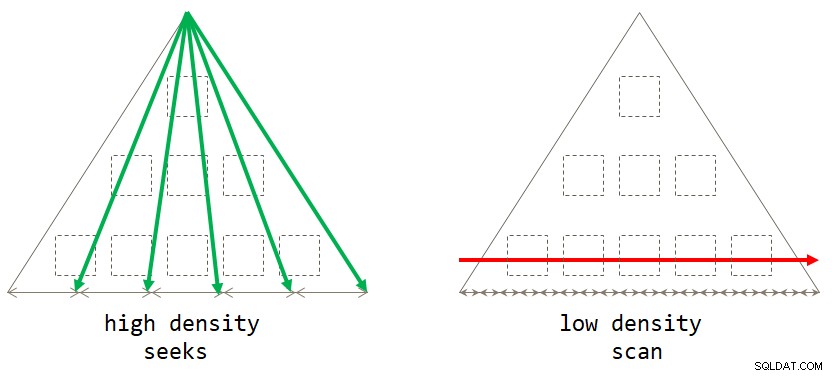 Figura 2:strategia ottimale in base alla densità degli insiemi di raggruppamento
Figura 2:strategia ottimale in base alla densità degli insiemi di raggruppamento
Finché si scrive la soluzione sotto forma di una query raggruppata, attualmente SQL Server prenderà in considerazione solo la strategia di scansione. Questo funzionerà bene per te quando il gruppo di raggruppamento ha una bassa densità. Quando hai un'alta densità, per ottenere la strategia di ricerca, dovrai applicare una riscrittura della query. Un modo per ottenere ciò è eseguire una query sulla tabella che contiene i gruppi e utilizzare una sottoquery di aggregazione scalare rispetto alla tabella principale per ottenere l'aggregazione. Ad esempio, per calcolare la data massima dell'ordine per ciascun mittente, dovresti utilizzare il seguente codice:
SELECT shipperid,
( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS maxod
FROM dbo.Shippers AS S; Le linee guida per l'indicizzazione della tabella principale sono le stesse a supporto della strategia predefinita. Disponiamo già di quegli indici per i tre compiti summenzionati. Probabilmente vorresti anche un indice di supporto sulle colonne del gruppo di raggruppamento nella tabella che contiene i gruppi per ridurre al minimo il costo di I/O rispetto a quella tabella. Utilizza il codice seguente per creare tali indici di supporto per le nostre tre attività:
CREATE INDEX idx_sid ON dbo.Shippers(shipperid); CREATE INDEX idx_eid ON dbo.Employees(empid); CREATE INDEX idx_cid ON dbo.Customers(custid);
Un piccolo problema, tuttavia, è che la soluzione basata sulla sottoquery non è un esatto equivalente logico della soluzione basata sulla query raggruppata. Se hai un gruppo senza presenza nella tabella principale, il primo restituirà il gruppo con un NULL come aggregato, mentre il secondo non restituirà affatto il gruppo. Un modo semplice per ottenere un vero equivalente logico della query raggruppata consiste nell'invocare la sottoquery utilizzando l'operatore CROSS APPLY nella clausola FROM invece di utilizzare una subquery scalare nella clausola SELECT. Ricorda che CROSS APPLY non restituirà una riga sinistra se la query applicata restituisce un set vuoto. Ecco le tre query di soluzione che implementano questa strategia per le nostre tre attività, insieme alle relative statistiche sulle prestazioni:
-- Query 4
-- Estimated Subtree Cost: 0.0072299
-- logical reads: 2 + 15, CPU time: 0 ms, elapsed time: 43 ms
SELECT S.shipperid, A.orderdate AS maxod
FROM dbo.Shippers AS S
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS A;
-- Query 5
-- Estimated Subtree Cost: 0.089694
-- logical reads: 2 + 1620, CPU time: 0 ms, elapsed time: 148 ms
SELECT E.empid, A.orderdate AS maxod
FROM dbo.Employees AS E
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.empid = E.empid
ORDER BY O.orderdate DESC ) AS A;
-- Query 6
-- Estimated Subtree Cost: 3.5227
-- logical reads: 45 + 63777, CPU time: 171 ms, elapsed time: 306 ms
SELECT C.custid, A.orderdate AS maxod
FROM dbo.Customers AS C
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC ) AS A; I piani per queste query sono mostrati nella Figura 3.
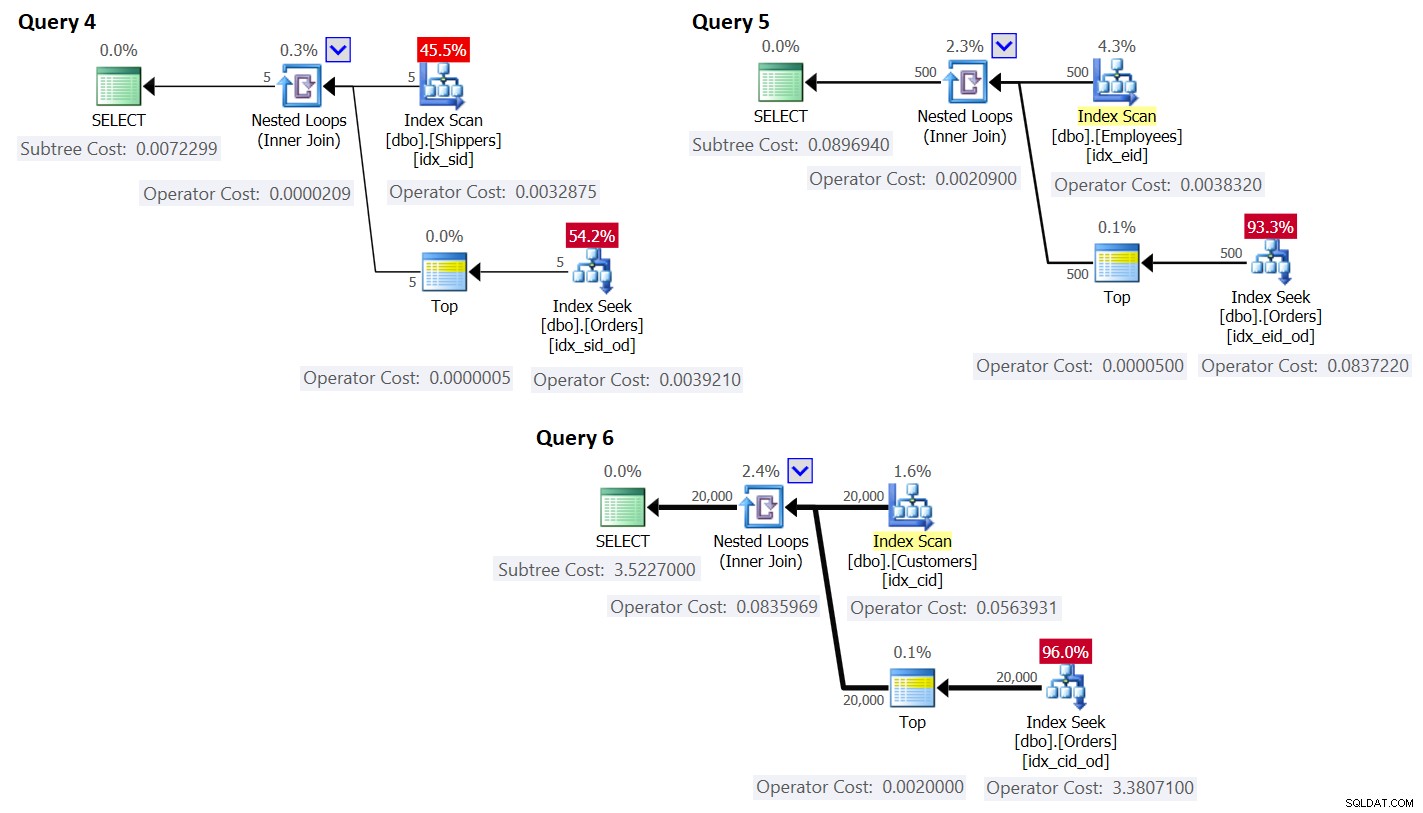 Figura 3:Piani per query con riscrittura
Figura 3:Piani per query con riscrittura
Come puoi vedere, i gruppi si ottengono scansionando l'indice sulla tabella dei gruppi e l'aggregato si ottiene applicando una ricerca nell'indice sulla tabella principale. Maggiore è la densità del set di raggruppamento, più ottimale è questo piano rispetto alla strategia predefinita per la query raggruppata.
Proprio come abbiamo fatto in precedenza per la strategia di scansione predefinita, stimiamo il numero di letture logiche e pianifichiamo il costo per la strategia di ricerca. Il numero stimato di letture logiche è il numero di letture per la singola esecuzione dell'operatore Index Scan che recupera i gruppi, più le letture per tutte le esecuzioni dell'operatore Index Seek.
Il numero stimato di letture logiche per l'operatore Index Scan è trascurabile rispetto alle ricerche; ancora, è CEILING(1e0 * @numgroups / @rowsperpage). Prendi la query 4 come esempio; supponiamo che l'indice idx_sid si adatti a circa 600 righe per pagina foglia (il numero effettivo dipende dai valori di shipperid effettivi poiché il tipo di dati è VARCHAR(5)). Con 5 gruppi, tutte le righe si adattano a una singola pagina foglia. Se avessi 5.000 gruppi, starebbero in 9 pagine.
Il numero stimato di letture logiche per tutte le esecuzioni dell'operatore Index Seek è @numgroups * @indexdepth. La profondità dell'indice può essere calcolata come:
CEILING(LOG(CEILING(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
Usando la query 4 come esempio, supponiamo che possiamo inserire circa 404 righe per pagina foglia dell'indice idx_sid_od e circa 352 righe per pagina non foglia. Anche in questo caso, i numeri effettivi dipenderanno dai valori effettivi memorizzati nella colonna shipperid poiché il suo tipo di dati è VARCHAR(5)). Per i preventivi, ricorda che puoi utilizzare i calcoli qui descritti. Con buoni dati di esempio rappresentativi disponibili, puoi utilizzare la query seguente per calcolare il numero di righe che possono rientrare nelle pagine foglia e non foglia dell'indice specificato:
SELECT
CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype,
FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage
FROM (SELECT *
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.Orders')
AND name = 'idx_sid_od') AS I
CROSS APPLY sys.dm_db_index_physical_stats
(DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P
WHERE P.index_level <= 1; Ho ottenuto il seguente output:
pagetype rowsperpage -------- ---------------------- leaf 404 nonleaf 352
Con questi numeri, la profondità dell'indice rispetto al numero di righe nella tabella è:
CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1
Con 1.000.000 di righe nella tabella, ciò si traduce in una profondità dell'indice di 3. A circa 50 milioni di righe, la profondità dell'indice aumenta a 4 livelli e a circa 17,62 miliardi di righe aumenta a 5 livelli.
In ogni caso, rispetto al numero di gruppi e al numero di righe, assumendo il numero di righe per pagina sopra indicato, la seguente formula calcola il numero stimato di letture logiche per la Query 4:
CEILING(1e0 * @numgroups / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)
Ad esempio, con 5 gruppi e 1.000.000 di righe, ottieni solo 16 letture in totale! Ricordiamo che la strategia predefinita basata sulla scansione per la query raggruppata prevede tante letture logiche quante CEILING(1e0 * @numrows / @rowsperpage). Utilizzando la query 1 come esempio e supponendo circa 404 righe per pagina foglia dell'indice idx_sid_od, con lo stesso numero di righe di 1.000.000, si ottengono circa 2.476 letture. Aumenta il numero di righe nella tabella di un fattore da 1.000 a 1.000.000.000, ma mantieni fisso il numero di gruppi. Il numero di letture richieste con la strategia di ricerca cambia molto poco a 21, mentre il numero di letture richieste con la strategia di scansione aumenta linearmente a 2.475.248.
Il bello della strategia di ricerca è che finché il numero di gruppi è piccolo e fisso, ha un ridimensionamento quasi costante rispetto al numero di righe nella tabella. Questo perché il numero di ricerche è determinato dal numero di gruppi e la profondità dell'indice si riferisce al numero di righe nella tabella in modo logaritmico in cui la base del registro è il numero di righe che si adattano a una pagina non foglia. Al contrario, la strategia basata sulla scansione ha un ridimensionamento lineare rispetto al numero di righe coinvolte.
La Figura 4 mostra il numero di letture stimato per le due strategie, applicato da Query 1 e Query 4, dato un numero fisso di gruppi di 5 e un numero diverso di righe nella tabella principale.
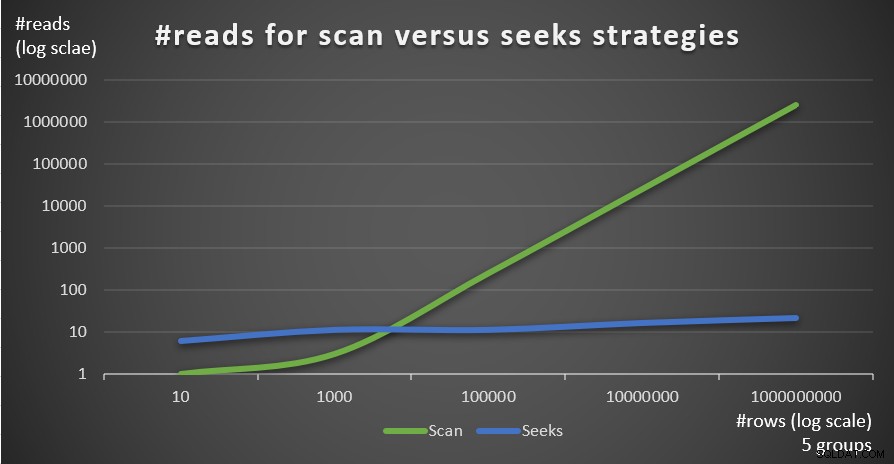 Figura 4:#reads per strategie di scansione e ricerca (5 gruppi)
Figura 4:#reads per strategie di scansione e ricerca (5 gruppi)
La figura 5 mostra il numero di letture stimato per le due strategie, dato un numero fisso di righe di 1.000.000 nella tabella principale e un numero diverso di gruppi.
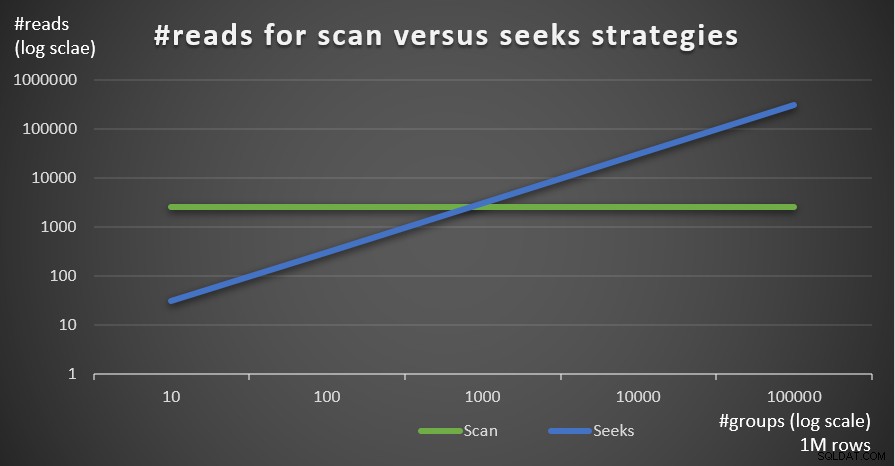 Figura 5:#reads per strategie di scansione e ricerca (1 milione di righe)
Figura 5:#reads per strategie di scansione e ricerca (1 milione di righe)
Puoi vedere molto chiaramente che maggiore è la densità dell'insieme di raggruppamento (minore numero di gruppi) e più grande è la tabella principale, più la strategia di ricerca è preferita in termini di numero di letture. Se ti stai chiedendo quale sia il modello di I/O utilizzato da ciascuna strategia; certo, le operazioni di ricerca dell'indice eseguono I/O casuali, mentre un'operazione di scansione dell'indice esegue I/O sequenziale. Tuttavia, è abbastanza chiaro quale strategia sia più ottimale nei casi più estremi.
Per quanto riguarda il costo del piano di query, ancora una volta, utilizzando il piano per la query 4 in Figura 3 come esempio, scomponiamolo ai singoli operatori del piano.
La formula di reverse engineering per il costo dell'operatore Index Scan è:
0.002541259259259 + @numpages * 0.000740740740741 + @numgroups * 0.0000011
Nel nostro caso, con 5 gruppi, che stanno tutti in una pagina, il costo è:
0.002541259259259 + 1 * 0.000740740740741 + 5 * 0.0000011 = 0.0032875
Il costo indicato nel piano è lo stesso.
Come prima, puoi stimare il numero di pagine nel livello foglia dell'indice in base al numero stimato di righe per pagina usando la formula CEILING(1e0 * @numrows / @rowsperpage), che nel nostro caso è CEILING(1e0 * @ numgroups / @groupsperpage). Supponiamo che l'indice idx_sid si adatti a circa 600 righe per pagina foglia, con 5 gruppi di cui avresti bisogno per leggere una pagina. In ogni caso, la formula di costo per l'operatore Index Scan diventa quindi:
0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011
La formula dei costi di reverse engineering per l'operatore Nested Loops è:
@executions * 0.00000418
Nel nostro caso, questo si traduce in:
@numgroups * 0.00000418
Per la query 4, con 5 gruppi, ottieni:
5 * 0.00000418 = 0.0000209
Il costo indicato nel piano è lo stesso.
La formula dei costi di reverse engineering per l'operatore Top è:
@executions * @toprows * 0.00000001
Nel nostro caso, questo si traduce in:
@numgroups * 1 * 0.00000001
Con 5 gruppi, ottieni:
5 * 0.0000001 = 0.0000005
Il costo indicato nel piano è lo stesso.
Per quanto riguarda l'operatore Index Seek, qui ho avuto un grande aiuto da Paul White; grazie amico mio! Il calcolo è diverso per la prima esecuzione e per i rebind (non prime esecuzioni che non riutilizzano il risultato dell'esecuzione precedente). Come abbiamo fatto con l'operatore Index Scan, iniziamo con l'identificazione delle costanti del modello di costo:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Per un'esecuzione, senza un obiettivo di riga applicato, i costi di I/O e CPU sono:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.002384259259259 + @numpages * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011
Poiché utilizziamo TOP (1) abbiamo solo una pagina e una riga coinvolta, quindi i costi sono:
I/O cost: 0.002384259259259 + 1 * 0.000740740740741 = 0.003125 CPU cost: 0.000157 + 1 * 0.0000011 = 0.0001581
Quindi il costo della prima esecuzione dell'operatore Index Seek nel nostro caso è:
@firstexecution = 0.003125 + 0.0001581 = 0.0032831
Per quanto riguarda il costo dei rebind, come al solito, è fatto di CPU e costi di I/O. Chiamiamoli rispettivamente @rebindcpu e @rebindio. Con Query 4, avendo 5 gruppi, abbiamo 4 rebind (chiamalo @rebinds). Il costo di @rebindcpu è la parte facile. La formula è:
@rebindcpu = @rebinds * (@cpubase + @cpurow)
Nel nostro caso, questo si traduce in:
@rebindcpu = 4 * (0.000157 + 0.0000011) = 0.0006324
La parte di @rebindio è leggermente più complessa. Qui, la formula di costo calcola, statisticamente, il numero previsto di pagine distinte che ci si aspetta che le rilegature leggano utilizzando il campionamento con sostituzione. Chiameremo questo elemento @pswr (per pagine distinte campionate con sostituzione). L'idea è che abbiamo @indexdatapages numero di pagine nell'indice (nel nostro caso, 2.473) e @rebinds numero di rebind (nel nostro caso, 4). Supponendo di avere la stessa probabilità di leggere una determinata pagina con ogni rilegatura, quante pagine distinte dovremmo leggere in totale? Questo è come avere una sacca con 2.473 palline, e quattro volte estrarre alla cieca una palla dalla sacca e poi rimetterla nella sacca. Statisticamente, quante palline distinte ti aspetti di estrarre in totale? La formula per questo, usando i nostri operandi, è:
@pswr = @indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))
Con i nostri numeri ottieni:
@pswr = 2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) = 3.99757445099277
Successivamente, calcoli il numero di righe e pagine che hai in media per gruppo:
@grouprows = @cardinality * @density @grouppages = CEILING(@indexdatapages * @density)
Nella nostra Query 4, la cardinalità è 1.000.000 e la densità è 1/5 =0,2. Quindi ottieni:
@grouprows = 1000000 * 0.2 = 200000 @numpages = CEILING(2473 * 0.2) = 495
Quindi calcoli il costo di I/O senza filtrare (chiamalo @io) come:
@io = @randomio + (@seqio * (@grouppages - 1e0))
Nel nostro caso, ottieni:
@io = 0.003125 + (0.000740740740741 * (495 - 1e0)) = 0.369050925926054
E infine, poiché la ricerca estrae solo una riga in ogni rebind, calcoli @rebindio usando la seguente formula:
@rebindio = (1e0 / @grouprows) * ((@pswr - 1e0) * @io)
Nel nostro caso, ottieni:
@rebindio = (1e0 / 200000) * ((3.99757445099277 - 1e0) * 0.369050925926054) = 0.000005531288
Infine, il costo dell'operatore è:
Operator cost: @firstexecution + @rebindcpu + @rebindio = 0.0032831 + 0.0006324 + 0.000005531288 = 0.003921031288
È lo stesso del costo dell'operatore di ricerca indice mostrato nel piano per la query 4.
È ora possibile aggregare i costi di tutti gli operatori per ottenere il costo completo del piano di query. Ottieni:
Query plan cost: 0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00000418
+ @numgroups * 0.00000001
+ 0.0032831 + (@numgroups - 1e0) * 0.0001581
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Dopo la semplificazione, ottieni la seguente formula di determinazione dei costi completa per la nostra strategia Seeks:
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Ad esempio, utilizzando T-SQL, ecco il calcolo del costo del piano di query con la nostra strategia Seeks per la query 4:
DECLARE
@numrows AS FLOAT = 1000000,
@numgroups AS FLOAT = 5,
@rowsperpage AS FLOAT = 404,
@groupsperpage AS FLOAT = 600;
SELECT
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0)))
AS seeksplancost; Questo calcolo calcola il costo 0,0072295 per la query 4. Il costo stimato mostrato nella Figura 3 è 0,0072299. È abbastanza vicino! Come esercizio, calcola i costi per Query 5 e Query 6 utilizzando questa formula e verifica di ottenere numeri vicini a quelli mostrati nella Figura 3.
Ricordiamo che la formula dei costi per la strategia predefinita basata sulla scansione è (chiamatela Scansione strategia):
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Utilizzando la query 1 come esempio e supponendo 1.000.000 di righe nella tabella, 404 righe per pagina e 5 gruppi, il costo stimato del piano di query della strategia di scansione è 3,5366.
La figura 6 mostra i costi stimati del piano di query per le due strategie, applicati da Query 1 (scansione) e Query 4 (ricerche), dato un numero fisso di gruppi di 5 e un numero diverso di righe nella tabella principale.
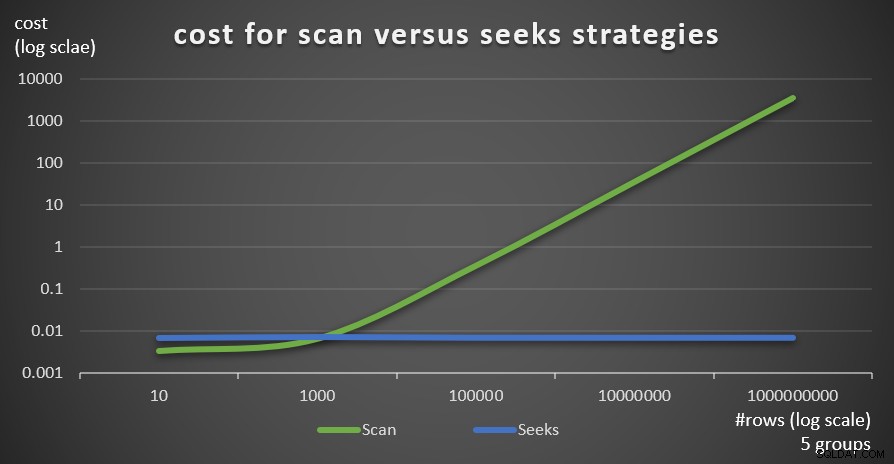 Figura 6:costo per strategie di scansione e ricerca (5 gruppi)
Figura 6:costo per strategie di scansione e ricerca (5 gruppi)
La Figura 7 mostra i costi stimati del piano di query per le due strategie, dato un numero fisso di righe nella tabella principale di 1.000.000 e un numero diverso di gruppi.
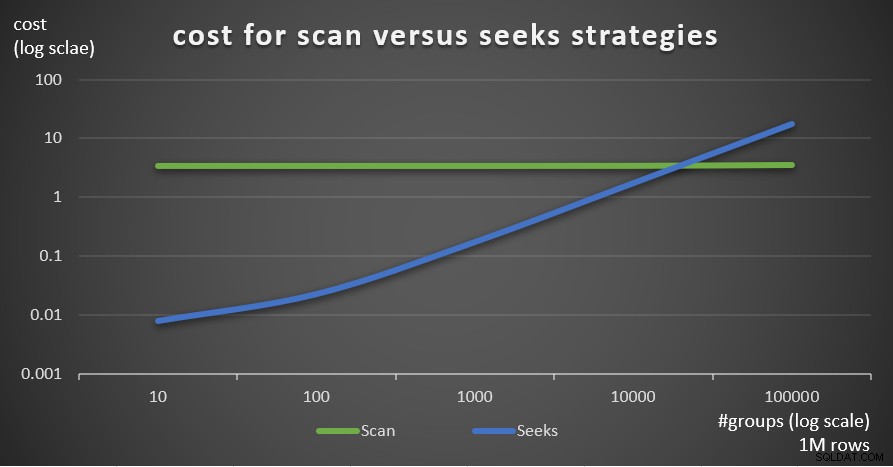 Figura 7:costo per strategie di scansione e ricerca (1 milione di righe)
Figura 7:costo per strategie di scansione e ricerca (1 milione di righe)
Come è evidente da questi risultati, maggiore è la densità del set di raggruppamento e più righe nella tabella principale, più ottimale è la strategia di ricerca rispetto alla strategia di scansione. Quindi, in scenari ad alta densità, assicurati di provare la soluzione basata su APPLY. Nel frattempo, possiamo sperare che Microsoft aggiunga questa strategia come opzione integrata per le query raggruppate.
Conclusione
Questo articolo conclude una serie in cinque parti sulle soglie di ottimizzazione delle query per le query che raggruppano e aggregano i dati. Uno degli obiettivi della serie era discutere le specifiche dei vari algoritmi che l'ottimizzatore può utilizzare, le condizioni in cui ciascun algoritmo è preferito e quando è necessario intervenire con le proprie riscritture di query. Un altro obiettivo era spiegare il processo di scoperta delle varie opzioni e confrontarle. Ovviamente, lo stesso processo di analisi può essere applicato a filtri, join, windowing e molti altri aspetti dell'ottimizzazione delle query. Si spera che ora ti senta più attrezzato per gestire l'ottimizzazione delle query rispetto a prima.