Questo articolo è la settima parte di una serie sulle espressioni di tabelle con nome. Nella parte 5 e nella parte 6 ho trattato gli aspetti concettuali delle espressioni di tabelle comuni (CTE). Questo mese e il prossimo il mio focus si sposta sulle considerazioni sull'ottimizzazione dei CTE.
Inizierò rivisitando rapidamente il concetto di annullamento dell'annidamento delle espressioni di tabelle con nome e dimostrerò la sua applicabilità ai CTE. Poi mi concentrerò su considerazioni di persistenza. Parlerò degli aspetti di persistenza dei CTE ricorsivi e non ricorsivi. Spiegherò quando ha senso attenersi ai CTE rispetto a quando ha effettivamente più senso lavorare con tabelle temporanee.
Nei miei esempi continuerò a utilizzare i database di esempio TSQLV5 e PerformanceV5. Puoi trovare lo script che crea e popola TSQLV5 qui e il suo diagramma ER qui. Puoi trovare lo script che crea e popola PerformanceV5 qui.
Sostituzione/annullamento dell'annidamento
Nella parte 4 della serie, incentrata sull'ottimizzazione delle tabelle derivate, ho descritto un processo di annullamento/sostituzione delle espressioni di tabella. Ho spiegato che quando SQL Server ottimizza una query che coinvolge tabelle derivate, applica regole di trasformazione all'albero iniziale degli operatori logici prodotti dal parser, eventualmente spostando le cose attraverso quelli che originariamente erano i limiti dell'espressione della tabella. Ciò accade al punto che quando si confronta un piano per una query che utilizza tabelle derivate con un piano per una query che va direttamente rispetto alle tabelle di base sottostanti in cui è stata applicata la logica di disannidamento, hanno lo stesso aspetto. Ho anche descritto una tecnica per impedire l'annullamento dell'annidamento utilizzando il filtro TOP con un numero molto elevato di righe come input. Ho illustrato un paio di casi in cui questa tecnica è stata molto utile, uno in cui l'obiettivo era evitare errori e un altro per motivi di ottimizzazione.
La versione TL;DR di sostituzione/annullamento dell'annidamento di CTE prevede che il processo sia lo stesso delle tabelle derivate. Se sei soddisfatto di questa affermazione, puoi sentirti libero di saltare questa sezione e passare direttamente alla sezione successiva sulla Persistenza. Non ti perderai nulla di importante che non hai letto prima. Tuttavia, se sei come me, probabilmente vorrai la prova che è davvero così. Quindi, probabilmente vorrai continuare a leggere questa sezione e testare il codice che utilizzo mentre rivisito esempi di disnidimento chiave che ho dimostrato in precedenza con tabelle derivate e convertirli per utilizzare CTE.
Nella parte 4 ho dimostrato la seguente query (la chiameremo Query 1):
USE TSQLV5;
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; La query prevede tre livelli di nidificazione di tabelle derivate, oltre a una query esterna. Ciascun livello filtra un diverso intervallo di date degli ordini. Il piano per la query 1 è mostrato nella figura 1.
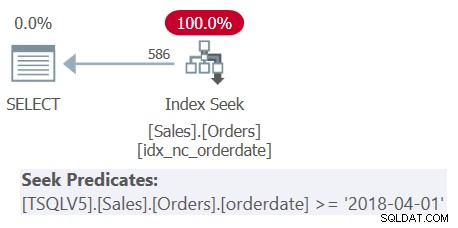 Figura 1:piano di esecuzione per la query 1
Figura 1:piano di esecuzione per la query 1
Il piano nella Figura 1 mostra chiaramente che la rimozione dell'annidamento delle tabelle derivate ha avuto luogo poiché tutti i predicati di filtro sono stati uniti in un unico predicato di filtro globale.
Ho spiegato che puoi impedire il processo di annullamento dell'annidamento utilizzando un filtro TOP significativo (al contrario di TOP 100 PERCENT) con un numero molto elevato di righe come input, come mostra la seguente query (la chiameremo Query 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Il piano per la query 2 è mostrato nella Figura 2.
 Figura 2:piano di esecuzione per la query 2
Figura 2:piano di esecuzione per la query 2
Il piano mostra chiaramente che lo snidamento non è avvenuto poiché puoi vedere in modo efficace i limiti della tabella derivata.
Proviamo gli stessi esempi usando i CTE. Ecco la query 1 convertita per utilizzare CTE:
WITH C1 AS
(
SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; Ottieni lo stesso identico piano mostrato in precedenza nella Figura 1, dove puoi vedere che è avvenuto lo snidamento.
Ecco la query 2 convertita per utilizzare CTE:
WITH C1 AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT TOP (9223372036854775807) *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT TOP (9223372036854775807) *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; Ottieni lo stesso piano mostrato in precedenza nella Figura 2, dove puoi vedere che lo snidamento non è avvenuto.
Quindi, rivisitiamo i due esempi che ho usato per dimostrare la praticità della tecnica per prevenire il disannidamento, solo che questa volta utilizzando CTE.
Iniziamo con la query errata. La query seguente tenta di restituire righe ordine con uno sconto maggiore dello sconto minimo e in cui il reciproco dello sconto è maggiore di 10:
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
Lo sconto minimo non può essere negativo, ma nullo o superiore. Quindi, probabilmente stai pensando che se una riga ha uno sconto zero, il primo predicato dovrebbe restituire false e che un cortocircuito dovrebbe impedire il tentativo di valutare il secondo predicato, evitando così un errore. Tuttavia, quando esegui questo codice, ottieni un errore di divisione per zero:
Msg 8134, Level 16, State 1, Line 99 Divide by zero error encountered.
Il problema è che anche se SQL Server supporta un concetto di cortocircuito a livello di elaborazione fisica, non vi è alcuna garanzia che valuterà i predicati del filtro in ordine scritto da sinistra a destra. Un tentativo comune di evitare tali errori consiste nell'usare un'espressione di tabella denominata che gestisce la parte della logica di filtro che si desidera valutare per prima e fare in modo che la query esterna gestisca la logica di filtro che si desidera valutare per seconda. Ecco la soluzione tentata utilizzando un CTE:
WITH C AS
(
SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; Sfortunatamente, tuttavia, l'annullamento dell'annidamento dell'espressione della tabella risulta in un equivalente logico della query della soluzione originale e quando si tenta di eseguire questo codice si ottiene nuovamente un errore di divisione per zero:
Msg 8134, Level 16, State 1, Line 108 Divide by zero error encountered.
Usando il nostro trucco con il filtro TOP nella query interna, impedisci l'annullamento dell'annidamento dell'espressione della tabella, in questo modo:
WITH C AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; Questa volta il codice viene eseguito correttamente senza errori.
Procediamo con l'esempio in cui si utilizza la tecnica per impedire il disannidamento per motivi di ottimizzazione. Il codice seguente restituisce solo i mittenti con una data massima dell'ordine pari o successiva al 1 gennaio 2018:
USE PerformanceV5;
WITH C AS
(
SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; Se ti stai chiedendo perché non utilizzare una soluzione molto più semplice con una query raggruppata e un filtro HAVING, ha a che fare con la densità della colonna shipperid. La tabella Ordini contiene 1.000.000 di ordini e le spedizioni di tali ordini sono state gestite da cinque spedizionieri, il che significa che in media ogni spedizioniere ha gestito il 20% degli ordini. Il piano per una query raggruppata che calcola la data massima dell'ordine per mittente scansionerebbe tutte le 1.000.000 di righe, risultando in migliaia di letture di pagine. Infatti, se evidenzi solo la query interna del CTE (la chiameremo Query 3) calcolando la data massima dell'ordine per mittente e ne controlli il piano di esecuzione, otterrai il piano mostrato nella Figura 3.
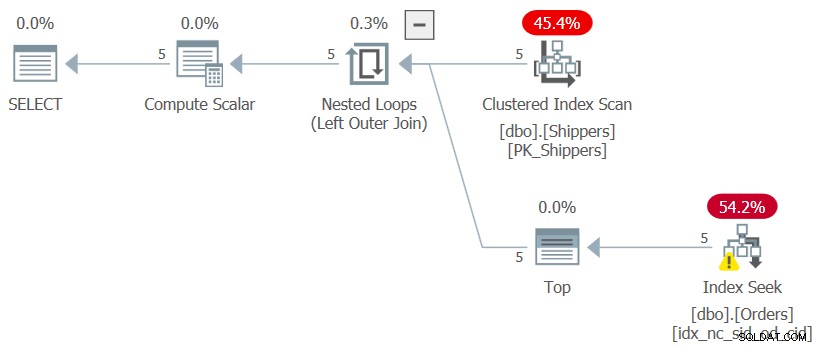 Figura 3:Piano di esecuzione per la query 3
Figura 3:Piano di esecuzione per la query 3
Il piano esegue la scansione di cinque righe nell'indice cluster su Utenti. Per mittente, il piano applica una ricerca rispetto a un indice di copertura sugli ordini, dove (shipperid, orderdate) sono le chiavi iniziali dell'indice, andando direttamente all'ultima riga in ciascuna sezione del mittente a livello di foglia per estrarre la data massima dell'ordine per l'attuale spedizioniere. Dal momento che abbiamo solo cinque caricatori, ci sono solo cinque operazioni di ricerca di indici, risultando in un piano molto efficiente. Ecco le misure delle prestazioni che ho ottenuto quando ho eseguito la query interna del CTE:
duration: 0 ms, CPU: 0 ms, reads: 15
Tuttavia, quando esegui la soluzione completa (la chiameremo Query 4), ottieni un piano completamente diverso, come mostrato nella Figura 4.
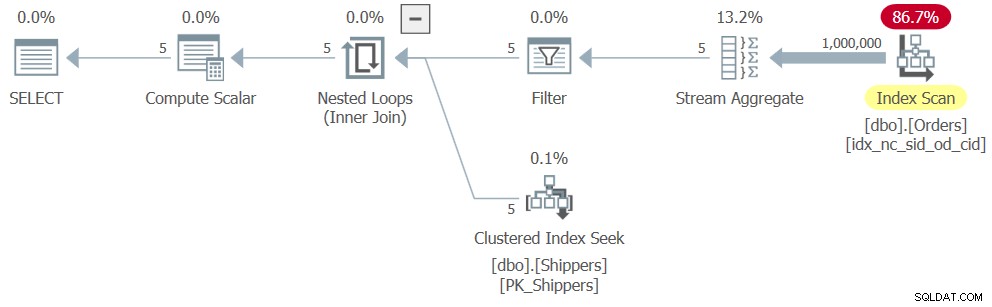 Figura 4:Piano di esecuzione per la query 4
Figura 4:Piano di esecuzione per la query 4
Quello che è successo è che SQL Server ha annullato l'annidamento dell'espressione della tabella, convertendo la soluzione in un equivalente logico di una query raggruppata, risultando in un'analisi completa dell'indice su Orders. Ecco i numeri delle prestazioni che ho ottenuto per questa soluzione:
duration: 316 ms, CPU: 281 ms, reads: 3854
Ciò di cui abbiamo bisogno qui è impedire che avvenga l'annullamento dell'annidamento dell'espressione della tabella, in modo che la query interna venga ottimizzata con le ricerche rispetto all'indice su Orders e che la query esterna si traduca semplicemente nell'aggiunta di un operatore Filter nel Piano. Puoi ottenere questo risultato usando il nostro trucco aggiungendo un filtro TOP alla query interna, in questo modo (chiameremo questa soluzione Query 5):
WITH C AS
(
SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; Il piano per questa soluzione è mostrato nella Figura 5.
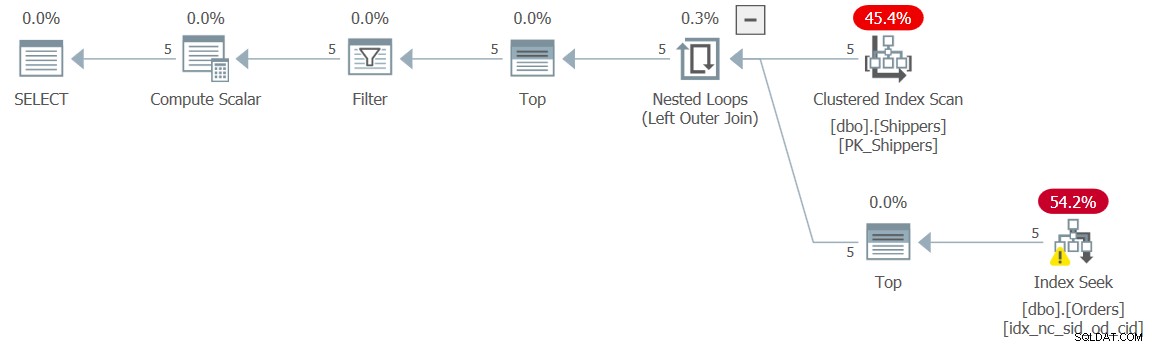 Figura 5:Piano di esecuzione per la query 5
Figura 5:Piano di esecuzione per la query 5
Il piano mostra che l'effetto desiderato è stato raggiunto e di conseguenza i numeri di performance lo confermano:
duration: 0 ms, CPU: 0 ms, reads: 15
Pertanto, i nostri test confermano che SQL Server gestisce la sostituzione/annullamento dell'annidamento di CTE proprio come fa per le tabelle derivate. Ciò significa che non dovresti preferire l'uno all'altro per motivi di ottimizzazione, ma per differenze concettuali che ti interessano, come discusso nella Parte 5.
Persistenza
Un malinteso comune riguardo ai CTE e alle espressioni di tabelle con nome in generale è che servano come una sorta di veicolo di persistenza. Alcuni pensano che SQL Server persista il set di risultati della query interna in una tabella di lavoro e che la query esterna interagisca effettivamente con tale tabella di lavoro. In pratica, le normali CTE non ricorsive e le tabelle derivate non vengono mantenute. Ho descritto la logica di annullamento dell'annidamento applicata da SQL Server durante l'ottimizzazione di una query che coinvolge le espressioni di tabella, risultando in un piano che interagisce direttamente con le tabelle di base sottostanti. Tieni presente che l'ottimizzatore può scegliere di utilizzare le tabelle di lavoro per mantenere i set di risultati intermedi se ha senso farlo per motivi di prestazioni o altri, come la protezione di Halloween. Quando lo fa, vedrai gli operatori Spool o Index Spool nel piano. Tuttavia, tali scelte non sono correlate all'uso delle espressioni di tabella nella query.
CTE ricorsivi
Esistono un paio di eccezioni in cui SQL Server persiste i dati dell'espressione della tabella. Uno è l'uso di viste indicizzate. Se si crea un indice cluster in una vista, SQL Server mantiene il set di risultati della query interna nell'indice cluster della vista e lo mantiene sincronizzato con eventuali modifiche nelle tabelle di base sottostanti. L'altra eccezione è quando si utilizzano query ricorsive. SQL Server deve mantenere i set di risultati intermedi delle query anchor e ricorsive in uno spool in modo che possa accedere al set di risultati dell'ultimo round rappresentato dal riferimento ricorsivo al nome CTE ogni volta che viene eseguito il membro ricorsivo.
Per dimostrarlo utilizzerò una delle query ricorsive della Parte 6 della serie.
Utilizzare il codice seguente per creare la tabella Employees nel database tempdb, popolarla con dati di esempio e creare un indice di supporto:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary);
GO Ho utilizzato il seguente CTE ricorsivo per restituire tutti i subordinati di un gestore radice di sottoalbero di input, utilizzando l'impiegato 3 come gestore di input in questo esempio:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; Il piano per questa query (che chiameremo Query 6) è mostrato nella Figura 6.
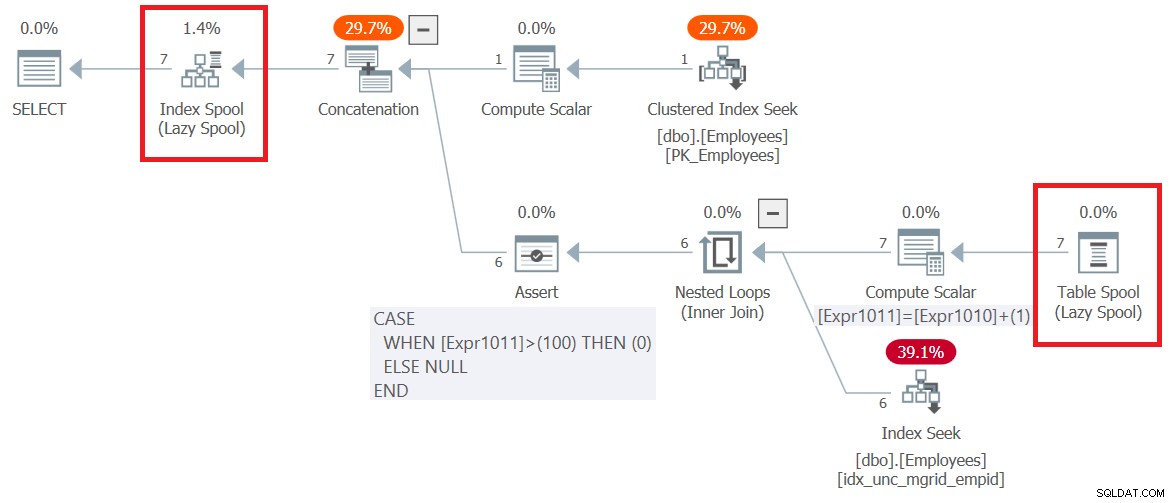 Figura 6:piano di esecuzione per la query 6
Figura 6:piano di esecuzione per la query 6
Osservare che la prima cosa che accade nel piano, a destra del nodo radice SELECT, è la creazione di una tabella di lavoro basata su B-tree rappresentata dall'operatore Index Spool. La parte superiore del piano gestisce la logica del membro di ancoraggio. Estrae le righe dei dipendenti di input dall'indice cluster su Dipendenti e le scrive nello spool. La parte inferiore del piano rappresenta la logica del membro ricorsivo. Viene eseguito ripetutamente finché non restituisce un set di risultati vuoto. L'input esterno all'operatore Nested Loops ottiene i gestori del round precedente dallo spool (operatore Table Spool). L'input interno utilizza un operatore Index Seek rispetto a un indice non cluster creato su Employees(mgrid, empid) per ottenere i subordinati diretti dei manager dal round precedente. Anche il set di risultati di ogni esecuzione della parte inferiore del piano viene scritto nello spool dell'indice. Si noti che in tutto sono state scritte 7 righe nello spool. Uno restituito dal membro di ancoraggio e altri 6 restituiti da tutte le esecuzioni del membro ricorsivo.
Per inciso, è interessante notare come il piano gestisca il limite di maxrecursione predefinito, che è 100. Osservare che l'operatore di calcolo scalare inferiore continua ad aumentare di 1 un contatore interno chiamato Expr1011 ad ogni esecuzione del membro ricorsivo. Quindi, l'operatore Assert imposta un flag su zero se questo contatore supera 100. In questo caso SQL Server interrompe l'esecuzione della query e genera un errore.
Quando non insistere
Tornando ai CTE non ricorsivi, che normalmente non vengono mantenuti, sta a te capire da una prospettiva di ottimizzazione quando è una buona cosa usarli rispetto a strumenti di persistenza effettivi come tabelle temporanee e variabili di tabella. Esaminerò un paio di esempi per dimostrare quando ogni approccio è più ottimale.
Iniziamo con un esempio in cui i CTE fanno meglio delle tabelle temporanee. Questo è spesso il caso quando non si hanno più valutazioni dello stesso CTE, ma forse solo una soluzione modulare in cui ogni CTE viene valutato una sola volta. Il codice seguente (lo chiameremo Query 7) interroga la tabella Orders nel database Performance, che ha 1.000.000 di righe, per restituire gli anni dell'ordine in cui più di 70 clienti distinti hanno effettuato ordini:
USE PerformanceV5;
WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM dbo.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70; Questa query genera il seguente output:
orderyear numcusts ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000
Ho eseguito questo codice utilizzando SQL Server 2019 Developer Edition e ho ottenuto il piano mostrato nella Figura 7.
 Figura 7:Piano di esecuzione per la query 7
Figura 7:Piano di esecuzione per la query 7
Si noti che l'annullamento dell'annidamento del CTE ha portato a un piano che estrae i dati da un indice nella tabella Ordini e non comporta alcuno spooling del set di risultati della query interna del CTE. Ho ottenuto i seguenti numeri di prestazioni durante l'esecuzione di questa query sul mio computer:
duration: 265 ms, CPU: 828 ms, reads: 3970, writes: 0
Ora proviamo una soluzione che utilizza tabelle temporanee invece di CTE (la chiameremo Soluzione 8), in questo modo:
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; SELECT orderyear, COUNT(DISTINCT custid) AS numcusts INTO #T2 FROM #T1 GROUP BY orderyear; SELECT orderyear, numcusts FROM #T2 WHERE numcusts > 70; DROP TABLE #T1, #T2;
I piani per questa soluzione sono mostrati nella Figura 8.
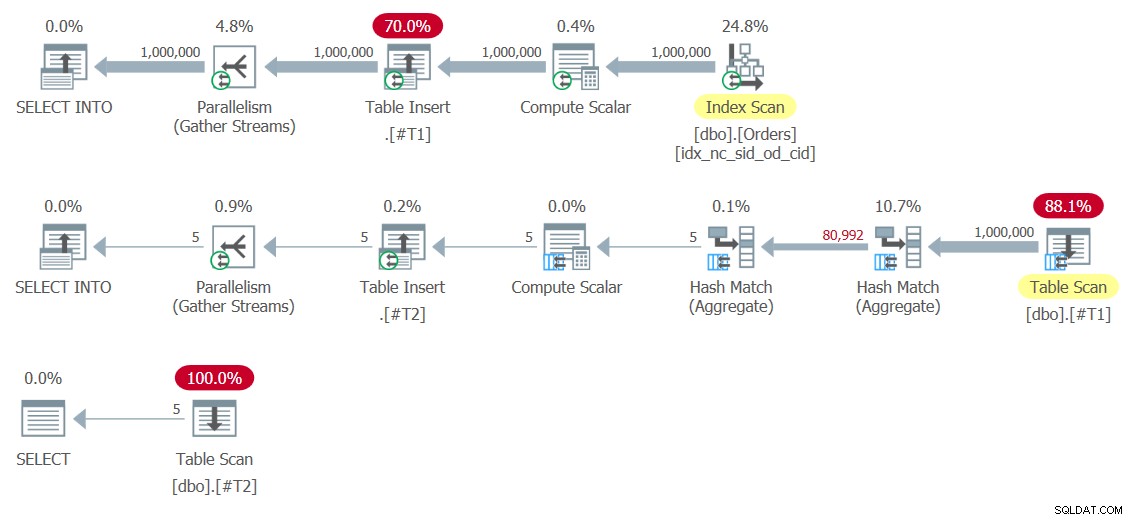 Figura 8:Piani per la Soluzione 8
Figura 8:Piani per la Soluzione 8
Notare gli operatori di inserimento tabella che scrivono i set di risultati nelle tabelle temporanee #T1 e #T2. Il primo è particolarmente costoso poiché scrive 1.000.000 di righe su #T1. Ecco i numeri delle prestazioni che ho ottenuto per questa esecuzione:
duration: 454 ms, CPU: 1517 ms, reads: 14359, writes: 359
Come puoi vedere, la soluzione con i CTE è molto più ottimale.
Quando insistere
Quindi è sempre preferibile una soluzione modulare che prevede una sola valutazione di ogni CTE rispetto all'utilizzo di tabelle temporanee? Non necessariamente. Nelle soluzioni basate su CTE che comportano molti passaggi e danno luogo a piani elaborati in cui l'ottimizzatore deve applicare molte stime di cardinalità in molti punti diversi del piano, potresti ritrovarti con imprecisioni accumulate che si traducono in scelte non ottimali. Una delle tecniche per tentare di affrontare tali casi consiste nel persistere alcuni set di risultati intermedi in tabelle temporanee e persino creare indici su di essi se necessario, dando all'ottimizzatore un nuovo inizio con nuove statistiche, aumentando la probabilità di stime di cardinalità di migliore qualità che si spera che porti a scelte più ottimali. Se questo è meglio di una soluzione che non utilizza tabelle temporanee è qualcosa che dovrai testare. A volte ne varrà la pena il compromesso di costi aggiuntivi per la persistenza di set di risultati intermedi al fine di ottenere stime di cardinalità di qualità migliore.
Un altro caso tipico in cui l'utilizzo di tabelle temporanee è l'approccio preferito è quando la soluzione basata su CTE ha più valutazioni dello stesso CTE e la query interna del CTE è piuttosto costosa. Considera la seguente soluzione basata su CTE (la chiameremo Query 9), che corrisponde a ogni anno e mese dell'ordine a un anno e al mese dell'ordine diversi con il conteggio degli ordini più vicino:
WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate)
)
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2; Questa query genera il seguente output:
orderyear ordermonth numorders orderyear2 ordermonth2 numorders2 ----------- ----------- ----------- ----------- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 2016 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 rows affected)
Il piano per la query 9 è mostrato nella Figura 9.
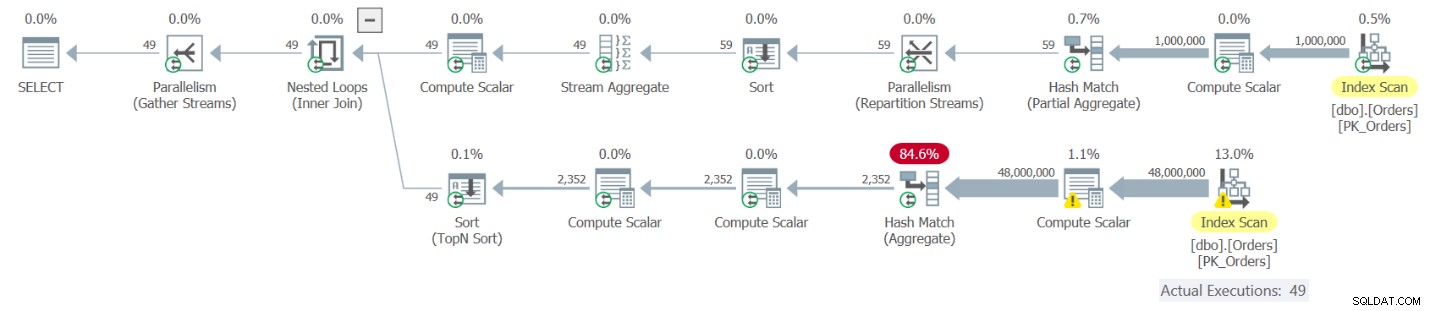 Figura 9:Piano di esecuzione per la query 9
Figura 9:Piano di esecuzione per la query 9
La parte superiore del piano corrisponde all'istanza dell'OrdCount CTE alias O1. Questo riferimento si traduce in una valutazione del CTE OrdCount. Questa parte del piano estrae le righe da un indice nella tabella Ordini, le raggruppa per anno e mese e aggrega il conteggio degli ordini per gruppo, ottenendo 49 righe. La parte inferiore del piano corrisponde alla tabella derivata correlata O2, che viene applicata per riga da O1, quindi viene eseguita 49 volte. Ogni esecuzione interroga l'OrdCount CTE, e quindi si traduce in una valutazione separata della query interna del CTE. Puoi vedere che la parte inferiore del piano scansiona tutte le righe dall'indice su Ordini, raggruppa e le aggrega. In pratica ottieni un totale di 50 valutazioni del CTE, con il risultato di scansionare 50 volte le 1.000.000 di righe di Ordini, raggruppandole e aggregandole. Non sembra una soluzione molto efficiente. Ecco le misure delle prestazioni che ho ottenuto durante l'esecuzione di questa soluzione sul mio computer:
duration: 16 seconds, CPU: 56 seconds, reads: 130404, writes: 0
Dato che ci sono solo poche decine di mesi coinvolti, sarebbe molto più efficiente utilizzare una tabella temporanea per memorizzare il risultato di una singola attività che raggruppa e aggrega le righe di Ordini, e quindi avere sia gli input esterni che quelli interni di l'operatore APPLY interagisce con la tabella temporanea. Ecco la soluzione (la chiameremo Soluzione 10) utilizzando una tabella temporanea al posto del CTE:
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
INTO #OrdCount
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate);
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM #OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM #OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2;
DROP TABLE #OrdCount; Qui non ha molto senso indicizzare la tabella temporanea, poiché il filtro TOP si basa su un calcolo nella sua specifica di ordinamento, e quindi un ordinamento è inevitabile. Tuttavia, potrebbe benissimo essere che in altri casi, con altre soluzioni, sarebbe importante considerare anche l'indicizzazione delle tabelle temporanee. In ogni caso, il piano per questa soluzione è mostrato nella Figura 10.
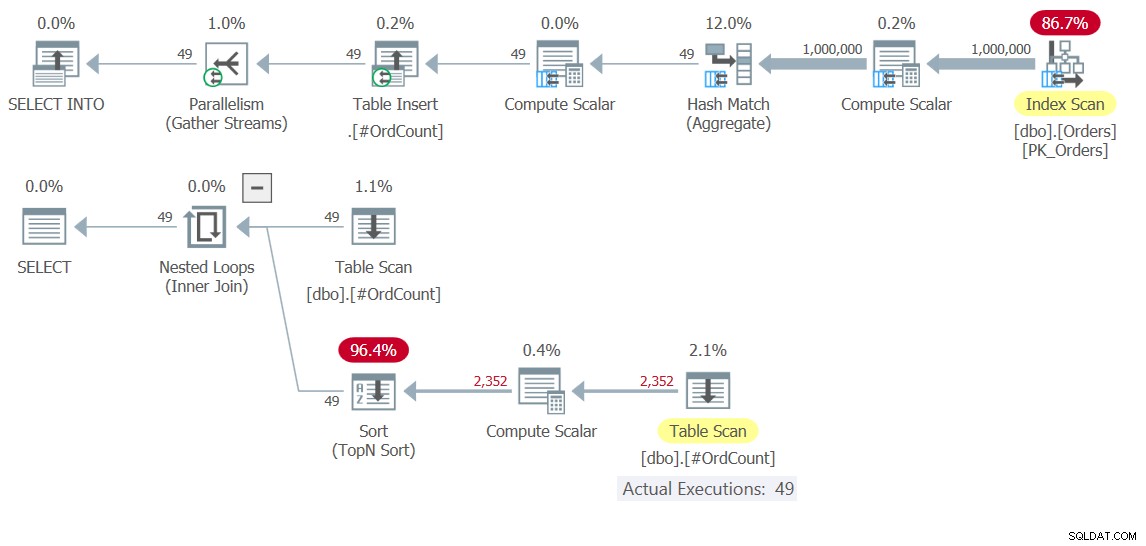 Figura 10:piani di esecuzione per la Soluzione 10
Figura 10:piani di esecuzione per la Soluzione 10
Osservare nella pianta in alto come il sollevamento di carichi pesanti che comporta la scansione di 1.000.000 di righe, il raggruppamento e l'aggregazione, avviene solo una volta. 49 righe vengono scritte nella tabella temporanea #OrdCount, quindi il piano inferiore interagisce con la tabella temporanea sia per gli input esterni che per quelli interni dell'operatore Nested Loops, che gestisce la logica dell'operatore APPLY.
Ecco i numeri delle prestazioni che ho ottenuto per l'esecuzione di questa soluzione:
duration: 0.392 seconds, CPU: 0.5 seconds, reads: 3636, writes: 3
È più veloce in ordine di grandezza rispetto alla soluzione basata su CTE.
Cosa c'è dopo?
In questo articolo ho iniziato la trattazione delle considerazioni di ottimizzazione relative ai CTE. Ho mostrato che il processo di annullamento/sostituzione che avviene con le tabelle derivate funziona allo stesso modo con i CTE. Ho anche discusso del fatto che i CTE non ricorsivi non vengono persistenti e ho spiegato che quando la persistenza è un fattore importante per le prestazioni della tua soluzione, devi gestirlo da solo utilizzando strumenti come tabelle temporanee e variabili di tabella. Il mese prossimo continuerò la discussione trattando aspetti aggiuntivi dell'ottimizzazione CTE.