In un blog precedente, abbiamo discusso di come migrare una configurazione autonoma di Moodle in una configurazione scalabile basata su un database in cluster. Il passaggio successivo a cui dovrai pensare è il meccanismo di failover:cosa fare se e quando il servizio di database si interrompe.
Un server di database guasto non è insolito se hai MySQL Replication come database Moodle di back-end e, in tal caso, dovrai trovare un modo per ripristinare la tua topologia, ad esempio promuovendo un server di standby a diventare un nuovo server primario. Avere il failover automatico per il tuo database Moodle MySQL aiuta il tempo di attività dell'applicazione. Spiegheremo come funzionano i meccanismi di failover e come creare un failover automatico nella tua configurazione.
Architettura ad alta disponibilità per database MySQL
L'architettura ad alta disponibilità può essere ottenuta raggruppando il database MySQL in un paio di modi diversi. Puoi utilizzare MySQL Replication, impostare più repliche che seguono da vicino il tuo database primario. Inoltre, puoi inserire un sistema di bilanciamento del carico del database per dividere il traffico di lettura/scrittura e distribuire il traffico tra i nodi di lettura-scrittura e di sola lettura. L'architettura ad alta disponibilità del database che utilizza MySQL Replication può essere descritta come segue:
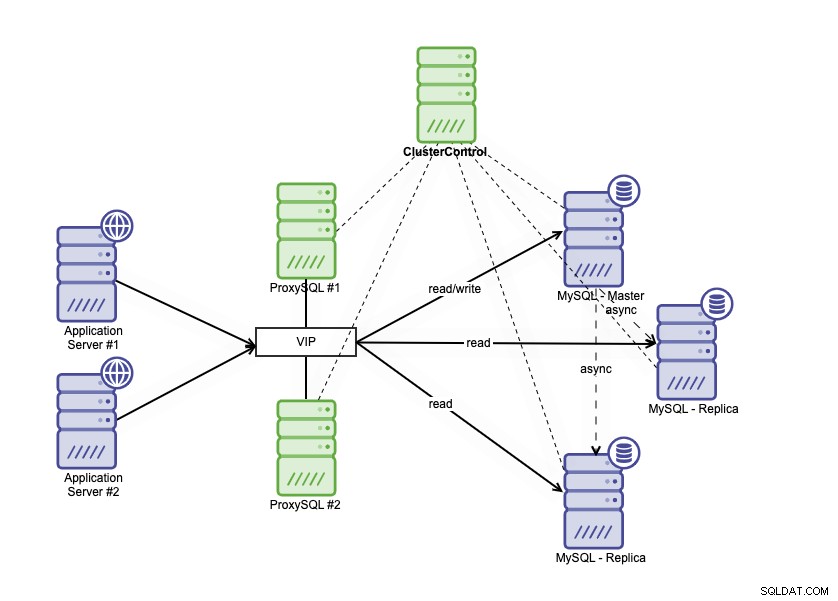
È costituito da un database primario, due repliche del database e bilanciatori del carico del database (in questo blog, utilizziamo ProxySQL come bilanciatori di carico del database) e keepalive come servizio per monitorare i processi ProxySQL. Utilizziamo l'indirizzo IP virtuale come una singola connessione dall'applicazione. Il traffico verrà distribuito al servizio di bilanciamento del carico attivo in base al flag del ruolo in keepalived.
ProxySQL è in grado di analizzare il traffico e capire se una richiesta è in lettura o in scrittura. Quindi inoltrerà la richiesta agli host appropriati.
Failover su replica MySQL
La replica MySQL utilizza la registrazione binaria per replicare i dati dal primario alle repliche. Le repliche si connettono al nodo primario e ogni modifica viene replicata e scritta nei log di inoltro dei nodi di replica tramite IO_THREAD. Dopo che le modifiche sono state archiviate nel registro di inoltro, il processo SQL_THREAD procederà con l'applicazione dei dati nel database di replica.
L'impostazione predefinita per il parametro read_only in una replica è ON. Viene utilizzato per proteggere la replica stessa da qualsiasi scrittura diretta, quindi le modifiche proverranno sempre dal database primario. Questo è importante in quanto non vogliamo che la replica si discosti dal server primario. Lo scenario di failover in MySQL Replication si verifica quando il database primario non è raggiungibile. Ci possono essere molte ragioni per questo; ad esempio, arresti anomali del server o problemi di rete.
È necessario promuovere una delle repliche a primaria, disabilitare il parametro di sola lettura sulla replica promossa in modo che possa essere scrivibile. È inoltre necessario modificare l'altra replica per connettersi al nuovo primario. In modalità GTID, non è necessario annotare il nome del registro binario e la posizione da cui riprendere la replica. Tuttavia, nella replica tradizionale basata su binlog, è assolutamente necessario conoscere l'ultimo nome del registro binario e la posizione da cui proseguire. Il failover nella replica basata su binlog è un processo piuttosto complesso, ma anche il failover nella replica basata su GTID non è banale poiché è necessario prestare attenzione a cose come le transazioni errate. Rilevare un guasto è una cosa, e quindi reagire al guasto in un breve ritardo probabilmente non è possibile senza automazione.
Come ClusterControl abilita il failover automatico
ClusterControl ha la capacità di eseguire il failover automatico per il tuo database Moodle MySQL. È disponibile una funzionalità di ripristino automatico per cluster e nodi che attiverà il processo di failover in caso di arresto anomalo del database primario.
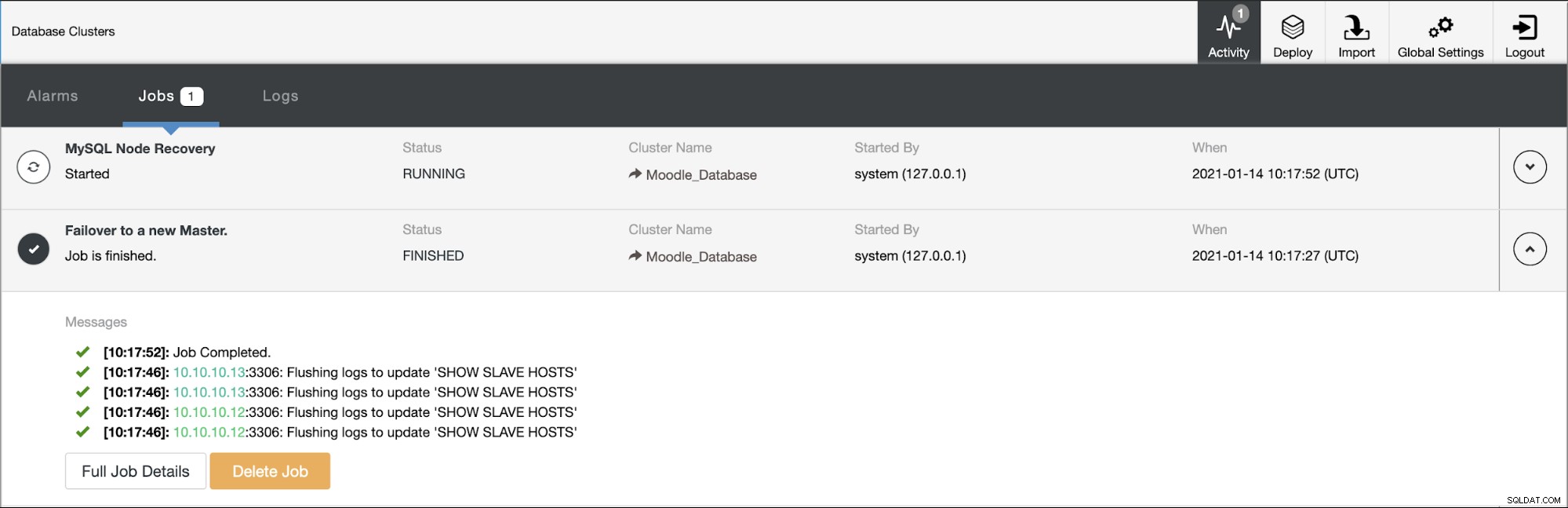
Simuleremo come avviene il failover automatico in ClusterControl. Faremo arrestare in modo anomalo il database primario e lo vedremo solo sul dashboard di ClusterControl. Di seguito è riportata la topologia corrente del cluster:
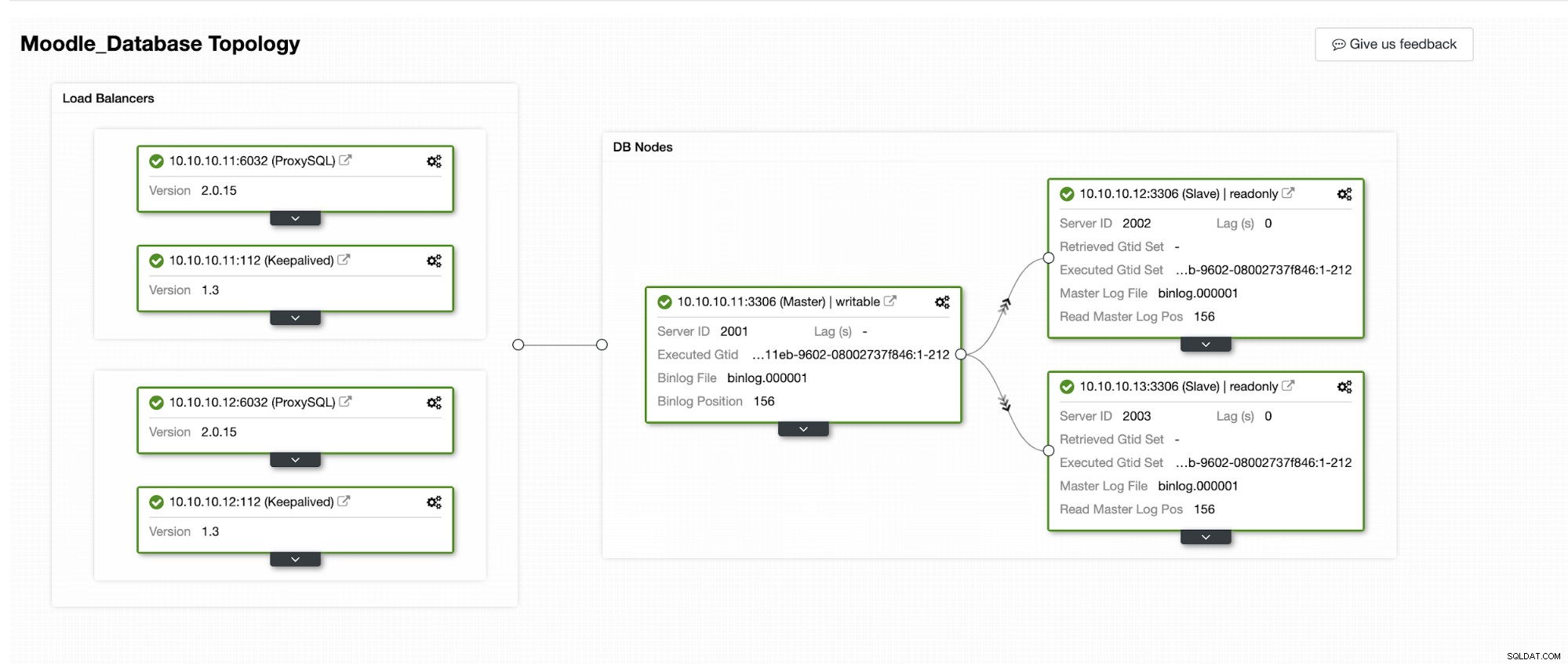
Il database primario utilizza l'indirizzo IP 10.10.10.11 e le repliche sono:10.10.10.12 e 10.10.10.13. Quando si verifica l'arresto anomalo sul primario, ClusterControl attiva un avviso e viene avviato un failover come mostrato nell'immagine seguente:
Una delle repliche verrà promossa a primaria, risultando nella topologia come nell'immagine qui sotto:
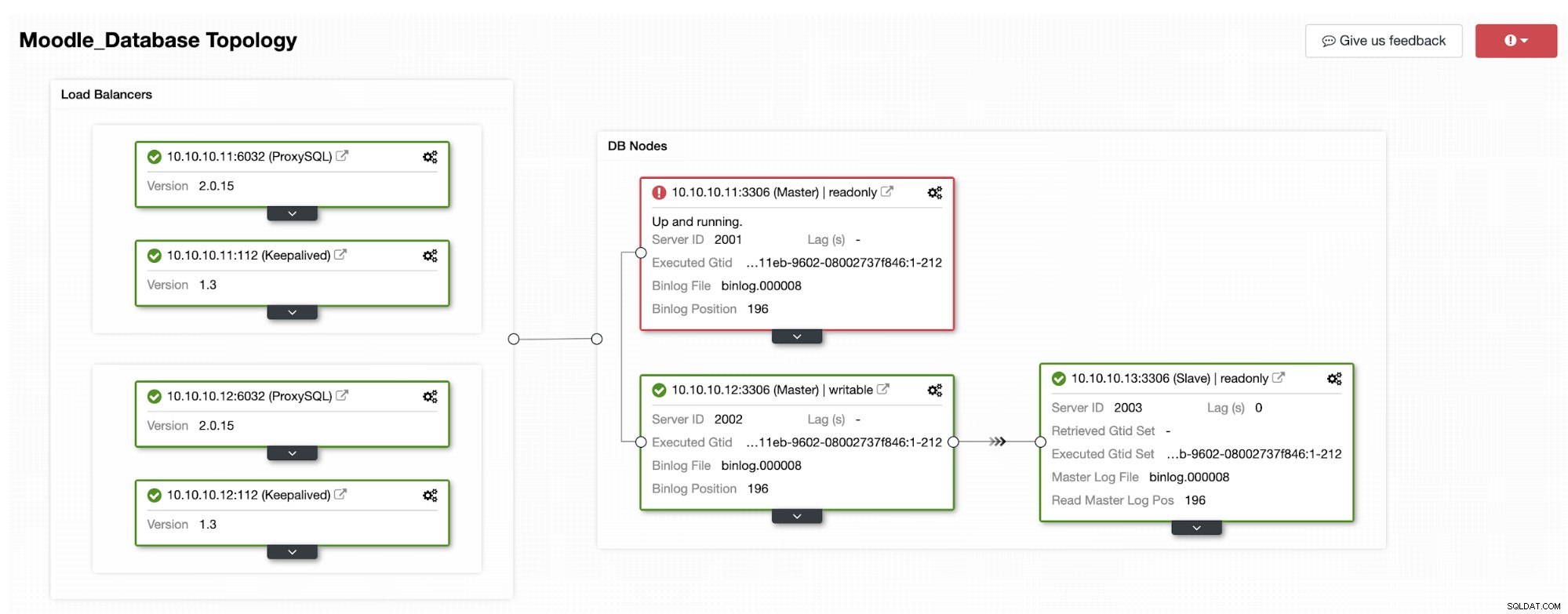
L'indirizzo IP 10.10.10.12 ora serve il traffico di scrittura come primario, e inoltre ci rimane solo una replica che ha l'indirizzo IP 10.10.10.13. Sul lato ProxySQL, il proxy rileverà automaticamente il nuovo database primario. Il gruppo host (HG10) serve ancora il traffico di scrittura che ha il membro 10.10.10.12 come mostrato di seguito:

Hostgroup (HG20) può ancora servire il traffico di lettura, ma come puoi vedere il nodo 10.10.10.11 è offline a causa dell'arresto anomalo :
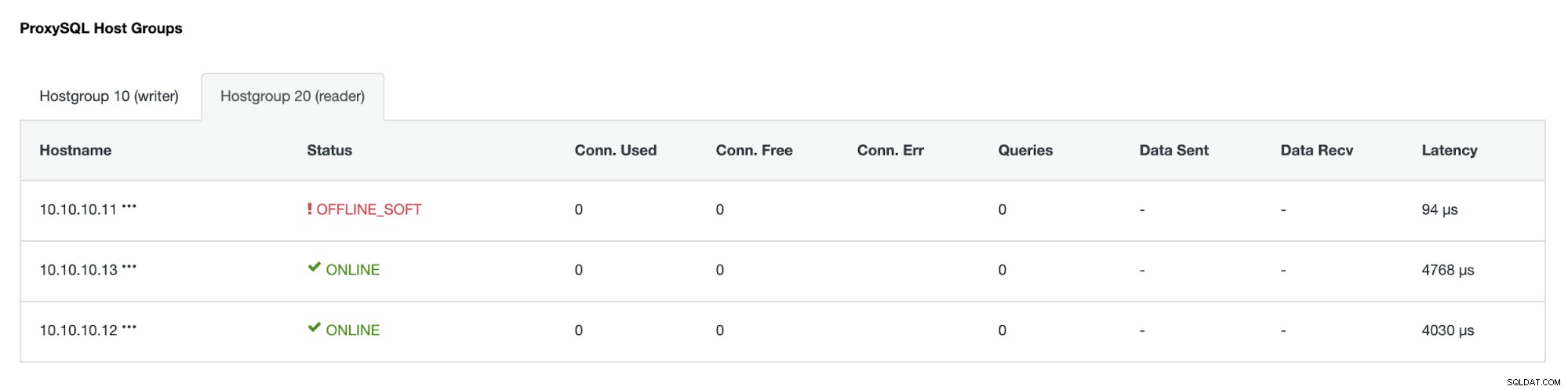
Una volta che il server primario guasto torna online, non verrà ripristinato automaticamente -Introdotto nella topologia del database. Questo per evitare di perdere le informazioni sulla risoluzione dei problemi, poiché la reintroduzione del nodo come replica potrebbe richiedere la sovrascrittura di alcuni registri o altre informazioni. Ma è possibile configurare il rejoin automatico del nodo fallito.