Esistono diversi metodi per esaminare le query con prestazioni scadenti in SQL Server, in particolare Query Store, eventi estesi e viste a gestione dinamica (DMV). Ogni opzione ha pro e contro. Gli eventi estesi forniscono dati sull'esecuzione individuale delle query, mentre Query Store e DMV aggregano i dati sulle prestazioni. Per utilizzare Query Store ed eventi estesi, devi configurarli in anticipo, abilitando Query Store per i tuoi database o configurando una sessione XE e avviandola. I dati DMV sono sempre disponibili, quindi molto spesso è il metodo più semplice per dare una prima occhiata alle prestazioni delle query. È qui che le query DMV di Glenn tornano utili:all'interno del suo script sono presenti più query che puoi utilizzare per trovare le query principali per l'istanza in base a CPU, I/O logico e durata. Puntare alle query che consumano più risorse è spesso un buon inizio durante la risoluzione dei problemi, ma non possiamo dimenticare lo scenario della "morte per mille tagli" - la query o l'insieme di query che vengono eseguiti MOLTO frequentemente - forse centinaia o migliaia di volte un minuto. Glenn ha una query nel suo set che elenca le query principali per un database in base al conteggio delle esecuzioni, ma secondo la mia esperienza non fornisce un quadro completo del tuo carico di lavoro.
Il principale DMV utilizzato per esaminare le metriche delle prestazioni delle query è sys.dm_exec_query_stats. Sono disponibili anche dati aggiuntivi specifici per stored procedure (sys.dm_exec_procedure_stats), funzioni (sys.dm_exec_function_stats) e trigger (sys.dm_exec_trigger_stats), ma considera un carico di lavoro che non è puramente stored procedure, funzioni e trigger. Prendi in considerazione un carico di lavoro misto che contiene alcune query ad hoc, o forse è interamente ad hoc.
Esempio di scenario
Prendendo in prestito e adattando il codice di un post precedente, Esaminando l'impatto sulle prestazioni di un carico di lavoro ad hoc, creeremo prima due stored procedure. Il primo, dbo.RandomSelects, genera ed esegue un'istruzione ad hoc, mentre il secondo, dbo.SPRandomSelects, genera ed esegue una query parametrizzata.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Ora eseguiremo entrambe le stored procedure 1000 volte, utilizzando lo stesso metodo descritto nel mio post precedente con file .cmd che chiamano file .sql con le seguenti istruzioni:
Contenuto del file Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Contenuto del file Parameterized.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Esempio di sintassi nel file .cmd che chiama il file .sql:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Se utilizziamo una variante della query Orario di lavoro massimo di Glenn per esaminare le query principali in base al tempo di lavoro (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
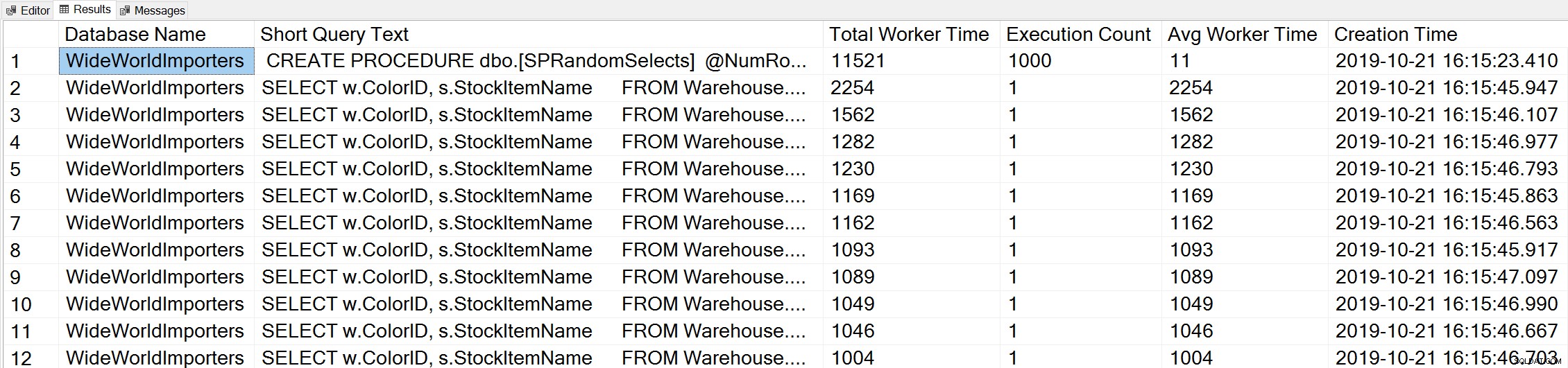
Consideriamo l'istruzione della nostra procedura memorizzata come la query che viene eseguita con la quantità maggiore di CPU cumulativa.
Se eseguiamo una variante della query Query Execution Counts di Glenn sul database WideWorldImporters:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
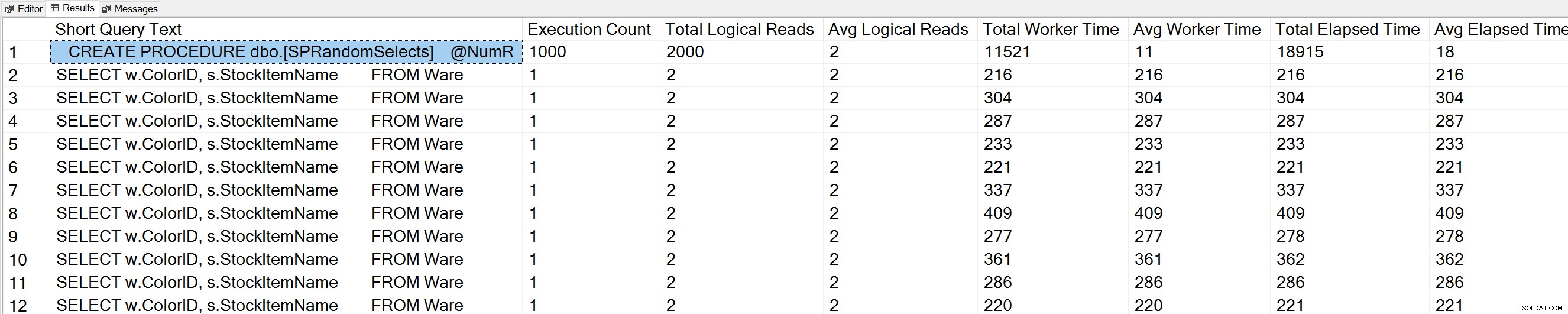
Vediamo anche la nostra istruzione di stored procedure in cima all'elenco.
Ma la query ad hoc che abbiamo eseguito, anche se ha valori letterali diversi, era essenzialmente la identica istruzione eseguita ripetutamente, come possiamo vedere osservando query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
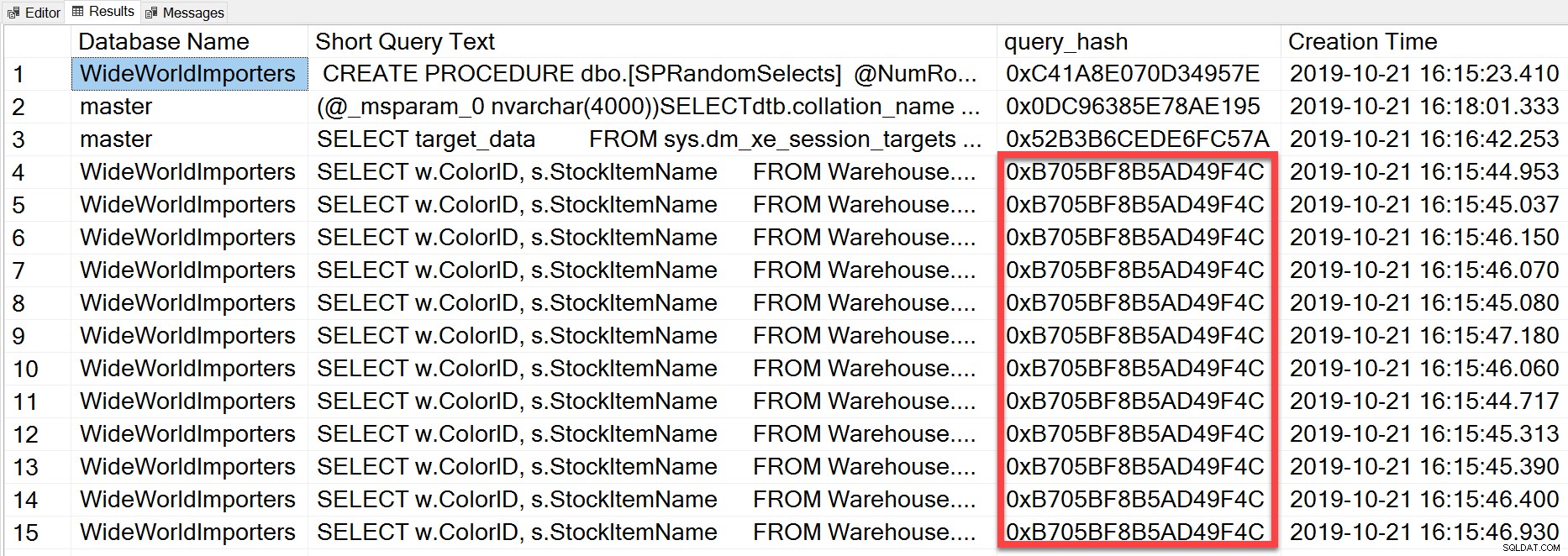
Il query_hash è stato aggiunto in SQL Server 2008 e si basa sulla struttura ad albero degli operatori logici generati da Query Optimizer per il testo dell'istruzione. Le query che hanno un testo di istruzione simile che genera lo stesso albero di operatori logici avranno lo stesso query_hash, anche se i valori letterali nel predicato della query sono diversi. Sebbene i valori letterali possano essere diversi, gli oggetti e i relativi alias devono essere gli stessi, così come i suggerimenti per le query e potenzialmente le opzioni SET. La procedura memorizzata RandomSelects genera query con valori letterali diversi:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Ma ogni esecuzione ha lo stesso identico valore per query_hash, 0xB705BF8B5AD49F4C. Per capire con quale frequenza viene eseguita una query ad hoc, e quelle che sono le stesse in termini di query_hash, dobbiamo raggruppare in base all'ordine query_hash su quel conteggio, piuttosto che guardare esecuzione_count in sys.dm_exec_query_stats (che spesso mostra un valore di 1).
Se cambiamo contesto nel database WideWorldImporters e cerchiamo le query principali in base al conteggio delle esecuzioni, dove raggruppiamo su query_hash, ora possiamo vedere sia la stored procedure che la nostra domanda ad hoc:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Nota:la DMV sys.dm_exec_function_stats è stata aggiunta in SQL Server 2016. L'esecuzione di questa query in SQL Server 2014 e versioni precedenti richiede la rimozione del riferimento a questa DMV.
Questo output fornisce una comprensione molto più completa di quali query vengono effettivamente eseguite più frequentemente, poiché si aggrega in base a query_hash, non semplicemente esaminando esecuzione_count in sys.dm_exec_query_stats, che può avere più voci per lo stesso query_hash quando sono valori letterali diversi Usato. L'output della query include anche query_plan_hash, che può essere diverso per le query con lo stesso query_hash. Queste informazioni aggiuntive sono utili quando si valutano le prestazioni del piano per una query. Nell'esempio sopra, ogni query ha lo stesso query_plan_hash, 0x299275DD475C4B17, a dimostrazione del fatto che anche con valori di input diversi, Query Optimizer genera lo stesso piano:è stabile. Quando esistono più valori query_plan_hash per lo stesso query_hash, esiste una variabilità del piano. In uno scenario in cui la stessa query, basata su query_hash, viene eseguita migliaia di volte, una raccomandazione generale consiste nel parametrizzare la query. Se è possibile verificare che non esista variabilità del piano, la parametrizzazione della query rimuove il tempo di ottimizzazione e compilazione per ogni esecuzione e può ridurre la CPU complessiva. In alcuni scenari, la parametrizzazione da cinque a 10 query ad hoc può migliorare le prestazioni del sistema nel suo complesso.
Riepilogo
Per qualsiasi ambiente, è importante capire quali query sono più costose in termini di utilizzo delle risorse e quali query vengono eseguite più frequentemente. Lo stesso insieme di query può essere visualizzato per entrambi i tipi di analisi quando si utilizza lo script DMV di Glenn, il che può essere fuorviante. Pertanto, è importante stabilire se il carico di lavoro è per lo più procedurale, per lo più ad hoc o misto. Sebbene sia molto documentato sui vantaggi delle stored procedure, trovo che i carichi di lavoro misti o altamente ad hoc siano molto comuni, in particolare con soluzioni che utilizzano i mappatori relazionali a oggetti (ORM) come Entity Framework, NHibernate e LINQ to SQL. Se non sei chiaro sul tipo di carico di lavoro per un server, eseguire la query precedente per esaminare le query più eseguite in base a query_hash è un buon inizio. Man mano che inizi a comprendere il carico di lavoro e ciò che esiste sia per i picchiatori pesanti che per le query di morte per mille tagli, puoi passare a comprendere veramente l'uso delle risorse e l'impatto che queste query hanno sulle prestazioni del sistema e concentrare i tuoi sforzi per l'ottimizzazione.