Ci troviamo al terzo articolo della serie sulla migrazione di Oracle. Questa volta, esaminiamo quegli strani operatori che modificano i criteri della clausola WHERE in Oracle (+). Come ogni altra cosa, PostgreSQL ha una soluzione per questo.
ACCESSO DESTRO
Oracle supporta e molti sviluppatori utilizzano la sintassi ANSI JOIN esterna utilizzando gli operatori per la clausola di qualificazione.
In genere, è simile a questo:
SELECT *
FROM person, places
WHERE person.id = places.person_id(+)L'obiettivo di questa sintassi è un join esterno destro. In termini di teoria degli insiemi, questo è il sottoinsieme che include tutti i luoghi, indipendentemente dalla persona.

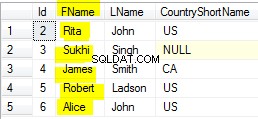
Il risultato di un piccolo campione sarebbe simile a questo:
| id | cognome | nome | id | posizione | id_persona |
|---|---|---|---|---|---|
| 1 | (NULL) | (NULL) | 1 | Dallas | (NULL) |
| 2 | Roybal | Kirk | 2 | Londra | 2 |
| 3 | Riggs | Simone | 3 | Parigi | 3 |
Questa sintassi non è supportata in PostgreSQL.
Per ottenere lo stesso risultato, dovresti utilizzare la sintassi SQL standard per gli outer join.
SELECT *
FROM persons
RIGHT JOIN places
ON persons.id = places.person_id;
SQL fornisce anche un avverbio chiarificatore OUTER . Questo chiarificatore è completamente opzionale, come qualsiasi RIGHT JOIN è per definizione un OUTER unisciti.
FULL JOIN
Allo stesso modo, l'utilizzo della sintassi Oracle per un join completo non funziona in PostgreSQL.
SELECT *
FROM persons, places
WHERE persons.id(+) = places(+);L'obiettivo di questa sintassi è un elenco completo di persone e luoghi indipendentemente dal fatto che una persona sia associata a un luogo o meno.
Il risultato sarebbe questo:
| id | cognome | first_name** | id | posizione | id_persona |
|---|---|---|---|---|---|
| 1 | (NULL) | (NULL) | 1 | Dallas | (NULL) |
| 2 | Roybal | Kirk | 2 | Londra | 2 |
| 3 | Riggs | Simone | 3 | Parigi | 3 |
| 4 | Andrea | Dunstan | (NULL) | (NULL) | (NULL) |
Usando la sintassi di PostgreSQL, la query verrebbe scritta in questo modo:
SELECT *
FROM persons
FULL JOIN places
ON persons.id = places.person_id;
Di nuovo, il OUTER la parola chiave è completamente facoltativa.
CROSS JOIN
Un netto vantaggio dell'approccio all'utilizzo di parole chiave anziché di relazioni implicite è che non è possibile creare accidentalmente un prodotto incrociato.
La sintassi:
SELECT *
FROM persons
LEFT JOIN places;Risulterà in un errore:
ERROR: syntax error at or near ";"Indicando che l'istruzione non è completa all'indicatore di fine riga ";".
PostgreSQL creerà il prodotto cross join utilizzando la sintassi ANSI.

SELECT *
FROM persons, places;| id | cognome | nome | id | posizione | ID_persona |
|---|---|---|---|---|---|
| 1 | Dunstan | Andrea | 1 | Dallas | (null) |
| 1 | Dunstan | Andrea | 2 | Londra | 2 |
| 1 | Dunstan | Andrea | 3 | Parigi | 3 |
| 1 | Dunstan | Andrea | 4 | Madrid | (null) |
| 2 | Reale | Kirk | 1 | Dallas | (null) |
| 2 | Reale | Kirk | 2 | Londra | 2 |
| 2 | Reale | Kirk | 3 | Parigi | 3 |
| 2 | Reale | Kirk | 4 | Madrid | (null) |
| 3 | Riggs | Simone | 1 | Dallas | (null) |
| 3 | Riggs | Simone | 2 | Londra | 2 |
| 3 | Riggs | Simone | 3 | Parigi | 3 |
| 3 | Riggs | Simone | 4 | Madrid | (null) |
| 6 | Wong | Segna | 1 | Dallas | (null) |
| 6 | Wong | Segna | 2 | Londra | 2 |
| 6 | Wong | Segna | 3 | Parigi | 3 |
| 6 | Wong | Segna | 4 | Madrid | (null) |
Che è più probabilmente un errore di codifica rispetto al risultato intenzionale.
Per ottenere intenzionalmente questa funzionalità, si consiglia di utilizzare il CROSS JOIN dichiarazione.
SELECT *
FROM persons
CROSS JOIN places;Rendendo così inequivocabile ciò che si intendeva nella dichiarazione.
UNIONE NATURALE
PostgreSQL supporta il NATURAL JOIN sintassi, ma un po' sotto protesta.
SELECT *
FROM persons
NATURAL JOIN places;Questo produce il seguente risultato.
| id | cognome | nome | ID_genitore | posizione | ID_persona |
|---|---|---|---|---|---|
| 1 | Dunstan | Andrea | (null) | Dallas | (null) |
| 2 | Reale | Kirk | 1 | Londra | 2 |
| 3 | Riggs | Simone | 1 | Parigi | 3 |
Tuttavia, questa sintassi è un problema. Per il nostro esempio, la colonna "id" in entrambe le tabelle non ha nulla a che fare l'una con l'altra . Questo join ha prodotto un risultato, ma con contenuti completamente irrilevanti.
Inoltre, potresti avere una query che inizialmente presenta il risultato corretto, ma le successive istruzioni DDL influiscono silenziosamente.
Considera:
ALTER TABLE person ADD COLUMN places_id bigint;
ALTER TABLE places ADD COLUMN places_id bigint;
ALTER TABLE person ADD COLUMN person_id bigint;
Ora quale colonna è il NATURAL JOIN usando? Le scelte sono id, places_id, person_id e tutto quanto sopra. Lascio la risposta come esercizio al lettore.
Questa sintassi è una bomba a orologeria per il tuo codice. Basta non usarlo.
Ok, quindi non sei convinto. Bene, allora almeno abbi delle sane convenzioni di codifica. Per la tabella padre, denominare la colonna di identità "myparenttable_id". Quando si fa riferimento ad esso dalle relazioni figlio, utilizzare lo stesso nome, "myparenttable_id". Non nominare mai nulla "id" e non fare mai riferimento a una colonna con un nome diverso. Ah, dimenticalo. Basta non farlo.
Potresti essere tentato di chiarire l'enigma precedente usando USING parola chiave. Sarebbe simile a questo:
SELECT *
FROM persons
JOIN places
USING (id);
Ma il USING la parola chiave può sfruttare solo le corrispondenze esatte dei nomi tra le tabelle. Il che, ancora una volta, nel nostro esempio è completamente sbagliato.
La scelta migliore per PostgreSQL è semplicemente evitare di progettare tabelle codificando gli standard delle convenzioni.
Riepilogo
Queste tecniche di parole chiave (rispetto agli operatori) sono disponibili anche su Oracle. Sono più multipiattaforma e meno ambigui. Questo da solo li renderebbe le migliori pratiche.
In aggiunta a ciò, espongono errori logici se utilizzati in modo improprio. Per qualsiasi sviluppo in PostgreSQL, consigliamo unilateralmente di utilizzare parole chiave esplicite.