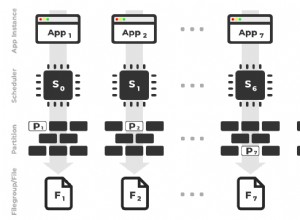
Lo schema del database non è qualcosa che è scritto nella pietra. È progettato per una determinata applicazione, ma i requisiti possono e di solito cambiano. Nuovi moduli e funzionalità vengono aggiunti all'applicazione, vengono raccolti più dati, viene eseguito il refactoring del codice e del modello di dati. Di conseguenza la necessità di modificare lo schema del database per adattarsi a queste modifiche; aggiungere o modificare colonne, creare nuove tabelle o partizionare quelle grandi. Anche le query cambiano poiché gli sviluppatori aggiungono nuovi modi per consentire agli utenti di interagire con i dati:le nuove query potrebbero utilizzare indici nuovi e più efficienti, quindi ci affrettiamo a crearli per fornire all'applicazione le migliori prestazioni del database.
Quindi, come possiamo affrontare al meglio una modifica dello schema? Quali strumenti sono utili? Come ridurre al minimo l'impatto su un database di produzione? Quali sono i problemi più comuni con la progettazione di schemi? Quali strumenti possono aiutarti a rimanere aggiornato sul tuo schema? In questo post del blog ti forniremo una breve panoramica su come apportare modifiche allo schema in MySQL e MariaDB. Tieni presente che non discuteremo le modifiche allo schema nel contesto di Galera Cluster. Abbiamo già discusso dell'isolamento totale degli ordini, degli aggiornamenti dello schema in sequenza e dei suggerimenti per ridurre al minimo l'impatto della RSU nei precedenti post del blog. Discuteremo anche suggerimenti e trucchi relativi alla progettazione dello schema e come ClusterControl può aiutarti a rimanere aggiornato su tutte le modifiche allo schema.
Tipi di modifiche allo schema
Cominciando dall'inizio. Prima di approfondire l'argomento, dobbiamo capire come MySQL e MariaDB eseguono le modifiche allo schema. Vedete, una modifica dello schema non è uguale a un'altra modifica dello schema.
Potresti aver sentito parlare di alter online, alter istantanei o alter sul posto. Tutto ciò è il risultato del lavoro in corso per ridurre al minimo l'impatto delle modifiche allo schema sul database di produzione. Storicamente, quasi tutte le modifiche allo schema stavano bloccando. Se hai eseguito una modifica dello schema, tutte le query inizieranno ad accumularsi, in attesa del completamento di ALTER. Ovviamente, ciò poneva seri problemi per le implementazioni di produzione. Certo, le persone iniziano immediatamente a cercare soluzioni alternative e ne parleremo più avanti in questo blog, poiché anche oggi sono ancora rilevanti. Ma è anche iniziato il lavoro per migliorare la capacità di MySQL di eseguire DDL (Data Definition Language) senza molto impatto su altre query.
Modifiche istantanee
A volte non è necessario toccare alcun dato nel tablespace, perché tutto ciò che deve essere modificato sono i metadati. Un esempio qui sarà l'eliminazione di un indice o la ridenominazione di una colonna. Tali operazioni sono rapide ed efficienti. In genere, il loro impatto è limitato. Non è senza alcun impatto, però. A volte sono necessari un paio di secondi per eseguire la modifica dei metadati e tale modifica richiede l'acquisizione di un blocco dei metadati. Questo blocco è per tabella e può bloccare altre operazioni che devono essere eseguite su questa tabella. Vedrai questo come voci "In attesa di blocco dei metadati della tabella" nell'elenco dei processi.
Un esempio di tale modifica potrebbe essere ADD COLUMN istantanea, introdotta in MariaDB 10.3 e MySQL 8.0. Dà la possibilità di eseguire questa modifica allo schema abbastanza popolare senza alcun ritardo. Sia MariaDB che Oracle hanno deciso di includere il codice di Tencent Game che consente di aggiungere istantaneamente una nuova colonna alla tabella. Questo è in alcune condizioni specifiche; la colonna deve essere aggiunta come ultima, gli indici di testo completo non possono esistere nella tabella, il formato della riga non può essere compresso - puoi trovare maggiori informazioni su come funziona l'aggiunta istantanea della colonna nella documentazione di MariaDB. Per MySQL, l'unico riferimento ufficiale può essere trovato sul blog mysqlserverteam.com, sebbene esista un bug per aggiornare la documentazione ufficiale.
Modifiche in atto
Alcune delle modifiche richiedono la modifica dei dati nel tablespace. Tali modifiche possono essere eseguite sui dati stessi e non è necessario creare una tabella temporanea con una nuova struttura dati. Tali modifiche, in genere (sebbene non sempre) consentono l'esecuzione di altre query che toccano la tabella mentre è in esecuzione la modifica dello schema. Un esempio di tale operazione consiste nell'aggiungere un nuovo indice secondario alla tabella. Questa operazione richiederà del tempo per essere eseguita, ma consentirà l'esecuzione di DML.
Ricostruzione tabella
Se non è possibile apportare una modifica sul posto, InnoDB creerà una tabella temporanea con la nuova struttura desiderata. Quindi copierà i dati esistenti nella nuova tabella. Questa operazione è la più costosa ed è probabile (sebbene non sempre avvenga) bloccare i DML. Di conseguenza, tale modifica dello schema è molto difficile da eseguire su una tabella di grandi dimensioni su un server autonomo, senza l'ausilio di strumenti esterni:in genere non puoi permetterti di bloccare il database per lunghi minuti o addirittura ore. Un esempio di tale operazione potrebbe essere la modifica del tipo di dati della colonna, ad esempio da INT a VARCHAR.
Modifiche allo schema e replica
Ok, quindi sappiamo che InnoDB consente modifiche allo schema online e se consultiamo la documentazione di MySQL, vedremo che la maggior parte delle modifiche allo schema (almeno tra le più comuni) possono essere eseguite online. Qual è il motivo per dedicare ore di sviluppo alla creazione di strumenti di modifica degli schemi online come gh-ost? Possiamo accettare che pt-online-schema-change sia un residuo dei vecchi, brutti tempi, ma gh-ost è un nuovo software.
La risposta è complessa. Ci sono due problemi principali.
Per cominciare, una volta avviata una modifica dello schema, non hai il controllo su di essa. Puoi interromperlo ma non puoi metterlo in pausa. Non puoi strozzarlo. Come puoi immaginare, ricostruire la tabella è un'operazione costosa e anche se InnoDB consente l'esecuzione di DML, il carico di lavoro di I/O aggiuntivo dal DDL influisce su tutte le altre query e non c'è modo di limitare questo impatto a un livello accettabile per il applicazione.
In secondo luogo, un problema ancora più serio è la replica. Se esegui un'operazione non bloccante, che richiede una ricostruzione della tabella, in effetti non bloccherà i DML, ma questo è vero solo sul master. Supponiamo che tale DDL abbia richiesto 30 minuti per essere completato:la velocità di ALTER dipende dall'hardware, ma è abbastanza comune vedere tali tempi di esecuzione su tabelle con dimensioni di 20 GB. Viene quindi replicato su tutti gli slave e, dal momento in cui DDL viene avviato su quegli slave, la replica attende il completamento. Non importa se utilizzi MySQL o MariaDB o se hai una replica multi-thread. Gli slave ritarderanno:attenderanno quei 30 minuti per il completamento del DDL prima di iniziare ad applicare gli eventi binlog rimanenti. Come puoi immaginare, 30 minuti di ritardo (a volte anche 30 secondi non sono accettabili - tutto dipende dall'applicazione) è qualcosa che rende impossibile l'uso di quegli slave per lo scale-out. Naturalmente, ci sono soluzioni alternative:puoi eseguire modifiche allo schema dal basso verso l'alto della catena di replica, ma questo limita seriamente le tue opzioni. Soprattutto se si utilizza la replica basata su righe, è possibile eseguire solo modifiche allo schema compatibili in questo modo. Un paio di esempi di limitazioni della replica basata su righe; non puoi eliminare una colonna che non sia l'ultima, non puoi aggiungere una colonna in una posizione diversa dall'ultima. Non è inoltre possibile modificare il tipo di colonna (ad esempio, INT -> VARCHAR).
Come puoi vedere, la replica aggiunge complessità al modo in cui puoi eseguire modifiche allo schema. Le operazioni non bloccanti sull'host autonomo diventano bloccanti durante l'esecuzione sugli slave. Diamo un'occhiata a un paio di metodi che puoi utilizzare per ridurre al minimo l'impatto delle modifiche allo schema.
Strumenti di modifica dello schema online
Come accennato in precedenza, esistono strumenti che hanno lo scopo di eseguire modifiche allo schema. I più popolari sono pt-online-schema-change creato da Percona e gh-ost, creato da GitHub. In una serie di post sul blog li abbiamo confrontati e discusso di come gh-ost può essere utilizzato per eseguire modifiche allo schema e di come limitare e riconfigurare una migrazione in corso. Qui non entreremo nei dettagli, ma vorremmo comunque menzionare alcuni degli aspetti più importanti dell'utilizzo di questi strumenti. Per cominciare, una modifica dello schema eseguita tramite pt-osc o gh-ost avverrà su tutti i nodi del database contemporaneamente. Non vi è alcun ritardo in termini di quando verrà applicata la modifica. Ciò consente di utilizzare tali strumenti anche per le modifiche dello schema che sono incompatibili con la replica basata su riga. I meccanismi esatti su come questi strumenti tengono traccia delle modifiche sulla tabella sono diversi (trigger in pt-osc e analisi binlog in gh-ost) ma l'idea principale è la stessa:viene creata una nuova tabella con lo schema desiderato e i dati esistenti vengono copiato dalla vecchia tabella. Nel frattempo, i DML vengono tracciati (in un modo o nell'altro) e applicati alla nuova tabella. Una volta migrati tutti i dati, le tabelle vengono rinominate e la nuova tabella sostituisce quella precedente. Questa è un'operazione atomica, quindi non è visibile all'applicazione. Entrambi gli strumenti hanno un'opzione per limitare il carico e mettere in pausa le operazioni. Gh-ost può interrompere tutta l'attività, solo pt-osc può interrompere il processo di copia dei dati tra la vecchia e la nuova tabella:i trigger rimarranno attivi e continueranno a duplicare i dati, il che aggiunge un sovraccarico. A causa della tabella di ridenominazione, entrambi gli strumenti hanno alcune limitazioni relative alle chiavi esterne - non supportate da gh-ost, parzialmente supportate da pt-osc tramite il normale ALTER, che può causare un ritardo di replica (non fattibile se la tabella figlio è grande) o da eliminare la vecchia tabella prima di rinominare quella nuova:è pericoloso in quanto non è possibile eseguire il rollback se, per qualche motivo, i dati non sono stati copiati correttamente nella nuova tabella. Anche i trigger sono difficili da supportare.
Non sono supportati in gh-ost, pt-osc in MySQL 5.7 e versioni successive hanno un supporto limitato per le tabelle con trigger esistenti. Un'altra importante limitazione per gli strumenti di modifica dello schema online è che la chiave univoca o primaria deve esistere nella tabella. Viene utilizzato per identificare le righe da copiare tra le vecchie e le nuove tabelle. Questi strumenti sono anche molto più lenti di ALTER diretto:una modifica che richiede ore durante l'esecuzione di ALTER può richiedere giorni se eseguita utilizzando pt-osc o gh-ost.
D'altra parte, come accennato, finché i requisiti sono soddisfatti e le limitazioni non entrano in gioco, puoi eseguire tutte le modifiche allo schema utilizzando uno degli strumenti. Tutto accadrà contemporaneamente su tutti gli host, quindi non devi preoccuparti della compatibilità. Hai anche un certo livello di controllo su come viene eseguito il processo (meno in pt-osc, molto di più in gh-ost).
Puoi ridurre l'impatto della modifica dello schema, puoi metterli in pausa e lasciarli eseguire solo sotto supervisione, puoi testare la modifica prima di eseguirla effettivamente. Puoi fare in modo che tengano traccia del ritardo di replica e mettano in pausa se viene rilevato un impatto. Ciò rende questi strumenti un'aggiunta davvero eccezionale all'arsenale del DBA mentre si lavora con la replica di MySQL.
Modifiche allo schema in sequenza
In genere, un DBA utilizzerà uno degli strumenti di modifica dello schema online. Ma come abbiamo discusso in precedenza, in alcune circostanze, non possono essere utilizzati e un alter diretto è l'unica opzione praticabile. Se stiamo parlando di MySQL standalone, non hai scelta:se la modifica non è bloccante, va bene. Se non lo è, beh, non c'è niente che tu possa fare al riguardo. Ma poi, non così tante persone eseguono MySQL come istanze singole, giusto? E la replica? Come discusso in precedenza, l'alterazione diretta sul master non è fattibile:nella maggior parte dei casi causerà un ritardo sullo slave e questo potrebbe non essere accettabile. Ciò che si può fare, tuttavia, è eseguire il cambiamento in modo progressivo. Puoi iniziare con gli slave e, una volta applicata la modifica a tutti, promuovere uno degli slave come nuovo master, retrocedere il vecchio master a slave ed eseguire la modifica su di esso. Certo, la modifica deve essere compatibile ma, a dire il vero, i casi più comuni in cui non è possibile utilizzare le modifiche allo schema online sono a causa della mancanza di chiave primaria o univoca. Per tutti gli altri casi, esiste una sorta di soluzione alternativa, specialmente in pt-online-schema-change poiché gh-ost ha limitazioni più rigide. È una soluzione alternativa che definiresti "così così" o "lontano dall'ideale", ma farà il lavoro se non hai altra opzione tra cui scegliere. Ciò che è anche importante, la maggior parte delle limitazioni può essere evitata se si monitora lo schema e si rilevano i problemi prima che la tabella cresca. Anche se qualcuno crea una tabella senza una chiave primaria, non è un problema eseguire una modifica diretta che richiede mezzo secondo o meno, poiché la tabella è quasi vuota.
Se crescerà, questo diventerà un problema serio, ma spetta al DBA rilevare questo tipo di problemi prima che inizino effettivamente a creare problemi. Tratteremo alcuni suggerimenti e trucchi su come assicurarti di rilevare tali problemi in tempo. Condivideremo anche suggerimenti generici su come progettare i tuoi schemi.
Suggerimenti e trucchi
Progettazione di schemi
Come abbiamo mostrato in questo post, gli strumenti di modifica dello schema online sono piuttosto importanti quando si lavora con una configurazione di replica, pertanto è molto importante assicurarsi che lo schema sia progettato in modo tale da non limitare le opzioni per l'esecuzione delle modifiche allo schema. Ci sono tre aspetti importanti. In primo luogo, deve esistere una chiave primaria o univoca:è necessario assicurarsi che non ci siano tabelle senza una chiave primaria nel database. Dovresti monitorarlo regolarmente, altrimenti potrebbe diventare un problema serio in futuro. In secondo luogo, dovresti considerare seriamente se l'utilizzo di chiavi esterne è una buona idea. Certo, hanno i loro usi ma aggiungono anche un sovraccarico al tuo database e possono rendere problematico l'uso degli strumenti di modifica dello schema online. Le relazioni possono essere rafforzate dall'applicazione. Anche se ciò significa più lavoro, potrebbe comunque essere un'idea migliore che iniziare a utilizzare chiavi esterne ed essere fortemente limitato a quali tipi di modifiche allo schema possono essere eseguite. Terzo, trigger. Stessa storia delle chiavi esterne. Sono una bella caratteristica da avere, ma possono diventare un peso. Devi considerare seriamente se i vantaggi derivanti dal loro utilizzo superano i limiti che pongono.
Tracciamento delle modifiche allo schema
La gestione delle modifiche allo schema non riguarda solo l'esecuzione delle modifiche allo schema. Devi anche rimanere in cima alla struttura del tuo schema, soprattutto se non sei l'unico a apportare le modifiche.
ClusterControl fornisce agli utenti gli strumenti per tenere traccia di alcuni dei problemi di progettazione degli schemi più comuni. Può aiutarti a tenere traccia delle tabelle che non hanno chiavi primarie:
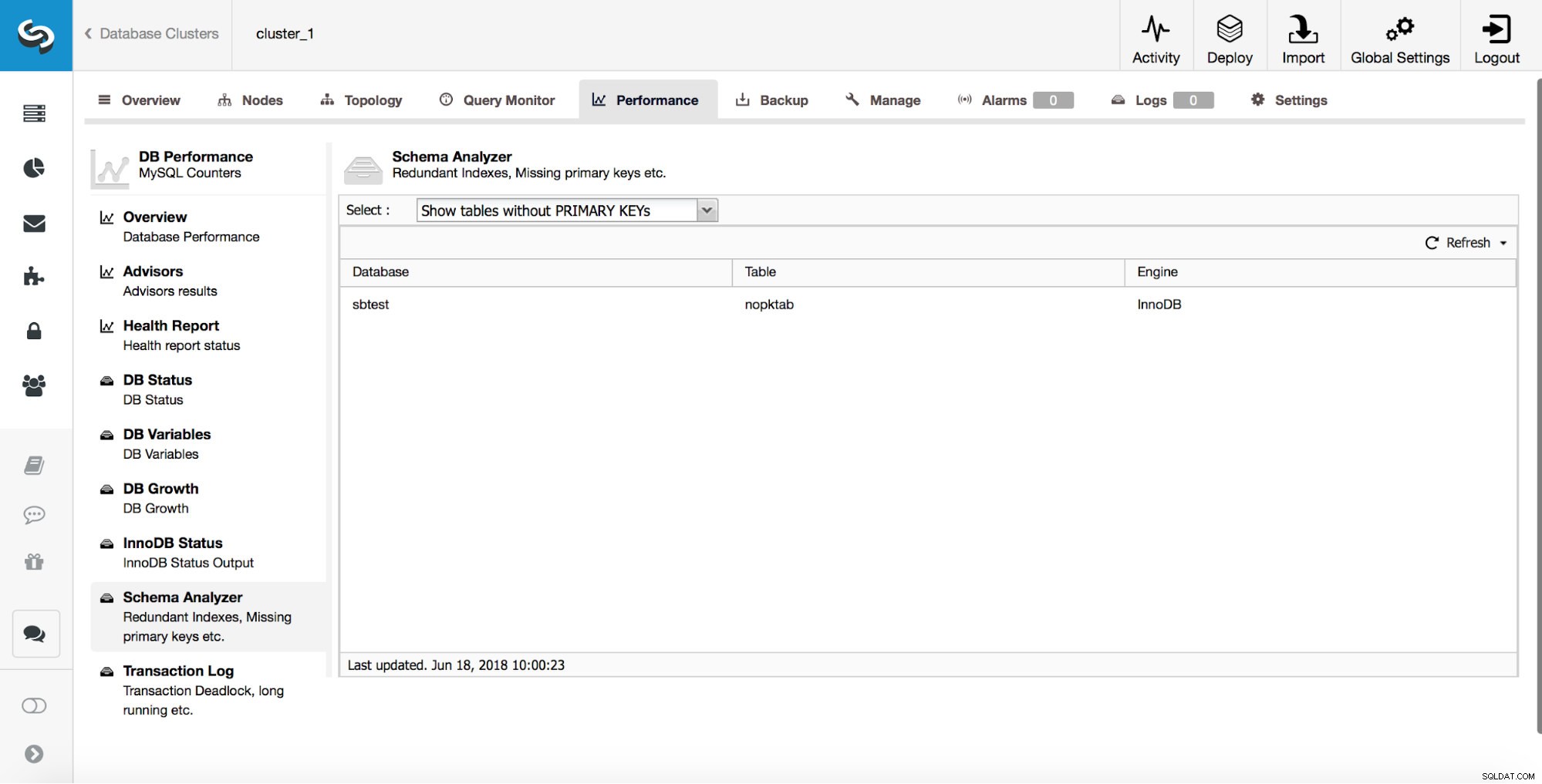
Come abbiamo discusso in precedenza, catturare tali tabelle in anticipo è molto importante poiché le chiavi primarie devono essere aggiunte utilizzando l'alterazione diretta.
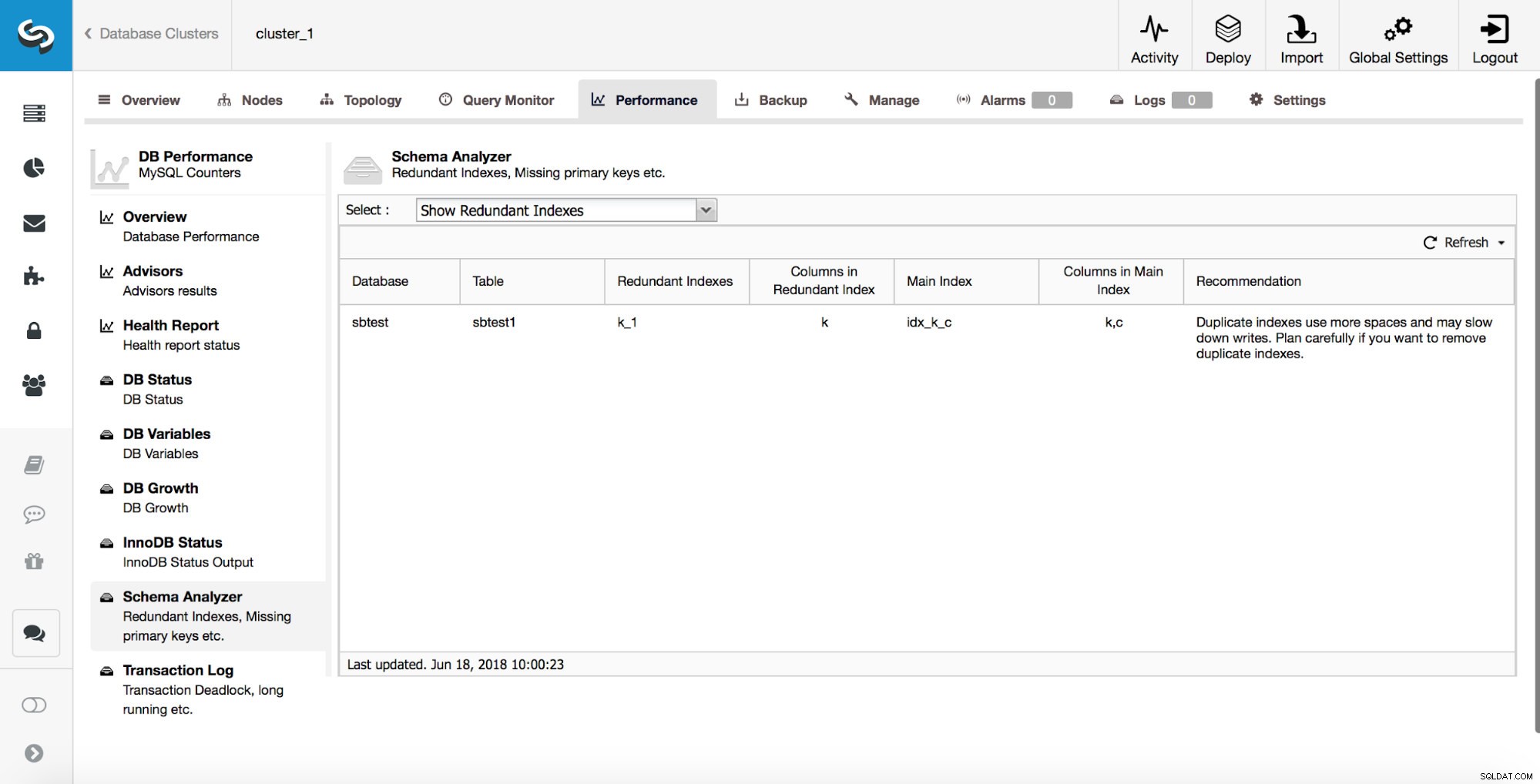
ClusterControl può anche aiutarti a tenere traccia degli indici duplicati. In genere, non si desidera avere più indici ridondanti. Nell'esempio sopra, puoi vedere che c'è un indice su (k, c) e c'è anche un indice su (k). Qualsiasi query che può utilizzare l'indice creato sulla colonna "k" può anche utilizzare un indice composto creato sulle colonne (k, c). Ci sono casi in cui è vantaggioso mantenere gli indici ridondanti, ma è necessario affrontarlo caso per caso. A partire da MySQL 8.0, è possibile verificare rapidamente se un indice è realmente necessario o meno. Puoi rendere "invisibile" un indice ridondante eseguendo:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 INVISIBLE;Ciò farà sì che MySQL ignori quell'indice e, attraverso il monitoraggio, potrai verificare se c'è stato un impatto negativo sulle prestazioni del database. Se tutto funziona come previsto per un po' di tempo (un paio di giorni o addirittura settimane), puoi pianificare la rimozione dell'indice ridondante. Se hai rilevato che qualcosa non va, puoi sempre riattivare questo indice eseguendo:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 VISIBLE;Queste operazioni sono istantanee e l'indice è sempre presente ed è ancora mantenuto:è solo che non verrà preso in considerazione dall'ottimizzatore. Grazie a questa opzione, rimuovere gli indici in MySQL 8.0 sarà un'operazione molto più sicura. Nelle versioni precedenti, la riaggiunta di un indice rimosso erroneamente potrebbe richiedere ore se non giorni su tabelle di grandi dimensioni.
ClusterControl può anche informarti sulle tabelle MyISAM.
Sebbene MyISAM possa ancora avere i suoi usi, devi tenere presente che non è un motore di archiviazione transazionale. In quanto tale, può facilmente introdurre incoerenze di dati tra i nodi in una configurazione di replica.
Un'altra caratteristica molto utile di ClusterControl è uno dei report operativi:uno Schema Change Report.
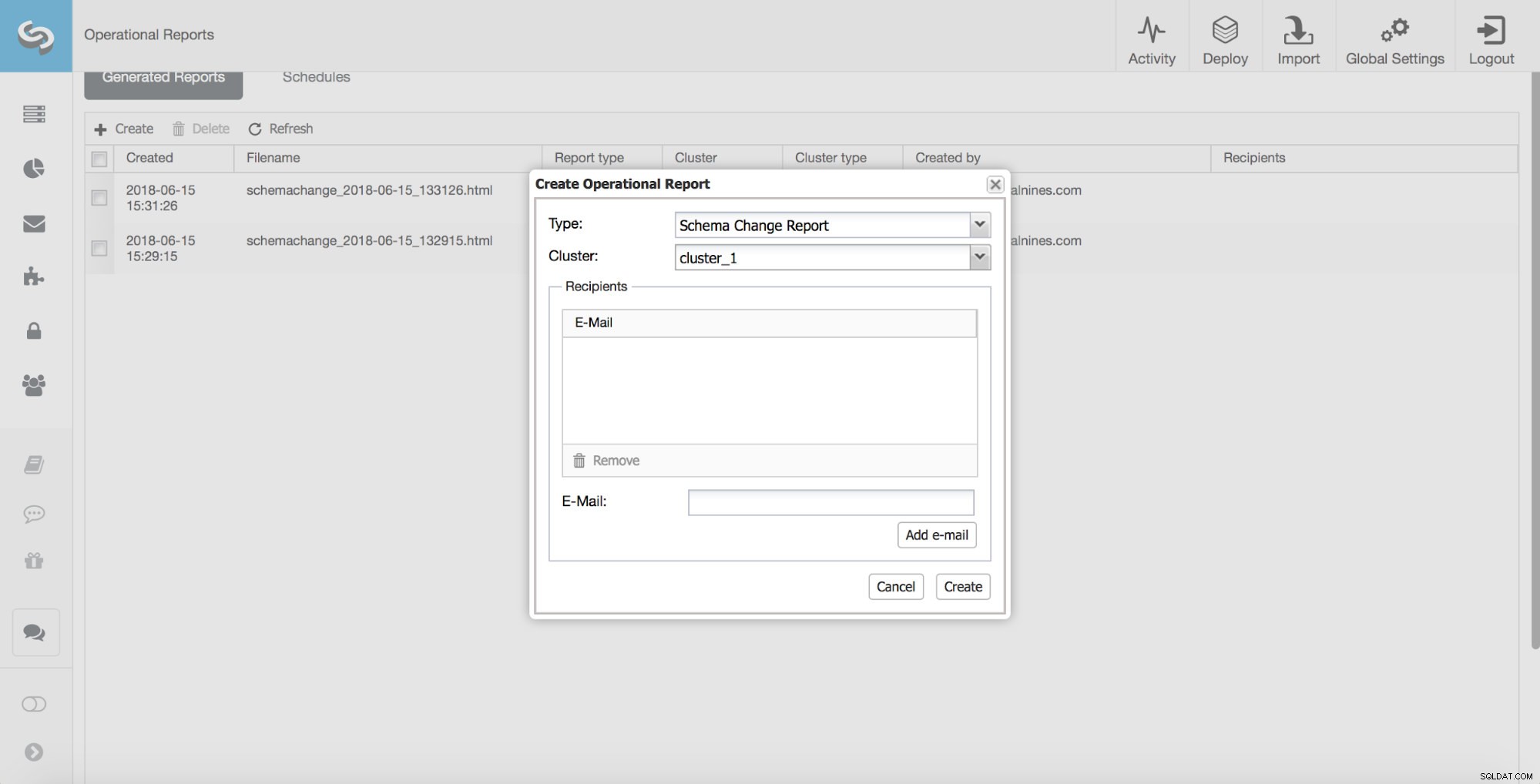
In un mondo ideale, un DBA esamina, approva e implementa tutte le modifiche allo schema. Sfortunatamente, questo non è sempre il caso. Tale processo di revisione semplicemente non va bene con lo sviluppo agile. In aggiunta a ciò, il rapporto sviluppatore-DBA è in genere piuttosto alto, il che può anche diventare un problema poiché i DBA farebbero fatica a non diventare un collo di bottiglia. Ecco perché non è raro vedere modifiche allo schema eseguite al di fuori delle conoscenze del DBA. Tuttavia, il DBA è solitamente l'unico responsabile delle prestazioni e della stabilità del database. Grazie allo Schema Change Report, ora possono tenere traccia delle modifiche allo schema.
All'inizio è necessaria una configurazione. In un file di configurazione per un determinato cluster (/etc/cmon.d/cmon_X.cnf), devi definire su quale host ClusterControl deve tenere traccia delle modifiche e quali schemi devono essere controllati.
schema_change_detection_address=10.0.0.126
schema_change_detection_databases=sbtestUna volta fatto, puoi pianificare un rapporto da eseguire regolarmente. Un esempio di output potrebbe essere come quello di seguito:
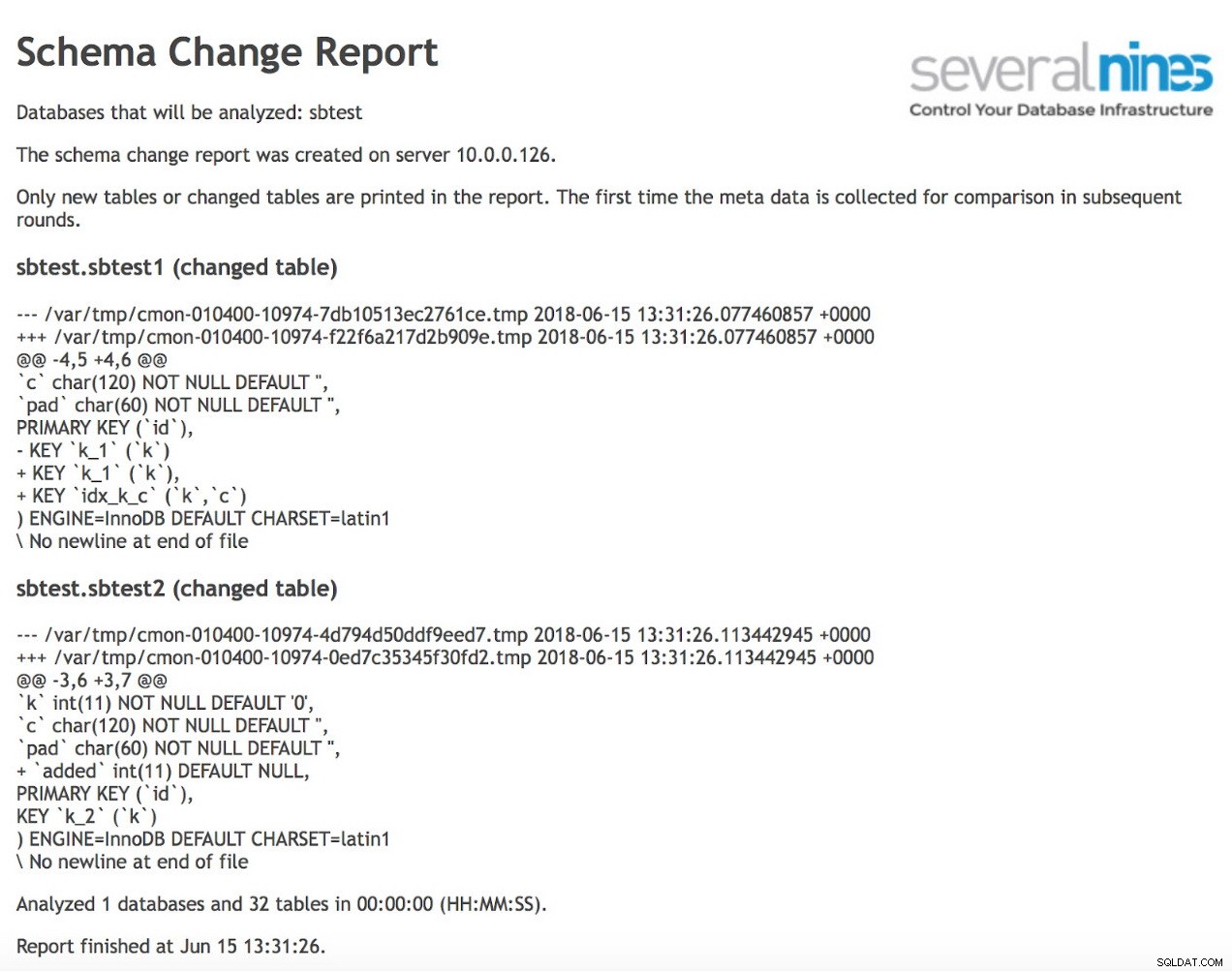
Come puoi vedere, due tabelle sono cambiate rispetto alla precedente esecuzione del report. Nella prima è stato creato un nuovo indice composito sulle colonne (k, c). Nella seconda tabella è stata aggiunta una colonna.
Nell'esecuzione successiva abbiamo ottenuto informazioni sulla nuova tabella, che è stata creata senza alcun indice o chiave primaria. Utilizzando questo tipo di informazioni, possiamo facilmente agire quando è necessario e risolvere i problemi prima che inizino effettivamente a diventare bloccanti.