[ Parte 1 | Parte 2 | Parte 3]
Nella parte 1 di questa serie, ho provato alcuni modi per comprimere una tabella da 1 TB. Anche se ho ottenuto risultati decenti nel mio primo tentativo, volevo vedere se potevo migliorare le prestazioni nella parte 2. Lì ho delineato alcune delle cose che pensavo potessero essere problemi di prestazioni e ho spiegato come partizionare meglio la tabella di destinazione per una compressione ottimale del columnstore. Ho già:
- ha partizionato la tabella in 8 partizioni (una per core);
- metti il file di dati di ciascuna partizione nel proprio filegroup; e,
- imposta la compressione dell'archivio su tutte le partizioni tranne quella "attiva".
Devo ancora fare in modo che ogni scheduler scriva esclusivamente nella propria partizione.
Innanzitutto, devo apportare modifiche alla tabella batch che ho creato. Ho bisogno di una colonna per memorizzare il numero di righe aggiunte per batch (una specie di controllo di integrità di autocontrollo) e gli orari di inizio/fine per misurare i progressi.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Successivamente, ho bisogno di creare una tabella per fornire affinità:non vogliamo mai più di un processo in esecuzione su qualsiasi scheduler, anche se ciò significa perdere del tempo per riprovare la logica. Quindi abbiamo bisogno di una tabella che tenga traccia di qualsiasi sessione su uno scheduler specifico e prevenga lo stacking:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
L'idea è che avrei otto istanze di un'applicazione (SQLQueryStress) che verrebbero eseguite ciascuna su uno scheduler dedicato, gestendo solo i dati destinati a una partizione/filegroup/file di dati specifico, ~100 milioni di righe alla volta (fare clic per ingrandire) :
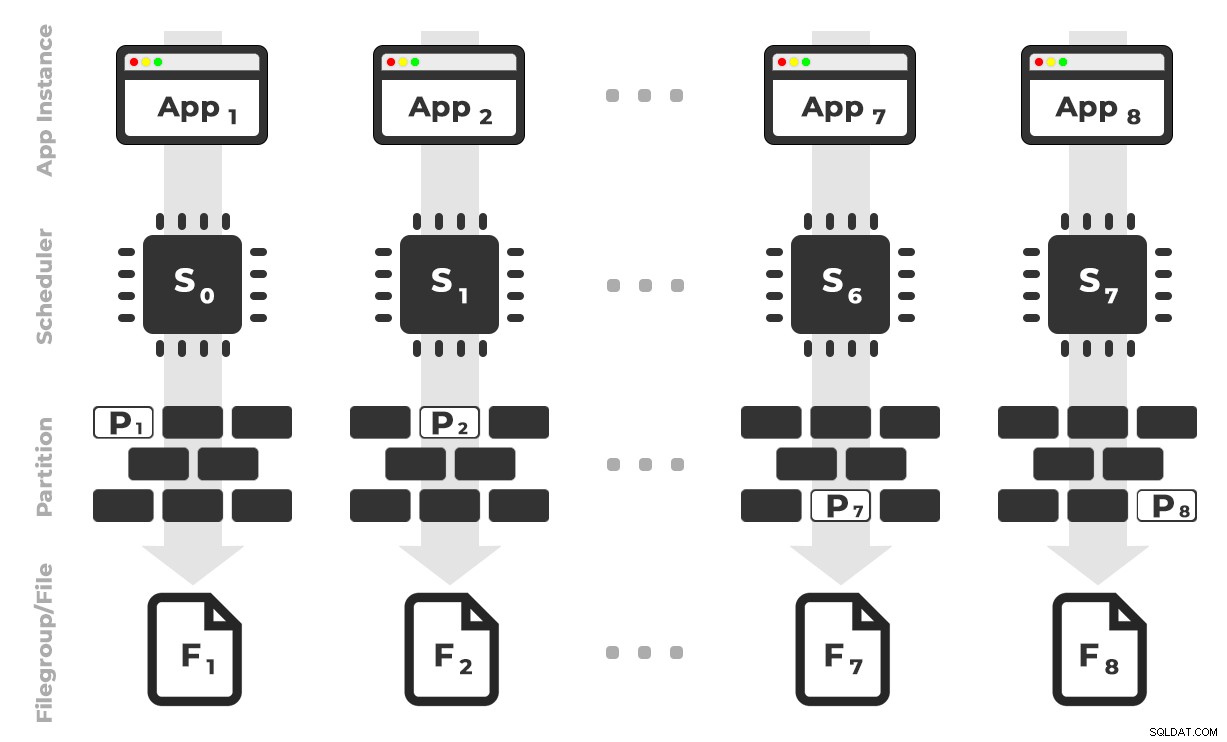 L'app 1 ottiene lo scheduler 0 e scrive nella partizione 1 sul filegroup 1 e così via …
L'app 1 ottiene lo scheduler 0 e scrive nella partizione 1 sul filegroup 1 e così via …
Successivamente abbiamo bisogno di una stored procedure che consenta a ciascuna istanza dell'applicazione di riservare tempo su un unico scheduler. Come ho accennato in un post precedente, questa non è la mia idea originale (e non l'avrei mai trovata in quella guida se non fosse stato per Joe Obbish). Ecco la procedura che ho creato in Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Semplice, vero? Avvia 8 istanze di SQLQueryStress e inserisci questo batch in ciascuna:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
 Poveri parallelismi
Poveri parallelismi
Solo che non è così semplice, dal momento che l'assegnazione del programmatore è un po' come una scatola di cioccolatini. Ci sono voluti molti tentativi per ottenere ogni istanza dell'app sullo scheduler previsto; Ispezionerei le eccezioni su una determinata istanza dell'app e cambierei il PartitionID da abbinare. Questo è il motivo per cui ho usato più di un'iterazione (ma volevo comunque solo un thread per istanza). Ad esempio, questa istanza dell'app si aspettava di essere sullo scheduler 3, ma ha ottenuto lo scheduler 4:
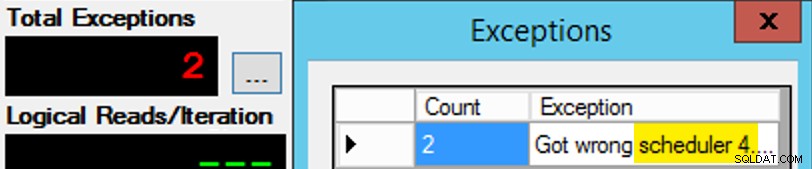 Se all'inizio non ci riesci...
Se all'inizio non ci riesci...
Ho cambiato i 3 nella finestra della query in 4 e ho riprovato. Se fossi stato veloce, l'assegnazione dello scheduler era abbastanza "appiccicosa" da poterla raccogliere e iniziare a sbuffare. Ma non sono sempre stato abbastanza veloce, quindi è stato un po' come fare un colpo a una talpa per andare avanti. Probabilmente avrei potuto escogitare una routine di ripetizione/ciclo migliore per rendere il lavoro meno manuale qui e ridurre il ritardo in modo da sapere immediatamente se funzionava o meno, ma questo era abbastanza buono per le mie esigenze. Ha anche creato uno scaglionamento non intenzionale dei tempi di inizio per ogni processo, un altro consiglio del signor Obbish.
Monitoraggio
Mentre la copia affinitizzata è in esecuzione, posso ottenere un suggerimento sullo stato corrente con le seguenti due query:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Se avessi fatto tutto bene, entrambe le query avrebbero restituito 8 righe e avrebbero mostrato letture logiche e durata incrementali. I tipi di attesa cambieranno tra PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD e occasionalmente RESERVED_MEMORY_ALLOCATION_EXT. Al termine di un batch (potrei esaminarli decommentando -- AND EndTime IS NULL , confermerei che RowsAdded = RowsInRange .
Una volta completate tutte le 8 istanze di SQLQueryStress, ho potuto semplicemente eseguire un SELECT INTO <newtable> FROM dbo.BatchQueue per registrare i risultati finali per un'analisi successiva.
Altri test
Oltre a copiare i dati nell'indice columnstore cluster partizionato che già esisteva, usando l'affinità, volevo provare anche un paio di altre cose:
- Copiare i dati nella nuova tabella senza tentare di controllare l'affinità. Ho eliminato la logica dell'affinità dalla procedura e ho lasciato al caso l'intera faccenda "spero che tu abbia il programmatore giusto". Ci è voluto più tempo perché, sicuramente, lo stacking dello scheduler ha fatto si verificano. Ad esempio, a questo punto specifico, lo scheduler 3 stava eseguendo due processi, mentre lo scheduler 0 era in pausa pranzo:
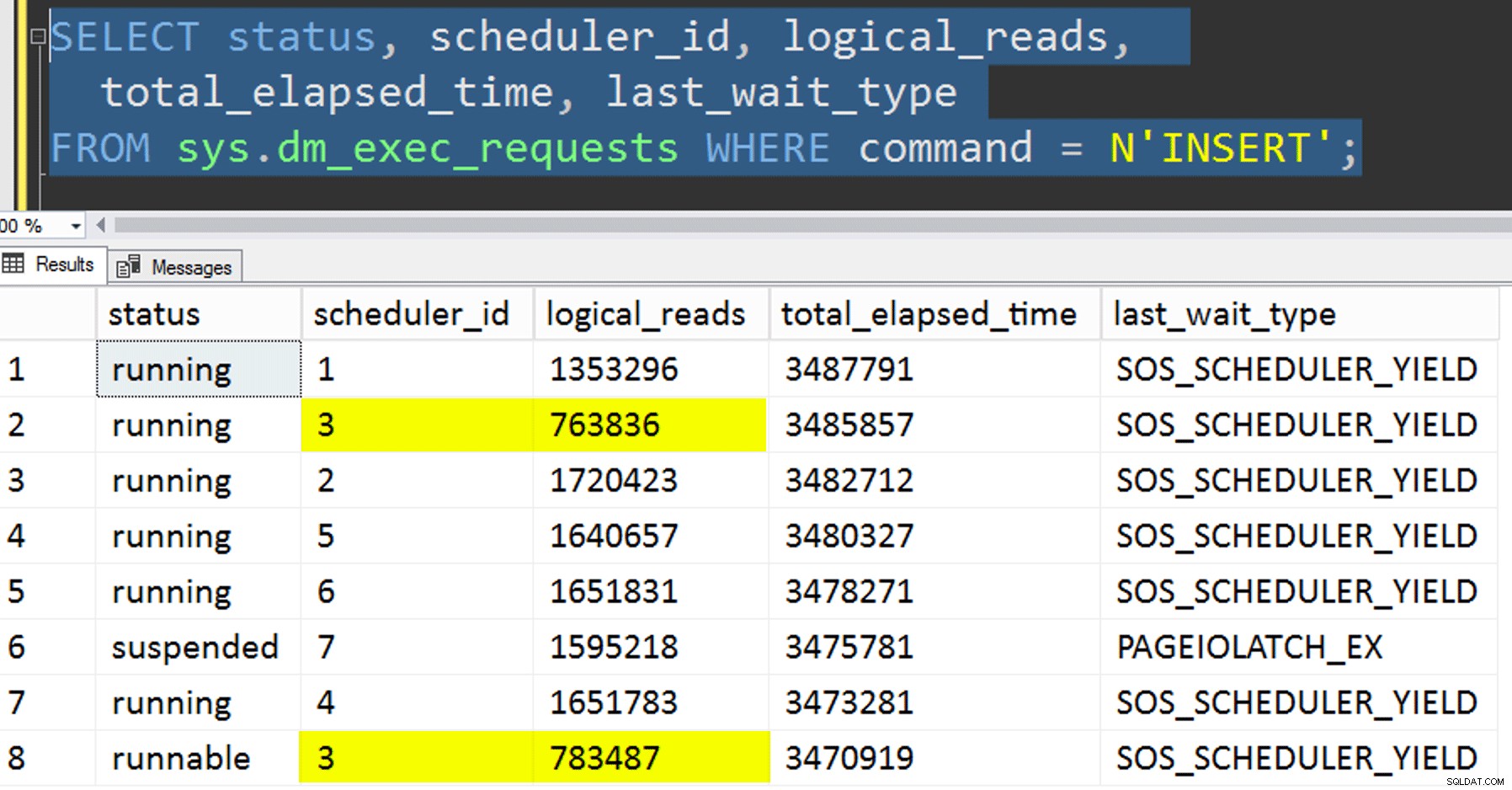 Dove sei, scheduler numero 0?
Dove sei, scheduler numero 0? - Applicazione di pagina o riga compressione (sia online che offline) alla sorgente prima la copia affinitizzata (offline), per vedere se la prima compressione dei dati potrebbe velocizzare la destinazione. Nota che la copia potrebbe essere eseguita anche online ma, come
intdi Andy Mallon abigintconversione, richiede un po' di ginnastica. Nota che in questo caso non possiamo sfruttare l'affinità della CPU (sebbene potremmo se la tabella di origine fosse già partizionata). Sono stato intelligente e ho eseguito un backup della fonte originale e ho creato una procedura per ripristinare il database al suo stato iniziale. Molto più veloce e più semplice del tentativo di ripristinare manualmente uno stato specifico.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- E infine, ricostruire prima l'indice cluster sullo schema di partizione, quindi costruire l'indice columnstore cluster su quello. Lo svantaggio di quest'ultimo è che, in SQL Server 2017, non puoi eseguirlo online... ma sarai in grado di farlo nel 2019.
Qui dobbiamo prima eliminare il vincolo PK; non puoi usare
Msg 1907, livello 16, stato 1DROP_EXISTING, poiché il vincolo univoco originale non può essere applicato dall'indice columnstore cluster e non è possibile sostituire un indice cluster univoco con un indice cluster non univoco.
Impossibile ricreare l'indice 'pk_tblOriginal'. La nuova definizione di indice non corrisponde al vincolo imposto dall'indice esistente.Tutti questi dettagli rendono questo un processo in tre fasi, solo il secondo passaggio online. Il primo passo ho solo testato esplicitamente
OFFLINE; che è stato eseguito in tre minuti, mentreONLINEHo smesso dopo 15 minuti. Una di quelle cose che forse non dovrebbe essere un'operazione di dimensione dei dati in entrambi i casi, ma la lascerò per un altro giorno.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Risultati
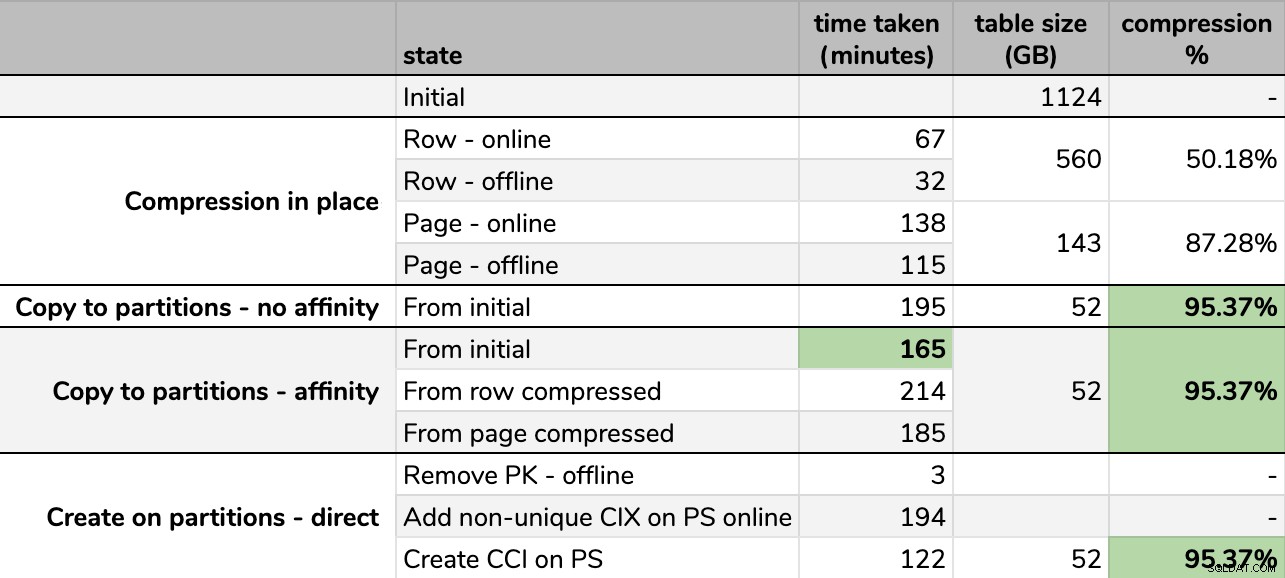
Tempi e tassi di compressione:
 Alcune opzioni sono migliori di altre
Alcune opzioni sono migliori di altre
Nota che ho arrotondato a GB perché ci sarebbero piccole differenze nella dimensione finale dopo ogni corsa, anche usando la stessa tecnica. Inoltre, i tempi per i metodi di affinità erano basati sulla media runtime di pianificazione/batch individuale, poiché alcuni pianificatori terminavano più velocemente di altri.
È difficile immaginare un'immagine esatta dal foglio di calcolo come mostrato, perché alcune attività hanno dipendenze, quindi cercherò di visualizzare le informazioni come una sequenza temporale e mostrare quanta compressione ottieni rispetto al tempo impiegato:
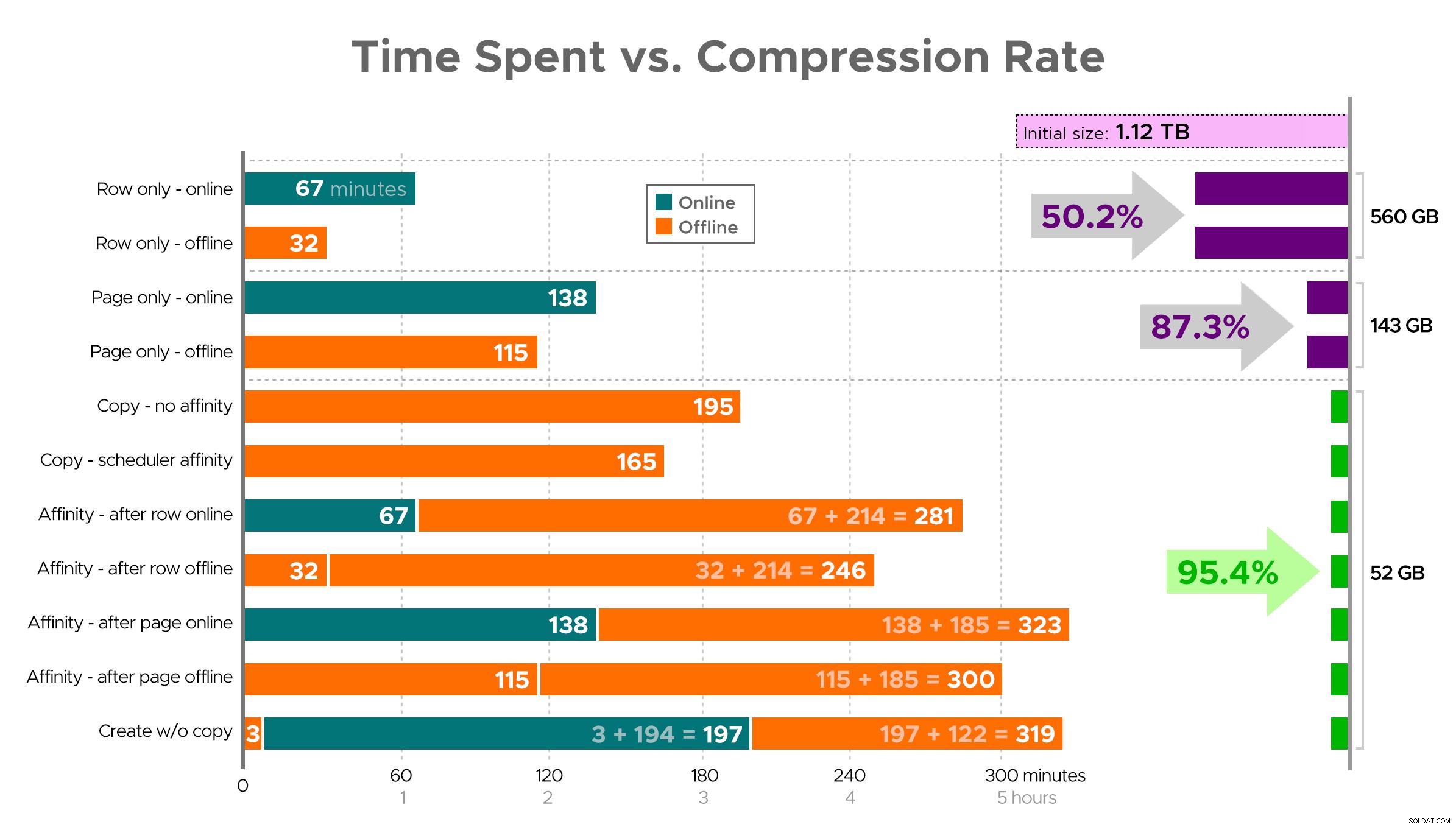 Tempo trascorso (minuti) rispetto al tasso di compressione
Tempo trascorso (minuti) rispetto al tasso di compressione
Alcune osservazioni dai risultati, con l'avvertenza che i tuoi dati potrebbero comprimersi in modo diverso (e che le operazioni online si applicano solo a te se utilizzi Enterprise Edition):
- Se la tua priorità è risparmiare spazio il più rapidamente possibile , la soluzione migliore è applicare la compressione delle righe sul posto. Se vuoi ridurre al minimo le interruzioni, usa online; se vuoi ottimizzare la velocità, usa offline.
- Se vuoi massimizzare la compressione senza interruzioni , puoi avvicinarti alla riduzione dello spazio di archiviazione del 90% senza alcuna interruzione, utilizzando la compressione della pagina online.
- Se vuoi massimizzare la compressione e l'interruzione va bene , copia i dati in una nuova versione partizionata della tabella, con un indice columnstore cluster, e utilizza il processo di affinità descritto sopra per migrare i dati. (E ancora, puoi eliminare questa interruzione se sei un pianificatore migliore di me.)
L'ultima opzione ha funzionato meglio per il mio scenario, anche se dovremo ancora dare un calcio alle gomme sui carichi di lavoro (sì, plurale). Tieni inoltre presente che in SQL Server 2019 questa tecnica potrebbe non funzionare così bene, ma puoi creare indici columnstore cluster online lì, quindi potrebbe non essere così importante.
Alcuni di questi approcci potrebbero essere più o meno accettabili per te, perché potresti preferire "rimanere disponibili" rispetto a "finire il più rapidamente possibile" o "ridurre al minimo l'utilizzo del disco" rispetto a "rimanere disponibili" o semplicemente bilanciare le prestazioni di lettura e il sovraccarico di scrittura .
Se vuoi maggiori dettagli su qualsiasi aspetto di questo, basta chiedere. Ho tagliato un po' di grasso per bilanciare i dettagli con la digeribilità, e in precedenza ho sbagliato su quell'equilibrio. Un pensiero d'addio è che sono curioso di sapere quanto sia lineare:abbiamo un altro tavolo con una struttura simile che supera i 25 TB e sono curioso di sapere se possiamo avere un impatto simile lì. Fino ad allora, buona compressione!
[ Parte 1 | Parte 2 | Parte 3]