"Waitstats ci aiuta a identificare i contatori relativi alle prestazioni. Ma le informazioni di attesa da sole non sono sufficienti per diagnosticare con precisione i problemi di prestazioni. La componente code della nostra metodologia proviene dai contatori di Performance Monitor, che forniscono una visione delle prestazioni del sistema dal punto di vista delle risorse".Tom Davidson, Apertura di Microsoft Performance-Tuning Toolbox
SQL Server Pro Magazine, dicembre 2003
Waits and Queues è stato utilizzato come metodologia di ottimizzazione delle prestazioni di SQL Server da quando Tom Davidson ha pubblicato l'articolo precedente e il noto white paper di SQL Server 2005 Waits and Queues nel 2006. Se applicati in combinazione con le metriche delle risorse, le attese possono essere utili per valutare alcune caratteristiche prestazionali del carico di lavoro e aiutare a guidare gli sforzi di messa a punto. I dati di Waits sono emersi da molte soluzioni di monitoraggio delle prestazioni di SQL Server e sono stato un sostenitore dell'ottimizzazione dell'utilizzo di questa metodologia sin dall'inizio. L'approccio è stato influente nella progettazione del dashboard delle prestazioni di SQL Sentry, che presenta le attese affiancate da code (metriche delle risorse chiave) per offrire una visione completa delle prestazioni del server.
Tuttavia, alcuni sembrano aver perso il punto di Davidson sull'importanza delle risorse e si basano quasi interamente sulle attese per presentare un quadro delle prestazioni delle query e dello stato di salute del sistema. Le statistiche di attesa provengono direttamente dal motore di SQL Server e sono facili da utilizzare e classificare. Le query in attesa significano le applicazioni e gli utenti in attesa e a nessuno piace aspettare! È più facile evangelizzare la sintonia con le attese come unica soluzione per fare query e applicazioni più velocemente che raccontare l'intera storia, che è più coinvolta.
Sfortunatamente, un approccio incentrato sull'attesa per l'esclusione dell'analisi delle risorse può fuorviare e, nel peggiore dei casi, farti volare alla cieca. I membri del team SentryOne Kevin Kline e Steve Wright hanno già toccato questo qui e qui. In questo post farò un tuffo più approfondito in alcune recenti ricerche rese possibili da Query Store che hanno gettato nuova luce su quanto possa essere davvero carente l'ottimizzazione delle attese esclusive.
Le principali domande che non lo erano
Di recente, un cliente SentryOne mi ha contattato per problemi di prestazioni con il proprio database SentryOne. C'è un unico database SQL Server al centro di ogni ambiente di monitoraggio SentryOne e questo cliente stava monitorando circa 600 server con il nostro software. Su tale scala non è insolito riscontrare problemi di prestazioni delle query occasionali e fare un po' di ottimizzazione, e alcune presunte nuove query nel carico di lavoro erano la fonte delle loro preoccupazioni.
Mi sono unito a una sessione di condivisione dello schermo per dare un'occhiata e il cliente mi ha prima presentato i dati di un sistema diverso che stava anche monitorando il database SentryOne. Il sistema utilizzava un approccio di attesa a livello di query e mostrava due stored procedure come responsabili di circa la metà delle attese sul server di database SQL Sentry. Questo era insolito perché queste due procedure vengono eseguite sempre molto rapidamente e non sono mai state indicative di un reale problema di prestazioni nel nostro database. Perplesso, sono passato a SQL Sentry per vedere cosa ci avrebbe mostrato e sono rimasto sorpreso di vedere che nello stesso intervallo la procedura n. 1 nell'altro sistema era n. 6, n. 7 e n. 8 in termini di durata totale, CPU e letture logiche rispettivamente:
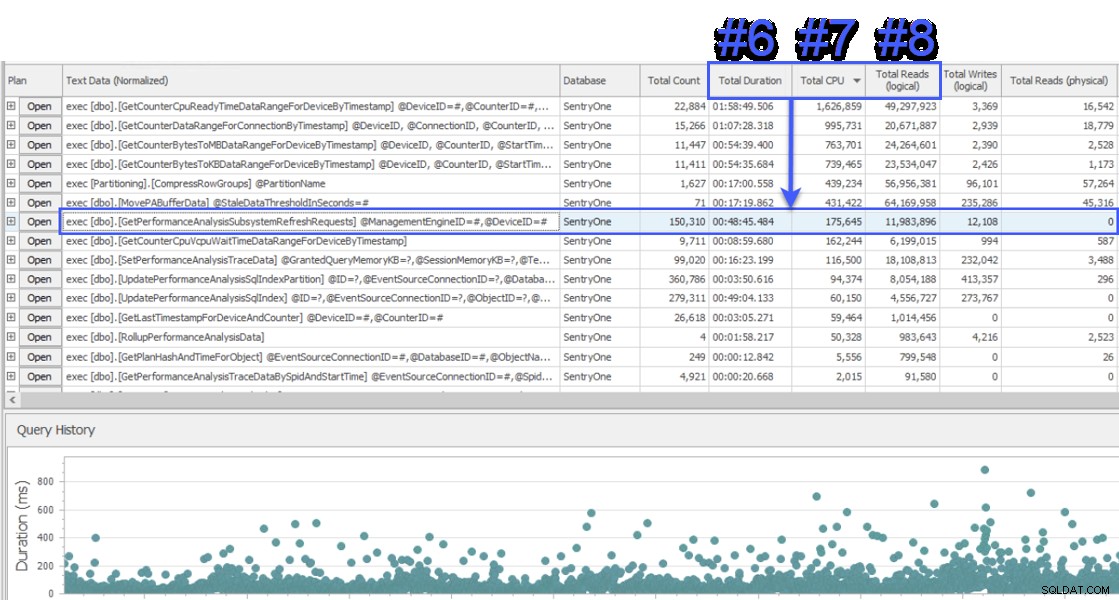 Vista "Top SQL" di SQL Sentry
Vista "Top SQL" di SQL Sentry
Dal punto di vista del consumo di risorse, ciò significava che le query sopra rappresentavano il 75% della durata totale, l'87% della CPU totale e l'88% delle letture logiche. Inoltre, la procedura n. 2 nell'altro sistema non era nemmeno tra le prime 30 in SQL Sentry, in ogni caso! Queste due query erano lontane dalle prime 2 e le query che rappresentavano la maggior parte del effettivo i consumi del sistema erano gravemente sottorappresentati.
Ho sempre pensato che ci fosse una correlazione più forte tra i migliori camerieri e i principali consumatori di risorse, ma non avevo mai eseguito un confronto diretto a livello di query come questo, quindi questi risultati sono stati a dir poco sorprendenti. Il mio interesse ha suscitato, ho deciso di indagare per determinare se questa situazione fosse tipica o anomala.
Query Store 2017 in soccorso
In SQL Server 2017 e versioni successive, Query Store acquisisce le attese a livello di query oltre al consumo delle risorse della query. Erin Stellato ha fatto un ottimo post su Query Store aspetta qui. È un sovraccarico inferiore e più accurato rispetto all'interrogazione che attende i DMV ogni secondo sperando di catturare le query in corso, l'approccio standard utilizzato da altri strumenti, incluso quello sopra menzionato.
SQL Sentry ha sempre acquisito le attese, ma a livello di istanza di SQL Server, a causa di questi problemi di sovraccarico e precisione. Le attese di query dettagliate sono disponibili su richiesta tramite Plan Explorer integrato e stiamo valutando l'aumento delle attese a livello di istanza con i dati a livello di query da Query Store, quando disponibili.
Per questo sforzo ho chiesto l'aiuto del SentryOne Product Advisory Council, un gruppo di clienti, partner e amici di SentryOne nel settore che partecipano a un canale Slack privato. Ho condiviso questo script per scaricare le 8 ore precedenti di dati da Query Store e ho ricevuto risultati per 11 server di produzione su più verticali, inclusi servizi finanziari, pubblicazione di giochi, monitoraggio del fitness e assicurazioni.
Le categorie di attesa di Query Store sono documentate qui. Tutte le categorie sono state incluse nell'analisi ad eccezione di queste, che sono state rimosse per i motivi citati:
- Parallelismo – Può gonfiare enormemente il tempo di attesa di una query ben oltre la sua durata effettiva poiché più thread possono eliminare le attese associate, confondendo la correlazione con la durata e altre metriche. Inoltre, sebbene la divisione CXPACKET/CXCONSUMER sia utile, CXPACKET significa ancora solo che hai parallelismo e non è necessariamente problematico o perseguibile.
- CPU – Il tempo di attesa del segnale può essere utile per accertare i colli di bottiglia della CPU tramite la correlazione con le attese delle risorse, ma Query Store attualmente include solo SOS_SCHEDULER_YIELD in questa categoria, che non è un'attesa nel senso tradizionale come descritto qui. Non si presta a facili confronti o correlazioni, soprattutto quando SQL Server si trova in una macchina virtuale che risiede in un host con sottoscrizione eccessiva. Ad esempio, su un server Query Store le attese della CPU sono state il 227% del tempo totale della CPU in tutte le query senza alcun parallelismo, il che non dovrebbe essere possibile.
- Aspetta utente e Inattivo – Queste categorie sono composte esclusivamente da timer e attese di coda e sono state escluse per lo stesso motivo per cui si dovrebbero sempre escludere questi tipi:sono innocui e creano solo rumore.
Per inciso, di recente ho parlato con il padre di Query Store, Conor Cunningham, della probabilità di modifiche future ai tipi e alle categorie di attesa di Query Store e ha indicato che era certamente possibile... quindi dovremo tenere d'occhio esso.
Risultati dell'analisi TL;DR
Dopo un'analisi approfondita, ho confermato che i risultati osservati sul sistema del cliente non sono anomali, ma piuttosto banali. Ciò significa che se dipendi da uno strumento incentrato sulle attese per il monitoraggio e l'ottimizzazione dei tuoi carichi di lavoro, è molto probabile che ti stia concentrando sulle query sbagliate e ti manchi i responsabili della maggior parte della durata della query e del consumo di risorse su un sistema. Poiché il consumo di CPU e IO si traduce direttamente in hardware del server e spesa per il cloud, questo è significativo.
La maggior parte delle query non attende
Una scoperta interessante e importante che tratterò per prima è che la maggior parte delle query non genera attese. Su 56.438 query totali su tutti i server, solo 9.781 (17%) hanno avuto un tempo di attesa e solo 8.092 (14%) hanno avuto un tempo di attesa da tipi significativi. Se utilizzi le attese da solo per determinare quali query ottimizzare, perderai la maggior parte delle query nel carico di lavoro.
Attese e risorse correlate
Ho analizzato il modo in cui le attese sono correlate al consumo di risorse classificando tutte le query su ciascun sistema in base alle attese e alle risorse e utilizzando i ranghi per calcolare la correlazione di Spearman. Quello che in definitiva stiamo cercando di determinare è se i migliori camerieri tendono ad essere i migliori consumatori. A quanto pare, non lo fanno.
Tabella 1 mostra i coefficienti di correlazione in scala cromatica per attesa media della query tempo ad altre misure – un valore di 1,00 (blu scuro) rappresenta un dato perfettamente correlato. Come puoi vedere, la correlazione con le attese e altre misure sulla maggior parte dei server non è forte e per un server esiste una correlazione negativa con la maggior parte delle misure.
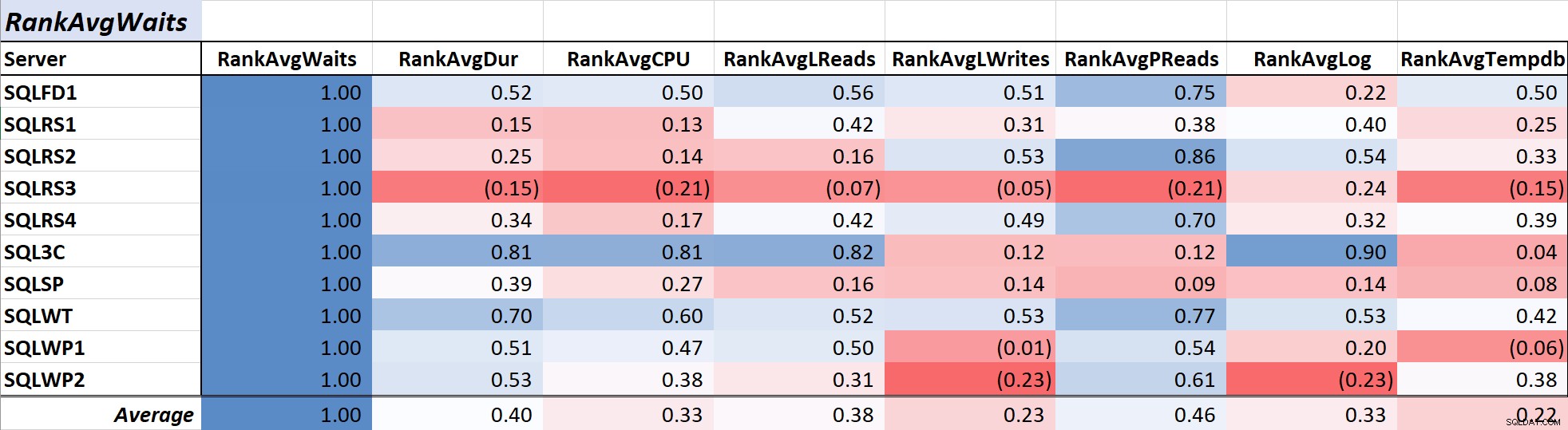 Tabella 1:correlazione con il tempo medio di attesa della query (ms)
Tabella 1:correlazione con il tempo medio di attesa della query (ms)
La durata delle query è spesso una preoccupazione primaria per i DBA e gli sviluppatori poiché si traduce direttamente nell'esperienza dell'utente e nella Tabella 2 mostra la correlazione tra la durata media della query e le altre misure. La correlazione con la durata e le due misure delle risorse primarie, CPU e letture logiche, è piuttosto forte rispettivamente a .97 e .75.
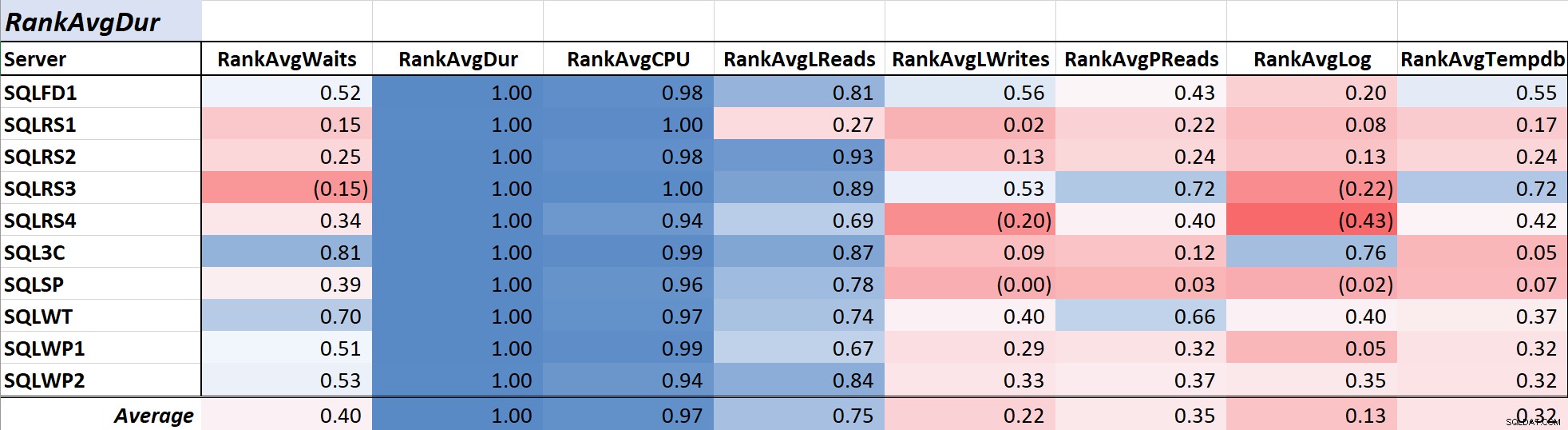 Tabella 2:correlazione con la durata media della query (ms)
Tabella 2:correlazione con la durata media della query (ms)
Poiché le letture logiche utilizzano sempre la CPU e, come la durata, la CPU viene misurata in millisecondi, questa relazione non è sorprendente. I risultati sono coerenti con l'idea che se si desidera che le applicazioni di database vengano eseguite il più velocemente possibile, concentrarsi sulla riduzione della CPU delle query e delle letture logiche sarà più efficace nel ridurre la durata rispetto all'utilizzo delle sole attese. Fortunatamente, farlo tramite una migliore progettazione delle query, indicizzazione e così via è solitamente una proposta più semplice rispetto alla riduzione diretta del tempo di attesa della query. Il collega Aaron Bertrand presenta in modo efficace alcune delle avvertenze quando si sintonizza con le attese qui.
% del tempo di attesa totale
Successivamente, ho esaminato se le query con il tempo di attesa più elevato tendono a rappresentare il maggior consumo di risorse. Vogliamo determinare se ciò che abbiamo visto sul sistema del cliente è atipico, in quanto le prime 2 query in attesa rappresentavano una percentuale relativamente piccola del consumo totale di risorse.
Grafico 1 di seguito mostra la % della CPU totale e delle letture logiche per ciascun server contabilizzato dalle query che rappresentano il 75% del tempo di attesa totale. Solo un server aveva una risorsa superiore al 75%:legge su SQLRS3. Per il resto, le query responsabili del 75% del tempo di attesa hanno consumato meno del 75% delle risorse, spesso molto meno. Ciò riflette ciò che abbiamo visto sul sistema del cliente ed è coerente con l'analisi di correlazione.
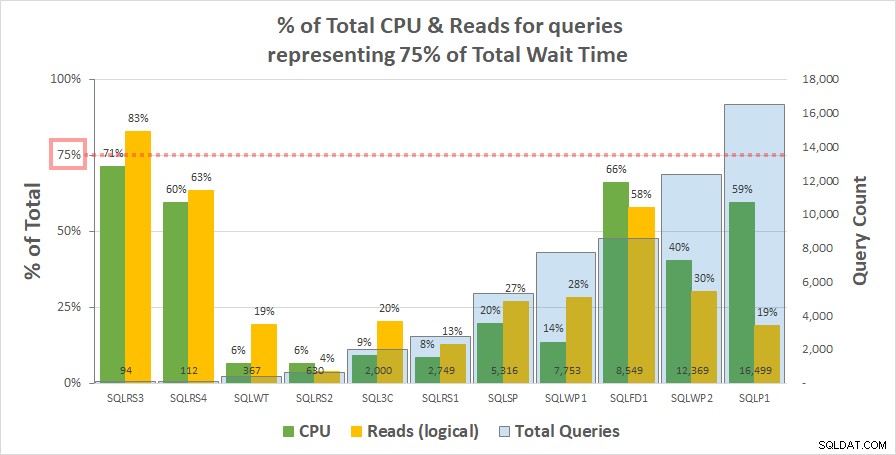 Grafico 1
Grafico 1
Si noti che sembra esserci una relazione con il numero totale di query nel carico di lavoro. Questo è rappresentato dalla serie di colonne azzurre sull'asse y secondario e il grafico è ordinato in ordine crescente in base a questa serie. I due server con le misure di risorse più elevate al 75% delle attese avevano anche il minor numero di query (SQLRS3 e SQLRS4). Minore è il carico di lavoro impostato, maggiore è l'influenza potenziale di un numero limitato di query e, in effetti, su entrambi i server solo due query hanno rappresentato la maggior parte delle attese e delle risorse. Un modo per vedere questo è che le attese aiutano di più a identificare le tue domande più pesanti quando meno ne hai bisogno.
Tempo di attesa e durata della query
Infine, ho valutato la % del tempo di attesa totale rispetto alla durata totale della query su ciascun sistema. Tabella 3 ha colonne per:
- Durata totale della query in ms
- Tempo di attesa totale ms – grezzo
- Tempo di attesa totale ms – senza parallelismo, inattività e attese utente (Rev1)
- Tempo di attesa totale ms – senza parallelismo, inattività, attese utente e CPU (Rev2)
- La % di durata per le 3 colonne del tempo di attesa, con barre di dati
- Numero totale di query univoche, con barre di dati
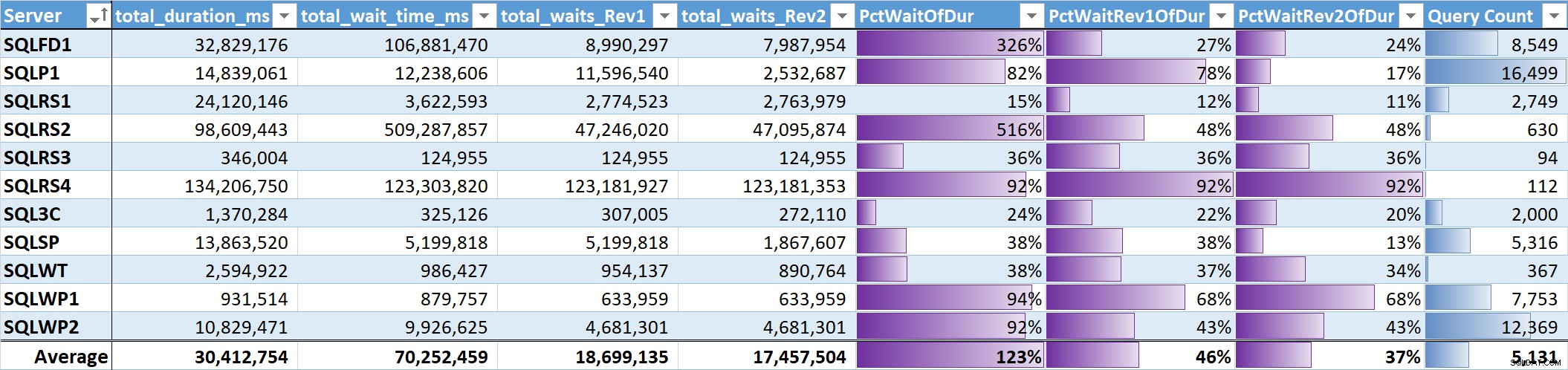 Tabella 3
Tabella 3
La media non ponderata per le attese significative (Rev2) in tutti i sistemi è il 37% della durata totale della query. Su cinque dei sistemi era inferiore al 25% e solo su due sistemi era superiore al 50%. Nel sistema con il 92% del tempo di attesa (SQLRS4), quello con il minor numero di query, due query rappresentavano il 99% delle attese, il 97% della durata, l'84% della CPU e l'86% delle letture.
Sebbene il tempo di attesa possa rappresentare una parte significativa del runtime di query su determinati sistemi, e sembra intuitivo che se si riduce anche la durata della query, abbiamo visto che il tempo di attesa e la durata sono debolmente correlati. È improbabile che sia così semplice e la mia esperienza lo conferma. Sono necessarie ulteriori ricerche qui.
Ottimizzazione completa con Plan Explorer e SQL Sentry
Come suggerisce spesso questo eccellente white paper sulle competenze SQL, la radice delle attese elevate è spesso costituita da query e indici non ottimizzati. Il SentryOne Plan Explorer gratuito è stato creato appositamente per ridurre il consumo di risorse tramite un'efficiente ottimizzazione delle query utilizzando il suo modulo di analisi dell'indice e molte altre funzionalità innovative. SQL Sentry integra Plan Explorer direttamente nei moduli Top SQL, Blocking e Deadlock, così puoi acquisire e ottimizzare automaticamente le query problematiche in un'unica posizione. È possibile selezionare facilmente un intervallo di interesse sulle attese storiche, sulla CPU o sui grafici IO del dashboard di SQL Sentry e passare alla visualizzazione SQL superiore per trovare le query che consumano più risorse durante quel periodo. Quindi con un solo clic puoi aprire una query in Plan Explorer e ottenere attese dettagliate a livello di query e risorse su richiesta quando necessario. Non credo che ci sia un'incarnazione migliore della metodologia di ottimizzazione di Waits and Queues completa di questa.
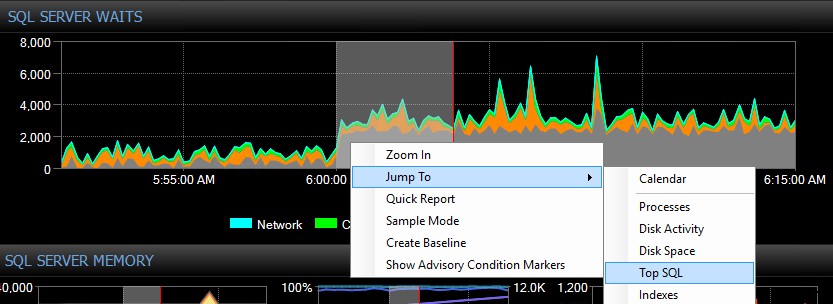 Grafico "Attese" di SQL Sentry Dashboard
Grafico "Attese" di SQL Sentry Dashboard
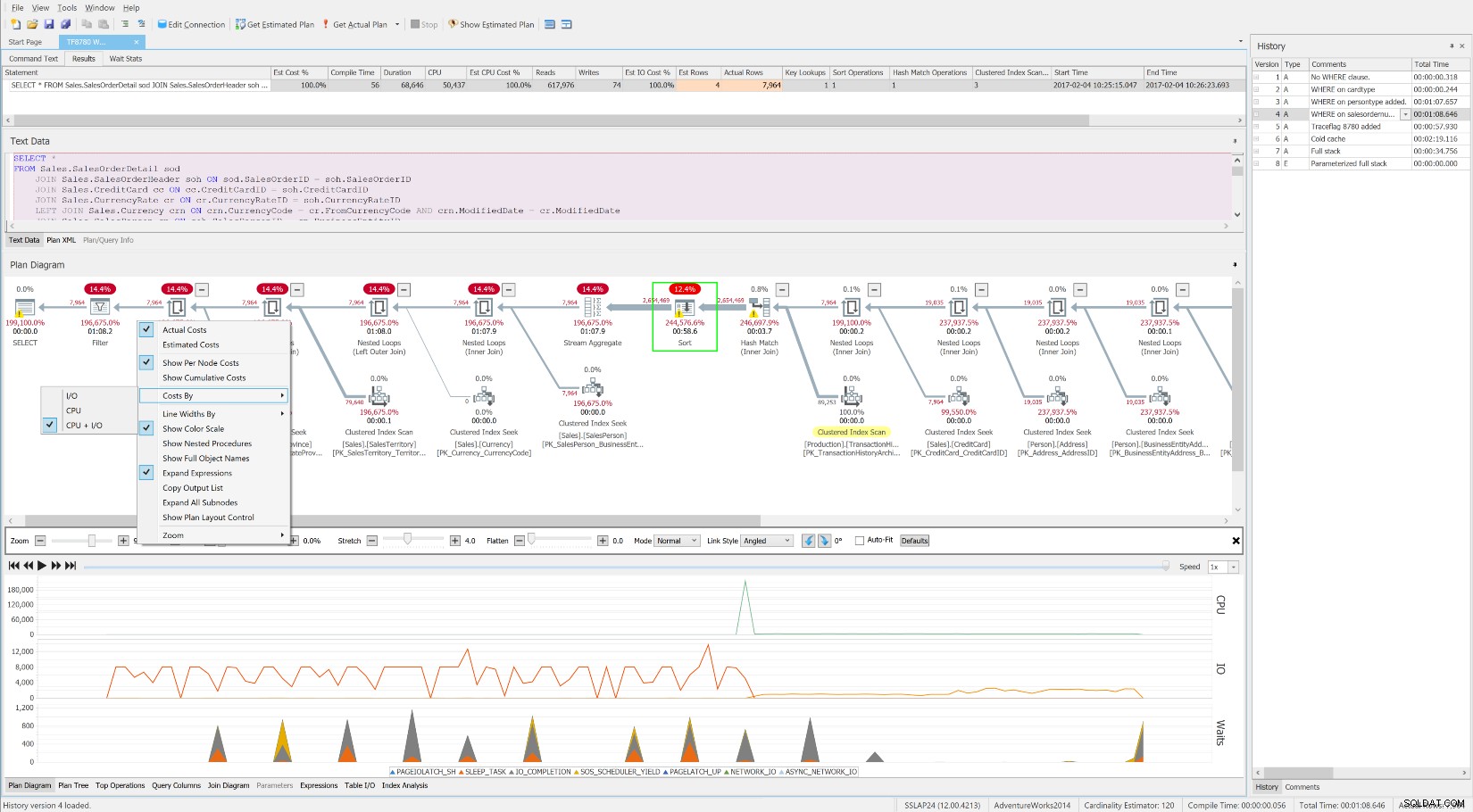 Il SentryOne Plan Explorer gratuito che mostra le attese nel tempo, insieme al livello di operazione costi e risorse
Il SentryOne Plan Explorer gratuito che mostra le attese nel tempo, insieme al livello di operazione costi e risorse
Conclusione
L'ottimizzazione con le attese e le code è applicabile alle prestazioni di SQL Server oggi come lo era nel 2006. Tuttavia, concentrarsi sulle attese fino all'esclusione delle risorse è un'attività pericolosa, poiché dai dati è chiaro che ciò porterà a risultati generalmente non ottimizzati e sistemi inefficienti in termini di costi. Quando si tratta di risorse hardware e spesa per il cloud, alla fine paghi per le risorse di elaborazione e IO, non per i tempi di attesa, quindi è opportuno ottimizzare direttamente per il consumo. In base alla mia esperienza, poiché il consumo di risorse e la relativa contesa si riducono, seguirà naturalmente una riduzione del tempo di attesa.
Riconoscimento
Volevo ringraziare Fred Frost, Lead Data Scientist di SentryOne, per il suo prezioso contributo e la sua revisione critica di questa analisi.