I parametri con valori di tabella esistono da SQL Server 2008 e forniscono un meccanismo utile per inviare più righe di dati a SQL Server, riunite come un'unica chiamata parametrizzata. Tutte le righe sono quindi disponibili in una variabile di tabella che può quindi essere utilizzata nella codifica T-SQL standard, eliminando la necessità di scrivere una logica di elaborazione specializzata per suddividere nuovamente i dati. Per la loro stessa definizione, i parametri con valori di tabella sono fortemente tipizzati in un tipo di tabella definito dall'utente che deve esistere all'interno del database in cui viene effettuata la chiamata. Tuttavia, la tipizzazione forte non è in realtà strettamente "tipizzata forte" come ti aspetteresti, come dimostrerà questo articolo e di conseguenza le prestazioni potrebbero risentirne.
Per dimostrare i potenziali impatti sulle prestazioni di parametri con valori di tabella digitati in modo errato con SQL Server, creeremo un tipo di tabella definito dall'utente di esempio con la struttura seguente:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Quindi avremo bisogno di un'applicazione .NET che utilizzerà questo tipo di tabella definito dall'utente come parametro di input per il passaggio di dati in SQL Server. Per utilizzare un parametro con valori di tabella dalla nostra applicazione, un oggetto DataTable viene in genere popolato e quindi passato come valore per il parametro con un tipo di SqlDbType.Structured. Il DataTable può essere creato in più modi nel codice .NET, ma un modo comune per creare la tabella è simile al seguente:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); Puoi anche creare la DataTable usando la definizione inline come segue:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; Una di queste definizioni dell'oggetto DataTable in .NET può essere utilizzata come parametro con valori di tabella per il tipo di dati definito dall'utente che è stato creato, ma tenere presente la definizione typeof(string) per le varie colonne di stringa; questi possono essere tutti tipizzati "correttamente" ma in realtà non sono fortemente tipizzati per i tipi di dati implementati nel tipo di dati definito dall'utente. Possiamo popolare la tabella con dati casuali e passarli a SQL Server come parametro per un'istruzione SELECT molto semplice che restituirà le stesse identiche righe della tabella che abbiamo passato, come segue:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
} Possiamo quindi utilizzare un'interruzione di debug in modo da poter controllare la definizione di DefaultTable durante l'esecuzione, come mostrato di seguito:
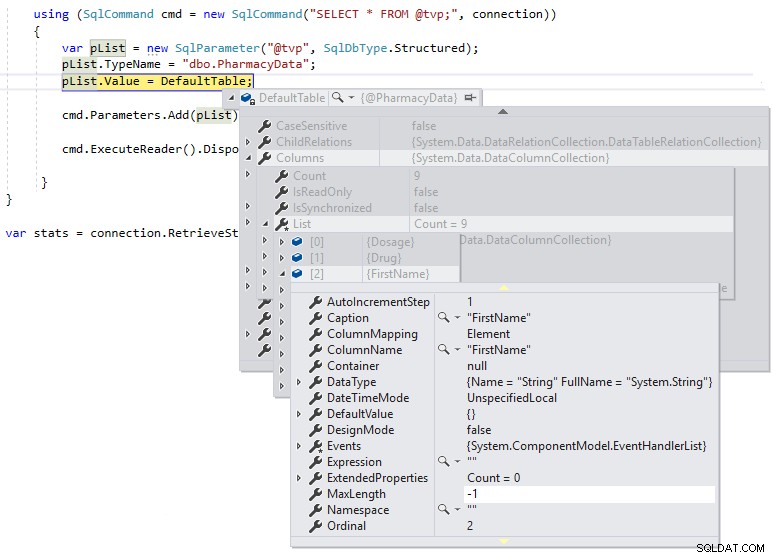
Possiamo vedere che MaxLength per le colonne di stringa è impostato su -1, il che significa che vengono passate su TDS a SQL Server come LOB (Large Objects) o essenzialmente come colonne con tipi di dati MAX e questo può influire negativamente sulle prestazioni. Se modifichiamo la definizione di .NET DataTable in modo che sia fortemente tipizzata nella definizione dello schema del tipo di tabella definito dall'utente come segue e osserviamo la MaxLength della stessa colonna usando un'interruzione di debug:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};
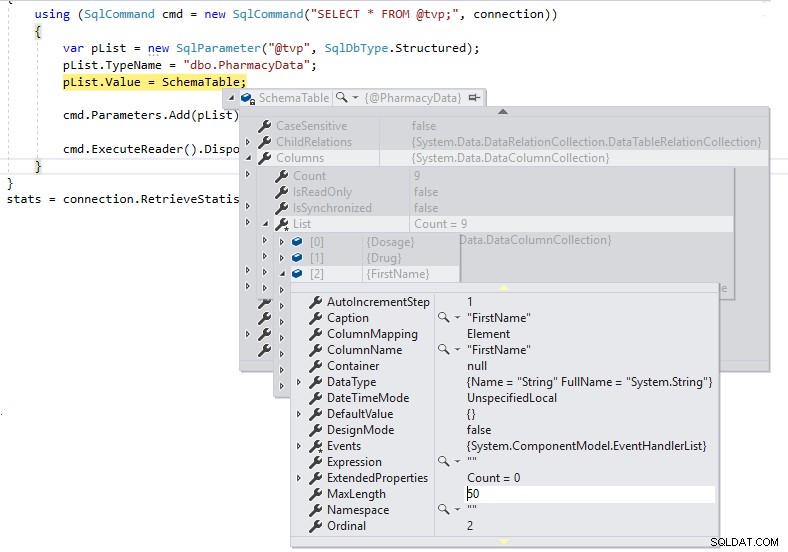
Ora abbiamo lunghezze corrette per le definizioni di colonna e non le passeremo come LOB su TDS a SQL Server.
In che modo questo influisce sulle prestazioni, potresti chiederti? Influisce sul numero di buffer TDS inviati attraverso la rete a SQL Server e influisce anche sul tempo di elaborazione complessivo per i comandi.
Utilizzando lo stesso identico set di dati per le due tabelle di dati e sfruttando il metodo RetrieveStatistics sull'oggetto SqlConnection ci consente di ottenere le metriche statistiche ExecutionTime e BuffersSent per le chiamate allo stesso comando SELECT e semplicemente utilizzando le due diverse definizioni di DataTable come parametri e la chiamata del metodo ResetStatistics dell'oggetto SqlConnection consente di cancellare le statistiche di esecuzione tra i test.
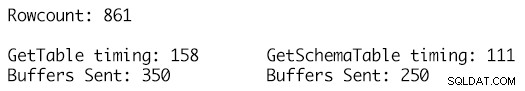
La definizione GetSchemaTable specifica correttamente MaxLength per ciascuna delle colonne della stringa in cui GetTable aggiunge semplicemente colonne di tipo string che hanno un valore MaxLength impostato su -1 con conseguente 100 buffer TDS aggiuntivi inviati per 861 righe di dati nella tabella e un runtime di 158 millisecondi rispetto ai soli 250 buffer inviati per la definizione DataTable fortemente tipizzata e un tempo di esecuzione di 111 millisecondi. Anche se questo potrebbe non sembrare molto nel grande schema delle cose, questa è una singola chiamata, una singola esecuzione e l'impatto accumulato nel tempo per molte migliaia o milioni di tali esecuzioni è dove i vantaggi iniziano a sommarsi e ad avere un impatto notevole sulle prestazioni del carico di lavoro e sul throughput.
Laddove questo può davvero fare la differenza è nelle implementazioni cloud in cui stai pagando per qualcosa di più delle semplici risorse di calcolo e archiviazione. Oltre ai costi fissi delle risorse hardware per VM di Azure, database SQL o AWS EC2 o RDS, è previsto un costo aggiuntivo per il traffico di rete da e verso il cloud che viene aggiunto alla fatturazione mensile. La riduzione dei buffer che attraversano il cavo abbasserà il TCO per la soluzione nel tempo e le modifiche al codice necessarie per implementare questi risparmi sono relativamente semplici.