SQL Server 2014 ha introdotto molte nuove funzionalità che i DBA e gli sviluppatori non vedevano l'ora di testare e utilizzare nei loro ambienti, come l'indice Columnstore in cluster aggiornabile, la durata ritardata e le estensioni del pool di buffer. Una caratteristica non discussa spesso è la statistica incrementale. A meno che non utilizzi il partizionamento, questa non è una funzionalità che puoi implementare. Ma se hai delle tabelle partizionate nel tuo database, le statistiche incrementali potrebbero essere qualcosa che stavi aspettando con impazienza.
Nota:Benjamin Nevarez ha trattato alcune nozioni di base relative alle statistiche incrementali nel suo post di febbraio 2014, Statistiche incrementali di SQL Server 2014. E sebbene non sia cambiato molto nel modo in cui questa funzione funziona dal suo post e dal rilascio di aprile 2014, sembrava un buon momento per approfondire come l'abilitazione delle statistiche incrementali può aiutare con le prestazioni di manutenzione.
Le statistiche incrementali sono talvolta chiamate statistiche a livello di partizione e questo perché per la prima volta SQL Server può creare automaticamente statistiche specifiche per una partizione. Una delle precedenti sfide con il partizionamento era che, anche se avresti potuto avere da 1 a n partizioni per una tabella, c'era solo una (1) statistica che rappresentava la distribuzione dei dati in tutte quelle partizioni. È possibile creare statistiche filtrate per la tabella partizionata, una statistica per ogni partizione, per fornire a Query Optimizer informazioni migliori sulla distribuzione dei dati. Ma questo era un processo manuale e richiedeva uno script per crearli automaticamente per ogni nuova partizione.
In SQL Server 2014 si usa STATISTICS_INCREMENTAL opzione per fare in modo che SQL Server crei automaticamente quelle statistiche a livello di partizione. Tuttavia, queste statistiche non vengono utilizzate come potresti pensare.
Ho accennato in precedenza che, prima del 2014, era possibile creare statistiche filtrate per fornire all'ottimizzatore informazioni migliori sulle partizioni. Quelle statistiche incrementali? Non sono attualmente utilizzati dall'ottimizzatore. Query Optimizer utilizza ancora solo l'istogramma principale che rappresenta l'intera tabella. (Post a venire che lo dimostrerà!)
Allora, qual è il punto delle statistiche incrementali? Se si presume che vengano modificati solo i dati nella partizione più recente, idealmente si aggiornano solo le statistiche per quella partizione. Puoi farlo ora con le statistiche incrementali e quello che succede è che le informazioni vengono quindi rifuse nell'istogramma principale. L'istogramma per l'intera tabella si aggiornerà senza dover leggere l'intera tabella per aggiornare le statistiche e questo può aiutare con l'esecuzione delle tue attività di manutenzione.
Configurazione
Inizieremo con la creazione di una funzione e di uno schema di partizione, quindi una nuova tabella che partizioneremo. Nota che ho creato un filegroup per ogni funzione di partizione come potresti fare in un ambiente di produzione. Puoi creare lo schema di partizione sullo stesso filegroup (ad es. PRIMARY ) se non è possibile eliminare facilmente il database di test. Ogni filegroup ha anche una dimensione di pochi GB, poiché aggiungeremo quasi 400 milioni di righe.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Prima di aggiungere i dati, creeremo l'indice cluster e noteremo che la sintassi include WITH (STATISTICS_INCREMENTAL = ON) opzione:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
La cosa interessante da notare qui è che se guardi il ALTER TABLE voce in MSDN, non include questa opzione. Lo troverai solo in ALTER INDEX voce... ma funziona. Se vuoi seguire la documentazione alla lettera, esegui:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Una volta che l'indice cluster è stato creato per lo schema di partizione, caricheremo i nostri dati e quindi verificheremo quante righe esistono per partizione (tieni presente che ci vogliono oltre 7 minuti sul mio laptop, potresti voler aggiungere meno righe a seconda di quanto spazio di archiviazione (e tempo) hai a disposizione):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
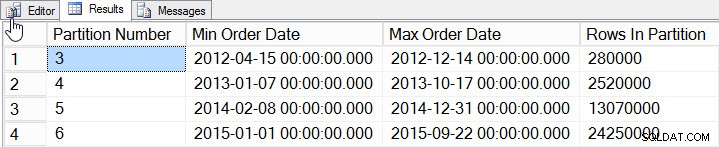 Dati per partizione
Dati per partizione
Abbiamo aggiunto i dati dal 2012 al 2015, con molti più dati nel 2014 e nel 2015. Vediamo come appaiono le nostre statistiche:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
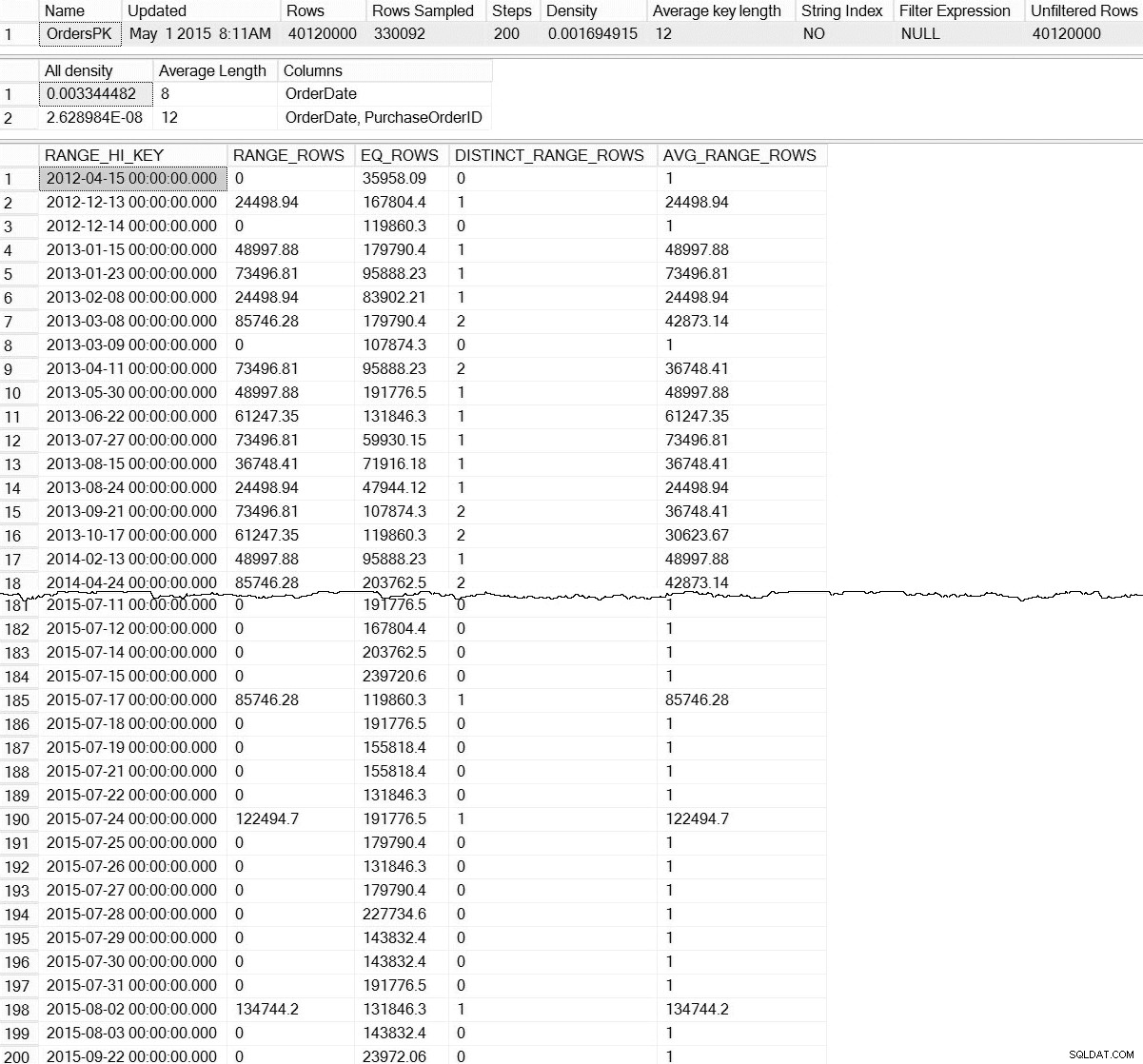 Output DBCC SHOW_STATISTICS per dbo.Orders (fai clic per ingrandire)
Output DBCC SHOW_STATISTICS per dbo.Orders (fai clic per ingrandire)
Con il valore predefinito DBCC SHOW_STATISTICS comando, non abbiamo alcuna informazione sulle statistiche a livello di partizione. Non aver paura; non siamo completamente condannati:esiste una funzione di gestione dinamica non documentata, sys.dm_db_stats_properties_internal . Ricorda che non documentato significa che non è supportato (non esiste una voce MSDN per DMF) e che può cambiare in qualsiasi momento senza alcun avviso da parte di Microsoft. Detto questo, è un buon inizio per avere un'idea di ciò che esiste per le nostre statistiche incrementali:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Informazioni sull'istogramma da dm_db_stats_properties_internal (fare clic per ingrandire)
Informazioni sull'istogramma da dm_db_stats_properties_internal (fare clic per ingrandire)
Questo è molto più interessante. Qui possiamo vedere la prova che esistono statistiche a livello di partizione (e altro). Poiché questo DMF non è documentato, dobbiamo fare qualche interpretazione. Per oggi, ci concentreremo sulle prime sette righe nell'output, dove la prima riga rappresenta l'istogramma per l'intera tabella (nota le rows valore di 40 milioni) e le righe successive rappresentano gli istogrammi per ciascuna partizione. Sfortunatamente, il partition_number il valore in questo istogramma non si allinea con il numero di partizione da sys.dm_db_index_physical_stats per il partizionamento a destra (correla correttamente per il partizionamento a sinistra). Nota inoltre che questo output include anche last_updated e modification_counter colonne, che sono utili durante la risoluzione dei problemi e possono essere utilizzate per sviluppare script di manutenzione che aggiornano in modo intelligente le statistiche in base all'età o alle modifiche delle righe.
Ridurre al minimo la manutenzione
Il valore principale delle statistiche incrementali in questo momento è la possibilità di aggiornare le statistiche per una partizione e farle unire nell'istogramma a livello di tabella, senza dover aggiornare la statistica per l'intera tabella (e quindi leggere l'intera tabella). Per vederlo in azione, aggiorniamo prima le statistiche per la partizione che contiene i dati del 2015, la partizione 5, e registreremo il tempo impiegato e faremo uno snapshot del sys.dm_io_virtual_file_stats DMF prima e dopo per vedere quanto I/O si verifica:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Uscita:
Tempi di esecuzione di SQL Server:Tempo CPU =203 ms, tempo trascorso =240 ms.
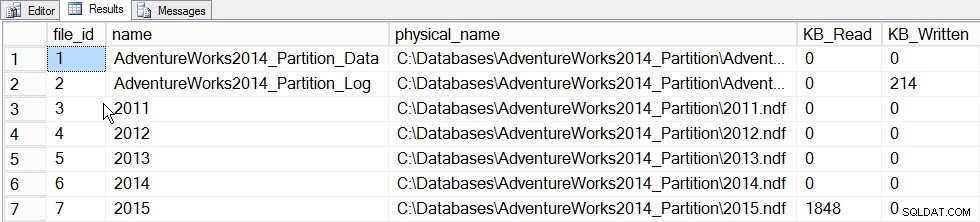 Dati File_stats dopo l'aggiornamento di una partizione
Dati File_stats dopo l'aggiornamento di una partizione
Se osserviamo il sys.dm_db_stats_properties_internal output, vediamo che last_updated modificato sia per l'istogramma 2015 che per l'istogramma a livello di tabella (così come per alcuni altri nodi, che è per un'indagine successiva):
 Informazioni sull'istogramma aggiornate da dm_db_stats_properties_internal
Informazioni sull'istogramma aggiornate da dm_db_stats_properties_internal
Ora aggiorneremo le statistiche con un FULLSCAN per la tabella, e faremo un'istantanea di file_stats prima e dopo ancora:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Uscita:
Tempi di esecuzione di SQL Server:Tempo CPU =12720 ms, tempo trascorso =13646 ms
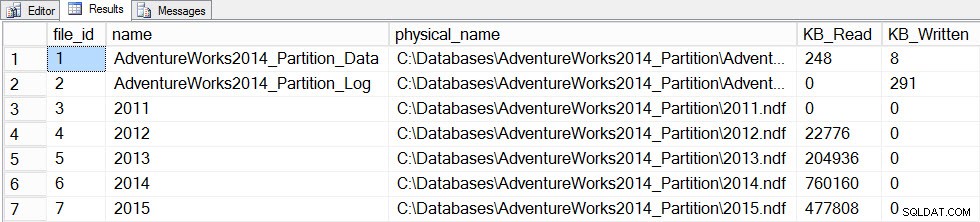 Dati delle statistiche dopo l'aggiornamento con una scansione completa
Dati delle statistiche dopo l'aggiornamento con una scansione completa
L'aggiornamento ha richiesto molto più tempo (13 secondi contro un paio di centinaia di millisecondi) e ha generato molto più I/O. Se controlliamo sys.dm_db_stats_properties_internal di nuovo, troviamo che last_updated modificato per tutti gli istogrammi:
 Informazioni sull'istogramma da dm_db_stats_properties_internal dopo una scansione completa
Informazioni sull'istogramma da dm_db_stats_properties_internal dopo una scansione completa
Riepilogo
Sebbene le statistiche incrementali non siano ancora utilizzate da Query Optimizer per fornire informazioni su ciascuna partizione, forniscono un vantaggio in termini di prestazioni durante la gestione delle statistiche per le tabelle partizionate. Se le statistiche devono essere aggiornate solo per partizioni selezionate, è possibile aggiornare solo quelle. Le nuove informazioni vengono quindi unite nell'istogramma a livello di tabella, fornendo all'ottimizzatore informazioni più aggiornate, senza il costo della lettura dell'intera tabella. In futuro, ci auguriamo che le statistiche a livello di partizione saranno essere utilizzato dall'ottimizzatore. Resta sintonizzato...