Predicati singoli
La stima del numero di righe qualificate da un singolo predicato di query è spesso semplice. Quando un predicato effettua un semplice confronto tra una colonna e un valore scalare, è molto probabile che lo stimatore di cardinalità sarà in grado di ricavare una stima di buona qualità dall'istogramma delle statistiche. Ad esempio, la seguente query AdventureWorks produce una stima esatta di 203 righe (supponendo che non siano state apportate modifiche ai dati dalla creazione delle statistiche):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
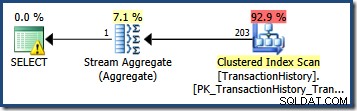
Osservando l'istogramma delle statistiche per TransactionDate colonna, è chiaro da dove proviene questa stima:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
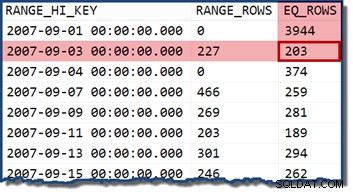
Se modifichiamo la query per specificare una data che rientra in un bucket dell'istogramma, lo stimatore di cardinalità presuppone che i valori siano distribuiti uniformemente. Utilizzando una data di 2007-09-02 produce una stima di 227 righe (da RANGE_ROWS iscrizione). Come nota a margine interessante, la stima rimane a 227 righe indipendentemente da qualsiasi porzione di tempo che potremmo aggiungere al valore della data (il TransactionDate la colonna è un datetime tipo di dati).
Se proviamo di nuovo la query con una data di 2007-09-05 o 2007-09-06 (entrambi rientrano tra il 2007-09-04 e 2007-09-07 istogramma), lo stimatore di cardinalità assume 466 RANGE_ROWS sono equamente divisi tra i due valori, stimando 233 righe in entrambi i casi.
Ci sono molti altri dettagli sulla stima della cardinalità per predicati semplici, ma quanto sopra servirà come aggiornamento per i nostri scopi attuali.
I problemi dei predicati multipli
Quando una query contiene più di un predicato di colonna, la stima della cardinalità diventa più difficile. Considera la seguente query con due semplici predicati (ciascuno dei quali è facile da stimare da solo):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; Gli intervalli di valori specifici nella query vengono scelti deliberatamente in modo che entrambi i predicati identifichino esattamente le stesse righe. Potremmo facilmente modificare i valori della query per ottenere qualsiasi sovrapposizione, inclusa nessuna sovrapposizione. Immagina ora di essere lo stimatore di cardinalità:come trarresti una stima di cardinalità per questa query?
Il problema è più difficile di quanto potrebbe sembrare a prima vista. Per impostazione predefinita, SQL Server crea automaticamente statistiche a colonna singola su entrambe le colonne del predicato. Possiamo anche creare manualmente statistiche multicolonna. Questo ci fornisce informazioni sufficienti per produrre una buona stima per questi valori specifici? Che dire del caso più generale in cui potrebbero essercene qualsiasi grado di sovrapposizione?
Utilizzando i due oggetti statistici a colonna singola, possiamo facilmente ricavare una stima per ciascun predicato utilizzando il metodo dell'istogramma descritto nella sezione precedente. Per i valori specifici nella query precedente, gli istogrammi mostrano che il TransactionID l'intervallo dovrebbe corrispondere a 68412.4 righe e il TransactionDate l'intervallo dovrebbe corrispondere a 68.413 righe. (Se gli istogrammi fossero perfetti, questi due numeri sarebbero esattamente gli stessi.)
Cosa gli istogrammi non possono dicci quanti di questi due insiemi di righe saranno le stesse righe . Tutto ciò che possiamo dire in base alle informazioni dell'istogramma è che la nostra stima dovrebbe essere compresa tra zero (per nessuna sovrapposizione) e 68412,4 righe (sovrapposizione completa).
La creazione di statistiche su più colonne non fornisce assistenza per questa query (o per le query di intervallo in generale). Le statistiche multicolonna creano ancora solo un istogramma sulla prima colonna denominata, duplicando essenzialmente l'istogramma associato a una delle statistiche create automaticamente. La densità aggiuntiva le informazioni fornite dalla statistica a più colonne possono essere utili per fornire informazioni di casi medi per query che contengono più predicati di uguaglianza, ma qui non ci aiutano.
Per produrre una stima con un alto grado di confidenza, avremmo bisogno di SQL Server per fornire informazioni migliori sulla distribuzione dei dati, qualcosa come un multidimensionale istogramma delle statistiche. Per quanto ne so, nessun motore di database commerciale offre attualmente una struttura come questa, sebbene siano stati pubblicati diversi documenti tecnici sull'argomento (incluso uno di Microsoft Research che utilizzava uno sviluppo interno di SQL Server 2000).
Senza sapere nulla delle correlazioni dei dati e delle sovrapposizioni per particolari intervalli di valori, non è chiaro come procedere per produrre una buona stima per la nostra query. Quindi, cosa fa SQL Server qui?
SQL Server 7 – 2012
Lo stimatore di cardinalità in queste versioni di SQL Server presuppone in genere che i valori di attributi diversi in una tabella siano distribuiti in modo completamente indipendente l'uno dall'altro. Questa ipotesi di indipendenza è raramente una riproduzione accurata dei dati reali, ma ha il vantaggio di semplificare i calcoli.
E Selettività
Usando l'ipotesi di indipendenza, due predicati collegati da AND (noto come congiunzione ) con selettività S1 e S2 , risulta in una selettività combinata di:
(S1 * S2)
Nel caso in cui il termine non ti sia familiare, selettività è un numero compreso tra 0 e 1, che rappresenta la frazione di righe nella tabella che superano il predicato. Ad esempio, se un predicato seleziona 12 righe da una tabella di 100 righe, la selettività è (12/100) =0,12.
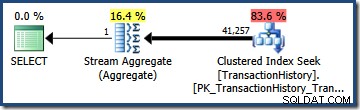
Nel nostro esempio, la TransactionHistory la tabella contiene 113.443 righe in totale. Il predicato su TransactionID è stimato (dall'istogramma) per qualificare 68.412,4 righe, quindi la selettività è (68.412,4 / 113.443) o circa 0,603055 . Il predicato su TransactionDate allo stesso modo si stima che abbia una selettività di (68.413 / 113.443) =circa 0,603061 .
Moltiplicando le due selettività (usando la formula sopra) si ottiene una stima della selettività combinata di 0,363679 . Moltiplicando questa selettività per la cardinalità della tabella (113.443) si ottiene la stima finale di 41.256,8 righe:
OPPURE Selettività
Due predicati collegati da OR (una disgiunzione ) con selettività S1 e S2 , risulta in una selettività combinata di:
(S1 + S2) – (S1 * S2)
L'intuizione alla base della formula è sommare le due selettività, quindi sottrarre la stima per la loro congiunzione (usando la formula precedente). Chiaramente potremmo avere due predicati, ciascuno di selettività 0,8, ma semplicemente sommandoli insieme produrrebbe un'impossibile selettività combinata di 1,6. Nonostante l'ipotesi di indipendenza, dobbiamo riconoscere che i due predicati possono avere una sovrapposizione, quindi per evitare il doppio conteggio, viene sottratta la selettività stimata della congiunzione.
Possiamo facilmente modificare il nostro esempio in esecuzione per utilizzare OR :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
Sostituendo le selettività del predicato in OR la formula fornisce una selettività combinata di:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Moltiplicata per il numero di righe nella tabella, questa selettività fornisce la stima finale della cardinalità di 95.568,6 :
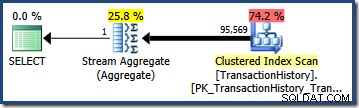
Nessuna delle due stime (41.257 per il AND interrogazione; 95.569 per il OR query) è particolarmente valido perché entrambi si basano su un'ipotesi di modellazione che non corrisponde molto bene alla distribuzione dei dati. Entrambe le query restituiscono effettivamente 68.413 righe (perché i predicati identificano esattamente le stesse righe).
Traccia Flag 4137 – Selettività minima
Per SQL Server 2008 (R1) fino al 2012 incluso, Microsoft ha rilasciato una correzione che cambia il modo in cui viene calcolata la selettività per AND solo caso (predicati congiuntivi). L'articolo della Knowledge Base in quel collegamento non contiene molti dettagli, ma risulta che la correzione modifica la formula di selettività utilizzata. Invece di moltiplicare le selettività individuali, la stima della cardinalità per i predicati congiuntivi ora utilizza solo la selettività più bassa.
Per attivare il comportamento modificato, è necessario il flag di traccia supportato 4137. Un articolo separato della Knowledge Base documenta che questo flag di traccia è supportato anche per l'utilizzo per query tramite QUERYTRACEON suggerimento:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); Con questo flag attivo, la stima della cardinalità utilizza la selettività minima dei due predicati, risultando in una stima di 68.412,4 righe:
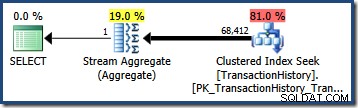
Questo sembra essere quasi perfetto per la nostra query perché i nostri predicati di test sono esattamente correlati (e anche le stime derivate dagli istogrammi di base sono molto buone).
È ragionevolmente raro che i predicati siano perfettamente correlati in questo modo con dati reali, ma il flag di traccia può comunque aiutare in alcuni casi. Si noti che il comportamento di selettività minima si applicherà a tutti i congiuntivi (AND ) predicati nella query; non c'è modo di specificare il comportamento a un livello più granulare.
Non esiste un flag di traccia corrispondente per stimare il disgiuntivo (OR ) predicati che utilizzano la selettività minima.
SQL Server 2014
Il calcolo della selettività in SQL Server 2014 si comporta come nelle versioni precedenti (e il flag di traccia 4137 funziona come prima) se il livello di compatibilità del database è impostato su un valore inferiore a 120 o se il flag di traccia 9481 è attivo. L'impostazione del livello di compatibilità del database è ufficiale modo di utilizzare lo stimatore di cardinalità precedente al 2014 in SQL Server 2014. Il flag di traccia 9481 è efficace per eseguire le stesse operazioni al momento della scrittura e funziona anche con QUERYTRACEON , sebbene non sia documentato. Non c'è modo di sapere quale sarà il comportamento RTM di questo flag.
Se il nuovo stimatore di cardinalità è attivo, SQL Server 2014 usa una formula predefinita diversa per combinare predicati congiuntivi e disgiuntivi. Sebbene non documentata, la formula di selettività per le congiunzioni è stata scoperta e documentata diverse volte. Il primo che ricordo di aver visto è in questo post sul blog portoghese e nella seconda parte di follow-up pubblicata un paio di settimane dopo. Per riassumere, l'approccio del 2014 ai predicati congiuntivi consiste nell'usare backoff esponenziale: data una tabella con cardinalità C e selettività del predicato S1 , S2 , S3 … Sn , dove S1 è il più selettivo e Sn il minimo:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
La stima viene calcolata il predicato più selettivo moltiplicato per la cardinalità della tabella, moltiplicato per la radice quadrata del successivo predicato più selettivo e così via con ogni nuova selettività che ottiene una radice quadrata aggiuntiva.
Ricordando che la selettività è un numero compreso tra 0 e 1, è chiaro che l'applicazione di una radice quadrata avvicina il numero a 1. L'effetto è quello di tenere conto di tutti i predicati nella stima finale, ma di ridurre l'impatto dei predicati meno selettivi esponenzialmente. C'è probabilmente più logica in questa idea rispetto al assunto di indipendenza , ma è ancora una formula fissa:non cambia in base al grado effettivo di correlazione dei dati.
Lo stimatore di cardinalità 2014 utilizza una formula di backoff esponenziale per entrambi predicati congiuntivi e disgiuntivi, sebbene la formula usata nel disgiuntivo (OR ) il caso non è stato ancora documentato (ufficialmente o meno).
Flag di traccia di selettività di SQL Server 2014
Il flag di traccia 4137 (per utilizzare la selettività minima) non funziona in SQL Server 2014, se il nuovo stimatore di cardinalità viene utilizzato durante la compilazione di una query. È invece presente un nuovo flag di traccia 9471 . Quando questo flag è attivo, la selettività minima viene utilizzata per stimare più congiuntivi e disgiuntivi predicati. Questo è un cambiamento rispetto al comportamento 4137, che interessava solo i predicati congiuntivi.
Allo stesso modo, traccia il flag 9472 può essere specificato per assumere indipendenza per più predicati, come facevano le versioni precedenti. Questo flag è diverso da 9481 (per utilizzare lo stimatore di cardinalità precedente al 2014) perché sotto 9472 verrà ancora utilizzato il nuovo stimatore di cardinalità, solo la formula di selettività per più predicati è interessata.
Né 9471 né 9472 sono documentati al momento della scrittura (sebbene potrebbero essere in RTM).
Un modo conveniente per vedere quale ipotesi di selettività viene utilizzata in SQL Server 2014 (con il nuovo stimatore di cardinalità attivo) consiste nell'esaminare l'output di debug del calcolo della selettività prodotto quando la traccia contrassegna 2363 e 3604 sono attivi. La sezione da cercare si riferisce al calcolatore di selettività che combina i filtri, dove vedrai uno dei seguenti, a seconda dell'ipotesi utilizzata:
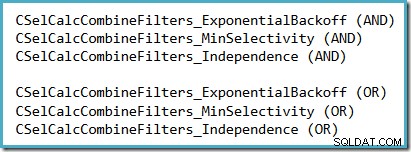
Non vi è alcuna prospettiva realistica che 2363 sarà documentato o supportato.
Pensieri finali
Non c'è nulla di magico nel backoff esponenziale, nella selettività minima o nell'indipendenza. Ogni approccio rappresenta un'ipotesi (estremamente) semplificativa che può o meno produrre stime accettabili per una particolare query o distribuzione di dati.
Per alcuni aspetti, backoff esponenziale rappresenta un compromesso tra i due estremi dell'indipendenza e selettività minima . Anche così, è importante non avere aspettative irragionevoli al riguardo. Fino a quando non si troverà un modo più accurato per stimare la selettività per più predicati (con caratteristiche prestazionali ragionevoli), resta importante essere consapevoli dei limiti del modello e fare attenzione di conseguenza ai (potenziali) errori di stima.
I vari flag di traccia forniscono un certo controllo su quale ipotesi viene utilizzata, ma la situazione è tutt'altro che perfetta. Per prima cosa, la granularità più fine a cui un flag può essere applicato è una singola query:il comportamento di stima non può essere specificato a livello di predicato. Se si dispone di una query in cui alcuni predicati sono correlati e altri indipendenti, i flag di traccia potrebbero non essere di grande aiuto senza refactoring della query in un modo o nell'altro. Allo stesso modo, una query problematica può avere correlazioni di predicati che non sono modellate bene da nessuna delle opzioni disponibili.
L'uso ad hoc dei flag di traccia richiede le stesse autorizzazioni di DBCC TRACEON – ovvero amministratore di sistema . Probabilmente va bene per i test personali, ma per la produzione usa una guida al piano usando QUERYTRACEON suggerimento è un'opzione migliore. Con una guida al piano, non sono necessarie autorizzazioni aggiuntive per eseguire la query (sebbene siano necessarie autorizzazioni elevate per creare la guida al piano, ovviamente).