Di tanto in tanto vedo qualcuno esprimere l'esigenza di creare un numero casuale per una chiave. Di solito si tratta di creare un tipo di ID cliente o ID utente surrogato che è un numero univoco all'interno di un intervallo, ma non viene emesso in sequenza ed è quindi molto meno intuibile di un IDENTITY valore.
NEWID() risolve il problema delle ipotesi, ma la penalità delle prestazioni di solito è un problema, specialmente se raggruppata:chiavi molto più larghe degli interi e divisioni di pagina dovute a valori non sequenziali. NEWSEQUENTIALID() risolve il problema della divisione della pagina, ma è ancora una chiave molto ampia e reintroduce il problema che è possibile indovinare il valore successivo (o i valori emessi di recente) con un certo livello di precisione.
Di conseguenza, vogliono una tecnica per generare un e casuale intero unico. Generare un numero casuale da solo non è difficile, usando metodi come RAND() o CHECKSUM(NEWID()) . Il problema arriva quando devi rilevare le collisioni. Diamo una rapida occhiata a un approccio tipico, supponendo di volere valori CustomerID compresi tra 1 e 1.000.000:
DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END Man mano che la tabella diventa più grande, non solo il controllo dei duplicati diventa più costoso, ma aumentano anche le probabilità di generare un duplicato. Quindi questo approccio può sembrare che funzioni bene quando il tavolo è piccolo, ma sospetto che nel tempo debba far male sempre di più.
Un approccio diverso
Sono un grande fan dei tavoli ausiliari; Scrivo pubblicamente di tabelle di calendario e tabelle di numeri da un decennio e le uso da molto più tempo. E questo è un caso in cui penso che un tavolo precompilato potrebbe tornare molto utile. Perché affidarsi alla generazione di numeri casuali in fase di esecuzione e alla gestione di potenziali duplicati, quando puoi popolare tutti quei valori in anticipo e sapere – con certezza al 100%, se proteggi le tue tabelle da DML non autorizzati – che il valore successivo che selezioni non è mai stato usato prima?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
ORDER BY r; Questa popolazione ha impiegato 9 secondi per la creazione (in una macchina virtuale su un laptop) e ha occupato circa 17 MB su disco. I dati nella tabella si presentano così:
(Se fossimo preoccupati per come vengono popolati i numeri, potremmo aggiungere un vincolo univoco sulla colonna Valore, che renderebbe la tabella 30 MB. Se avessimo applicato la compressione della pagina, sarebbero stati rispettivamente 11 MB o 25 MB. )
Ho creato un'altra copia della tabella e l'ho popolata con gli stessi valori, in modo da poter testare due metodi diversi per ricavare il valore successivo:
CREATE TABLE dbo.RandomNumbers2 ( RowID INT, Value INT, -- UNIQUE PRIMARY KEY (RowID, Value) ); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Ora, ogni volta che vogliamo un nuovo numero casuale, possiamo semplicemente estrarne uno dalla pila di numeri esistenti ed eliminarlo. Questo ci impedisce di doverci preoccupare dei duplicati e ci consente di estrarre numeri, utilizzando un indice cluster, che in realtà sono già in ordine casuale. (A rigor di termini, non dobbiamo eliminare i numeri come li usiamo; potremmo aggiungere una colonna per indicare se è stato utilizzato un valore:ciò semplificherebbe il ripristino e il riutilizzo di quel valore nel caso in cui un Cliente venga successivamente eliminato o qualcosa vada storto al di fuori di questa transazione ma prima che siano completamente creati.)
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
Ho usato una variabile di tabella per contenere l'output intermedio, perché ci sono varie limitazioni con DML componibile che possono rendere impossibile l'inserimento nella tabella Customers direttamente da DELETE (ad esempio la presenza di chiavi esterne). Tuttavia, riconoscendo che non sarà sempre possibile, ho voluto testare anche questo metodo:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...other params... INTO dbo.Customers(CustomerID, ...other columns...);
Si noti che nessuna di queste soluzioni garantisce veramente l'ordine casuale, in particolare se la tabella dei numeri casuali ha altri indici (come un indice univoco nella colonna Valore). Non c'è modo di definire un ordine per un DELETE utilizzando TOP; dalla documentazione:
Quindi, se vuoi garantire un ordine casuale, potresti invece fare qualcosa del genere:
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; Un'altra considerazione qui è che, per questi test, le tabelle Customers hanno una chiave primaria raggruppata nella colonna CustomerID; questo porterà sicuramente a divisioni di pagina quando inserisci valori casuali. Nel mondo reale, se avessi questo requisito, probabilmente finiresti per raggruppare su una colonna diversa.
Tieni presente che qui ho tralasciato anche le transazioni e la gestione degli errori, ma anche queste dovrebbero essere una considerazione per il codice di produzione.
Test delle prestazioni
Per fare dei confronti realistici delle prestazioni, ho creato cinque stored procedure, che rappresentano i seguenti scenari (test di velocità, distribuzione e frequenza di collisione dei diversi metodi casuali, nonché la velocità di utilizzo di una tabella predefinita di numeri casuali):
- Generazione di runtime utilizzando
CHECKSUM(NEWID()) - Generazione di runtime utilizzando
CRYPT_GEN_RANDOM() - Generazione di runtime utilizzando
RAND() - Tabella numerica predefinita con variabile tabella
- Tabella numeri predefiniti con inserimento diretto
Usano una tabella di registrazione per tenere traccia della durata e del numero di collisioni:
CREATE TABLE dbo.CustomerLog ( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, collisions INT, duration INT -- microseconds );
Di seguito il codice per le procedure (clicca per mostrare/nascondere):
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO E per testarlo, eseguirei ciascuna stored procedure 1.000.000 di volte:
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Predefined_Direct; GO 1000000
Non sorprende che i metodi che utilizzavano la tabella predefinita di numeri casuali richiedessero un po' più di tempo *all'inizio del test*, poiché dovevano eseguire sia I/O di lettura che di scrittura ogni volta. Tenendo presente che questi numeri sono in microsecondi , ecco le durate medie per ciascuna procedura, a intervalli diversi lungo il percorso (media delle prime 10.000 esecuzioni, delle 10.000 esecuzioni centrali, delle ultime 10.000 esecuzioni e delle ultime 1.000):
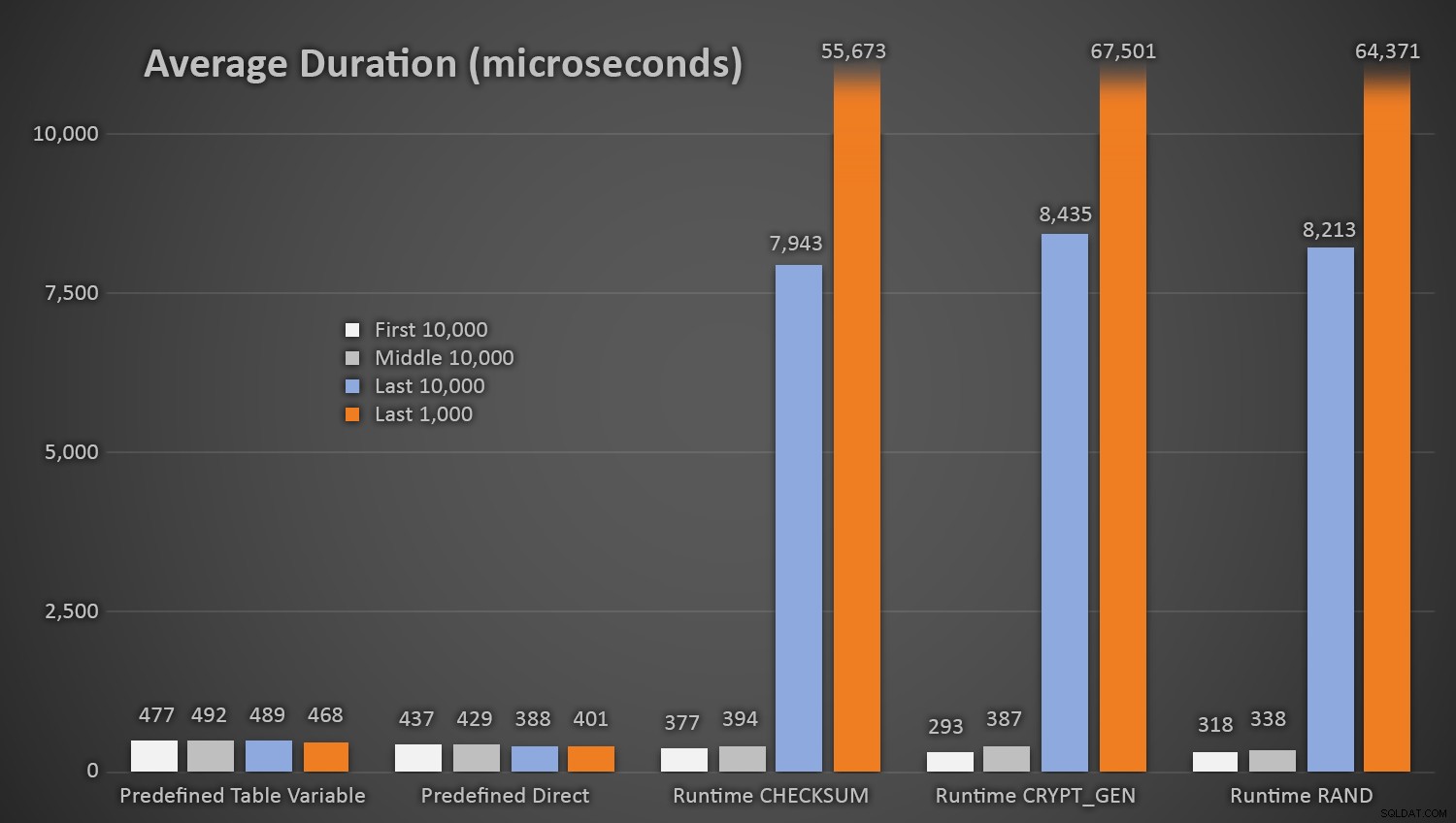
Durata media (in microsecondi) della generazione casuale utilizzando diversi approcci
Questo funziona bene per tutti i metodi quando ci sono poche righe nella tabella Customers, ma man mano che la tabella diventa sempre più grande, il costo del controllo del nuovo numero casuale rispetto ai dati esistenti utilizzando i metodi di runtime aumenta sostanzialmente, sia a causa dell'aumento di I /O e anche perché il numero di collisioni aumenta (costringendoti a provare e riprovare). Confronta la durata media nei seguenti intervalli di conteggi delle collisioni (e ricorda che questo modello influisce solo sui metodi di runtime):
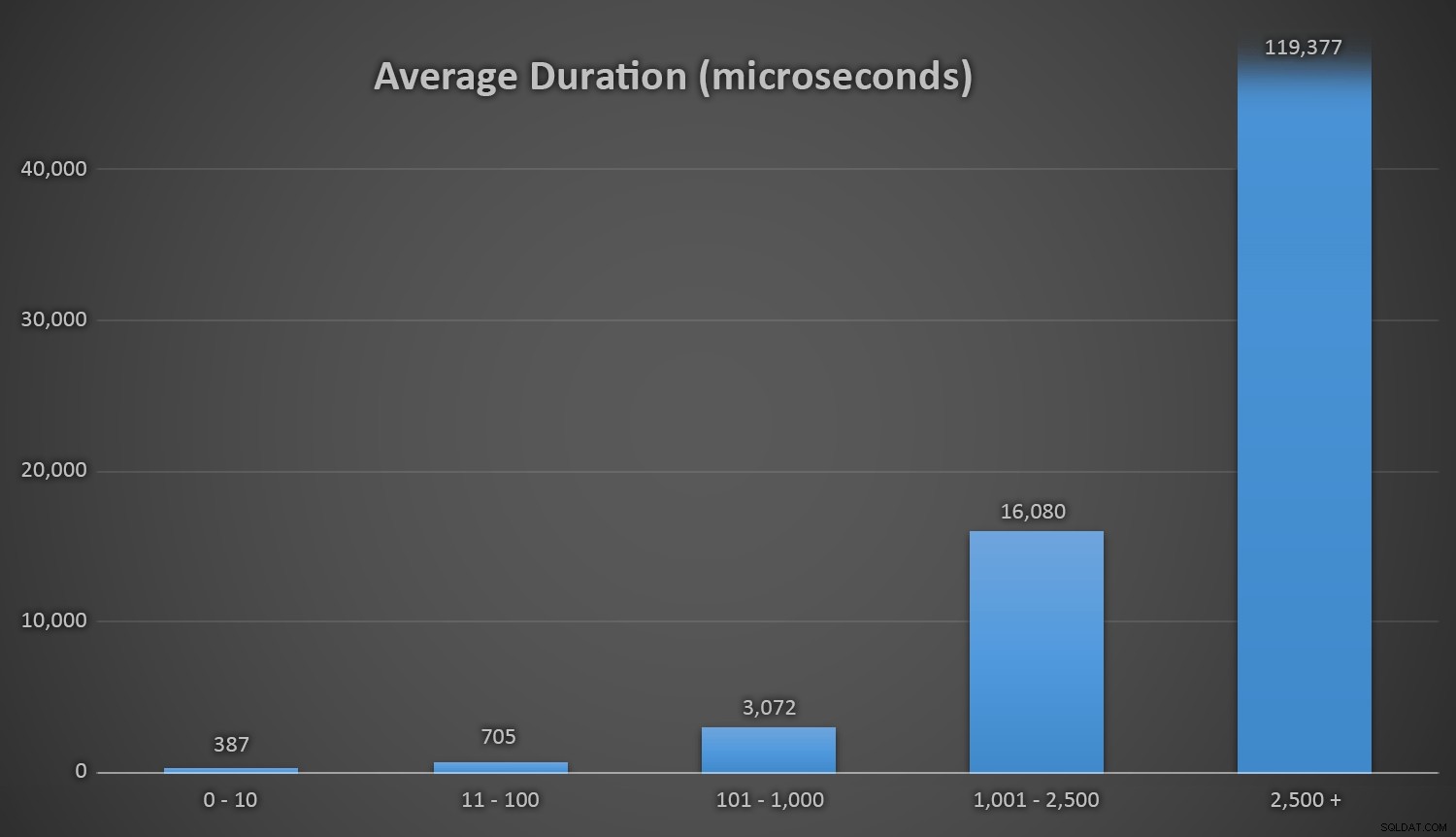
Durata media (in microsecondi) durante diversi intervalli di collisioni
Vorrei che ci fosse un modo semplice per rappresentare graficamente la durata rispetto al conteggio delle collisioni. Ti lascio con questa curiosità:negli ultimi tre inserti, i seguenti metodi di runtime hanno dovuto eseguire così tanti tentativi prima di incappare finalmente nell'ultimo ID univoco che stavano cercando, ed ecco quanto tempo ci è voluto:
| Numero di collisioni | Durata (microsecondi) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | dalla terza all'ultima riga | 63.545 | 639.358 |
| dalla seconda all'ultima riga | 164.807 | 1.605.695 | |
| Ultima riga | 30.630 | 296.207 | |
| CRYPT_GEN_RANDOM() | dalla terza all'ultima riga | 219.766 | 2.229.166 |
| dalla seconda all'ultima riga | 255.463 | 2.681.468 | |
| Ultima riga | 136.342 | 1.434.725 | |
| RAND() | dalla terza all'ultima riga | 129.764 | 1.215.994 |
| dalla seconda all'ultima riga | 220.195 | 2.088.992 | |
| Ultima riga | 440.765 | 4.161.925 | |
Durata eccessiva e collisioni verso la fine della riga
È interessante notare che l'ultima riga non è sempre quella che produce il maggior numero di collisioni, quindi questo può iniziare a essere un vero problema molto prima che tu abbia utilizzato oltre 999.000 valori.
Un'altra considerazione
Potresti prendere in considerazione l'impostazione di un tipo di avviso o notifica quando la tabella RandomNumbers inizia a scendere al di sotto di un certo numero di righe (a quel punto puoi ripopolare la tabella con un nuovo set da 1.000.001 a 2.000.000, ad esempio). Dovresti fare qualcosa di simile se stessi generando numeri casuali al volo:se lo stai mantenendo entro un intervallo da 1 a 1.000.000, dovresti cambiare il codice per generare numeri da un intervallo diverso una volta che ' ho esaurito tutti quei valori.
Se si utilizza il metodo del numero casuale in fase di esecuzione, è possibile evitare questa situazione modificando costantemente la dimensione del pool da cui si estrae un numero casuale (che dovrebbe anche stabilizzare e ridurre drasticamente il numero di collisioni). Ad esempio, invece di:
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Puoi basare il pool sul numero di righe già presenti nella tabella:
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0);
Ora la tua unica vera preoccupazione è quando ti avvicini al limite superiore per INT …
Nota:di recente ho anche scritto un suggerimento su questo su MSSQLTips.com.