Una semplice definizione della mediana è:
La mediana è il valore medio in un elenco ordinato di numeriPer approfondire un po', possiamo trovare la mediana di un elenco di numeri utilizzando la procedura seguente:
- Ordina i numeri (in ordine crescente o decrescente, non importa quale).
- Il numero centrale (per posizione) nell'elenco ordinato è la mediana.
- Se sono presenti due numeri "ugualmente medi", la mediana è la media dei due valori medi.
Aaron Bertrand ha precedentemente testato le prestazioni in diversi modi per calcolare la mediana in SQL Server:
- Qual è il modo più veloce per calcolare la mediana?
- I migliori approcci per la mediana raggruppata
Rob Farley ha recentemente aggiunto un altro approccio rivolto alle installazioni precedenti al 2012:
- Mediane pre-SQL 2012
Questo articolo introduce un nuovo metodo che utilizza un cursore dinamico.
Il metodo OFFSET-FETCH 2012
Inizieremo esaminando l'implementazione con le migliori prestazioni, creata da Peter Larsson. Utilizza il OFFSET di SQL Server 2012 estensione al ORDER BY clausola per individuare in modo efficiente una o due righe centrali necessarie per calcolare la mediana.
OFFSET mediana singola
Il primo articolo di Aaron ha testato il calcolo di una singola mediana su una tabella di dieci milioni di righe:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
La soluzione di Peter Larsson che utilizza OFFSET l'estensione è:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Il codice sopra codifica il risultato del conteggio delle righe nella tabella. Tutti i metodi testati per calcolare la mediana richiedono questo conteggio per calcolare i numeri di riga mediana, quindi è un costo costante. Lasciare l'operazione di conteggio delle righe fuori dai tempi evita una possibile fonte di variazione.
Il piano di esecuzione per OFFSET la soluzione è mostrata di seguito:

L'operatore Top salta rapidamente le righe non necessarie, passando solo una o due righe necessarie per calcolare la mediana allo Stream Aggregate. Quando viene eseguita con una cache calda e la raccolta del piano di esecuzione disattivata, questa query viene eseguita per 910 ms in media sul mio laptop. Questa è una macchina con un processore Intel i7 740QM funzionante a 1,73 GHz con Turbo disabilitato (per coerenza).
OFFSET mediana raggruppata
Il secondo articolo di Aaron ha testato le prestazioni del calcolo di una mediana per gruppo, utilizzando una tabella delle vendite di un milione di righe con diecimila voci per ciascuno dei cento venditori:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Anche in questo caso, la soluzione con le migliori prestazioni utilizza OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); La parte importante del piano di esecuzione è mostrata di seguito:

La riga superiore del piano riguarda la ricerca del conteggio delle righe del gruppo per ciascun addetto alle vendite. La riga inferiore utilizza gli stessi elementi del piano visti per la soluzione mediana a gruppo singolo per calcolare la mediana per ogni addetto alle vendite. Quando viene eseguita con una cache calda e i piani di esecuzione disattivati, questa query viene eseguita in 320 ms in media sul mio laptop.
Utilizzo di un cursore dinamico
Potrebbe sembrare folle anche solo pensare di usare un cursore per calcolare la mediana. I cursori Transact SQL hanno una (per lo più meritata) reputazione di essere lenti e inefficienti. Spesso si pensa anche che i cursori dinamici siano il peggior tipo di cursore. Questi punti sono validi in alcune circostanze, ma non sempre.
I cursori Transact SQL sono limitati all'elaborazione di una singola riga alla volta, quindi possono effettivamente essere lenti se è necessario recuperare ed elaborare molte righe. Tuttavia non è il caso del calcolo della mediana:tutto ciò che dobbiamo fare è individuare e recuperare uno o due valori intermedi in modo efficiente . Un cursore dinamico è molto adatto per questo compito, come vedremo.
Cursore dinamico mediano singolo
La soluzione del cursore dinamico per un singolo calcolo della mediana consiste nei seguenti passaggi:
- Crea un cursore dinamico scorrevole sull'elenco ordinato di elementi.
- Calcola la posizione della prima riga mediana.
- Riposiziona il cursore usando
FETCH RELATIVE. - Decidi se è necessaria una seconda riga per calcolare la mediana.
- In caso contrario, restituire immediatamente il valore mediano singolo.
- Altrimenti, recupera il secondo valore utilizzando
FETCH NEXT. - Calcola la media dei due valori e ritorna.
Nota come tale elenco rifletta la semplice procedura per trovare la mediana fornita all'inizio di questo articolo. Di seguito viene mostrata un'implementazione completa del codice Transact SQL:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Il piano di esecuzione per FETCH RELATIVE mostra il cursore dinamico che si riposiziona in modo efficiente sulla prima riga richiesta per il calcolo della mediana:
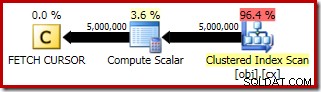
Il piano per FETCH NEXT (richiesto solo se c'è una seconda riga centrale, come in questi test) è una singola riga recupera dalla posizione salvata del cursore:
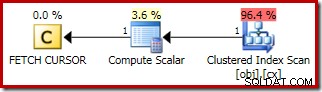
I vantaggi dell'utilizzo di un cursore dinamico qui sono:
- Evita di attraversare l'intero set (la lettura si interrompe dopo che sono state trovate le righe mediane); e
- Nessuna copia temporanea dei dati viene eseguita in tempdb , come sarebbe per un cursore statico o keyset.
Nota che non possiamo specificare un FAST_FORWARD cursore qui (lasciando la scelta di un piano di tipo statico o dinamico all'ottimizzatore) perché il cursore deve essere scorrevole per supportare FETCH RELATIVE . La dinamica è comunque la scelta ottimale qui.
Quando viene eseguita con una cache calda e la raccolta del piano di esecuzione disattivata, questa query viene eseguita per 930 ms in media sulla mia macchina di prova. Questo è un po' più lento di 910 ms per il OFFSET soluzione, ma il cursore dinamico è significativamente più veloce degli altri metodi testati da Aaron e Rob e non richiede SQL Server 2012 (o versioni successive).
Non ripeterò il test degli altri metodi precedenti al 2012 qui, ma come esempio dell'entità del divario di prestazioni, la seguente soluzione di numerazione delle righe richiede 1550 ms in media (70% più lento):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Test del cursore dinamico mediano raggruppato
È semplice estendere la soluzione del cursore dinamico a mediana singola per calcolare le mediane raggruppate. Per motivi di coerenza, userò i cursori nidificati (sì, davvero):
- Apri un cursore statico sopra gli addetti alle vendite e il conteggio delle righe.
- Calcola la mediana per ogni persona usando ogni volta un nuovo cursore dinamico.
- Salva ogni risultato in una variabile di tabella mentre procediamo.
Il codice è mostrato di seguito:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Il cursore esterno è deliberatamente statico perché tutte le righe in quel set verranno toccate (inoltre, un cursore dinamico non è disponibile a causa dell'operazione di raggruppamento nella query sottostante). Questa volta non c'è nulla di particolarmente nuovo o interessante da vedere nei piani di esecuzione.
La cosa interessante è la performance. Nonostante la creazione e la deallocazione ripetute del cursore dinamico interno, questa soluzione si comporta molto bene sul set di dati di test. Con una cache calda e i piani di esecuzione disattivati, lo script del cursore viene completato in 330 ms in media sulla mia macchina di prova. Anche questo è un po' più lento dei 320 ms registrato dal OFFSET mediana raggruppata, ma supera di gran lunga le altre soluzioni standard elencate negli articoli di Aaron e Rob.
Anche in questo caso, come esempio del divario di prestazioni rispetto agli altri metodi non del 2012, la seguente soluzione di numerazione delle righe viene eseguita per 485 ms in media sul mio banco di prova (50% peggio):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Riepilogo risultati
Nel test della singola mediana il cursore dinamico è stato eseguito per 930 ms rispetto a 910 ms per il OFFSET metodo.
Nel test della mediana raggruppata, il cursore nidificato è stato eseguito per 330 ms rispetto a 320 ms per OFFSET .
In entrambi i casi, il metodo del cursore era significativamente più veloce dell'altro non OFFSET metodi. Se devi calcolare una mediana singola o raggruppata su un'istanza precedente al 2012, un cursore dinamico o nidificato potrebbe davvero essere la scelta ottimale.
Rendimento della Cold Cache
Alcuni di voi potrebbero chiedersi delle prestazioni della cold cache. Eseguire quanto segue prima di ogni test:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Questi i risultati del test della singola mediana:
OFFSET metodo:940 ms
Cursore dinamico:955 ms
Per la mediana raggruppata:
OFFSET metodo:380 ms
Cursori nidificati:385 ms
Pensieri finali
Le soluzioni del cursore dinamico sono davvero significativamente più veloci del non OFFSET metodi per mediane singole e raggruppate, almeno con questi set di dati campione. Ho deliberatamente scelto di riutilizzare i dati di test di Aaron in modo che i set di dati non fossero intenzionalmente inclinati verso il cursore dinamico. Ci potrebbe essere altre distribuzioni di dati per le quali il cursore dinamico non è una buona opzione. Tuttavia, mostra che ci sono ancora momenti in cui un cursore può essere una soluzione rapida ed efficiente al giusto tipo di problema. Anche i cursori dinamici e annidati.
I lettori con gli occhi d'aquila potrebbero aver notato il PAGLOCK suggerimento nel OFFSET test mediano raggruppato. Questo è necessario per ottenere le migliori prestazioni, per ragioni che tratterò nel mio prossimo articolo. Senza di essa, la soluzione del 2012 perde effettivamente il cursore nidificato con un margine decente (590 ms rispetto a 330 ms ).