Sysbench è un ottimo strumento per generare dati di test ed eseguire benchmark OLTP MySQL. Comunemente, si esegue un ciclo di preparazione-esecuzione-pulizia durante l'esecuzione del benchmark utilizzando Sysbench. Per impostazione predefinita, la tabella generata da Sysbench è una tabella di base standard non di partizione. Questo comportamento può essere esteso, ovviamente, ma devi sapere come scriverlo nello script LUA.
In questo post del blog, mostreremo come generare dati di test per una tabella partizionata in MySQL usando Sysbench. Questo può essere utilizzato come terreno di gioco per approfondire ulteriormente la causa-effetto del partizionamento delle tabelle, della distribuzione dei dati e dell'instradamento delle query.
Partizionamento tabella a server singolo
Il partizionamento a server singolo significa semplicemente che tutte le partizioni della tabella risiedono sullo stesso server/istanza MySQL. Quando creiamo la struttura della tabella, definiremo tutte le partizioni contemporaneamente. Questo tipo di partizionamento è utile se hai dati che perdono la loro utilità nel tempo e possono essere facilmente rimossi da una tabella partizionata eliminando la partizione (o le partizioni) contenenti solo quei dati.
Crea lo schema Sysbench:
mysql> CREATE SCHEMA sbtest;Crea l'utente del database sysbench:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO 'sbtest'@'%';In Sysbench, si potrebbe usare il comando --prepare per preparare il server MySQL con le strutture dello schema e generare righe di dati. Dobbiamo saltare questa parte e definire manualmente la struttura della tabella.
Crea una tabella partizionata. In questo esempio, creeremo solo una tabella chiamata sbtest1 e sarà partizionata da una colonna denominata "k", che è fondamentalmente un numero intero compreso tra 0 e 1.000.000 (basato sull'opzione --table-size che siamo verrà utilizzato nell'operazione di solo inserimento in seguito):
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999),
PARTITION p2 VALUES LESS THAN MAXVALUE
);Avremo 2 partizioni - La prima partizione si chiama p1 e memorizzerà i dati in cui il valore nella colonna "k" è inferiore a 499.999 e la seconda partizione, p2, memorizzerà i valori rimanenti . Creiamo anche una chiave primaria che contiene entrambe le colonne importanti:"id" è per l'identificatore di riga e "k" è la chiave di partizione. Nel partizionamento, una chiave primaria deve includere tutte le colonne nella funzione di partizionamento della tabella (dove usiamo "k" nella funzione di partizione dell'intervallo).
Verifica che le partizioni siano presenti:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 0 |
| sbtest | sbtest1 | p2 | 0 |
+--------------+------------+----------------+------------+Possiamo quindi avviare un'operazione di solo inserimento Sysbench come di seguito:
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.131 \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runGuarda la crescita delle partizioni della tabella durante l'esecuzione di Sysbench:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 1021 |
| sbtest | sbtest1 | p2 | 1644 |
+--------------+------------+----------------+------------+Se contiamo il numero totale di righe utilizzando la funzione COUNT, esso corrisponderà al numero totale di righe riportato dalle partizioni:
mysql> SELECT COUNT(id) FROM sbtest1;
+-----------+
| count(id) |
+-----------+
| 2665 |
+-----------+Ecco fatto. Abbiamo un partizionamento della tabella a server singolo pronto con cui possiamo giocare.
Partizionamento tabella multi-server
Nel partizionamento multi-server, utilizzeremo più server MySQL per memorizzare fisicamente un sottoinsieme di dati di una particolare tabella (sbtest1), come mostrato nel diagramma seguente:
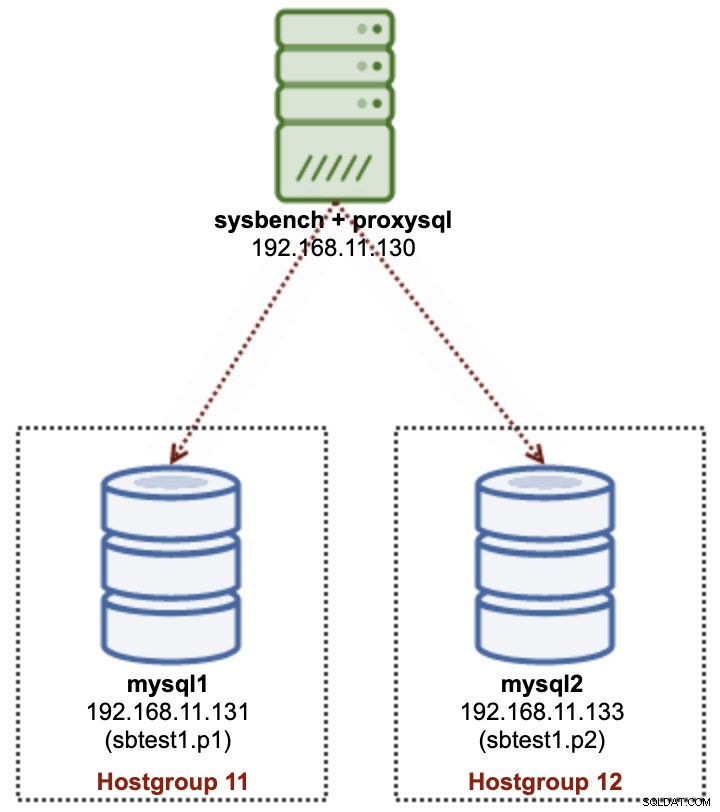
Distribuiremo 2 nodi MySQL indipendenti:mysql1 e mysql2. La tabella sbtest1 verrà partizionata su questi due nodi e chiameremo questa combinazione partizione + host shard. Sysbench è in esecuzione in remoto sul terzo server, imitando il livello dell'applicazione. Poiché Sysbench non è in grado di riconoscere le partizioni, è necessario disporre di un driver di database o di un router per instradare le query del database sullo shard corretto. Useremo ProxySQL per raggiungere questo scopo.
Creiamo un altro nuovo database chiamato sbtest3 per questo scopo:
mysql> CREATE SCHEMA sbtest3;
mysql> USE sbtest3;Concedi i privilegi corretti all'utente del database sbtest:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest3.* TO 'sbtest'@'%';Su mysql1, crea la prima partizione della tabella:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999)
);A differenza del partizionamento autonomo, nella tabella definiamo solo la condizione per la partizione p1 per memorizzare tutte le righe con valori di colonna "k" compresi tra 0 e 499.999.
Su mysql2, crea un'altra tabella partizionata:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p2 VALUES LESS THAN MAXVALUE
);Sul secondo server, dovrebbe contenere i dati della seconda partizione memorizzando il resto dei valori previsti della colonna "k".
La nostra struttura della tabella è ora pronta per essere popolata con i dati di test.
Prima di poter eseguire l'operazione di solo inserimento Sysbench, è necessario installare un server ProxySQL come router di query e fungere da gateway per i nostri shard MySQL. Il partizionamento orizzontale multi-server richiede che le connessioni al database provenienti dalle applicazioni vengano instradate allo shard corretto. In caso contrario, visualizzerai il seguente errore:
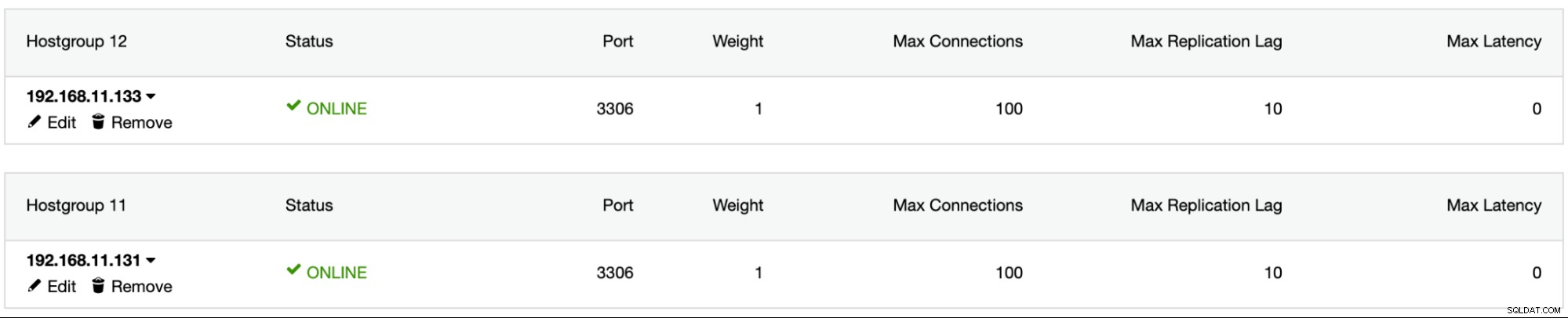
1526 (Table has no partition for value 503599)Installa ProxySQL utilizzando ClusterControl, aggiungi l'utente del database sbtest in ProxySQL, aggiungi entrambi i server MySQL in ProxySQL e configura mysql1 come hostgroup 11 e mysql2 come hostgroup 12:
Successivamente, dobbiamo lavorare su come instradare la query. Un esempio di query INSERT che verrà eseguita da Sysbench avrà un aspetto simile a questo:
INSERT INTO sbtest1 (id, k, c, pad)
VALUES (0, 503502, '88816935247-23939908973-66486617366-05744537902-39238746973-63226063145-55370375476-52424898049-93208870738-99260097520', '36669559817-75903498871-26800752374-15613997245-76119597989')Quindi useremo la seguente espressione regolare per filtrare la query INSERT per "k" => 500000, per soddisfare la condizione di partizionamento:
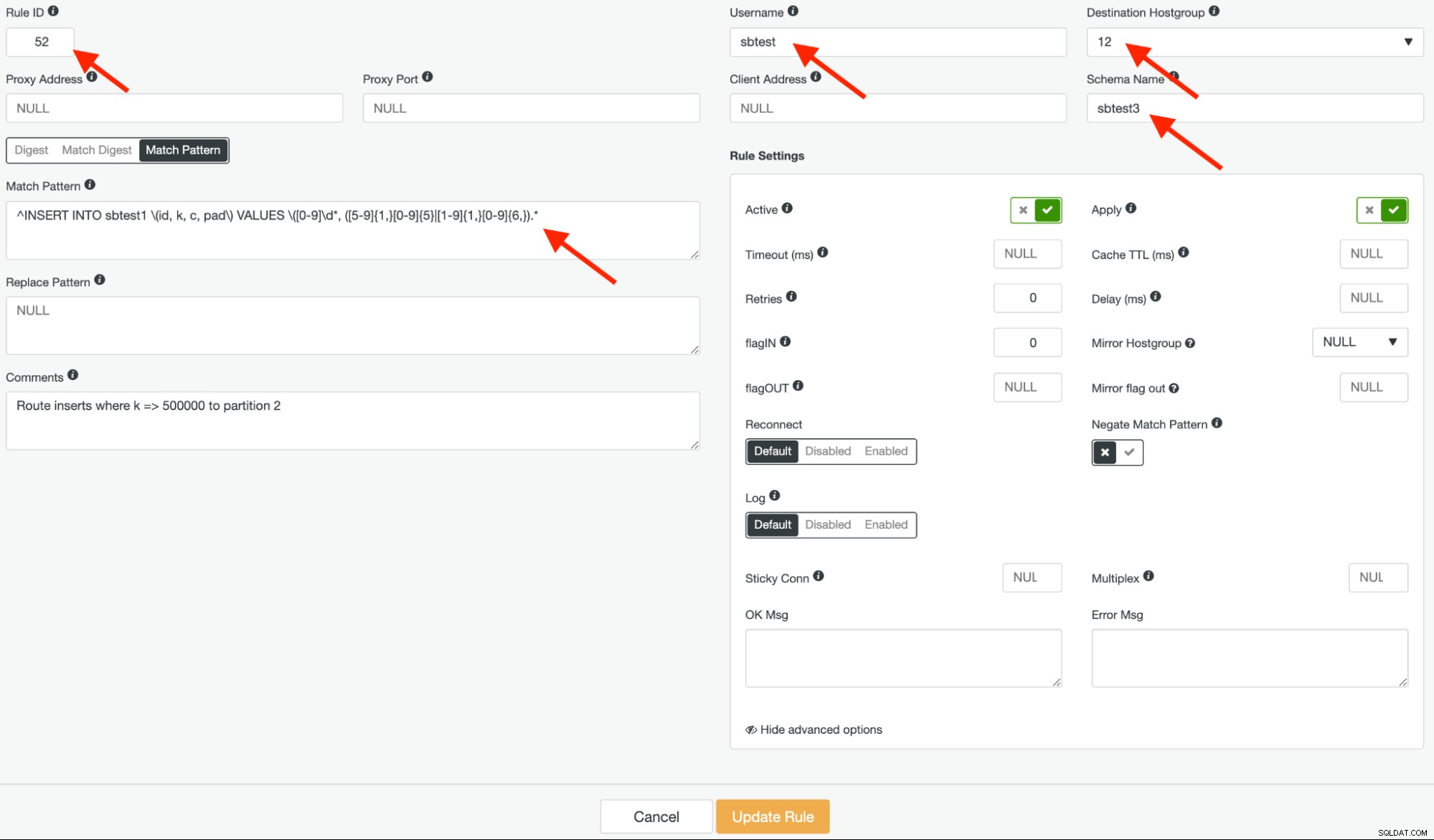
^INSERT INTO sbtest1 \(id, k, c, pad\) VALUES \([0-9]\d*, ([5-9]{1,}[0-9]{5}|[1-9]{1,}[0-9]{6,}).*L'espressione sopra cerca semplicemente di filtrare quanto segue:
-
[0-9]\d* - Ci aspettiamo un numero intero con incremento automatico, quindi abbiniamo qualsiasi numero intero.
-
[5-9]{1,}[0-9]{5} - Il valore corrisponde a qualsiasi numero intero compreso tra 5 come prima cifra e 0-9 sulle ultime 5 cifre, per corrispondere al valore dell'intervallo da 500.000 a 999.999.
-
[1-9]{1,}[0-9]{6,} - Il valore corrisponde a qualsiasi numero intero compreso tra 1-9 come prima cifra e 0-9 sulle ultime 6 cifre o superiori, per corrispondere al valore compreso tra 1.000.000 e oltre.
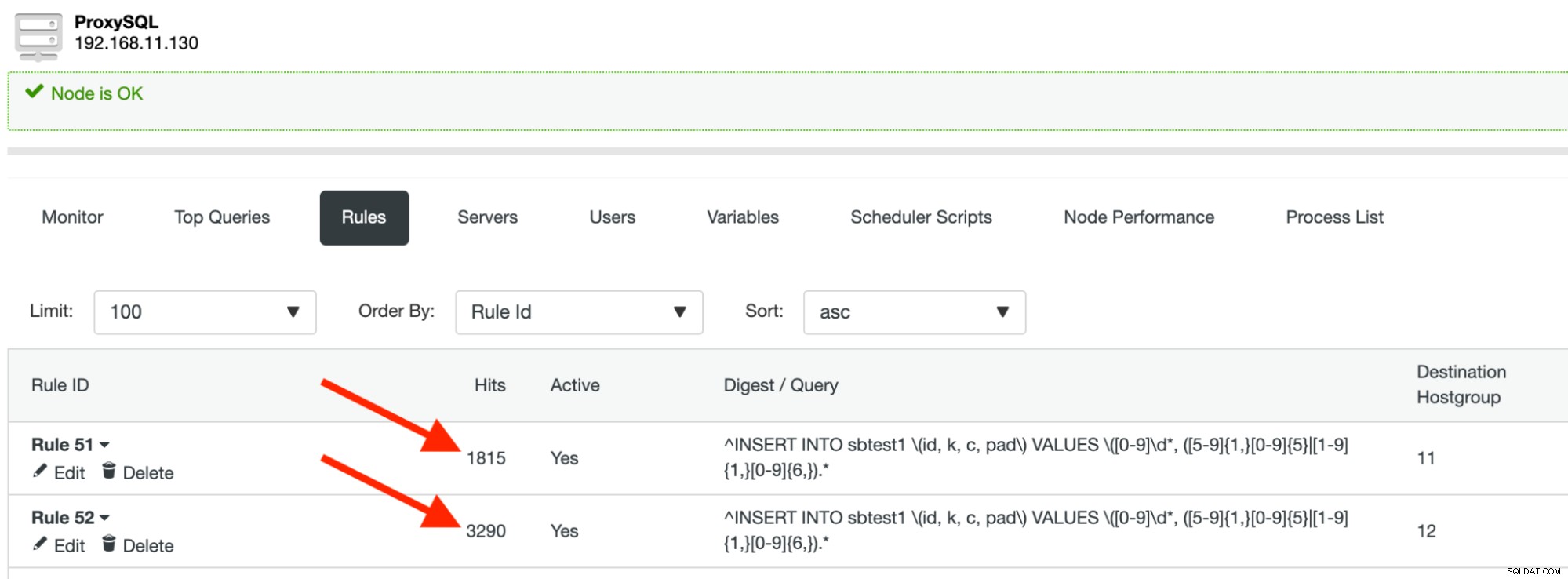
Creeremo due regole di query simili. La prima regola di query è la negazione dell'espressione regolare sopra. Diamo a questa regola l'ID 51 e il gruppo host di destinazione dovrebbe essere il gruppo host 11 per abbinare la colonna "k" <500.000 e inoltrare le query alla prima partizione. Dovrebbe assomigliare a questo:
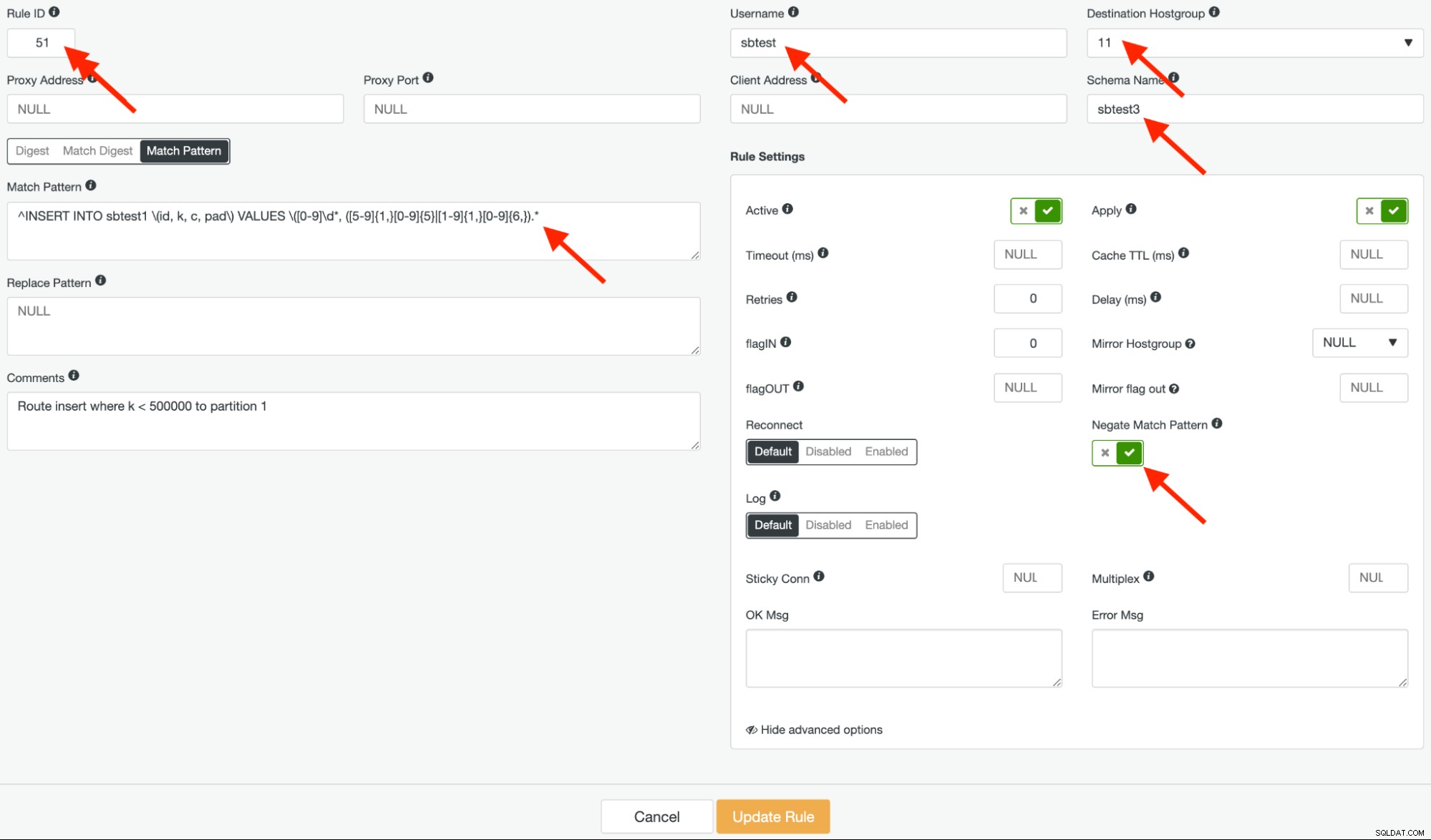
Presta attenzione al "Modello di corrispondenza negativo" nello screenshot sopra. Questa opzione è fondamentale per il corretto instradamento di questa regola di query.
Successivamente, crea un'altra regola di query con ID regola 52, utilizzando la stessa espressione regolare e il gruppo host di destinazione dovrebbe essere 12, ma questa volta lascia "Negate Match Pattern" su false, come mostrato di seguito:
Possiamo quindi avviare un'operazione di solo inserimento utilizzando Sysbench per generare dati di test . Le informazioni relative all'accesso a MySQL dovrebbero essere l'host ProxySQL (192.168.11.130 sulla porta 6033):
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.130 \
--mysql-port=6033 \
--mysql-user=sbtest \
--mysql-db=sbtest3 \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runSe non vedi alcun errore, significa che ProxySQL ha instradato le nostre query allo shard/partizione corretto. Dovresti vedere che i risultati della regola di query aumentano mentre il processo Sysbench è in esecuzione:
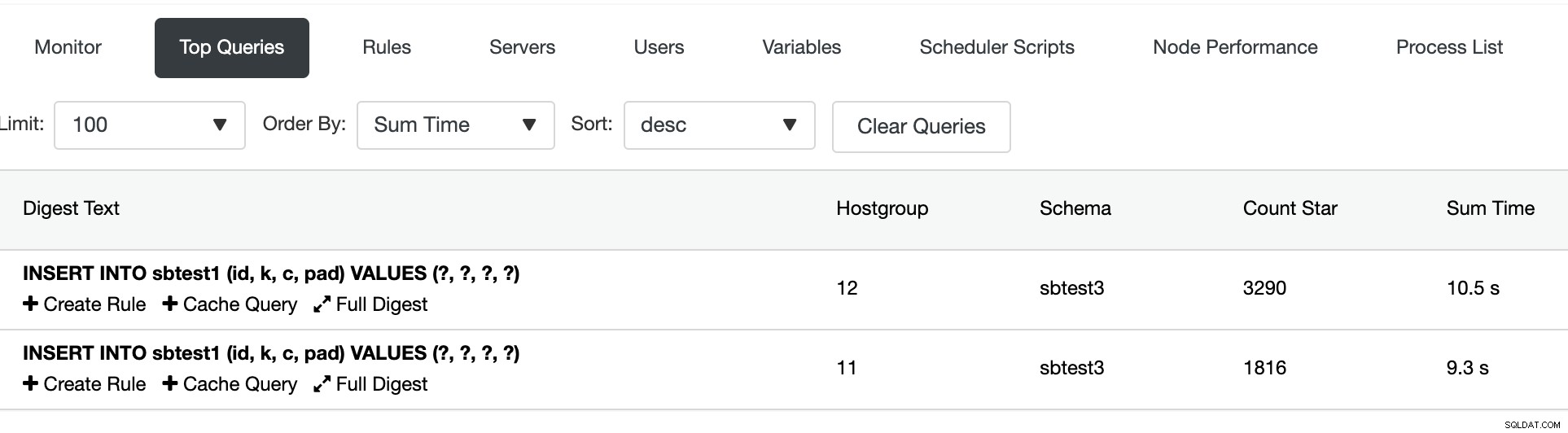
Nella sezione Query principali, possiamo vedere il riepilogo dell'instradamento delle query:
Per ricontrollare, accedi a mysql1 per cercare la prima partizione e controlla il valore minimo e massimo della colonna 'k' sulla tabella sbtest1:
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 232185 | 499998 |
+--------+--------+Sembra fantastico. Il valore massimo della colonna "k" non supera il limite di 499.999. Controlliamo il numero di righe memorizzate per questa partizione:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p1 | 1815 |
+--------------+------------+----------------+------------+Ora controlliamo l'altro server MySQL (mysql2):
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500003 | 794952 |
+--------+--------+Controlliamo il numero di righe memorizzate per questa partizione:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p2 | 3247 |
+--------------+------------+----------------+------------+Stupendo! Abbiamo una configurazione di test MySQL frammentata con un corretto partizionamento dei dati utilizzando Sysbench con cui giocare. Buon benchmarking!