Introduzione
Al giorno d'oggi, l'elevata disponibilità è un requisito per molti sistemi, indipendentemente dalla tecnologia in uso. Ciò è particolarmente importante per i database, poiché memorizzano i dati su cui fanno affidamento le applicazioni ei sistemi critici. La strategia più comune per ottenere un'elevata disponibilità è la replica. Esistono diversi modi per replicare i dati su più server e il traffico di failover quando, ad esempio, un server primario smette di rispondere.
Architettura ad alta disponibilità per PostgreSQL
Ci sono diverse architetture per implementare l'alta disponibilità in PostgreSQL, ma quelle di base sono le architetture Primary-Standby e Primary-Primary.
Architetture primarie-standby
Primary-Standby può essere l'architettura HA più semplice che puoi configurare e, spesso, la più semplice da implementare e mantenere. Si basa su un database primario con uno o più server Standby. Questi database di standby rimarranno sincronizzati (o quasi sincronizzati) con il nodo primario, a seconda che la replica sia sincrona o asincrona. Se il server primario si guasta, il server di standby contiene quasi tutti i dati del server primario e può essere rapidamente trasformato nel nuovo server di database primario.
Puoi implementare due tipi di database Standby, in base alla natura della replica:
- Standby logici:la replica tra Primary e Standby viene eseguita tramite istruzioni SQL.
- Standby fisici:la replica tra Primary e Standby viene effettuata tramite le modifiche interne alla struttura dei dati.
Nel caso di PostgreSQL, viene utilizzato un flusso di record WAL (write-ahead log) per mantenere sincronizzati i database Standby. Può essere sincrono o asincrono e l'intero server di database viene replicato.
Dalla versione 10 in poi, PostgreSQL include un'opzione incorporata per impostare la replica logica, che costruisce un flusso di modifiche ai dati logici dalle informazioni nel registro write-ahead. Questo metodo di replica consente di replicare le modifiche ai dati delle singole tabelle senza dover designare un server primario. Consente inoltre ai dati di fluire in più direzioni.
Purtroppo, una configurazione Primary-Standby non è sufficiente per garantire un'elevata disponibilità in modo efficace, poiché è necessario anche gestire gli errori. Per gestire gli errori, devi essere in grado di rilevarli. Una volta che si è a conoscenza della presenza di un errore, ad esempio errori nel nodo primario o del nodo che non risponde, è possibile selezionare un nodo di standby per sostituire il nodo guasto con il minor ritardo possibile. Questo processo deve essere il più efficiente possibile per ripristinare la piena funzionalità delle applicazioni. PostgreSQL stesso non include un meccanismo di failover automatico, quindi questo richiederà alcuni script personalizzati o strumenti di terze parti per questa automazione.
Dopo che si verifica un failover, la tua applicazione deve ricevere una notifica di conseguenza per iniziare a utilizzare il nuovo Primary. Devi anche valutare lo stato della tua architettura dopo il failover perché puoi imbatterti in una situazione in cui è in esecuzione solo la nuova primaria (ad esempio, avevi un nodo primario e solo uno standby prima del problema). In tal caso, dovrai aggiungere un nodo Standby per ricreare la configurazione Primary-Standby che avevi originariamente per l'alta disponibilità.
Architetture primarie-primarie
L'architettura primaria-primaria fornisce un modo per ridurre al minimo l'impatto di un errore su uno dei nodi, poiché gli altri nodi possono occuparsi di tutto il traffico, influenzando solo leggermente le prestazioni ma senza mai perdere funzionalità. L'architettura primaria-primaria viene spesso utilizzata con il duplice scopo di creare un ambiente ad alta disponibilità e scalare orizzontalmente (rispetto al concetto di scalabilità verticale in cui si aggiungono più risorse a un server).
PostgreSQL non supporta ancora questa architettura "nativamente", quindi dovrai fare riferimento a strumenti e implementazioni di terze parti. Quando scegli una soluzione, devi tenere presente che ci sono molti progetti/strumenti, ma alcuni di essi non sono più supportati, mentre altri sono nuovi e potrebbero non essere testati in produzione.
Bilanciamento del carico
I bilanciatori di carico sono strumenti che possono essere utilizzati per gestire il traffico dalla tua applicazione per ottenere il massimo dall'architettura del tuo database.
Non solo questi strumenti sono utili per bilanciare il carico dei database, ma aiutano anche le applicazioni a essere reindirizzate ai nodi disponibili/integri e persino a specificare porte con ruoli diversi.
HAProxy è un sistema di bilanciamento del carico che distribuisce il traffico da un'origine a una o più destinazioni e può definire regole e/o protocolli specifici per questa attività. Se una qualsiasi delle destinazioni smette di rispondere, viene contrassegnata come offline e il traffico viene inviato alle altre destinazioni disponibili.
Keepalived è un servizio che consente di configurare un indirizzo IP virtuale all'interno di un gruppo di server attivo/passivo. Questo indirizzo IP virtuale è assegnato a un server attivo. Se questo server si guasta, l'indirizzo IP viene automaticamente migrato sul server passivo "Secondario", consentendogli di continuare a lavorare con lo stesso indirizzo IP in modo trasparente per i sistemi.
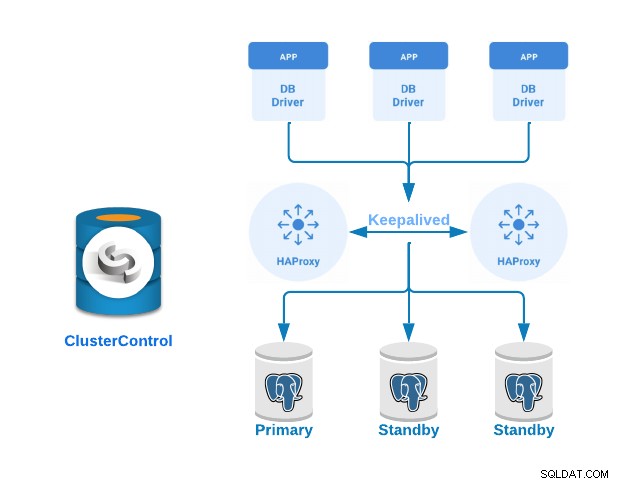
Vediamo ora come implementare un cluster PostgreSQL Primary-Standby con server di bilanciamento del carico e keepalived configurati tra di loro. Lo dimostreremo utilizzando l'interfaccia facile da usare di ClusterControl.
Per questo esempio creeremo:
- 3 server PostgreSQL (uno primario e due standby).
- 2 bilanciatori di carico HAProxy.
- Mantenuto configurato tra i server del servizio di bilanciamento del carico.
Distribuzione del database
Per distribuire un database utilizzando ClusterControl, seleziona semplicemente l'opzione "Deploy" e segui le istruzioni che appaiono.
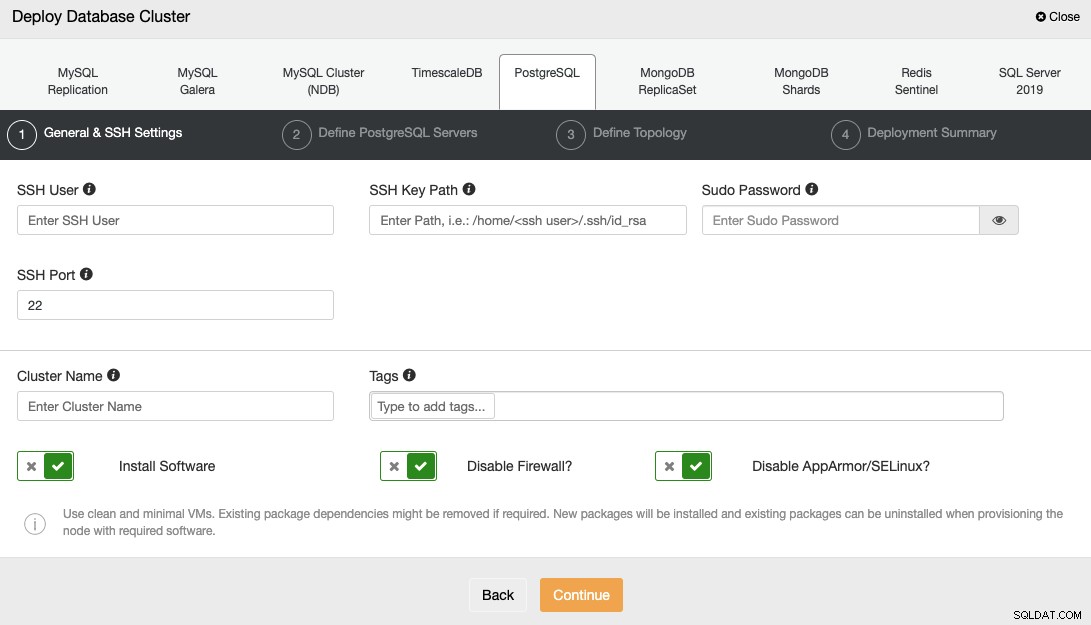
Quando si seleziona PostgreSQL, è necessario specificare l'utente, la chiave o la password e Porta per connetterti tramite SSH ai tuoi server. È necessario anche il nome per il nuovo cluster e scegliere se si desidera che ClusterControl installi il software e le configurazioni corrispondenti per te.
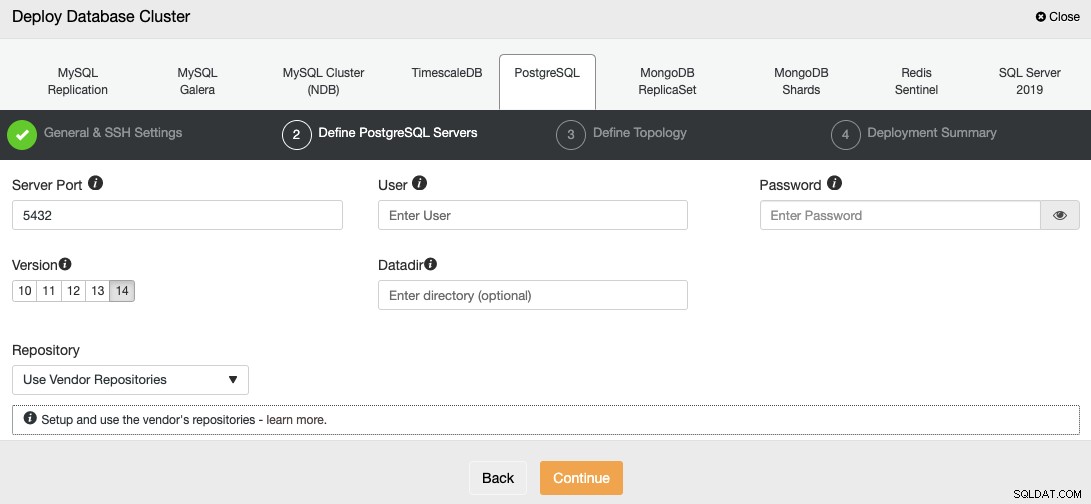
Dopo aver impostato le informazioni di accesso SSH, è necessario definire l'utente del database, versione e datadir (opzionale). Puoi anche specificare quale repository utilizzare; il repository ufficiale del fornitore verrà utilizzato per impostazione predefinita.
Nel passaggio successivo, devi aggiungere i tuoi server al cluster che creerai.
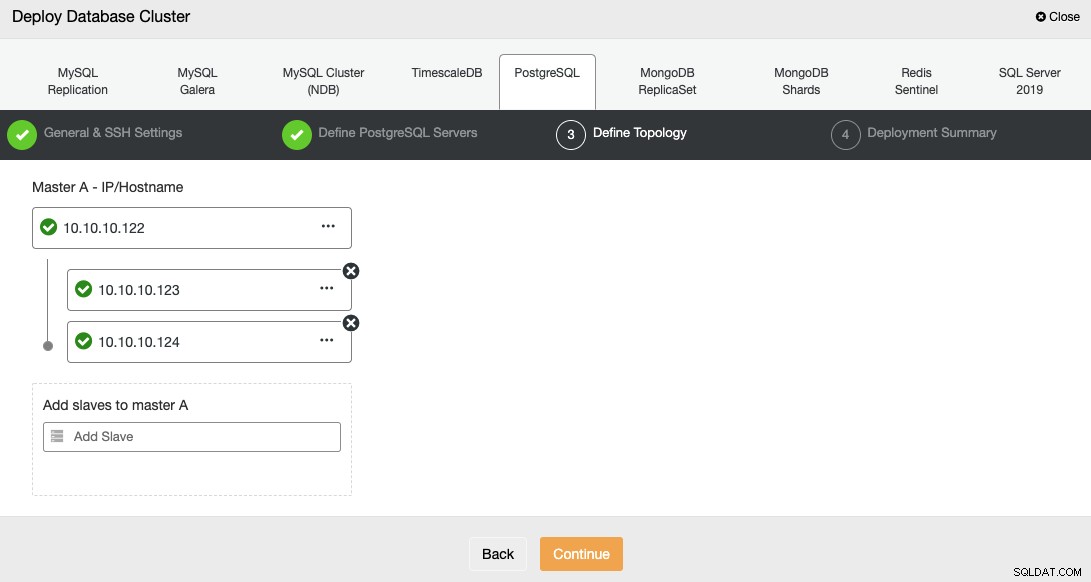
Quando aggiungi i tuoi server, puoi inserire IP o nome host.
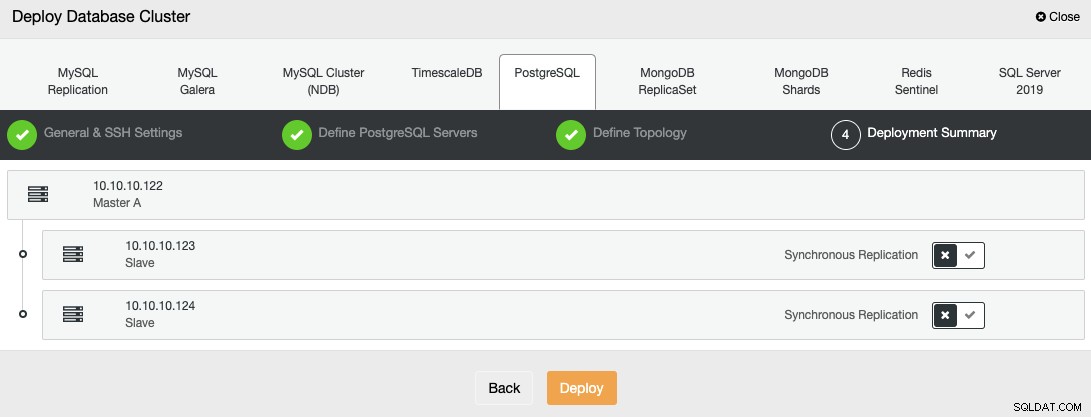
Nell'ultimo passaggio, puoi scegliere se la tua replica sarà Sincrona o Asincrona.
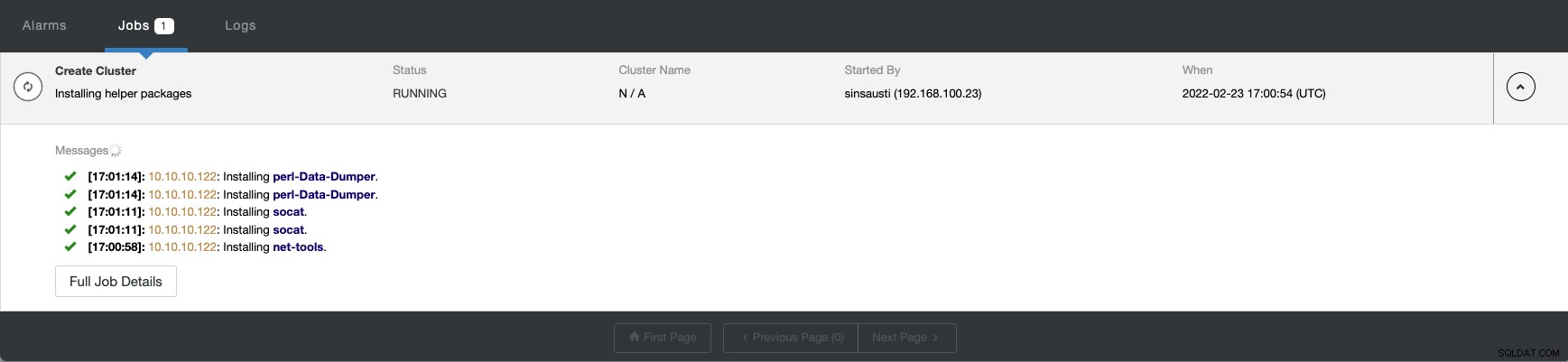
Puoi monitorare lo stato della creazione del tuo nuovo cluster dal ClusterControl monitoraggio attività.
Una volta terminata l'attività, puoi vedere il tuo cluster nel ClusterControl principale schermo.
Una volta creato il cluster, puoi eseguire diverse attività, come aggiungere un bilanciatore del carico (HAProxy) o una nuova replica.
Distribuzione del sistema di bilanciamento del carico
Per eseguire un'implementazione del sistema di bilanciamento del carico, seleziona l'opzione "Aggiungi Load Balancer" nelle azioni del cluster e inserisci le informazioni richieste.
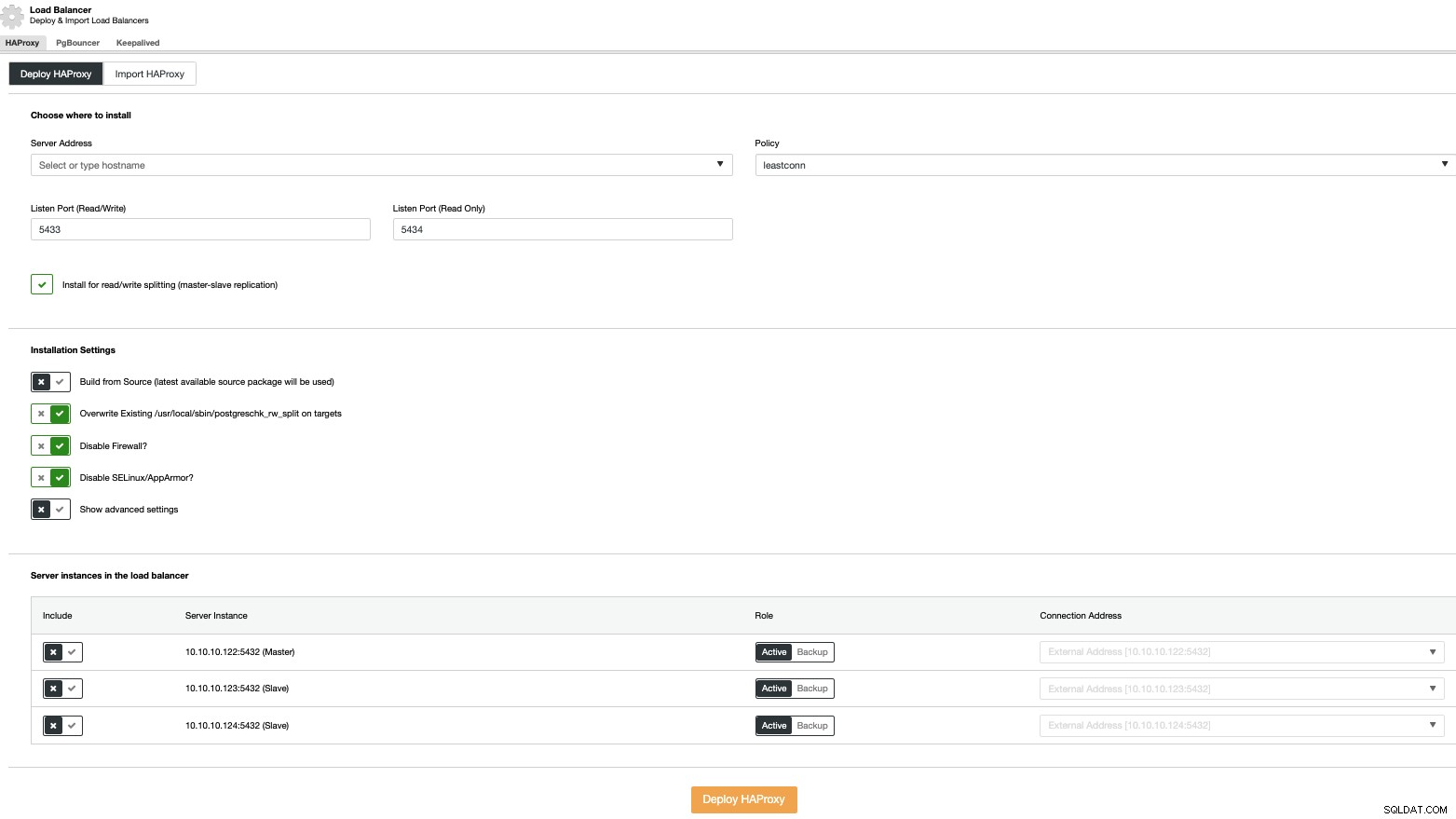
Devi solo aggiungere l'indirizzo IP o il nome host, la porta, la politica, e i nodi che configurerai nei tuoi bilanciatori di carico.
Distribuzione mantenuta
Per eseguire un'implementazione keepalived, seleziona il cluster, vai al menu "Gestisci" e alla sezione "Load Balancer", quindi seleziona l'opzione "Keepalived".
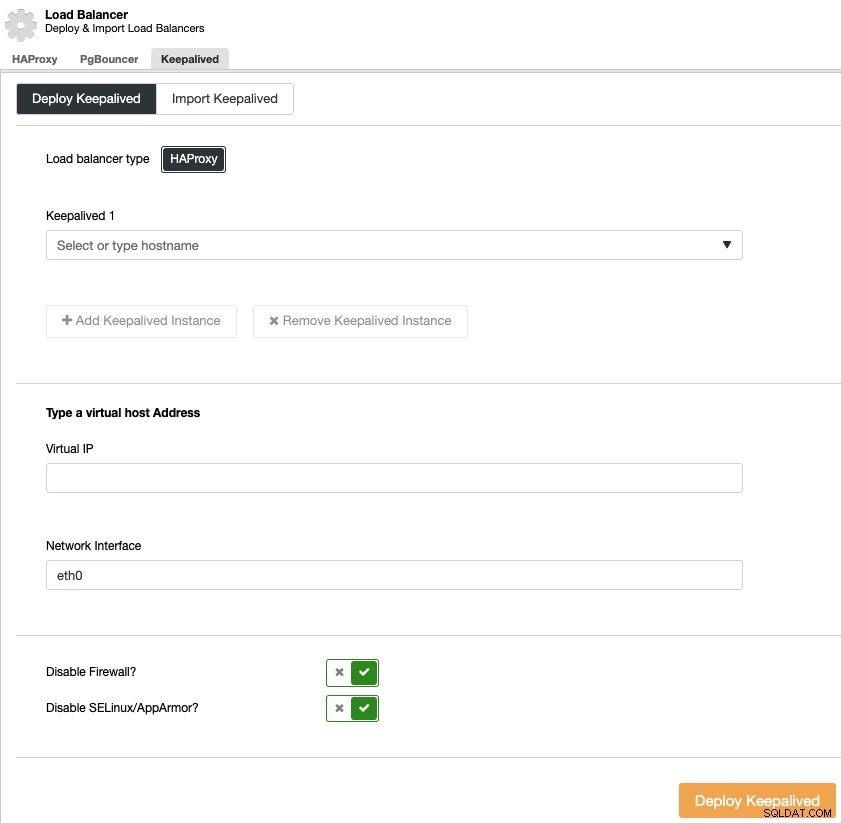
Devi selezionare i server di bilanciamento del carico e l'indirizzo IP virtuale per il tuo ambiente di disponibilità.
Keepalived utilizza l'indirizzo IP virtuale e lo migra da un sistema di bilanciamento del carico a un altro in caso di guasto, in modo che i tuoi sistemi possano continuare a funzionare normalmente.
Se hai seguito i passaggi precedenti, dovresti avere la seguente topologia:
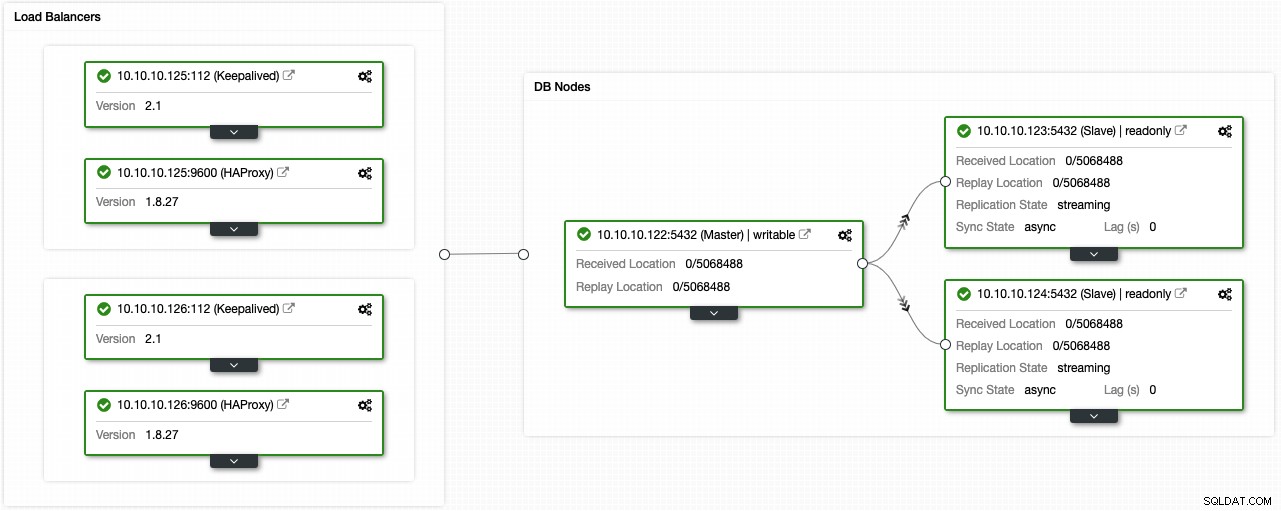
Puoi migliorare questo ambiente ad alta disponibilità aggiungendo un pool di connessioni come PgBouncer. Non è un must, ma potrebbe essere utile per migliorare le prestazioni e gestire le connessioni attive in caso di guasto e la cosa migliore è che puoi anche implementarlo utilizzando ClusterControl.
Failover di ClusterControl
Supponiamo che l'opzione "Ripristino automatico" sia attiva nel server ClusterControl. In caso di guasto del Primario, ClusterControl promuoverà lo Standby più avanzato (se non è nella lista nera) a Primario, oltre a informarti del problema. Eseguirà inoltre il failover del resto dei nodi di standby per la replica dal nuovo primario.
HAProxy è configurato di default con due porte differenti; porte di lettura-scrittura e di sola lettura.
Nella tua porta di lettura-scrittura, hai il tuo server primario online e il resto dei tuoi nodi offline, e nella porta di sola lettura hai sia il server primario che quelli di standby online.
Quando HAProxy rileva che uno dei tuoi nodi, primario o standby, non è accessibile, lo contrassegna automaticamente come offline. Non ne tiene conto per l'invio di traffico ad esso. Il rilevamento viene eseguito dagli script di controllo dello stato che ClusterControl configura al momento della distribuzione. Questi controllano se le istanze sono attive, se sono in fase di ripristino o sono di sola lettura.
Quando ClusterControl promuove uno Standby a Primario, HAProxy contrassegna il vecchio Primario come offline per entrambe le porte e mette il nodo promosso online nella porta di lettura-scrittura.
Se il tuo HAProxy attivo, che ha assegnato l'indirizzo IP virtuale a cui si connettono i tuoi sistemi, fallisce, Keepalived migra automaticamente questo indirizzo IP al tuo HAProxy passivo. Ciò significa che i tuoi sistemi potranno continuare a funzionare normalmente.
In questo modo, i tuoi sistemi continuano a funzionare come previsto e senza il tuo intervento manuale.
Considerazioni
Se riesci a ripristinare il tuo vecchio nodo primario guasto, NON verrà reintrodotto automaticamente nel cluster per impostazione predefinita. Devi farlo manualmente. Uno dei motivi è che se la replica è stata ritardata al momento dell'errore e ClusterControl aggiunge il vecchio primario al cluster, ciò significherebbe la perdita di informazioni o l'incoerenza dei dati tra i nodi. Potresti anche voler analizzare il problema in dettaglio. Se ClusterControl ha appena reintrodotto il nodo guasto nel cluster, potresti perdere le informazioni diagnostiche.
Inoltre, se il failover fallisce, non vengono effettuati ulteriori tentativi. È necessario un intervento manuale per analizzare il problema ed eseguire le azioni corrispondenti. Questo per evitare la situazione in cui ClusterControl, in qualità di gestore dell'alta disponibilità, tenta di promuovere il prossimo Standby e il successivo. Potrebbe esserci un problema e dovrai verificarlo.
Sicurezza
Una cosa importante che non puoi dimenticare prima di entrare in produzione con il tuo ambiente ad alta disponibilità è garantirne la sicurezza.
Diversi aspetti di sicurezza da considerare includono la crittografia, la gestione dei ruoli e la restrizione dell'accesso in base all'indirizzo IP, che abbiamo trattato in modo approfondito in un blog precedente.
Nel tuo database PostgreSQL, hai il file pg_hba.conf, che gestisce l'autenticazione del client. È possibile limitare il tipo di connessione, l'indirizzo IP di origine o la rete, il database a cui connettersi e con quali utenti. Pertanto, questo file è un elemento fondamentale per la sicurezza di PostgreSQL.
Puoi configurare il tuo database PostgreSQL dal file postgresql.conf, in modo che sia in ascolto solo su un'interfaccia di rete specifica e una porta diversa da quella predefinita (5432), evitando così tentativi di connessione di base da fonti indesiderate .
La corretta gestione degli utenti, utilizzando password sicure o limitando l'accesso e i privilegi, è un altro elemento fondamentale delle impostazioni di sicurezza. Si consiglia di assegnare il minor numero possibile di privilegi a tutti gli utenti e di specificare, se possibile, l'origine della connessione.
Puoi anche abilitare la crittografia dei dati, in transito o inattivi, evitando l'accesso alle informazioni a persone non autorizzate.
Un registro di controllo è utile per capire cosa sta succedendo o è successo nel tuo database. PostgreSQL ti consente di configurare diversi parametri per la registrazione o persino di utilizzare l'estensione pgAudit per questa attività.
Ultimo ma non meno importante, si consiglia di mantenere aggiornati database e server con le ultime patch per evitare rischi per la sicurezza. Per questo, ClusterControl ti consente di generare report operativi per verificare se hai aggiornamenti disponibili e persino aiutarti ad aggiornare i tuoi server di database.
Conclusione
Le implementazioni ad alta disponibilità possono sembrare difficili da raggiungere, in particolare quando si tratta di comprendere le diverse architetture e i componenti necessari per configurarle correttamente.
Se gestisci l'HA manualmente, assicurati di controllare Esecuzione delle modifiche alla topologia della replica per PostgreSQL. Molti cercheranno strumenti come ClusterControl per gestire la distribuzione, i servizi di bilanciamento del carico, il failover, la sicurezza e altro per un ambiente ad alta disponibilità completo. Puoi scaricare ClusterControl gratuitamente per 30 giorni per vedere come può alleviare l'onere della gestione di un'infrastruttura di database ad alta disponibilità.
Comunque tu scelga di gestire i tuoi database PostgreSQL ad alta disponibilità, assicurati di seguirci su Twitter o LinkedIn o iscriviti alla nostra newsletter per ricevere gli ultimi aggiornamenti e le migliori pratiche per la gestione delle impostazioni del tuo database.