Uno dei requisiti primari per qualsiasi database è il raggiungimento della scalabilità. Può essere ottenuto solo se la contesa (blocco) viene ridotta al minimo il più possibile, se non rimossa del tutto. Poiché lettura/scrittura/aggiornamento/eliminazione sono alcune delle principali operazioni frequenti che si verificano nel database, quindi è molto importante che queste operazioni continuino contemporaneamente senza essere bloccate. Per raggiungere questo obiettivo, la maggior parte dei principali database utilizza un modello di concorrenza chiamato Controllo di concorrenza multi-versione che riduce la contesa a un livello minimo.
Cos'è MVCC
Multi Version Concurrency Control (da qui in avanti MVCC) è un algoritmo per fornire un controllo preciso della concorrenza mantenendo più versioni dello stesso oggetto in modo che le operazioni di LETTURA e SCRITTURA non siano in conflitto. Qui SCRITTURA significa AGGIORNAMENTO ed ELIMINA, poiché il record appena INSERITO sarà comunque protetto secondo il livello di isolamento. Ogni operazione di SCRITTURA produce una nuova versione dell'oggetto e ogni operazione di lettura simultanea legge una versione diversa dell'oggetto a seconda del livello di isolamento. Poiché leggi e scrivi entrambi operano su versioni diverse dello stesso oggetto, quindi nessuna di queste operazioni richiede il blocco completo e quindi entrambe possono funzionare contemporaneamente. L'unico caso in cui la contesa può ancora esistere è quando due transazioni simultanee tentano di SCRIVERE lo stesso record.
La maggior parte dell'attuale database principale supporta MVCC. L'intenzione di questo algoritmo è mantenere più versioni dello stesso oggetto in modo che l'implementazione di MVCC differisca da database a database solo in termini di come vengono create e mantenute più versioni. Di conseguenza, il funzionamento del database corrispondente e la memorizzazione dei dati cambiano.
L'approccio più riconosciuto per implementare MVCC è quello utilizzato da PostgreSQL e Firebird/Interbase e un altro è utilizzato da InnoDB e Oracle. Nelle sezioni successive, discuteremo in dettaglio come è stato implementato in PostgreSQL e InnoDB.
MVCC in PostgreSQL
Per supportare più versioni, PostgreSQL mantiene campi aggiuntivi per ogni oggetto (Tuple nella terminologia PostgreSQL) come indicato di seguito:
- xmin – ID transazione della transazione che ha inserito o aggiornato la tupla. In caso di UPDATE, una versione più recente della tupla viene assegnata con questo ID transazione.
- xmax – ID transazione della transazione che ha eliminato o aggiornato la tupla. In caso di UPDATE, a una versione attualmente esistente della tupla viene assegnato questo ID transazione. In una tupla appena creata, il valore predefinito di questo campo è null.
PostgreSQL archivia tutti i dati in un archivio principale chiamato HEAP (pagina di dimensioni predefinite di 8 KB). Tutta la nuova tupla ottiene xmin come transazione che l'ha creata e la tupla della versione precedente (che è stata aggiornata o eliminata) viene assegnata con xmax. C'è sempre un collegamento dalla tupla della versione precedente alla nuova versione. La tupla della versione precedente può essere utilizzata per ricreare la tupla in caso di rollback e per leggere una versione precedente di una tupla tramite l'istruzione READ a seconda del livello di isolamento.
Considera che ci sono due tuple, T1 (con valore 1) e T2 (con valore 2) per una tabella, la creazione di nuove righe può essere dimostrata in 3 passaggi seguenti:
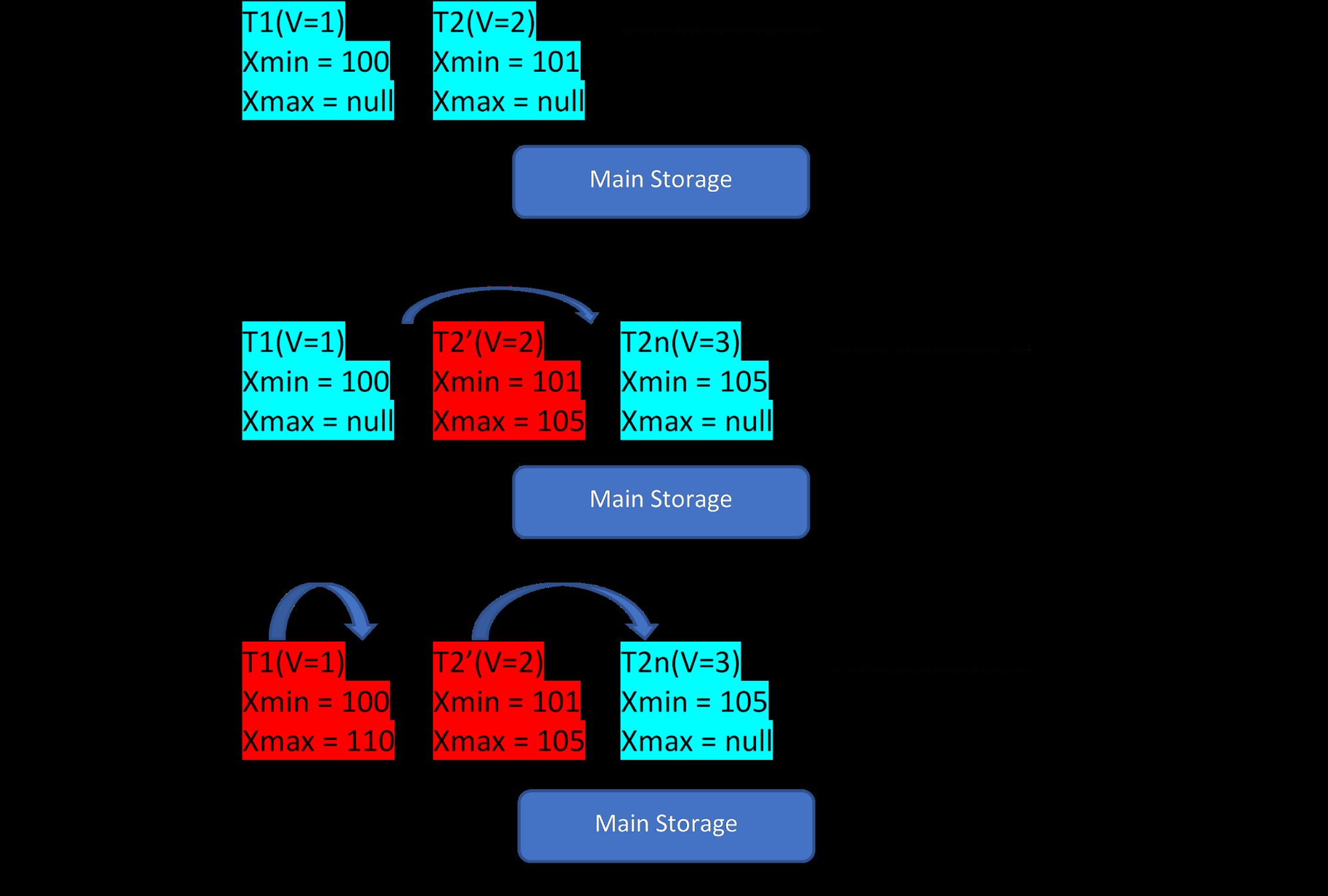 MVCC:archiviazione di più versioni in PostgreSQL
MVCC:archiviazione di più versioni in PostgreSQL Come si vede dall'immagine, inizialmente nel database sono presenti due tuple con valori 1 e 2.
Quindi, come al secondo passaggio, la riga T2 con valore 2 viene aggiornata con il valore 3. A questo punto viene creata una nuova versione con il nuovo valore e viene semplicemente archiviata come accanto alla tupla esistente nella stessa area di archiviazione . Prima di ciò, la versione precedente viene assegnata con xmax e punta alla tupla della versione più recente.
Allo stesso modo, nel terzo passaggio, quando la riga T1 con valore 1 viene eliminata, la riga esistente viene virtualmente eliminata (cioè è appena assegnata a xmax con la transazione corrente) nello stesso posto. Nessuna nuova versione viene creata per questo.
Successivamente, vediamo come ogni operazione crea più versioni e come il livello di isolamento della transazione viene mantenuto senza bloccarsi con alcuni esempi reali. In tutti gli esempi seguenti, per impostazione predefinita, viene utilizzato l'isolamento "READ COMMITTED".
INSERIRE
Ogni volta che un record viene inserito, viene creata una nuova tupla, che viene aggiunta a una delle pagine appartenenti alla tabella corrispondente.
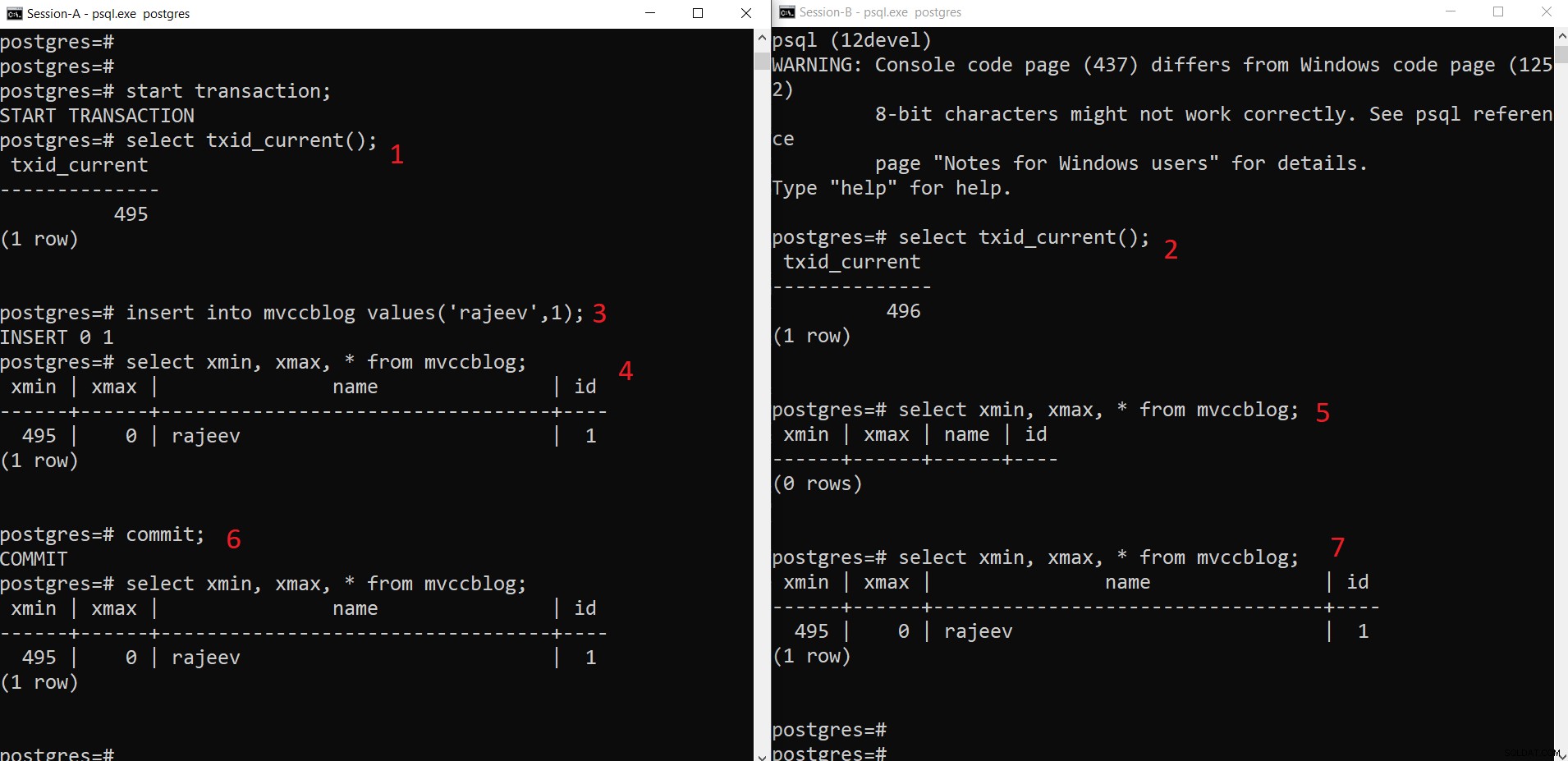 Operazione INSERT simultanea PostgreSQL
Operazione INSERT simultanea PostgreSQL Come possiamo vedere qui passo passo:
- La sessione A avvia una transazione e ottiene l'ID transazione 495.
- La sessione-B avvia una transazione e ottiene l'ID transazione 496.
- La sessione A inserisce una nuova tupla (viene archiviata in HEAP)
- Ora viene aggiunta la nuova tupla con xmin impostato sull'ID transazione corrente 495.
- Ma lo stesso non è visibile dalla Session-B poiché xmin (ovvero 495) non è ancora stato eseguito il commit.
- Una volta impegnato.
- I dati sono visibili a entrambe le sessioni.
AGGIORNAMENTO
PostgreSQL UPDATE non è un aggiornamento "IN-PLACE", ovvero non modifica l'oggetto esistente con il nuovo valore richiesto. Al contrario, crea una nuova versione dell'oggetto. Pertanto, l'AGGIORNAMENTO implica in generale i passaggi seguenti:
- Segna l'oggetto corrente come eliminato.
- Quindi aggiunge una nuova versione dell'oggetto.
- Reindirizza la versione precedente dell'oggetto a una nuova versione.
Quindi, anche se un numero di record rimane lo stesso, HEAP occupa spazio come se fosse stato inserito un altro record.
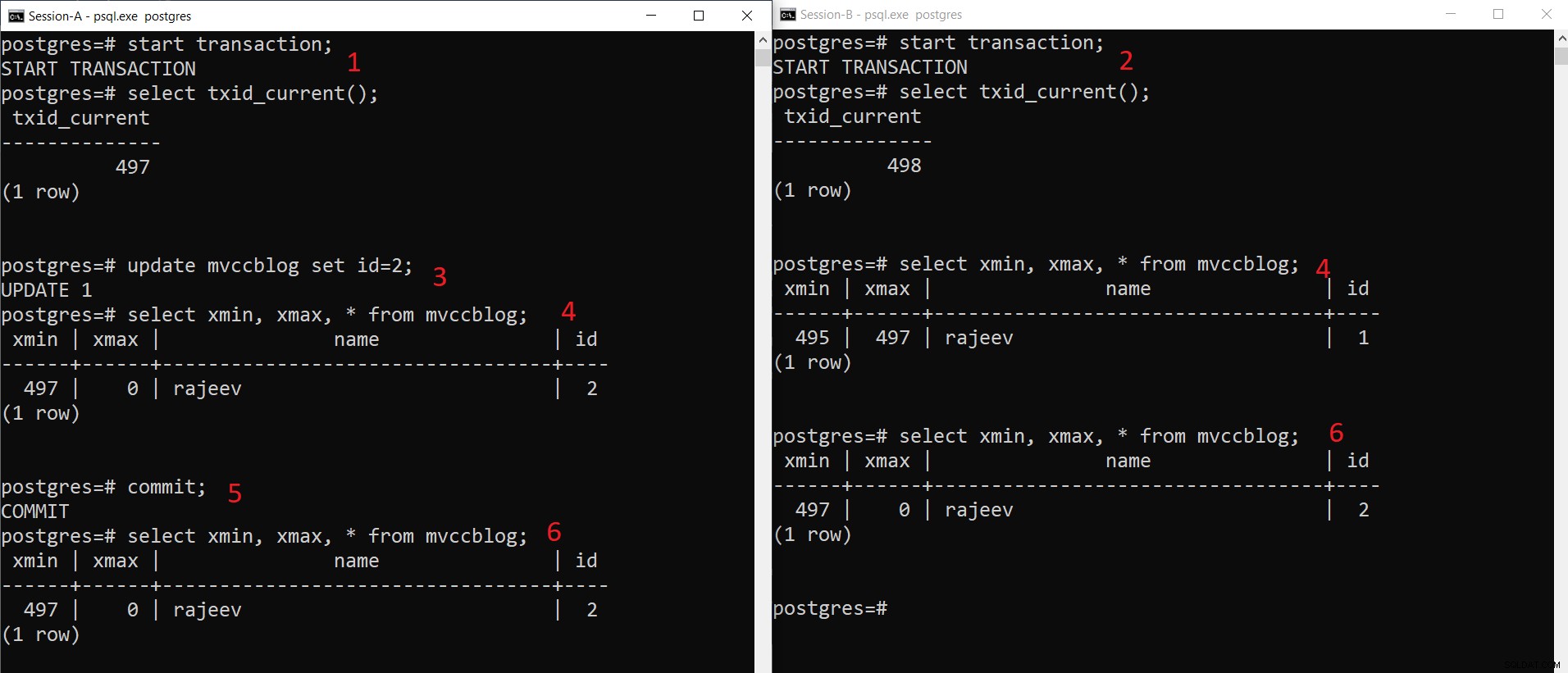 Operazione INSERT simultanea PostgreSQL
Operazione INSERT simultanea PostgreSQL Come possiamo vedere qui passo passo:
- La sessione A avvia una transazione e ottiene l'ID transazione 497.
- La sessione-B avvia una transazione e ottiene l'ID transazione 498.
- La sessione A aggiorna il record esistente.
- Qui Session-A vede una versione della tupla (tupla aggiornata) mentre Session-B vede un'altra versione (tupla precedente ma xmax impostato su 497). Entrambe le versioni della tupla vengono archiviate nella memoria HEAP (anche nella stessa pagina a seconda della disponibilità di spazio)
- Una volta che Session-A ha eseguito il commit della transazione, la tupla precedente scade quando viene eseguito il commit xmax della tupla precedente.
- Ora entrambe le sessioni vedono la stessa versione del record.
ELIMINA
L'eliminazione è quasi come l'operazione di AGGIORNAMENTO, tranne per il fatto che non è necessario aggiungere una nuova versione. Contrassegna semplicemente l'oggetto corrente come CANCELLATO come spiegato nel caso UPDATE.
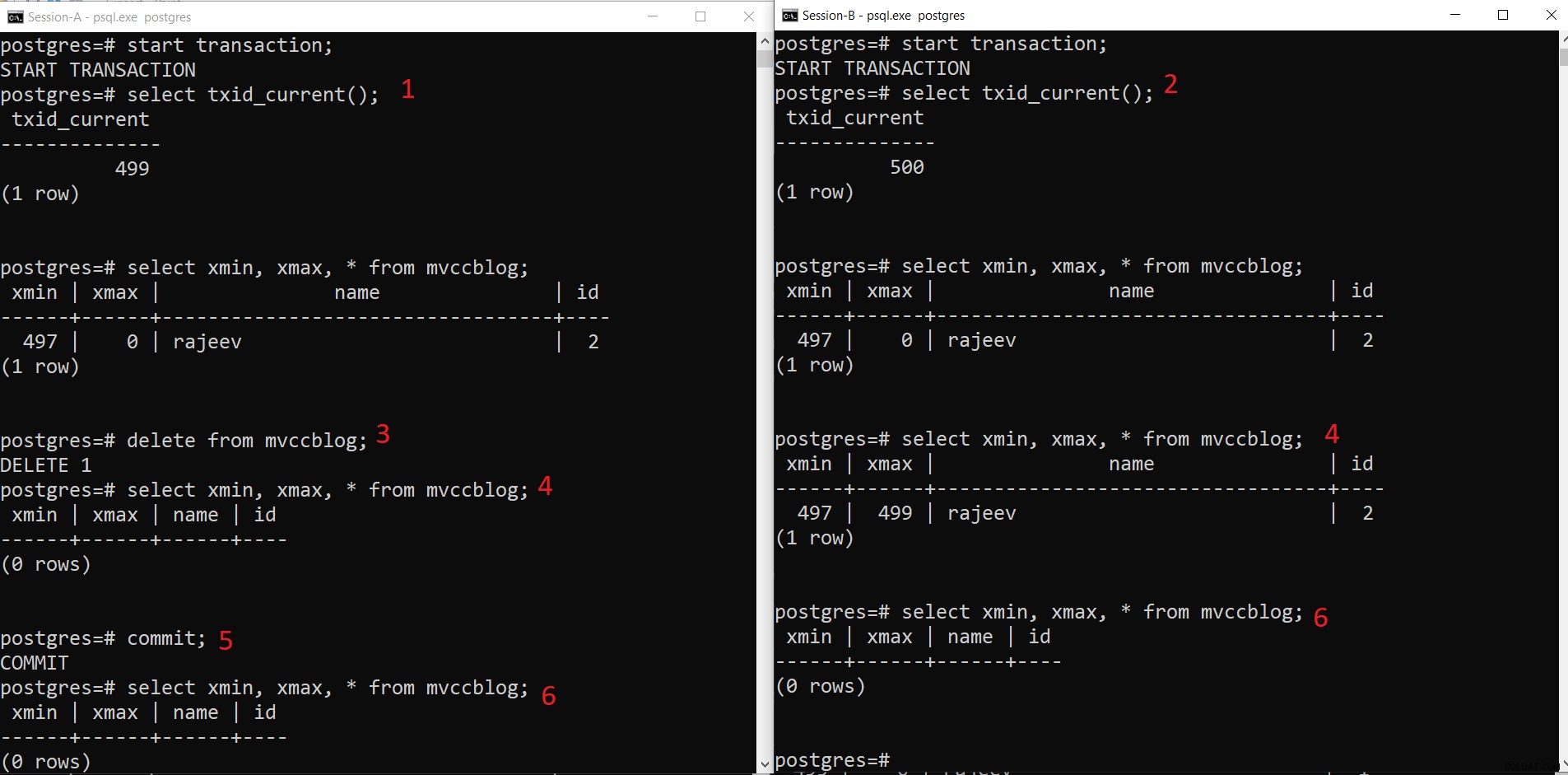 Operazione DELETE simultanea di PostgreSQL
Operazione DELETE simultanea di PostgreSQL - La sessione A avvia una transazione e ottiene l'ID transazione 499.
- La sessione-B avvia una transazione e ottiene l'ID transazione 500.
- La sessione A elimina il record esistente.
- Qui Session-A non vede alcuna tupla come eliminata dalla transazione corrente. Mentre Session-B vede una versione precedente della tupla (con xmax come 499; la transazione che ha cancellato questo record).
- Una volta che Session-A ha eseguito il commit della transazione, la tupla precedente scade quando viene eseguito il commit xmax della tupla precedente.
- Ora entrambe le sessioni non vedono la tupla eliminata.
Come possiamo vedere, nessuna delle operazioni rimuove direttamente la versione esistente dell'oggetto e, ove necessario, aggiunge una versione aggiuntiva dell'oggetto.
Ora, vediamo come la query SELECT viene eseguita su una tupla con più versioni:SELECT deve leggere tutte le versioni della tupla finché non trova la tupla appropriata secondo il livello di isolamento. Supponiamo che ci fosse la tupla T1, che è stata aggiornata e ha creato la nuova versione T1' e che a sua volta ha creato T1'' all'aggiornamento:
- L'operazione SELECT passerà attraverso l'archiviazione heap per questa tabella e prima verificherà T1. Se la transazione T1 xmax è stata confermata, si sposta alla versione successiva di questa tupla.
- Supponiamo ora che anche la tupla xmax di T1 sia impegnata, quindi di nuovo si sposti alla versione successiva di questa tupla.
- Infine, trova T1'' e vede che xmax non è vincolato (o nullo) e T1'' xmin è visibile alla transazione corrente come da livello di isolamento. Infine, leggerà la tupla T1''.
Come possiamo vedere, deve attraversare tutte e 3 le versioni della tupla per trovare la tupla visibile appropriata finché la tupla scaduta non viene eliminata dal Garbage Collector (VACUUM).
MVCC in InnoDB
Per supportare più versioni, InnoDB mantiene campi aggiuntivi per ogni riga come indicato di seguito:
- DB_TRX_ID:ID transazione della transazione che ha inserito o aggiornato la riga.
- DB_ROLL_PTR:è anche chiamato roll pointer e punta ad annullare il record di registro scritto nel segmento di rollback (ne parleremo più avanti).
Come PostgreSQL, anche InnoDB crea più versioni della riga come parte di tutte le operazioni, ma l'archiviazione della versione precedente è diversa.
Nel caso di InnoDB, la vecchia versione della riga modificata viene conservata in un tablespace/storage separato (chiamato segmento di annullamento). Quindi, a differenza di PostgreSQL, InnoDB conserva solo l'ultima versione delle righe nell'area di archiviazione principale e la versione precedente nel segmento di annullamento. Le versioni di riga del segmento di annullamento vengono utilizzate per annullare l'operazione in caso di rollback e per leggere una versione precedente di righe tramite l'istruzione READ a seconda del livello di isolamento.
Considera che ci sono due righe, T1 (con valore 1) e T2 (con valore 2) per una tabella, la creazione di nuove righe può essere dimostrata in 3 passaggi seguenti:
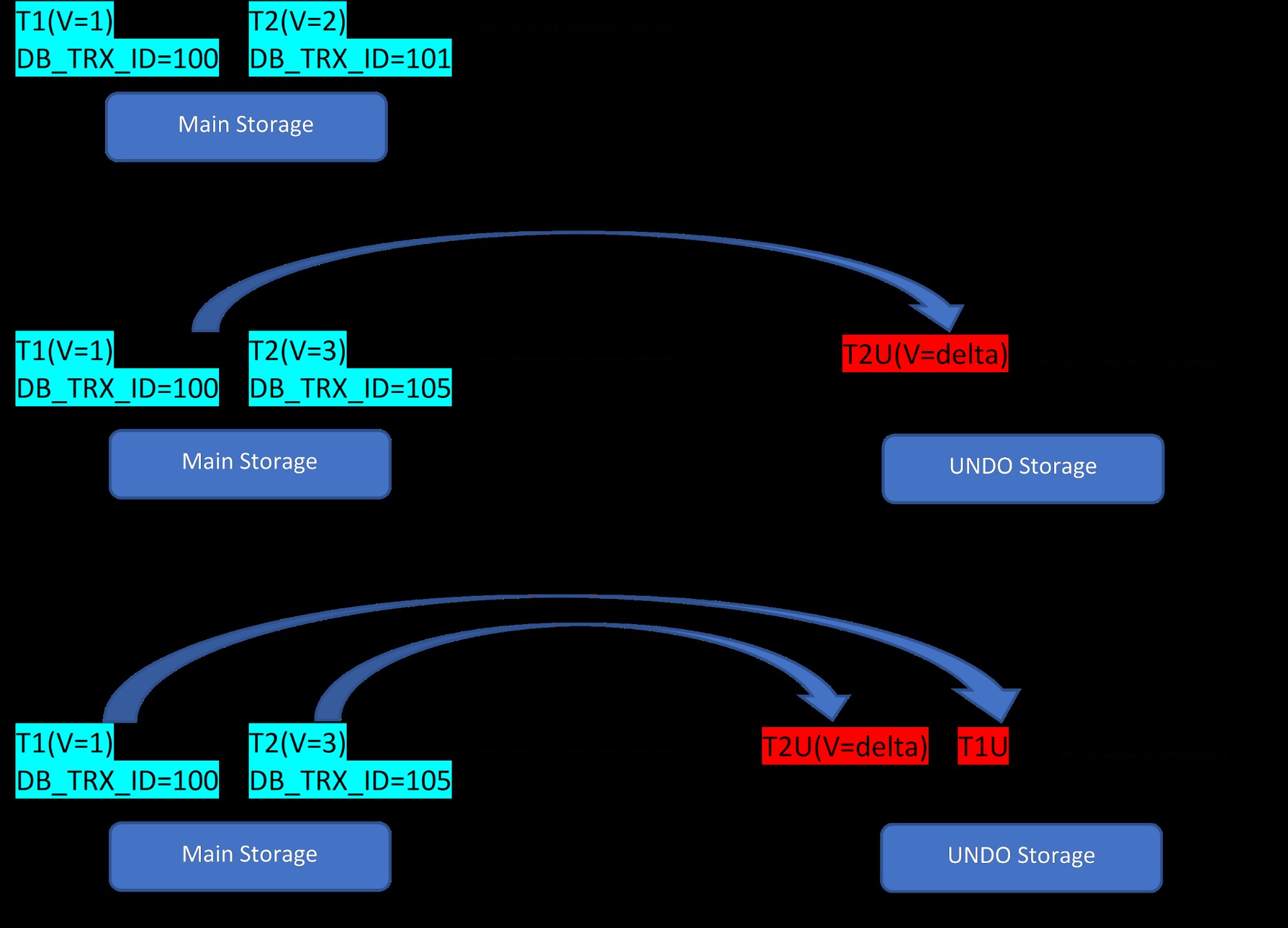 MVCC:archiviazione di più versioni in InnoDB
MVCC:archiviazione di più versioni in InnoDB Come si vede dalla figura, inizialmente nel database sono presenti due righe con valori 1 e 2.
Quindi, come nella seconda fase, la riga T2 con valore 2 viene aggiornata con il valore 3. A questo punto viene creata una nuova versione con il nuovo valore e sostituisce la versione precedente. Prima di ciò, la versione precedente viene archiviata nel segmento di annullamento (notare che la versione del segmento UNDO ha solo un valore delta). Inoltre, nota che c'è un puntatore dalla nuova versione alla versione precedente nel segmento di rollback. Quindi, a differenza di PostgreSQL, l'aggiornamento di InnoDB è "IN-PLACE".
Allo stesso modo, nel terzo passaggio, quando la riga T1 con valore 1 viene eliminata, la riga esistente viene virtualmente eliminata (cioè contrassegna solo un bit speciale nella riga) nell'area di archiviazione principale e una nuova versione corrispondente a questa viene aggiunta in il segmento Annulla. Di nuovo, c'è un puntatore di rollio dalla memoria principale al segmento di annullamento.
Tutte le operazioni si comportano allo stesso modo del caso di PostgreSQL se viste dall'esterno. Solo la memoria interna di più versioni differisce.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperMVCC:PostgreSQL vs InnoDB
Ora, analizziamo quali sono le principali differenze tra PostgreSQL e InnoDB in termini di implementazione MVCC:
-
Dimensioni di una versione precedente
PostgreSQL aggiorna semplicemente xmax sulla versione precedente della tupla, quindi la dimensione della versione precedente rimane la stessa per il record inserito corrispondente. Ciò significa che se hai 3 versioni di una tupla precedente, tutte avranno la stessa dimensione (tranne la differenza nella dimensione effettiva dei dati, se presente ad ogni aggiornamento).
Mentre nel caso di InnoDB, la versione dell'oggetto memorizzata nel segmento Undo è in genere più piccola del record inserito corrispondente. Questo perché solo i valori modificati (cioè differenziali) vengono scritti nel registro UNDO.
-
Operazione INSERIMENTO
InnoDB ha bisogno di scrivere un record aggiuntivo nel segmento UNDO anche per INSERT mentre PostgreSQL crea una nuova versione solo in caso di UPDATE.
-
Ripristino di una versione precedente in caso di rollback
PostgreSQL non ha bisogno di nulla di specifico per ripristinare una versione precedente in caso di rollback. Ricorda che la versione precedente ha xmax uguale alla transazione che ha aggiornato questa tupla. Quindi, fino a quando questo ID transazione non viene eseguito, è considerato una tupla viva per uno snapshot simultaneo. Una volta annullato il rollback della transazione, la transazione corrispondente verrà automaticamente considerata attiva per tutte le transazioni poiché sarà una transazione interrotta.
Mentre nel caso di InnoDB, è esplicitamente richiesto di ricostruire la versione precedente dell'oggetto una volta eseguito il rollback.
-
Recupero dello spazio occupato da una versione precedente
Nel caso di PostgreSQL, lo spazio occupato da una versione precedente può essere considerato morto solo quando non esiste uno snapshot parallelo per leggere questa versione. Una volta che la versione precedente è morta, l'operazione VACUUM può recuperare lo spazio occupato da loro. VACUUM può essere attivato manualmente o come attività in background a seconda della configurazione.
I registri UNDO di InnoDB sono principalmente divisi in INSERT UNDO e UPDATE UNDO. Il primo viene scartato non appena viene eseguita la transazione corrispondente. Il secondo deve essere conservato finché non è parallelo a qualsiasi altro snapshot. InnoDB non ha un'operazione VACUUM esplicita ma su una linea simile ha PURGE asincrono per eliminare i registri UNDO che vengono eseguiti come attività in background.
-
Impatto del vuoto ritardato
Come discusso in un punto precedente, c'è un enorme impatto del vuoto ritardato nel caso di PostgreSQL. Fa sì che la tabella inizi a gonfiarsi e provoca un aumento dello spazio di archiviazione anche se i record vengono costantemente eliminati. Potrebbe anche raggiungere un punto in cui è necessario eseguire VACUUM FULL, operazione molto costosa.
-
Scansione sequenziale in caso di tavolo gonfio
La scansione sequenziale di PostgreSQL deve attraversare tutte le versioni precedenti di un oggetto anche se tutte sono morte (fino a quando non vengono rimosse usando il vuoto). Questo è il problema tipico e più discusso in PostgreSQL. Ricorda PostgreSQL archivia tutte le versioni di una tupla nella stessa memoria.
Considerando che nel caso di InnoDB, non è necessario leggere il record Annulla a meno che non sia richiesto. Nel caso in cui tutti i record di annullamento siano morti, sarà sufficiente leggere tutta l'ultima versione degli oggetti.
-
Indice
PostgreSQL archivia l'indice in una memoria separata che mantiene un collegamento ai dati effettivi in HEAP. Quindi PostgreSQL deve aggiornare anche la parte INDEX anche se non ci sono state modifiche in INDEX. Sebbene in seguito questo problema sia stato risolto implementando l'aggiornamento HOT (Heap Only Tuple), presenta comunque la limitazione che se una nuova tupla heap non può essere ospitata nella stessa pagina, viene eseguito il fallback al normale UPDATE.
InnoDB non ha questo problema poiché utilizzano l'indice cluster.
Conclusione
PostgreSQL MVCC ha alcuni inconvenienti soprattutto in termini di spazio di archiviazione gonfio se il tuo carico di lavoro ha frequenti AGGIORNAMENTI/ELIMINA. Quindi, se decidi di utilizzare PostgreSQL, dovresti stare molto attento a configurare VACUUM in modo saggio.
Anche la comunità di PostgreSQL ha riconosciuto questo come un problema importante e ha già iniziato a lavorare sull'approccio MVCC basato su UNDO (nome provvisorio come ZHEAP) e potremmo vedere lo stesso in una versione futura.



