Quando si distribuisce un cluster di database in server diversi, si ottiene il vantaggio della replica di migliorare la disponibilità dei dati. Tuttavia è necessario tenere traccia dei processi e vedere se sono in esecuzione o meno. Uno dei programmi utilizzati in questo processo è Heartbeat che ha la capacità di controllare e verificare la presenza di risorse su uno o più sistemi in un dato cluster. Oltre a PostgreSQL e ai file system per i quali sono archiviati i dati PostgreSQL, il DRBD è una delle risorse di cui parleremo in questo articolo su come utilizzare il programma Heartbeat.
Ha battito cardiaco
Come discusso in precedenza nel blog DRBD, l'elevata disponibilità dei dati si ottiene eseguendo diverse istanze del server ma servendo gli stessi dati. Queste istanze del server in esecuzione possono essere definite come un cluster in relazione a un Heartbeat. Fondamentalmente, ciascuna istanza del server è fisicamente in grado di fornire lo stesso servizio delle altre all'interno di quel cluster. Tuttavia, solo un'istanza alla volta può fornire attivamente il servizio allo scopo di garantire un'elevata disponibilità dei dati. Possiamo quindi definire le altre istanze come 'hot-spare' che possono essere messe in servizio in caso di guasto del master. Il pacchetto Heartbeat può essere scaricato da questo link. Dopo aver installato questo pacchetto, puoi configurarlo per funzionare con il tuo sistema con la procedura seguente. Una struttura semplice della configurazione di Heartbeat è:
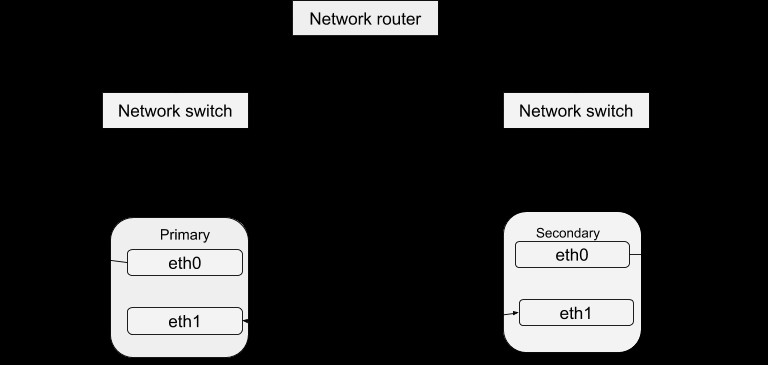
Configurazione del battito cardiaco
Guardando in questa directory /etc/ha.d troverai alcuni file che vengono utilizzati nel processo di configurazione. Il file ha.cf costituisce la configurazione principale dell'heartbeat. Include l'elenco di tutti i nodi e i tempi per l'identificazione dell'errore oltre a indirizzare l'heartbeat su quale tipo di percorsi multimediali utilizzare e come configurarli. Le informazioni sulla sicurezza per il cluster vengono registrate nel file authkeys. Le informazioni registrate in questi file dovrebbero essere identiche per tutti gli host nel cluster e ciò può essere ottenuto facilmente tramite la sincronizzazione tra tutti gli host. Vale a dire che qualsiasi modifica delle informazioni in un host dovrebbe essere copiata in tutti gli altri.
File Ha.cf
Lo schema di base del file ha.cf è
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility:questo viene utilizzato per indirizzare l'Heartbeat su quale funzione di registrazione del syslog dovrebbe utilizzare per la registrazione dei messaggi. I valori più comunemente usati sono auth, authpriv, user, local0, syslog e daemon. Puoi anche decidere di non avere alcun registro in modo da poter impostare il valore su nessuno .i.e
logfacility none - Keepalive:questo è il tempo tra i battiti cardiaci ovvero la frequenza con cui il segnale del battito cardiaco viene inviato agli altri host. Nel codice di esempio sopra è impostato su 3 secondi.
- Deadtime:è il ritardo in secondi dopo il quale un nodo viene dichiarato fallito.
- Avviso:è il ritardo in secondi dopo il quale viene registrato un avviso in un log che indica che un nodo non può più essere contattato.
- Initdead:questo è il tempo in secondi di attesa durante l'avvio del sistema prima che l'altro host venga considerato inattivo.
- Mcast:è una procedura di metodo definita per l'invio di un segnale heartbeat. Per il codice di esempio precedente, l'indirizzo di rete multicast viene utilizzato su un dispositivo di rete limitato. Per un cluster multiplo, l'indirizzo multicast deve essere univoco per ogni cluster. Puoi anche scegliere una connessione seriale sul multicast o se la configurazione è in modo tale che ci siano più interfacce di rete, usa entrambe per la connessione heartbeat come nell'esempio. Il vantaggio dell'utilizzo di entrambi è quello di superare le possibilità di guasto transitorio che di conseguenza può causare un evento di guasto non valido.
- Auto_failback:questo ricollega un server che aveva eseguito il failback al cluster se diventa disponibile. Tuttavia, potrebbe creare confusione se il server viene acceso e quindi si collega in un momento diverso. In relazione al DRBD, se non è ben configurato, potresti ritrovarti con più di un set di dati nello stesso server. Pertanto, è consigliabile impostarlo sempre su off.
- Nodo:delinea il nodo all'interno del gruppo di cluster Heartbeat. Dovresti avere almeno 1 nodo per ciascuno.
Configurazioni aggiuntive
Puoi anche impostare informazioni di configurazione aggiuntive come:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:questo è importante per garantire la connettività sull'interfaccia pubblica per i server e la connessione a un altro host. È importante considerare l'indirizzo IP piuttosto che il nome host della macchina di destinazione.
- Respawn:questo è il comando da eseguire quando si verifica un errore.
- Apiauth:è l'autorità per il fallimento. È necessario configurare l'utente e l'ID gruppo con cui verrà eseguito il comando. Il file authkeys contiene le informazioni di autorizzazione per il cluster Heartbeat e questa chiave è molto esclusiva per la verifica delle macchine all'interno di un determinato cluster Heartbeat.
- Deadping:definisce il timeout prima che una mancata risposta provochi un errore.
Integrazione di Heartbeat con Postgres e DRBD
Come accennato in precedenza, quando un server master si guasta, un altro server con un determinato cluster entrerà in azione per fornire lo stesso servizio. Heartbeat aiuta nella configurazione delle risorse che migliorano la selezione di un server in caso di guasto. Ad esempio, definisce quali server individuali devono essere attivati o eliminati in caso di guasto. Effettuando il check-in nel file haresources nella directory /etc/ha.d, otteniamo uno schema delle risorse che possono essere gestite. Il percorso del file di risorse è /etc/ha.d/resource.d e la definizione della risorsa è in una riga che è:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(notare gli spazi bianchi).
- Drbd1:fa riferimento al nome dell'host preferito per essere più secante del server che normalmente viene utilizzato come master predefinito per la gestione del servizio. Come accennato nel blog DRBD, abbiamo bisogno di risorse per il nostro server e queste sono definite nella riga come drbddisk, filesystem e postgres. L'ultimo campo è un indirizzo IP virtuale che dovrebbe essere utilizzato per condividere il servizio, ovvero la connessione al server Postgres. Per impostazione predefinita, verrà assegnato al server attivo all'avvio di Heartbeat. Quando si verifica un errore, queste risorse verranno avviate sul server di backup in ordine di disposizione quando viene chiamato lo script corrispondente. Nell'impostazione, lo script commuterà il disco DRBD sull'host secondario in modalità primaria, rendendo il dispositivo in lettura/scrittura.
- Filesystem:gestirà le risorse del file system e in questo caso è stato selezionato il DRBD quindi verrà montato durante la chiamata dello script delle risorse.
- Postgres:questo avvierà o gestirà il server Postgres
A volte vorresti ricevere notifiche tramite e-mail. Per fare ciò, aggiungi questa riga al file delle risorse con la tua email per ricevere i testi di avviso:
MailTo:: example@sqldat.com::DRBDFailurePer avviare l'heartbeat, puoi eseguire il comando
/etc/ha.d/heartbeat startoppure riavviare sia il server primario che quello secondario. Ora se esegui il comando
$ /usr/lib64/heartbeat/hb_standbyIl nodo corrente verrà attivato per cedere le sue risorse in modo pulito all'altro nodo.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperGestione degli errori a livello di sistema
A volte il kernel del server potrebbe essere danneggiato, indicando quindi un potenziale problema con il tuo server. Sarà necessario configurare il server per rimuoversi dal cluster durante l'evento di un problema. Questo problema viene spesso definito panico del kernel e di conseguenza avvia un riavvio forzato sulla macchina. Puoi forzare un riavvio impostando kernel.panic e kernel.panic_on_oop del file di controllo del kernel /etc/sysctl.conf. Cioè
kernel.panic_on_oops = 1
kernel.panic = 1Un'altra opzione è farlo dalla riga di comando usando il comando sysctl cioè:
$ sysctl -w kernel.panic=1Puoi anche modificare il file sysctl.conf e ricaricare le informazioni di configurazione usando questo comando.
sysctl -pIl valore indica il numero di secondi di attesa prima del riavvio. Il secondo nodo heartbeat dovrebbe quindi rilevare che il server è inattivo e quindi passare all'host di failover.
Conclusione
Heartbeat è un sottosistema che consente la selezione di un server secondario in un sistema primario e un sistema di backup in caso di guasto di un server attivo. Determina anche se tutti gli altri server sono attivi. Garantisce inoltre il trasferimento delle risorse al nuovo nodo primario



