Nel mio ultimo post, ho mostrato alcuni approcci efficienti alla concatenazione di gruppi. Questa volta, volevo parlare di un paio di aspetti aggiuntivi di questo problema che possiamo risolvere facilmente con FOR XML PATH approccio:ordinare l'elenco e rimuovere i duplicati.
Ci sono alcuni modi in cui ho visto persone che vogliono che l'elenco separato da virgole venga ordinato. A volte vogliono che l'elemento nell'elenco sia ordinato in ordine alfabetico; L'ho mostrato già nel mio post precedente. Ma a volte vogliono che sia ordinato in base a qualche altro attributo che in realtà non viene introdotto nell'output; ad esempio, forse voglio prima ordinare l'elenco in base all'elemento più recente. Facciamo un semplice esempio, dove abbiamo una tabella Employees e una tabella CoffeeOrders. Popoliamo solo gli ordini di una persona per alcuni giorni:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Se utilizziamo l'approccio esistente senza specificare un ORDER BY , otteniamo un ordinamento arbitrario (in questo caso, è molto probabile che vedrai le righe nell'ordine in cui sono state inserite, ma non dipende da quello con set di dati più grandi, più indici, ecc.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Risultati (ricorda, potresti ottenere *diversi* risultati a meno che tu non specifichi un ORDER BY ):
Jack | Doppia grande doppia, doppia doppia media, Latte alla vaniglia grande, doppia doppia media
Se vogliamo ordinare l'elenco in ordine alfabetico, è semplice; aggiungiamo semplicemente ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Risultati:
Nome | OrdiniJack | Doppia grande doppia, Latte alla vaniglia grande, Doppia doppia media, Doppia doppia media
Possiamo anche ordinare in base a una colonna che non appare nel set di risultati; ad esempio, possiamo ordinare prima per ordine di caffè più recente:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Risultati:
Nome | OrdiniJack | Doppia media doppia, Large Vanilla Latte, Medium doppia doppia, Large doppia doppia
Un'altra cosa che spesso vogliamo fare è rimuovere i duplicati; dopo tutto, ci sono poche ragioni per vedere due volte "Medium double double". Possiamo eliminarlo usando GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Ora, questo *succede* per ordinare l'output in ordine alfabetico, ma ancora una volta non puoi fare affidamento su questo:
Nome | OrdiniJack | Doppia grande doppia, Latte alla vaniglia grande, Doppia doppia media
Se vuoi garantire che ordinando in questo modo, puoi semplicemente aggiungere nuovamente un ORDER BY:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
I risultati sono gli stessi (ma lo ripeto, in questo caso è solo una coincidenza; se volete quest'ordine, ditelo sempre):
Nome | OrdiniJack | Doppia grande doppia, Latte alla vaniglia grande, Doppia doppia media
Ma cosa succede se vogliamo eliminare i duplicati *e* ordinare prima l'elenco in base all'ordine di caffè più recente? La tua prima inclinazione potrebbe essere quella di mantenere il GROUP BY e cambia semplicemente il ORDER BY , in questo modo:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Non funzionerà, dal momento che OrderDate non è raggruppato o aggregato come parte della query:
La colonna "dbo.CoffeeOrders.OrderDate" non è valida nella clausola ORDER BY perché non è contenuta né in una funzione aggregata né nella clausola GROUP BY.
Una soluzione alternativa, che certamente rende la query un po' più brutta, consiste nel raggruppare prima gli ordini separatamente, quindi prendere solo le righe con la data massima per quell'ordine di caffè per dipendente:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Risultati:
Nome | OrdiniJack | Doppia media doppia, Large Vanilla Latte, Large doppia doppia
Questo raggiunge entrambi i nostri obiettivi:abbiamo eliminato i duplicati e abbiamo ordinato l'elenco in base a qualcosa che non è effettivamente nell'elenco.
Prestazioni
Ti starai chiedendo quanto male si comportano questi metodi rispetto a un set di dati più robusto. Popolerò la nostra tabella con 100.000 righe, vedrò come funzionano senza indici aggiuntivi, quindi eseguirò di nuovo le stesse query con un po' di ottimizzazione dell'indice per supportare le nostre query. Quindi, per prima cosa, ottenere 100.000 righe distribuite su 1.000 dipendenti:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Ora eseguiamo ciascuna delle nostre query due volte e vediamo come sono i tempi al secondo tentativo (faremo un atto di fede qui e supponiamo che, in un mondo ideale, lavoreremo con una cache innescata ). Li ho eseguiti in SQL Sentry Plan Explorer, poiché è il modo più semplice che conosco per cronometrare e confrontare un gruppo di singole query:
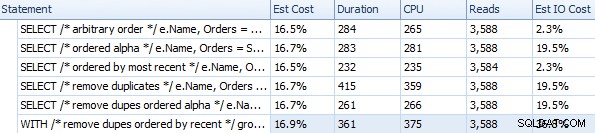 Durata e altre metriche di runtime per diversi approcci FOR XML PATH
Durata e altre metriche di runtime per diversi approcci FOR XML PATH
Questi tempi (la durata è in millisecondi) non sono affatto così male IMHO, quando si pensa a ciò che viene effettivamente fatto qui. Il piano più complicato, almeno visivamente, sembrava essere quello in cui abbiamo rimosso i duplicati e ordinato l'ordine più recente:
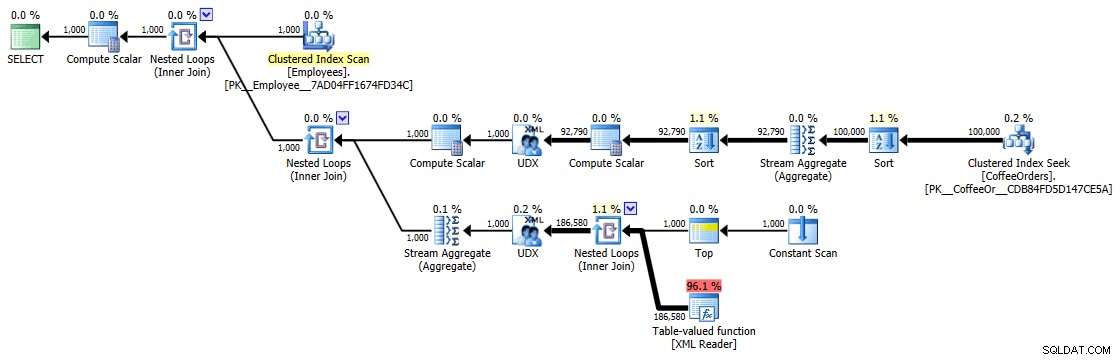 Piano di esecuzione per query raggruppate e ordinate
Piano di esecuzione per query raggruppate e ordinate
Ma anche l'operatore più costoso qui - la funzione con valori di tabella XML - sembra essere tutta CPU (anche se ammetto liberamente che non sono sicuro di quanto del lavoro effettivo sia esposto nei dettagli del piano di query):
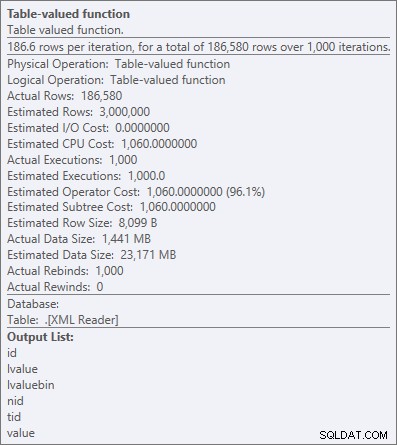 Proprietà dell'operatore per la funzione XML con valori di tabella
Proprietà dell'operatore per la funzione XML con valori di tabella
"Tutta la CPU" in genere va bene, poiché la maggior parte dei sistemi sono legati all'I/O e/o alla memoria, non alla CPU. Come dico abbastanza spesso, nella maggior parte dei sistemi baratterò parte del margine della mia CPU con memoria o disco in qualsiasi giorno della settimana (uno dei motivi per cui mi piace OPTION (RECOMPILE) come soluzione ai pervasivi problemi di sniffing dei parametri).
Detto questo, ti incoraggio vivamente a testare questi approcci rispetto a risultati simili che puoi ottenere dall'approccio GROUP_CONCAT CLR su CodePlex, oltre a eseguire l'aggregazione e l'ordinamento a livello di presentazione (in particolare se stai mantenendo i dati normalizzati in qualche modo del livello di memorizzazione nella cache).