Quando gli utenti richiedono dati da un sistema, di solito gli piace vederli in un ordine specifico... anche quando restituiscono migliaia di righe. Come molti DBA e sviluppatori sanno, ORDER BY può introdurre scompiglio in un piano di query, perché richiede l'ordinamento dei dati. Questo a volte può richiedere un operatore SORT come parte dell'esecuzione della query, che può essere un'operazione costosa, in particolare se le stime non sono corrette e si riversa su disco. In un mondo ideale, i dati sono già ordinati grazie a un indice (indici e ordinamenti sono molto complementari). Si parla spesso di creare un indice di copertura per soddisfare una query, in modo che l'ottimizzatore non debba tornare alla tabella di base o all'indice cluster per ottenere colonne aggiuntive. E potresti aver sentito dire che l'ordine delle colonne nell'indice è importante. Hai mai pensato a come influisce sulle tue operazioni SORT?
Esaminare ORDINE PER e Ordina
Inizieremo con una nuova copia del database AdventureWorks2014 su un'istanza di SQL Server 2014 (versione 12.0.2000). Se eseguiamo una semplice query SELECT su Sales.SalesOrderHeader senza ORDER BY, vediamo una normale scansione dell'indice cluster (usando SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Query senza ORDER BY, scansione dell'indice cluster
Query senza ORDER BY, scansione dell'indice cluster
Ora aggiungiamo un ORDER BY per vedere come cambia il piano:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
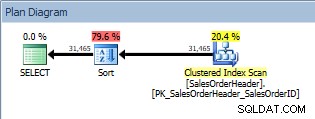 Query con ORDER BY, scansione dell'indice cluster e ordinamento
Query con ORDER BY, scansione dell'indice cluster e ordinamento
Oltre alla scansione dell'indice cluster, ora abbiamo un ordinamento introdotto dall'ottimizzatore e il suo costo stimato è significativamente superiore a quello della scansione. Ora, il costo stimato è solo stimato e non possiamo affermare con assoluta certezza che l'ordinamento ha richiesto il 79,6% del costo della query. Per capire davvero quanto sia costoso l'ordinamento, dovremmo guardare anche IO STATISTICS, che va oltre l'obiettivo odierno.
Ora, se questa fosse una query eseguita frequentemente nel tuo ambiente, probabilmente prenderesti in considerazione l'aggiunta di un indice per supportarla. In questo caso, non esiste una clausola WHERE, stiamo solo recuperando quattro colonne e ordinando in base a una di esse. Un primo tentativo logico di un indice sarebbe:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Eseguiremo nuovamente la nostra query dopo aver aggiunto l'indice che ha tutte le colonne desiderate e ricordiamo che l'indice ha svolto il lavoro per ordinare i dati. Ora vediamo una scansione dell'indice rispetto al nostro nuovo indice non cluster:
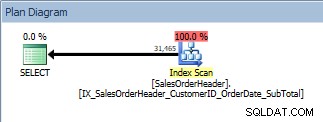 Query con ORDER BY, viene scansionato il nuovo indice non cluster
Query con ORDER BY, viene scansionato il nuovo indice non cluster
Questa è una buona notizia. Ma cosa succede se qualcuno modifica quella query, sia perché gli utenti possono specificare per quali colonne vogliono ordinare, sia perché è stata richiesta una modifica a uno sviluppatore? Ad esempio, forse gli utenti vogliono vedere CustomerIDs e SalesOrderIDs in ordine decrescente:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
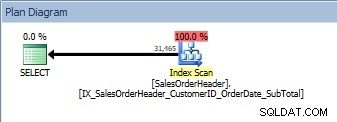 Query con due colonne in ORDER BY, viene scansionato il nuovo indice non cluster
Query con due colonne in ORDER BY, viene scansionato il nuovo indice non cluster
Abbiamo lo stesso piano; nessun operatore di ordinamento è stato aggiunto. Se osserviamo l'indice utilizzando sp_helpindex di Kimberly Tripp (alcune colonne sono state compresse per risparmiare spazio), possiamo vedere perché il piano non è cambiato:
 Output di sp_helpindex
Output di sp_helpindex
La colonna chiave per l'indice è CustomerID, ma poiché SalesOrderID è la colonna chiave per l'indice cluster, fa anche parte della chiave dell'indice, quindi i dati vengono ordinati per CustomerID, quindi SalesOrderID. La query ha richiesto i dati ordinati in base a queste due colonne, in ordine decrescente. L'indice è stato creato con entrambe le colonne ascendenti, ma poiché è un elenco a doppio collegamento, l'indice può essere letto all'indietro. Puoi vederlo nel riquadro Proprietà in Management Studio per l'operatore di scansione dell'indice non cluster:
 Riquadro delle proprietà della scansione dell'indice non cluster, che mostra che era all'indietro
Riquadro delle proprietà della scansione dell'indice non cluster, che mostra che era all'indietro
Ottimo, nessun problema con quella query... ma che dire di questa:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
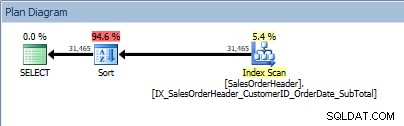 Query con due colonne in ORDER BY e viene aggiunto un ordinamento
Query con due colonne in ORDER BY e viene aggiunto un ordinamento
Ricompare il nostro operatore SORT, perché i dati provenienti dall'indice non sono ordinati nell'ordine richiesto. Vedremo lo stesso comportamento se ordiniamo su una delle colonne incluse:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
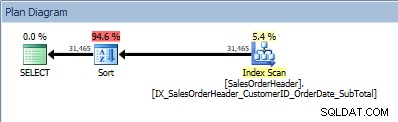 Query con due colonne in ORDER BY e viene aggiunto un ordinamento
Query con due colonne in ORDER BY e viene aggiunto un ordinamento
Cosa succede se aggiungiamo (finalmente) un predicato e cambiamo leggermente il nostro ORDER BY?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
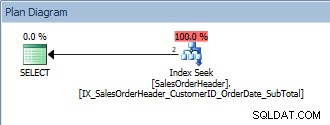 Query con un singolo predicato e un ORDER BY
Query con un singolo predicato e un ORDER BY
Questa query va bene perché, ancora una volta, SalesOrderID fa parte della chiave dell'indice. Per questo CustomerID, i dati sono già ordinati da SalesOrderID. Cosa succede se eseguiamo una query per un intervallo di CustomerID, ordinati per SalesOrderID?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
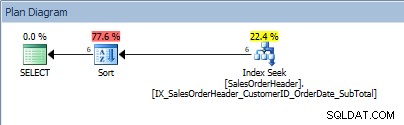 Query con un intervallo di valori nel predicato e un ORDER BY
Query con un intervallo di valori nel predicato e un ORDER BY
Ratti, il nostro SORT è tornato. Il fatto che i dati siano ordinati per CustomerID aiuta solo a cercare l'indice per trovare quell'intervallo di valori; per ORDER BY SalesOrderID, l'ottimizzatore deve interporre Sort per inserire i dati nell'ordine richiesto.
A questo punto, potresti chiederti perché sono fissato sull'operatore di ordinamento che appare nei piani di query. È perché è costoso. Può essere costoso in termini di risorse (memoria, IO) e/o durata.
La durata della query può essere influenzata da un ordinamento perché è un'operazione stop-and-go. L'intero set di dati deve essere ordinato prima che possa verificarsi l'operazione successiva nel piano. Se devono essere ordinate solo poche righe di dati, non è un grosso problema. Se sono migliaia o milioni di righe? Ora stiamo aspettando.
Oltre alla durata complessiva della query, dobbiamo anche pensare all'uso delle risorse. Prendiamo le 31.465 righe con cui abbiamo lavorato e le inseriamo in una variabile di tabella, quindi eseguiamo la query iniziale con ORDER BY su CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
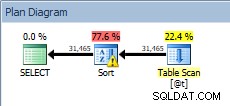 Query sulla variabile della tabella, con l'ordinamento
Query sulla variabile della tabella, con l'ordinamento
Il nostro SORT è tornato, e questa volta ha un avviso (notare il triangolo giallo con il punto esclamativo). Gli avvisi non vanno bene. Se osserviamo le proprietà dell'ordinamento, possiamo vedere l'avviso "L'operatore ha utilizzato tempdb per trasferire i dati durante l'esecuzione con livello di spill 1":
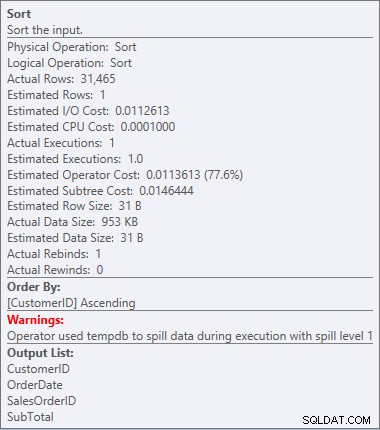 Avviso di ordinamento
Avviso di ordinamento
Questo non è qualcosa che voglio vedere in un piano. L'ottimizzatore ha effettuato una stima della quantità di spazio necessaria in memoria per ordinare i dati e ha richiesto tale memoria. Ma quando ha effettivamente avuto tutti i dati ed è andato a ordinarli, il motore si è reso conto che non c'era abbastanza memoria (l'ottimizzatore ha richiesto troppo poca!), quindi l'operazione di ordinamento è andata a vuoto. In alcuni casi, questo può riversarsi su disco, il che significa letture e scritture, che sono lente. Non solo stiamo aspettando solo di mettere in ordine i dati, ma è anche più lento perché non possiamo fare tutto in memoria. Perché l'ottimizzatore non ha richiesto memoria sufficiente? Aveva una cattiva stima dei dati necessari per ordinare:
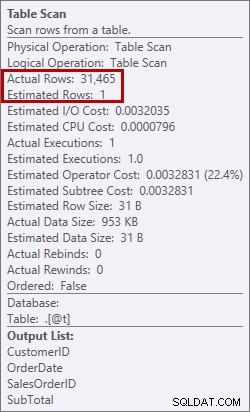 Stima di 1 riga rispetto a 31.465 righe effettive
Stima di 1 riga rispetto a 31.465 righe effettive
In questo caso ho forzato una stima errata utilizzando una variabile di tabella. Sono noti problemi con le stime statistiche e le variabili di tabella (Aaron Bertrand ha un ottimo post sulle opzioni per provare a risolvere questo problema) e qui, l'ottimizzatore credeva che sarebbe stata restituita solo 1 riga dalla scansione della tabella, non 31.465.
Opzioni
Quindi cosa puoi fare tu, come DBA o sviluppatore, per evitare SORT nei tuoi piani di query? La risposta rapida è:"Non ordinare i tuoi dati". Ma non è sempre realistico. In alcuni casi, puoi scaricare l'ordinamento sul client o su un livello dell'applicazione, ma gli utenti devono comunque attendere per ordinare i dati in quello strato. Nelle situazioni in cui non puoi modificare il funzionamento dell'applicazione, puoi iniziare guardando i tuoi indici.
Se si supporta un'applicazione che consente agli utenti di eseguire query ad hoc o di modificare l'ordinamento in modo che possano vedere i dati ordinati come vogliono... sarà il momento più difficile (ma non è una causa persa, quindi non smettere di leggere ancora!). Non puoi indicizzare per ogni opzione. È inefficiente e creerai più problemi di quanti ne risolvi. La soluzione migliore qui è parlare con gli utenti (lo so, a volte è spaventoso lasciare il tuo angolo di bosco, ma provalo). Per le query che gli utenti eseguono più spesso, scopri come in genere gli piace vedere i dati. Sì, puoi ottenerlo anche dalla cache dei piani:puoi recuperare query e piani fino al contenuto del tuo cuore per vedere cosa stanno facendo. Ma è più veloce parlare con gli utenti. Il vantaggio aggiuntivo è che puoi spiegare perché lo stai chiedendo e perché l'idea di "ordinare su tutte le colonne perché posso" non è così buona. Conoscere è metà della battaglia. Se puoi dedicare un po' di tempo a educare i tuoi utenti esperti e gli utenti che formano nuove persone, potresti essere in grado di fare del bene.
Se supporti un'applicazione con opzioni ORDER BY limitate, puoi fare delle analisi reali. Esamina quali variazioni ORDER BY esistono, determina quali combinazioni vengono eseguite più spesso e indicizza per supportare tali query. Probabilmente non colpirai tutti, ma puoi comunque avere un impatto. Puoi fare un ulteriore passo avanti parlando con i tuoi sviluppatori ed educandoli sul problema e su come affrontarlo.
Infine, quando guardi i piani di query con le operazioni SORT, non concentrarti solo sulla rimozione dell'ordinamento. Guarda dove l'ordinamento si verifica nel piano. Se accade molto a sinistra del piano, ed è tipicamente poche righe, potrebbero esserci altre aree con un fattore di miglioramento maggiore su cui concentrarsi. L'ordinamento a sinistra è lo schema su cui ci siamo concentrati oggi, ma un ordinamento non si verifica sempre a causa di un ORDINE PER. Se vedi un ordinamento all'estrema destra del piano e ci sono molte righe che si spostano in quella parte del piano, sai di aver trovato un buon punto per iniziare l'ottimizzazione.



