L'aggiunta di un indice filtrato può avere effetti collaterali sorprendenti sulle query esistenti, anche quando sembra che il nuovo indice filtrato non sia completamente correlato. Questo post esamina un esempio che interessa le istruzioni DELETE che si traducono in prestazioni scadenti e un aumento del rischio di deadlock.
Ambiente di prova
La seguente tabella verrà utilizzata in questo post:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Questa istruzione successiva crea 499.999 righe di dati di esempio:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; Ciò utilizza una tabella di numeri come fonte di numeri interi consecutivi da 1 a 499.999. Nel caso in cui non ne disponga uno nell'ambiente di test, è possibile utilizzare il codice seguente per crearne uno contenente numeri interi da 1 a 1.000.000:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); La base dei test successivi consisterà nell'eliminare righe dalla tabella di test per un particolare StartDate. Per rendere più efficiente il processo di identificazione delle righe da eliminare, aggiungi questo indice non cluster:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); I dati di esempio
Una volta completati questi passaggi, l'esempio sarà simile al seguente:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
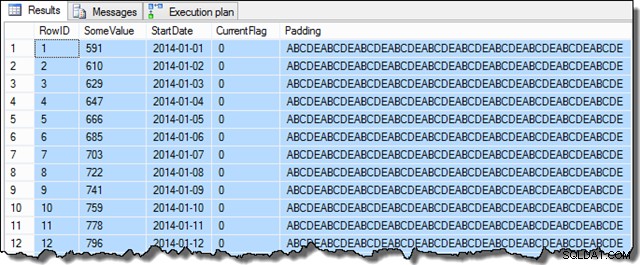
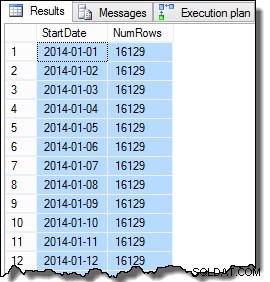
I dati della colonna SomeValue potrebbero essere leggermente diversi a causa della generazione pseudo-casuale, ma questa differenza non è importante. Complessivamente, i dati di esempio contengono 16.129 righe per ciascuna delle 31 date di StartDate di gennaio 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
L'ultimo passaggio che dobbiamo eseguire per rendere i dati alquanto realistici è impostare la colonna CurrentFlag su true per il RowID più alto per ogni StartDate. Il seguente script esegue questa attività:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; Il piano di esecuzione di questo aggiornamento prevede una combinazione Segment-Top per individuare in modo efficiente il RowID più alto al giorno:

Nota come il piano di esecuzione somiglia poco alla forma scritta della query. Questo è un ottimo esempio di come funziona l'ottimizzatore dalla specifica SQL logica, anziché implementare direttamente l'SQL. Nel caso ve lo stiate chiedendo, per la protezione di Halloween è richiesta la bobina da tavolo Eager in quel piano.
Eliminazione di un giorno di dati
Ok, quindi con i preliminari completati, l'attività a portata di mano è eliminare le righe per un particolare StartDate. Questo è il tipo di query che potresti eseguire di routine nella prima data in una tabella, in cui i dati hanno raggiunto la fine della loro vita utile.
Prendendo come esempio il 1° gennaio 2014, la query di eliminazione del test è semplice:
DELETE dbo.Data WHERE StartDate = '20140101';
Anche il piano di esecuzione è piuttosto semplice, anche se vale la pena guardare un po' in dettaglio:

Analisi del piano
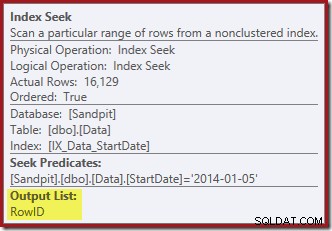
La ricerca dell'indice all'estrema destra usa l'indice non cluster per trovare le righe per il valore StartDate specificato. Restituisce solo i valori RowID che trova, come conferma il suggerimento dell'operatore:
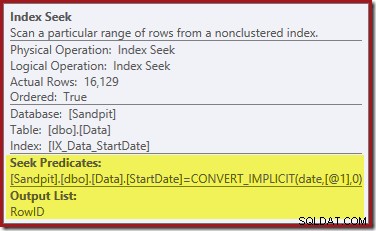
Se ti stai chiedendo come l'indice StartDate riesca a restituire il RowID, ricorda che RowID è l'indice cluster univoco per la tabella, quindi viene automaticamente incluso nell'indice non cluster StartDate.
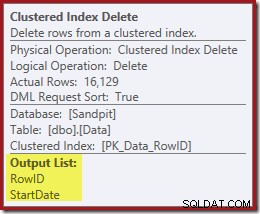
L'operatore successivo nel piano è l'eliminazione dell'indice cluster. Questo utilizza il valore RowID trovato da Index Seek per individuare le righe da rimuovere.
L'operatore finale nel piano è un'eliminazione dell'indice. Questo rimuove le righe dall'indice non cluster IX_Data_StartDate correlati al RowID rimosso dall'eliminazione dell'indice cluster. Per individuare queste righe nell'indice non cluster, il Query Processor necessita di StartDate (la chiave per l'indice non cluster).
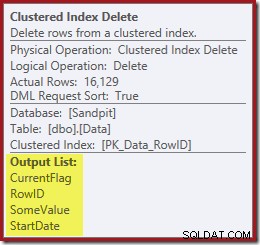
Ricorda che la ricerca dell'indice originale non ha restituito la data di inizio, ma solo il RowID. Quindi, come fa il Query Processor a ottenere StartDate per l'eliminazione dell'indice? In questo caso particolare, l'ottimizzatore potrebbe aver notato che il valore StartDate è una costante e l'ha ottimizzato, ma non è quello che è successo. La risposta è che l'operatore Clustered Index Delete legge il valore StartDate per la riga corrente e lo aggiunge al flusso. Confronta l'elenco di output dell'eliminazione dell'indice raggruppato mostrato di seguito, con quello della ricerca dell'indice appena sopra:
Potrebbe sembrare sorprendente vedere un operatore Elimina leggere i dati, ma questo è il modo in cui funziona. Il Query Processor sa che dovrà individuare la riga nell'indice cluster per eliminarlo, quindi potrebbe anche rinviare la lettura delle colonne necessarie per mantenere gli indici non cluster fino a quel momento, se possibile.
Aggiunta di un indice filtrato
Ora immagina che qualcuno abbia una query cruciale su questa tabella che sta funzionando male. L'utile DBA esegue un'analisi e aggiunge il seguente indice filtrato:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; Il nuovo indice filtrato ha l'effetto desiderato sulla query problematica e tutti sono contenti. Nota che il nuovo indice non fa affatto riferimento alla colonna StartDate, quindi non ci aspettiamo che influisca affatto sulla nostra query di eliminazione giornaliera.
Eliminazione di un giorno con l'indice filtrato attivo
Possiamo testare questa aspettativa cancellando i dati una seconda volta:
DELETE dbo.Data WHERE StartDate = '20140102';
Improvvisamente, il piano di esecuzione è passato a una scansione dell'indice cluster parallela:

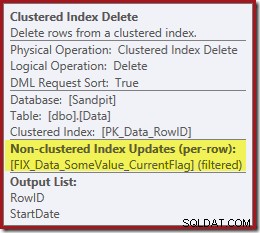
Si noti che non esiste un operatore di eliminazione dell'indice separato per il nuovo indice filtrato. L'ottimizzatore ha scelto di mantenere questo indice all'interno dell'operatore Clustered Index Delete. Questo è evidenziato in SQL Sentry Plan Explorer come mostrato sopra ("+1 indici non cluster") con tutti i dettagli nella descrizione comando:
Se la tabella è grande (si pensi al data warehouse), questa modifica a una scansione parallela potrebbe essere molto significativa. Che cosa è successo al simpatico Index Seek su StartDate e perché un indice filtrato completamente non correlato ha cambiato le cose in modo così drammatico?
Trovare il problema
Il primo indizio viene dall'esame delle proprietà della scansione dell'indice cluster:
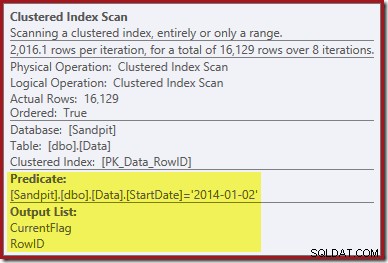
Oltre a trovare i valori RowID per l'eliminazione dell'operatore Clustered Index Delete, questo operatore ora legge i valori CurrentFlag. La necessità di questa colonna non è chiara, ma almeno inizia a spiegare la decisione di eseguire la scansione:la colonna CurrentFlag non fa parte del nostro indice non cluster StartDate.
Possiamo confermarlo riscrivendo la query di eliminazione per forzare l'uso dell'indice non cluster StartDate:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Il piano di esecuzione è più vicino alla sua forma originale, ma ora include una ricerca chiave:
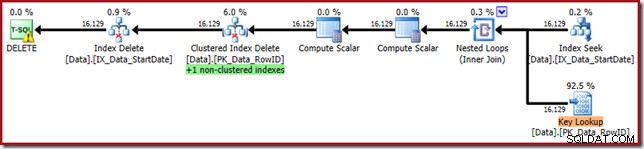
Le proprietà Key Lookup confermano che questo operatore sta recuperando i valori CurrentFlag:
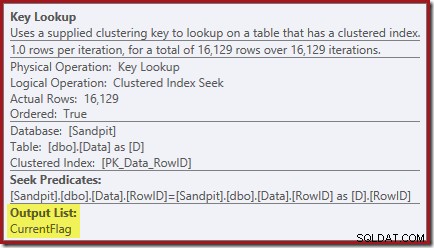
Potresti anche aver notato i triangoli di avvertimento negli ultimi due piani. Questi sono avvisi di indice mancanti:
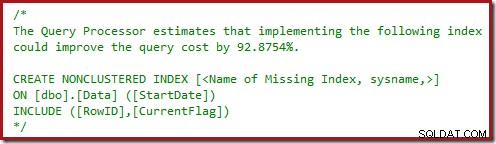
Questa è un'ulteriore conferma che SQL Server vorrebbe vedere la colonna CurrentFlag inclusa nell'indice non cluster. Il motivo del passaggio a una scansione dell'indice cluster parallela è ora chiaro:il Query Processor decide che la scansione della tabella sarà più economica rispetto all'esecuzione delle ricerche chiave.
Sì, ma perché?
Tutto questo è molto strano. Nel piano di esecuzione originale, SQL Server era in grado di leggere dati di colonna aggiuntivi necessari per mantenere gli indici non cluster nell'operatore Clustered Index Delete. Il valore della colonna CurrentFlag è necessario per mantenere l'indice filtrato, quindi perché SQL Server non lo gestisce semplicemente allo stesso modo?
La risposta breve è che può, ma solo se l'indice filtrato viene mantenuto in un operatore di eliminazione dell'indice separato. Possiamo forzarlo per la query corrente utilizzando il flag di traccia non documentato 8790. Senza questo flag, l'ottimizzatore sceglie se mantenere ogni indice in un operatore separato o come parte dell'operazione della tabella di base.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Il piano di esecuzione è tornato alla ricerca dell'indice non cluster StartDate:
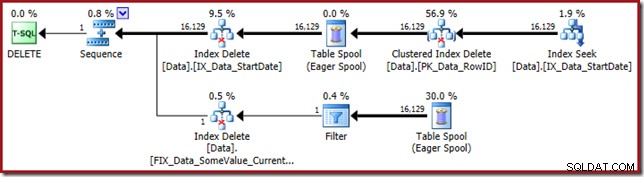
La ricerca dell'indice restituisce solo i valori RowID (senza CurrentFlag):
E l'eliminazione dell'indice cluster legge le colonne necessarie per mantenere gli indici non cluster, incluso CurrentFlag:
Questi dati vengono scritti avidamente in uno spool di tabella, che viene riprodotto per ogni indice che deve essere mantenuto. Notare anche l'operatore Filter esplicito prima dell'operatore Index Delete per l'indice filtrato.
Un altro schema a cui prestare attenzione
Questo problema non comporta sempre un'analisi della tabella anziché una ricerca di indice. Per vedere un esempio di ciò, aggiungi un altro indice alla tabella di test:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Tieni presente che questo indice non filtrato e non coinvolge la colonna StartDate. Ora prova di nuovo una query di eliminazione del giorno:
DELETE dbo.Data WHERE StartDate = '20140104';
L'ottimizzatore ora presenta questo mostro:
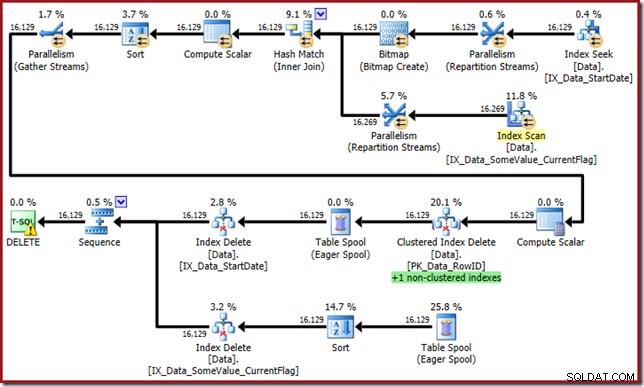
Questo piano di query ha un elevato fattore di sorpresa, ma la causa principale è la stessa. La colonna CurrentFlag è ancora necessaria, ma ora l'ottimizzatore sceglie una strategia di intersezione dell'indice per ottenerla invece di una scansione della tabella. L'uso del flag di traccia forza un piano di manutenzione per indice e la sanità mentale viene nuovamente ripristinata (l'unica differenza è una ripetizione dello spooling extra per mantenere il nuovo indice):
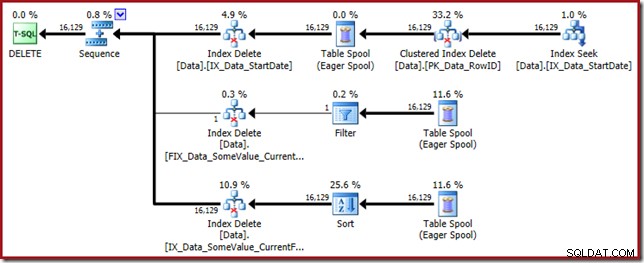
Solo gli indici filtrati causano questo
Questo problema si verifica solo se l'ottimizzatore sceglie di mantenere un indice filtrato in un operatore di eliminazione indice cluster. Gli indici non filtrati non sono interessati, come mostra l'esempio seguente. Il primo passaggio consiste nell'eliminare l'indice filtrato:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Ora è necessario scrivere la query in un modo che convinca l'ottimizzatore a mantenere tutti gli indici nell'eliminazione dell'indice cluster. La mia scelta per questo è utilizzare una variabile e un suggerimento per ridurre le aspettative di conteggio delle righe dell'ottimizzatore:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Il piano di esecuzione è:
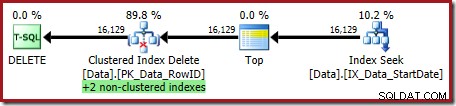
Entrambi gli indici non cluster vengono gestiti da Clustered Index Delete:
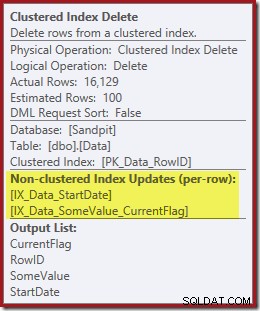
La ricerca dell'indice restituisce solo il RowID:
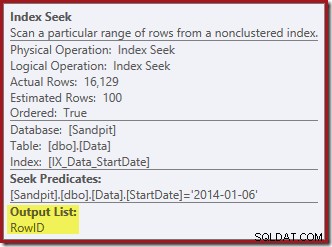
Le colonne necessarie per la manutenzione dell'indice vengono recuperate internamente dall'operatore di cancellazione; questi dettagli non sono esposti nell'output del piano di visualizzazione (quindi l'elenco di output dell'operatore di eliminazione sarebbe vuoto). Ho aggiunto un OUTPUT clausola alla query per mostrare ancora una volta l'eliminazione dell'indice cluster restituendo i dati che non ha ricevuto sul suo input:
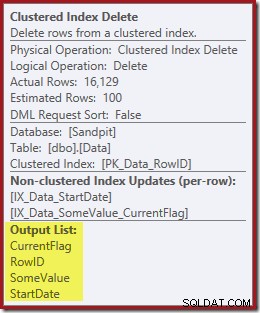
Pensieri finali
Questa è una limitazione difficile da aggirare. Da un lato, generalmente non vogliamo utilizzare flag di traccia non documentati nei sistemi di produzione.
La "correzione" naturale consiste nell'aggiungere le colonne necessarie per la manutenzione dell'indice filtrato a tutti indici non cluster che potrebbero essere utilizzati per individuare le righe da eliminare. Questa non è una proposta molto allettante, da diversi punti di vista. Un'altra alternativa è semplicemente non utilizzare affatto gli indici filtrati, ma non è nemmeno l'ideale.
La mia sensazione è che l'ottimizzatore di query dovrebbe considerare automaticamente un'alternativa di manutenzione per indice per gli indici filtrati, ma il suo ragionamento sembra essere incompleto in quest'area in questo momento (e basato su semplici euristiche piuttosto che sul costo corretto per indice/riga alternative).
Per mettere alcuni numeri attorno a questa affermazione, il piano di scansione dell'indice in cluster parallelo scelto dall'ottimizzatore è arrivato a 5.5 unità nei miei test. La stessa query con il flag di traccia stima un costo di 1,4 unità. Con il terzo indice in atto, il piano di intersezione indice parallelo scelto dall'ottimizzatore aveva un costo stimato di 4,9 , mentre il piano di tracciabilità è arrivato a 2,7 unità (tutti i test su SQL Server 2014 RTM CU1 build 12.0.2342 con il modello di stima della cardinalità 120 e con flag di traccia 4199 abilitato).
Considero questo un comportamento che dovrebbe essere migliorato. Puoi votare per essere d'accordo o non essere d'accordo con me su questo elemento Connect.