L'esigenza più comune per estrarre il tempo da un valore datetime è ottenere tutte le righe che rappresentano gli ordini (o le visite o gli incidenti) avvenuti in un determinato giorno. Tuttavia, non tutte le tecniche utilizzate per farlo sono efficienti o addirittura sicure.
TL;versione DR
Se desideri una query con intervallo sicuro che funzioni bene, utilizza un intervallo aperto oppure, per query di un giorno su SQL Server 2008 e versioni successive, usa CONVERT(DATE) :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Alcuni avvertimenti:
- Fai attenzione con il
DATEDIFFapproccio, poiché possono verificarsi alcune anomalie nella stima della cardinalità (per ulteriori informazioni, vedere questo post del blog e la domanda Stack Overflow che l'ha stimolata). - Anche se l'ultimo utilizzerà ancora potenzialmente una ricerca dell'indice (a differenza di ogni altra espressione non sargable che abbia mai incontrato), devi fare attenzione a convertire la colonna in una data prima di confrontare. Anche questo approccio può produrre stime di cardinalità fondamentalmente errate. Vedi questa risposta di Martin Smith per maggiori dettagli.
In ogni caso, continua a leggere per capire perché questi sono gli unici due approcci che io abbia mai raccomandato.
Non tutti gli approcci sono sicuri
Come esempio non sicuro, vedo questo usato molto:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Ci sono alcuni problemi con questo approccio, ma il più notevole è il calcolo della "fine" di oggi, se il tipo di dati sottostante è SMALLDATETIME , quell'intervallo finale verrà arrotondato per eccesso; se è DATETIME2 , potresti teoricamente perdere i dati alla fine della giornata. Se scegli minuti o nanosecondi o qualsiasi altro spazio vuoto per soddisfare il tipo di dati corrente, la tua query inizierà ad avere un comportamento strano se il tipo di dati dovesse cambiare in seguito (e siamo onesti, se qualcuno cambia il tipo di quella colonna in modo che sia più o meno granulare, non vanno in giro controllando ogni singola query che vi accede). Dover codificare in questo modo a seconda del tipo di dati di data/ora nella colonna sottostante è frammentato e soggetto a errori. È molto meglio utilizzare intervalli di date aperti per questo:
Ne parlo molto di più in un paio di vecchi post del blog:
- Cos'hanno in comune BETWEEN e il diavolo?
- Cattive abitudini da eliminare:gestione errata delle query su date/intervallo
Ma volevo confrontare le prestazioni di alcuni degli approcci più comuni che vedo là fuori. Ho sempre utilizzato intervalli illimitati e da SQL Server 2008 siamo stati in grado di utilizzare CONVERT(DATE) e utilizza ancora un indice su quella colonna, che è abbastanza potente.
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Un semplice test delle prestazioni
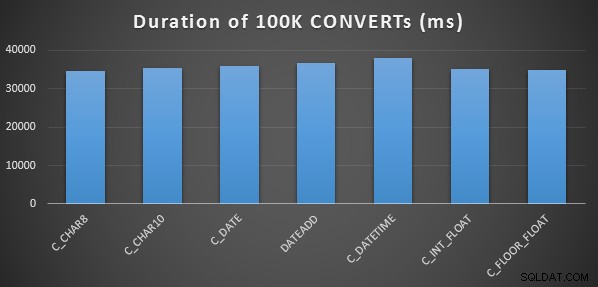
Per eseguire un test delle prestazioni iniziale molto semplice, ho eseguito quanto segue per ciascuna delle affermazioni precedenti, impostando una variabile sull'output del calcolo 100.000 volte:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
L'ho fatto tre volte per ogni metodo e tutti hanno funzionato nell'intervallo di 34-38 secondi. Quindi, a rigor di termini, ci sono differenze molto trascurabili in questi metodi quando si eseguono le operazioni in memoria:
Un test delle prestazioni più elaborato
Volevo anche confrontare questi metodi con diversi tipi di dati (DATETIME , SMALLDATETIME e DATETIME2 ), sia rispetto a un indice cluster che a un heap e con e senza compressione dei dati. Quindi prima ho creato un semplice database. Attraverso la sperimentazione ho determinato che la dimensione ottimale per gestire 120 milioni di righe e tutta l'attività di registro che potrebbe verificarsi (e per evitare che gli eventi di crescita automatica interferiscano con il test) fosse un file di dati da 20 GB e un registro da 3 GB:
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
Successivamente, ho creato 12 tabelle:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Quindi ripetere di nuovo per DATETIME e DATETIME2.]
Successivamente, ho inserito 10.000.000 di righe in ciascuna tabella. L'ho fatto creando una vista che generasse ogni volta le stesse 10.000.000 di date:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
Questo mi ha permesso di popolare le tabelle in questo modo:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Quindi ripetere di nuovo per gli heap e l'indice cluster non compresso. Ho inserito un CHECKPOINT tra ogni inserto per garantire il riutilizzo dei log (il modello di ripristino è semplice).]
INSERIRE Tempi e spazio utilizzato
Ecco i tempi per ogni inserto (come catturato con Plan Explorer):
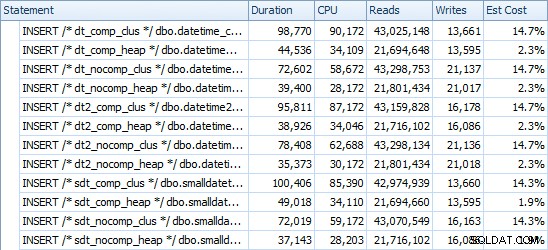
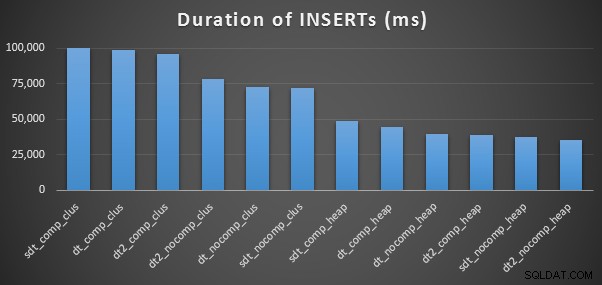
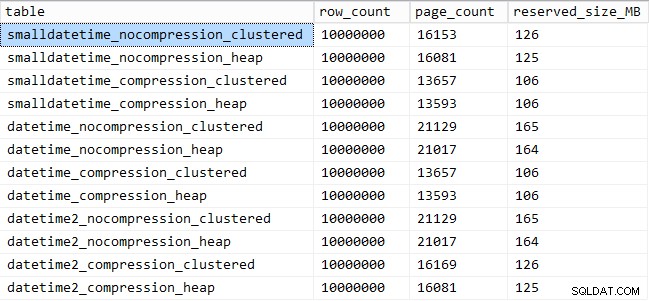
Ed ecco la quantità di spazio occupato da ogni tavolo:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
Rendimento del modello di query
Successivamente ho deciso di testare due diversi modelli di query per le prestazioni:
- Conteggio delle righe per un giorno specifico, utilizzando i sette approcci sopra indicati, nonché l'intervallo di date a tempo indeterminato
- Conversione di tutte le 10.000.000 di righe utilizzando i sette approcci precedenti, oltre a restituire semplicemente i dati grezzi (poiché la formattazione sul lato client potrebbe essere migliore)
[Ad eccezione di FLOAT metodi e il DATETIME2 colonna, poiché questa conversione non è legale.]
Per la prima domanda, le query si presentano così (ripetute per ogni tipo di tabella):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; I risultati rispetto a un indice raggruppato hanno il seguente aspetto (fai clic per ingrandire):
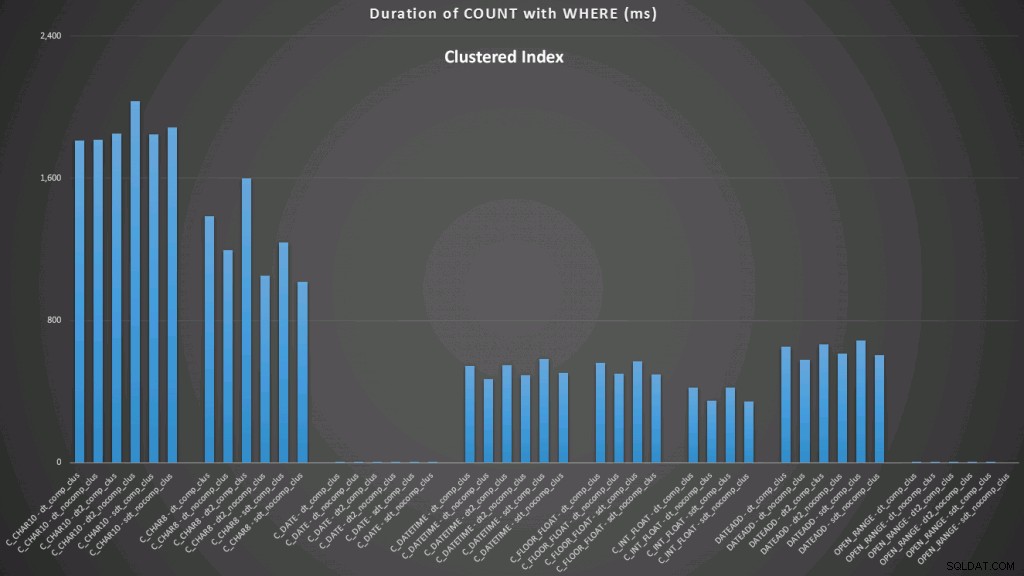
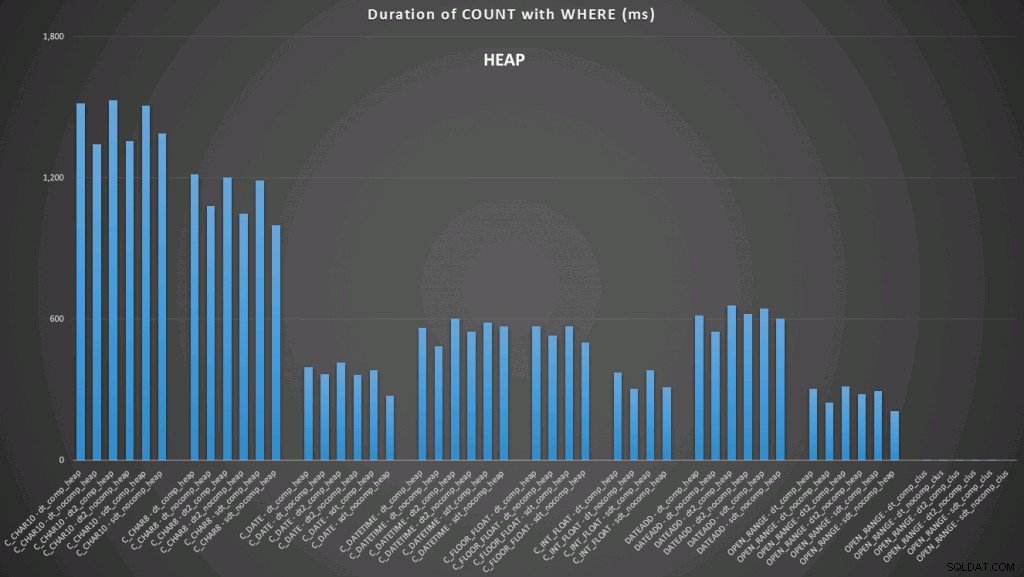
Qui vediamo che il convertito a data e l'intervallo aperto che utilizza un indice sono i migliori risultati. Tuttavia, a fronte di un heap, la conversione in data richiede effettivamente del tempo, rendendo l'intervallo aperto la scelta ottimale (fai clic per ingrandire):
Ed ecco la seconda serie di query (di nuovo, ripetute per ogni tipo di tabella):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; Concentrandosi sui risultati per le tabelle con un indice cluster, è chiaro che la conversione ad oggi è stata molto vicina alla selezione dei dati grezzi (clicca per ingrandire):
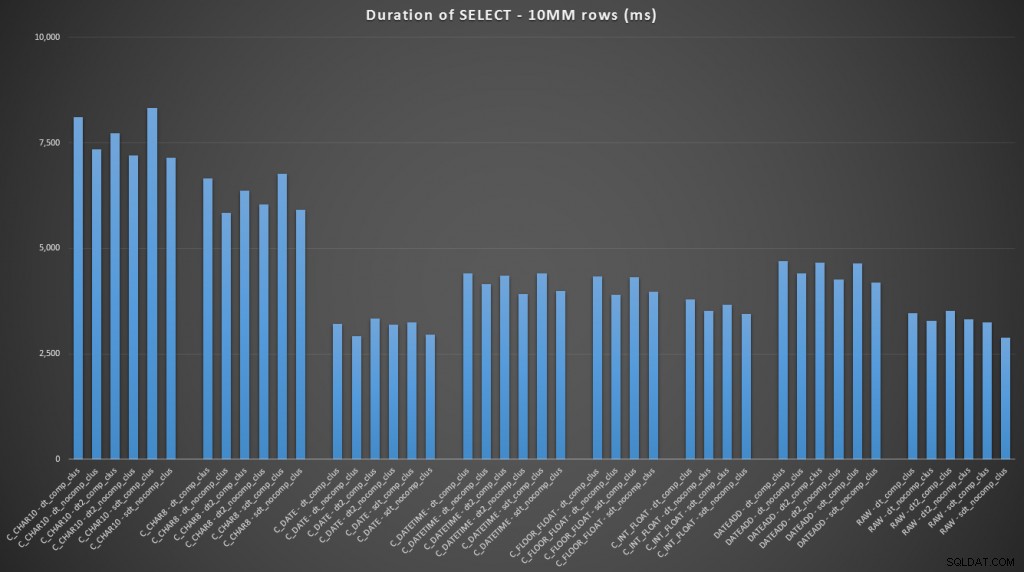
(Per questo insieme di query, l'heap ha mostrato risultati molto simili, praticamente indistinguibili.)
Conclusione
Nel caso tu volessi passare alla battuta finale, questi risultati mostrano che le conversioni in memoria non sono importanti, ma se stai convertendo i dati mentre esci da una tabella (o come parte di un predicato di ricerca), il metodo che scegli può avere un impatto drammatico sulle prestazioni. Conversione in DATE (per un solo giorno) o l'utilizzo di un intervallo di date aperto in ogni caso produrrà le migliori prestazioni, mentre il metodo più popolare in circolazione, la conversione in una stringa, è assolutamente pessimo.
Vediamo anche che la compressione può avere un effetto decente sullo spazio di archiviazione, con un impatto molto minore sulle prestazioni delle query. L'effetto sulle prestazioni di inserimento sembra dipendere dal fatto che la tabella disponga o meno di un indice cluster piuttosto che dal fatto che la compressione sia abilitata o meno. Tuttavia, con un indice cluster in atto, si è verificato un notevole aumento della durata necessaria per inserire 10 milioni di righe. Qualcosa da tenere a mente e da bilanciare con il risparmio di spazio su disco.
Chiaramente potrebbero essere coinvolti molti più test, con carichi di lavoro più sostanziali e vari, che potrei approfondire in un prossimo post.