Durante l'esecuzione di una query, l'ottimizzatore di SQL Server tenta di trovare il miglior piano di query in base agli indici esistenti e alle statistiche più recenti disponibili per un periodo di tempo ragionevole, ovviamente, se questo piano non è già archiviato nella cache del server. In caso negativo, la query viene eseguita in base a questo piano e il piano viene archiviato nella cache del server. Se il piano è già stato creato per questa query, la query viene eseguita in base al piano esistente.
Siamo interessati al seguente problema:
Durante la compilazione di un piano di query, durante l'ordinamento di possibili indici, se il server non trova l'indice migliore, l'indice mancante viene contrassegnato nel piano di query e il server conserva le statistiche su tali indici:quante volte il server utilizzerebbe questo indice e quanto costerebbe questa query.
In questo articolo, analizzeremo questi indici mancanti:come gestirli.
Consideriamo questo su un esempio particolare. Crea un paio di tabelle nel nostro database su un server locale e di prova:
[espandi titolo =”Codice”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/espandi]
La struttura è semplice ed è composta da due tavoli. La prima tabella è chiamata ordini con campi come identificatore, data di vendita e venditore. Il secondo sono i dettagli dell'ordine, in cui alcune merci sono specificate con prezzo e quantità.
Guarda una semplice query e il suo piano:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
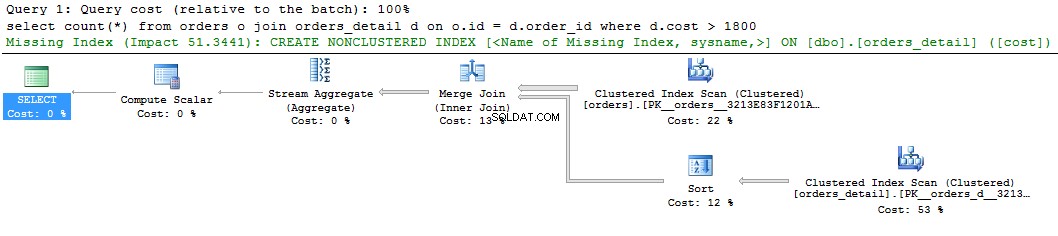
Possiamo vedere un suggerimento verde sull'indice mancante sul display grafico del piano di query. Se fai clic con il pulsante destro del mouse e selezioni "Dettagli indice mancanti ..", ci sarà il testo dell'indice suggerito. L'unica cosa da fare è rimuovere i commenti nel testo e dare un nome all'indice. Lo script è pronto per essere eseguito.
Non costruiremo l'indice che abbiamo ricevuto dal suggerimento fornito da SSMS. Vedremo invece se questo indice sarà consigliato da viste dinamiche collegate a indici mancanti. Le visualizzazioni sono le seguenti:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
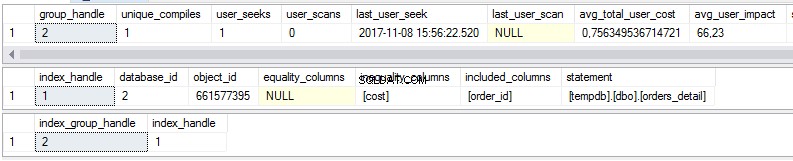
Come possiamo vedere, ci sono alcune statistiche sugli indici mancanti nella prima vista:
- Quante volte verrebbe eseguita una ricerca se esistesse l'indice suggerito?
- Quante volte verrebbe eseguita una scansione se esistesse l'indice suggerito?
- Ultima data e ora in cui abbiamo utilizzato l'indice
- Il costo reale attuale del piano di query senza l'indice suggerito.
La seconda vista è il corpo dell'indice:
- Banca dati
- Oggetto/tabella
- Colonne ordinate
- Colonne aggiunte per aumentare la copertura dell'indice
La terza vista è la combinazione della prima e della seconda vista.
Di conseguenza, non è difficile ottenere uno script che generi uno script per creare indici mancanti da queste viste dinamiche. Lo script è il seguente:
[expand title=”Codice”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/espandi]
Per l'efficienza dell'indice, vengono emessi gli indici mancanti. La soluzione perfetta è quando questo set di risultati non restituisce nulla. Nel nostro esempio, il set di risultati restituirà almeno un indice:

Quando non c'è tempo e non hai voglia di affrontare i bug del client, ho eseguito la query, copiato la prima colonna e l'ho eseguita sul server. Dopo questo, tutto ha funzionato bene.
Raccomando di trattare consapevolmente le informazioni su questi indici. Ad esempio, se il sistema consiglia i seguenti indici:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
E questi indici sono usati per la ricerca, è abbastanza ovvio che è più logico sostituire questi indici con uno che copra tutti e tre suggeriti:
create index ix_1 on tbl1 (a,b) include (c,d)
Pertanto, esaminiamo gli indici mancanti prima di distribuirli al server di produzione. Sebbene…. Ancora una volta, ad esempio, ho distribuito gli indici persi sul server TFS, aumentando così le prestazioni complessive. Ci è voluto un tempo minimo per eseguire questa ottimizzazione. Tuttavia, quando sono passato da TFS 2015 a TFS 2017, ho riscontrato il problema che non c'erano aggiornamenti a causa di questi nuovi indici. Tuttavia, possono essere facilmente trovati dalla maschera
select * from sys.indexes where name like 'ix[_]2017%'
Strumento utile:
dbForge Index Manager – pratico componente aggiuntivo SSMS per analizzare lo stato degli indici SQL e risolvere i problemi con la frammentazione degli indici.