È stato a lungo stabilito che le variabili di tabella con un numero elevato di righe possono essere problematiche, poiché l'ottimizzatore le vede sempre come aventi una riga. Senza una ricompilazione dopo che la variabile della tabella è stata popolata (poiché prima era vuota), non c'è cardinalità per la tabella e le ricompilazioni automatiche non si verificano perché le variabili della tabella non sono nemmeno soggette a una soglia di ricompilazione. I piani, quindi, si basano su una cardinalità della tabella di zero, non uno, ma il minimo viene aumentato a uno come descrive Paul White (@SQL_Kiwi) in questa risposta dba.stackexchange.
Il modo in cui in genere potremmo aggirare questo problema consiste nell'aggiungere OPTION (RECOMPILE) alla query che fa riferimento alla variabile di tabella, costringendo l'ottimizzatore a controllare la cardinalità della variabile di tabella dopo che è stata popolata. Per evitare la necessità di modificare manualmente ogni query per aggiungere un suggerimento di ricompilazione esplicito, è stato introdotto un nuovo flag di traccia (2453) in SQL Server 2012 Service Pack 2 e SQL Server 2014 Cumulative Update n. 3:
- KB #2952444:FIX:prestazioni scarse quando si utilizzano variabili di tabella in SQL Server 2012 o SQL Server 2014
Quando il flag di traccia 2453 è attivo, l'ottimizzatore può ottenere un'immagine accurata della cardinalità della tabella dopo la creazione della variabile della tabella. Questa può essere una buona cosa per molte query, ma probabilmente non tutte, e dovresti essere consapevole di come funziona in modo diverso da OPTION (RECOMPILE) . In particolare, l'ottimizzazione dell'incorporamento dei parametri di cui parla Paul White in questo post si verifica in OPTION (RECOMPILE) , ma non sotto questo nuovo flag di traccia.
Un semplice test
Il mio test iniziale consisteva semplicemente nel popolare una variabile di tabella e selezionarla; questo ha prodotto il conteggio delle righe stimato fin troppo familiare di 1. Ecco il test che ho eseguito (e ho aggiunto il suggerimento di ricompilazione per confrontare):
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Utilizzando SQL Sentry Plan Explorer, possiamo vedere che il piano grafico per entrambe le query in questo caso è identico, probabilmente almeno in parte perché questo è letteralmente un piano banale:

Piano grafico per una banale scansione dell'indice contro @t
Tuttavia, le stime non sono le stesse. Anche se il flag di traccia è abilitato, otteniamo comunque una stima di 1 in uscita dalla scansione dell'indice se non utilizziamo il suggerimento di ricompilazione:
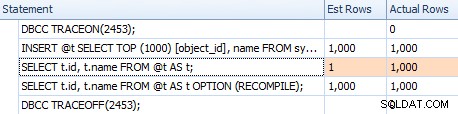
Confronto delle stime per un piano banale nella griglia degli estratti conto
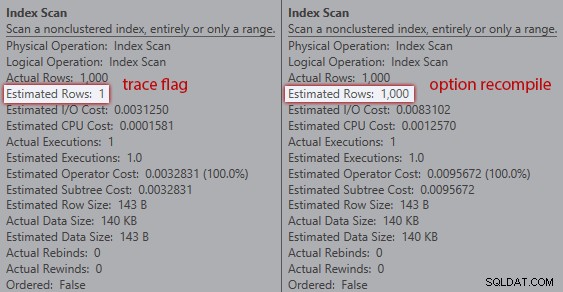
Confronto delle stime tra flag di traccia (a sinistra) e ricompilazione (a destra)
Se sei mai stato vicino a me di persona, probabilmente puoi immaginare la faccia che ho fatto a questo punto. Ho pensato per certo che l'articolo della Knowledge Base elencasse il numero di flag di traccia errato o che avessi bisogno di qualche altra impostazione abilitata affinché fosse veramente attivo.
Benjamin Nevarez (@BenjaminNevarez) mi ha subito fatto notare che dovevo esaminare più da vicino l'articolo della Knowledge Base "Bug risolti in SQL Server 2012 Service Pack 2". Sebbene abbiano oscurato il testo dietro un punto elenco nascosto in In evidenza> Motore relazionale, l'articolo dell'elenco di correzioni fa un lavoro leggermente migliore nel descrivere il comportamento del flag di traccia rispetto all'articolo originale (enfasi mia):
Se una variabile di tabella è unita ad altre tabelle in SQL Server, potrebbe causare prestazioni lente a causa della selezione inefficiente del piano di query perché SQL Server non supporta le statistiche o tiene traccia del numero di righe in una variabile di tabella durante la compilazione di un piano di query.Quindi sembrerebbe da questa descrizione che il flag di traccia ha lo scopo di risolvere il problema solo quando la variabile di tabella partecipa a un join. (Perché questa distinzione non è fatta nell'articolo originale, non ne ho idea.) Ma funziona anche se facciamo lavorare un po' di più le query:la query sopra è considerata banale dall'ottimizzatore e il flag di traccia non lo fa Non provare nemmeno a fare qualcosa in quel caso. Ma si avvierà se viene eseguita l'ottimizzazione basata sui costi, anche senza un join; il flag di traccia semplicemente non ha alcun effetto su piani banali. Ecco un esempio di un piano non banale che non prevede un'adesione:
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Questo piano non è più banale; l'ottimizzazione è contrassegnata come completa. La maggior parte del costo viene trasferita a un operatore di ordinamento:
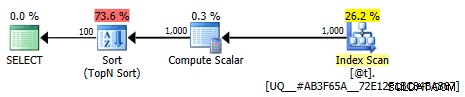
Piano grafico meno banale
E le stime si allineano per entrambe le query (questa volta ti conserverò i suggerimenti sugli strumenti, ma posso assicurarti che sono gli stessi):

Griglia delle dichiarazioni per piani meno banali con e senza il suggerimento di ricompilazione
Quindi sembra che l'articolo della Knowledge Base non sia esattamente accurato:sono stato in grado di forzare il comportamento previsto del flag di traccia senza introdurre un join. Ma voglio testarlo anche con un join.
Un test migliore
Prendiamo questo semplice esempio, con e senza il flag di traccia:
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
Senza il flag di traccia, l'ottimizzatore stima che una riga proverrà dalla scansione dell'indice rispetto alla variabile della tabella. Tuttavia, con il flag di traccia abilitato, vengono visualizzate le 1.000 righe:
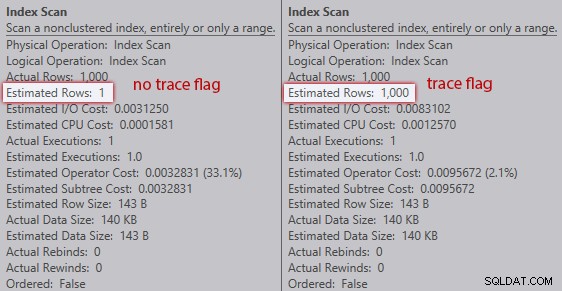
Confronto delle stime della scansione dell'indice (nessun flag di traccia a sinistra, flag di traccia a destra)
Le differenze non si fermano qui. Se osserviamo più da vicino, possiamo vedere una varietà di decisioni diverse che l'ottimizzatore ha preso, tutte derivanti da queste stime migliori:
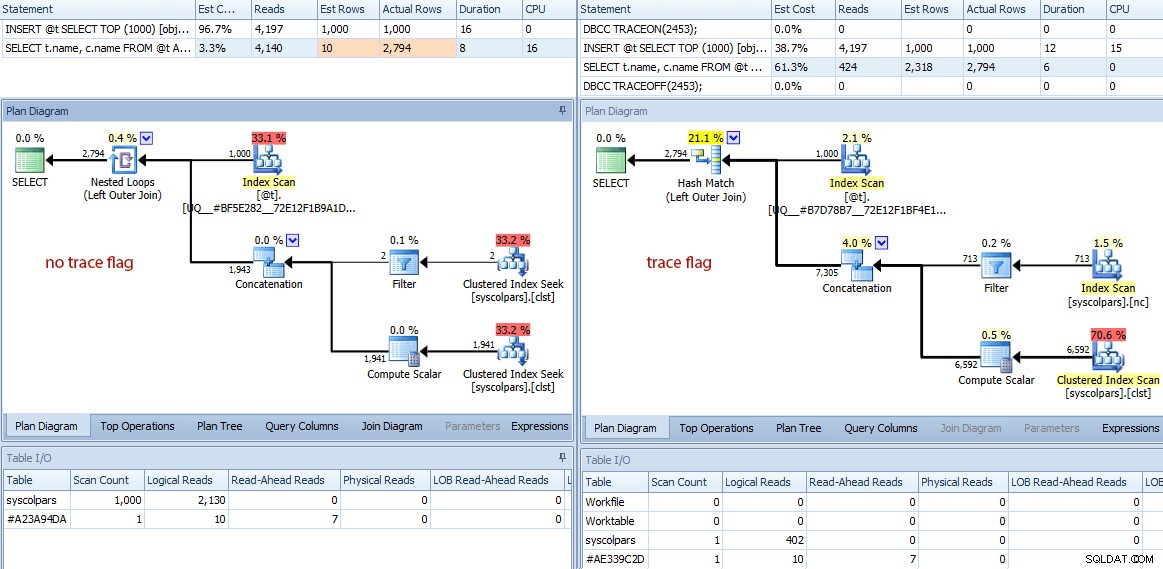
Confronto dei piani (nessuna traccia flag a sinistra, traccia flag a destra)
Un breve riassunto delle differenze:
- La query senza il flag di traccia ha eseguito 4.140 operazioni di lettura, mentre la query con la stima migliorata ne ha eseguite solo 424 (una riduzione di circa il 90%).
- L'ottimizzatore ha stimato che l'intera query avrebbe restituito 10 righe senza il flag di traccia e 2.318 righe molto più accurate quando si utilizza il flag di traccia.
- Senza il flag di traccia, l'ottimizzatore ha scelto di eseguire un join di loop nidificato (il che ha senso quando si stima che uno degli input sia molto piccolo). Ciò ha portato l'operatore di concatenazione ed entrambi gli indici cercano l'esecuzione 1.000 volte, in contrasto con la corrispondenza hash scelta sotto il flag di traccia, in cui l'operatore di concatenazione ed entrambe le scansioni sono state eseguite solo una volta.
- La scheda I/O tabella mostra anche 1.000 scansioni (scansioni di intervallo mascherate da ricerche di indice) e un conteggio di letture logiche molto più elevato rispetto a
syscolpars(la tabella di sistema dietrosys.all_columns). - Sebbene la durata non sia stata influenzata in modo significativo (24 millisecondi contro 18 millisecondi), puoi probabilmente immaginare il tipo di impatto che queste altre differenze potrebbero avere su una query più seria.
- Se passiamo al diagramma sui costi stimati, possiamo vedere quanto la variabile della tabella sia molto diversa può ingannare l'ottimizzatore senza il flag di traccia:
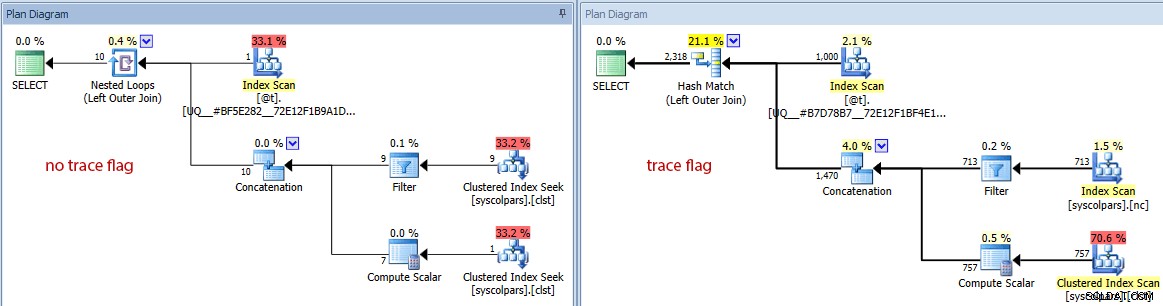
Confronto dei conteggi di righe stimati (nessun flag di traccia a sinistra, traccia bandiera a destra)
È chiaro e non scioccante che l'ottimizzatore fa un lavoro migliore nel selezionare il piano giusto quando ha una visione accurata della cardinalità coinvolta. Ma a quale costo?
ricompila e sovraccarichi
Quando utilizziamo OPTION (RECOMPILE) con il batch precedente, senza il flag di traccia abilitato, otteniamo il seguente piano, che è praticamente identico al piano con il flag di traccia (l'unica differenza evidente è che le righe stimate sono 2.316 invece di 2.318):
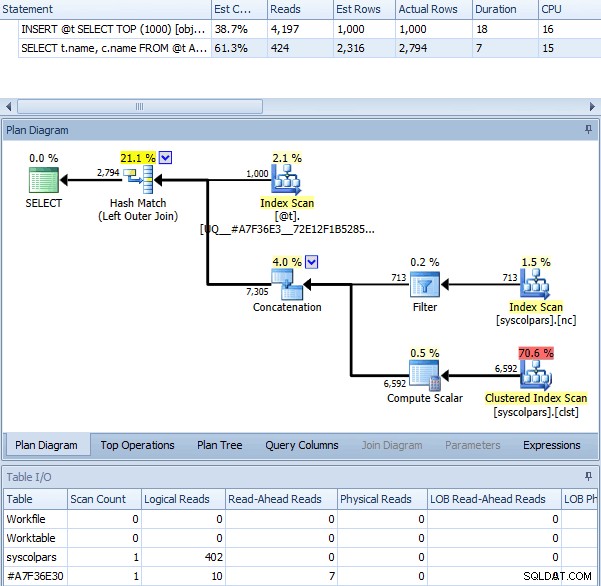
Stessa query con OPTION (RICIMPILA)
Quindi, questo potrebbe farti credere che il flag di traccia ottenga risultati simili attivando una ricompilazione per te ogni volta. Possiamo indagare su questo utilizzando una sessione di eventi estesi molto semplice:
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; Ho eseguito il seguente set di batch, che ha eseguito 20 query con (a) nessuna opzione di ricompilazione o flag di traccia, (b) l'opzione di ricompilazione e (c) un flag di traccia a livello di sessione.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
Poi ho guardato i dati dell'evento:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255);
I risultati mostrano che non si è verificata alcuna ricompilazione nella query standard, l'istruzione che fa riferimento alla variabile della tabella è stata ricompilata una volta sotto il flag di traccia e, come ci si potrebbe aspettare, ogni volta con il RECOMPILE opzione:
| sql_text | ricompile_count |
|---|---|
| /* ricompila */ DECLARE @t TABLE (i INT … | 20 |
| /* trace flag */ DBCC TRACEON(2453); DICHIARA @t … | 1 |
Risultati della query sui dati XEvents
Successivamente, ho disattivato la sessione Eventi estesi, quindi ho modificato il batch per misurare su larga scala. In sostanza, il codice misura 1.000 iterazioni di creazione e popolamento di una variabile di tabella, quindi seleziona i risultati in una tabella #temp (un modo per sopprimere l'output di tanti set di risultati usa e getta), utilizzando ciascuno dei tre metodi.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
Ho eseguito questo batch 10 volte e ho preso le medie; erano:
| Metodo | Durata media (millisecondi) |
|---|---|
| Predefinito | 23.148,4 |
| Ricompila | 29.959,3 |
| Traccia bandiera | 22.100,7 |
Durata media per 1.000 iterazioni
In questo caso, ottenere le stime corrette ogni volta utilizzando il suggerimento di ricompilazione era molto più lento del comportamento predefinito, ma l'utilizzo del flag di traccia era leggermente più veloce. Questo ha senso perché, mentre entrambi i metodi correggono il comportamento predefinito dell'utilizzo di una stima falsa (e di conseguenza di ottenere un piano errato), le ricompilazioni richiedono risorse e, quando non forniscono o non possono produrre un piano più efficiente, tendono a contribuiscono alla durata complessiva del batch.
Sembra semplice, ma aspetta...
Il test di cui sopra è leggermente - e intenzionalmente - imperfetto. Stiamo inserendo lo stesso numero di righe (1000) nella variabile di tabella ogni volta . Cosa succede se la popolazione iniziale della variabile tabella varia per batch diversi? Sicuramente vedremo ricompilazioni allora, anche sotto il flag di traccia, giusto? Tempo per un altro test. Impostiamo una sessione di eventi estesi leggermente diversa, solo con un nome file di destinazione diverso (per non confondere i dati dell'altra sessione):
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START;
Ora, esaminiamo questo batch, impostando i conteggi delle righe per ogni iterazione che sono significativamente diversi. Lo eseguiremo tre volte, rimuovendo i commenti appropriati in modo da avere un batch senza flag di traccia o ricompilazione esplicita, un batch con flag di traccia e un batch con OPTION (RECOMPILE) (avere un commento accurato all'inizio rende questi batch più facili da identificare in luoghi come l'output di eventi estesi):
/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END
Ho eseguito questi batch in Management Studio, li ho aperti singolarmente in Plan Explorer e ho filtrato l'albero delle istruzioni solo su SELECT interrogazione. Possiamo vedere il diverso comportamento nei tre batch osservando le righe stimate ed effettive:

Confronto di tre batch, guardando le righe stimate e quelle effettive
Nella griglia più a destra, puoi vedere chiaramente dove le ricompilazioni non sono avvenute sotto il flag di traccia
Possiamo controllare i dati di XEvents per vedere cosa è effettivamente successo con le ricompilazioni:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Risultati:
| sql_text | ricompile_count |
|---|---|
| /* ricompila */ DECLARE @i INT =1; MENTRE... | 6 |
| /* trace flag */ DECLARE @i INT =1; MENTRE... | 4 |
Risultati della query sui dati XEvents
Molto interessante! Sotto il flag di traccia, vengono *eseguite* ricompilazioni, ma solo quando il valore del parametro di runtime è variato in modo significativo dal valore memorizzato nella cache. Quando il valore di runtime è diverso, ma non di molto, non otteniamo una ricompilazione e vengono utilizzate le stesse stime. Quindi è chiaro che il flag di traccia introduce una soglia di ricompilazione per le variabili di tabella e ho confermato (attraverso un test separato) che questo utilizza lo stesso algoritmo descritto per le tabelle #temp in questo documento "antico" ma ancora rilevante. Lo dimostrerò in un post di follow-up.
Di nuovo testeremo le prestazioni, eseguendo il batch 1.000 volte (con la sessione Eventi estesi disattivata) e misurando la durata:
| Metodo | Durata media (millisecondi) |
|---|---|
| Predefinito | 101.285,4 |
| Ricompila | 111.423,3 |
| Traccia bandiera | 110.318,2 |
Durata media per 1.000 iterazioni
In questo scenario specifico, perdiamo circa il 10% delle prestazioni forzando una ricompilazione ogni volta o utilizzando un flag di traccia. Non sono esattamente sicuro di come fosse distribuito il delta:i piani basati su stime migliori non erano significativamente meglio? Le ricompilazioni hanno compensato eventuali incrementi di prestazioni di di tanto ? Non voglio dedicare troppo tempo a questo, ed era un esempio banale, ma ti mostra che giocare con il modo in cui funziona l'ottimizzatore può essere un affare imprevedibile. A volte potresti stare meglio con il comportamento predefinito di cardinalità =1, sapendo che non causerai mai ricompilazioni indebite. Il punto in cui il flag di traccia potrebbe avere molto senso è se si hanno query in cui si popolano ripetutamente variabili di tabella con lo stesso insieme di dati (ad esempio, una tabella di ricerca del codice postale) o si utilizzano sempre 50 o 1.000 righe (ad esempio, popolando una variabile di tabella da utilizzare nell'impaginazione). In ogni caso, dovresti sicuramente testare l'impatto che questo ha su qualsiasi carico di lavoro in cui prevedi di introdurre il flag di traccia o le ricompilazioni esplicite.
TVP e tipi di tabelle
Ero anche curioso di sapere come ciò avrebbe influenzato i tipi di tabella e se avremmo visto miglioramenti nella cardinalità per i TVP, dove esiste questo stesso sintomo. Quindi ho creato un semplice tipo di tabella che imita la variabile di tabella in uso finora:
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
Quindi ho preso il batch di cui sopra e ho semplicemente sostituito DECLARE @t TABLE(id INT PRIMARY KEY); con DECLARE @t dbo.t; – tutto il resto è rimasto esattamente lo stesso. Ho eseguito gli stessi tre batch ed ecco cosa ho visto:

Confronto di stime ed effettivi tra comportamento predefinito, ricompilazione delle opzioni e flag di traccia 2453
Quindi sì, sembra che il flag di traccia funzioni esattamente allo stesso modo con i TVP:le ricompilazioni generano nuove stime per l'ottimizzatore quando i conteggi delle righe superano la soglia di ricompilazione e vengono ignorati quando i conteggi delle righe sono "abbastanza vicini".
Pro, contro e avvertenze
Un vantaggio del flag di traccia è che puoi evitarne alcuni ricompila e continua a vedere la cardinalità della tabella, purché si preveda che il numero di righe nella variabile della tabella sia stabile o non si osservino deviazioni significative del piano dovute alla variazione della cardinalità. Un altro è che puoi abilitarlo a livello globale oa livello di sessione e non devi introdurre suggerimenti di ricompilazione a tutte le tue query. E infine, almeno nel caso in cui la cardinalità delle variabili di tabella fosse stabile, stime corrette hanno portato a prestazioni migliori rispetto all'impostazione predefinita e anche a prestazioni migliori rispetto all'utilizzo dell'opzione di ricompilazione:tutte quelle compilazioni possono certamente sommarsi.
Ci sono anche degli svantaggi, ovviamente. Uno che ho menzionato sopra è quello rispetto a OPTION (RECOMPILE) perdi alcune ottimizzazioni, come l'incorporamento dei parametri. Un altro è che il flag di traccia non avrà l'impatto che ti aspetti su piani banali. E uno che ho scoperto lungo la strada è che usando il QUERYTRACEON il suggerimento per applicare il flag di traccia a livello di query non funziona – per quanto ne so, il flag di traccia deve essere presente quando la variabile di tabella o TVP viene creata e/o popolata affinché l'ottimizzatore possa vedere la cardinalità sopra 1.
Tieni presente che l'esecuzione del flag di traccia a livello globale introduce la possibilità di regressioni del piano di query a qualsiasi query che coinvolga una variabile di tabella (motivo per cui questa funzionalità è stata introdotta in primo luogo con un flag di traccia), quindi assicurati di testare l'intero carico di lavoro non importa come usi il flag di traccia. Inoltre, quando stai testando questo comportamento, fallo in un database utente; alcune delle ottimizzazioni e semplificazioni che normalmente ti aspetti si verifichino semplicemente non si verificano quando il contesto è impostato su tempdb, quindi qualsiasi comportamento che osservi potrebbe non rimanere coerente quando sposti il codice e le impostazioni in un database utente.
Conclusione
Se si utilizzano variabili di tabella o TVP con un numero di righe elevato ma relativamente coerente, potrebbe essere utile abilitare questo flag di traccia per determinati batch o procedure al fine di ottenere una cardinalità precisa della tabella senza forzare manualmente una ricompilazione su singole query. Puoi anche utilizzare il flag di traccia a livello di istanza, che influirà su tutte le query. Ma come ogni modifica, in entrambi i casi, dovrai essere diligente nel testare le prestazioni dell'intero carico di lavoro, cercando esplicitamente eventuali regressioni e assicurandoti di volere il comportamento del flag di traccia perché puoi fidarti della stabilità della tua variabile di tabella conteggi delle righe.
Sono felice di vedere il flag di traccia aggiunto a SQL Server 2014, ma sarebbe meglio se diventasse il comportamento predefinito. Non che ci sia un vantaggio significativo nell'usare variabili di tabella di grandi dimensioni rispetto a tabelle #temp di grandi dimensioni, ma sarebbe bello vedere una maggiore parità tra questi due tipi di struttura temporanea che potrebbero essere dettati a un livello superiore. Più parità abbiamo, meno persone devono deliberare su quale utilizzare (o almeno avere meno criteri da considerare quando scelgono). Martin Smith ha un'ottima sessione di domande e risposte su dba.stackexchange che probabilmente ora dovrebbe essere aggiornata:qual è la differenza tra una tabella temporanea e una variabile di tabella in SQL Server?
Nota importante
Se hai intenzione di installare SQL Server 2012 Service Pack 2 (indipendentemente dal fatto che debba utilizzare o meno questo flag di traccia), consulta anche il mio post su una regressione in SQL Server 2012 e 2014 che può, in rari scenari, introdurre potenziale perdita o danneggiamento dei dati durante la ricostruzione dell'indice online. Sono disponibili aggiornamenti cumulativi per SQL Server 2012 SP1 e SP2 e anche per SQL Server 2014. Non ci saranno correzioni per il ramo RTM 2012.
Ulteriori test
Ho altre cose sulla mia lista da testare. Per prima cosa, vorrei vedere se questo flag di traccia ha qualche effetto sui tipi di tabella in memoria in SQL Server 2014. Dimostrerò anche senza ombra di dubbio che il flag di traccia 2453 utilizza la stessa soglia di ricompilazione per la tabella variabili e TVP come per le tabelle #temp.



