Alcune settimane fa il team di SQLskills era a Tampa per il nostro Performance Tuning Immersion Event (IE2) e stavo coprendo le linee di base. Le linee di base sono un argomento che mi sta a cuore e che mi sta molto a cuore, perché sono così preziose per molte ragioni. Due di questi motivi, che sollevo sempre sia quando insegno che quando lavoro con i clienti, sono l'utilizzo delle linee di base per risolvere i problemi delle prestazioni, quindi anche l'andamento dell'utilizzo e la fornitura di stime di pianificazione della capacità. Ma sono anche essenziali quando esegui l'ottimizzazione o il test delle prestazioni, indipendentemente dal fatto che tu consideri le metriche delle prestazioni esistenti come linee di base o meno.
Durante il modulo, ho esaminato diverse fonti di dati come Performance Monitor, DMV e dati di traccia o XE, ed è emersa una domanda relativa ai carichi di dati. In particolare, la domanda era se fosse meglio caricare i dati in una tabella senza indici e quindi crearli al termine, piuttosto che avere gli indici in posizione durante il caricamento dei dati. La mia risposta è stata:"In genere sì". La mia esperienza personale è stata che è sempre così, ma non si sa mai in quale avvertimento o scenario unico potrebbe imbattersi qualcuno in cui il cambiamento di prestazioni non è quello previsto, e come con tutte le domande sul rendimento, non lo sai con certezza finché non lo testi. Fino a quando non stabilisci una linea di base per un metodo e poi vedi se l'altro metodo migliora rispetto a quella linea di base, stai solo ipotizzando. Ho pensato che sarebbe stato divertente testarlo questo scenario, non solo per dimostrare ciò che mi aspetto sia vero, ma anche per mostrare quali metriche esaminerei, perché e come acquisirle. Se hai già eseguito test delle prestazioni in precedenza, probabilmente è un vecchio cappello. Ma per quelli di te nuovo alla pratica, illustrerò il processo che seguo per aiutarti a iniziare. Renditi conto che ci sono molti modi per ricavare la risposta a "Quale metodo è migliore?" Mi aspetto che prenderai questo processo, lo modificherai e lo renderai tuo nel tempo.
Cosa stai cercando di dimostrare?
Il primo passo è decidere esattamente cosa stai testando. Nel nostro caso è semplice:è più veloce caricare i dati in una tabella vuota, quindi aggiungere gli indici, oppure è più veloce avere gli indici sulla tabella durante il caricamento dei dati? Ma possiamo aggiungere qualche variazione qui se vogliamo. Considera il tempo necessario per caricare i dati in un heap e quindi creare gli indici cluster e non cluster, rispetto al tempo necessario per caricare i dati in un indice cluster, quindi creare gli indici non cluster. C'è una differenza nelle prestazioni? La chiave di clustering potrebbe essere un fattore? Mi aspetto che il carico di dati provochi la frammentazione degli indici non cluster esistenti, quindi forse voglio vedere quale impatto ha la ricostruzione degli indici dopo il carico sulla durata totale. È importante approfondire questo passaggio il più possibile ed essere molto specifici su ciò che si desidera misurare, poiché ciò determinerà quali dati acquisirai. Per il nostro esempio, i nostri quattro test saranno:
Test 1: Carica i dati in un heap, crea l'indice cluster, crea gli indici non cluster
Test 2: Carica i dati in un indice cluster, crea gli indici non cluster
Test 3: Crea l'indice cluster e gli indici non cluster, carica i dati
Test 4: Crea l'indice cluster e gli indici non cluster, carica i dati, ricostruisci gli indici non cluster
Cosa devi sapere?
Nel nostro scenario, la nostra domanda principale è "qual è il metodo più veloce"? Pertanto, vogliamo misurare la durata e per farlo dobbiamo catturare un'ora di inizio e un'ora di fine. Potremmo lasciarlo così, ma potremmo voler capire come appare l'utilizzo delle risorse per ciascun metodo, o forse vogliamo conoscere le attese più alte, il numero di transazioni o il numero di deadlock. I dati più interessanti e rilevanti dipenderanno dai processi che stai confrontando. Catturare il numero di transazioni non è così interessante per il nostro carico di dati; ma per una modifica del codice potrebbe essere. Poiché stiamo creando indici e ricostruendoli, sono interessato a quanto IO genera ciascun metodo. Sebbene la durata complessiva sia probabilmente il fattore decisivo alla fine, esaminare l'IO potrebbe essere utile non solo per capire quale opzione genera più IO, ma anche se l'archiviazione del database sta funzionando come previsto.
Dove sono i dati di cui hai bisogno?
Una volta determinati i dati di cui hai bisogno, decidi da dove verranno acquisiti. Siamo interessati alla durata, quindi vogliamo registrare l'ora in cui inizia ogni test di caricamento dei dati e quando finisce. Siamo anche interessati all'IO e possiamo estrarre questi dati da più posizioni:vengono in mente i contatori di Performance Monitor e il DMV sys.dm_io_virtual_file_stats.
Comprendi che potremmo ottenere questi dati manualmente. Prima di eseguire un test, possiamo selezionare contro sys.dm_io_virtual_file_stats e salvare i valori correnti in un file. Possiamo annotare l'ora e quindi iniziare il test. Al termine, notiamo di nuovo il tempo, eseguiamo nuovamente una query su sys.dm_io_virtual_file_stats e calcoliamo le differenze tra i valori per misurare l'IO.
Ci sono numerosi difetti in questa metodologia, vale a dire che lascia un ampio margine di errore; cosa succede se dimentichi di annotare l'ora di inizio o dimentichi di acquisire le statistiche del file prima di iniziare? Una soluzione molto migliore consiste nell'automatizzare non solo l'esecuzione dello script, ma anche l'acquisizione dei dati. Ad esempio, possiamo creare una tabella che contiene le informazioni sul test:una descrizione di cosa è il test, a che ora è iniziato e a che ora è stato completato. Possiamo includere le statistiche del file nella stessa tabella. Se stiamo raccogliendo altre metriche, possiamo aggiungerle alla tabella. Oppure, potrebbe essere più semplice creare una tabella separata per ogni set di dati che acquisiamo. Ad esempio, se memorizziamo i dati delle statistiche dei file in una tabella diversa, dobbiamo assegnare a ogni test un ID univoco, in modo da poter abbinare il nostro test con i dati delle statistiche dei file corretti. Quando si acquisiscono le statistiche sui file, dobbiamo acquisire i valori per il nostro database prima di iniziare, quindi dopo, e calcolare la differenza. Possiamo quindi archiviare tali informazioni nella propria tabella, insieme all'ID univoco del test.
Un esempio di esercizio
Per questo test ho creato una copia vuota della tabella Sales.SalesOrderHeader denominata Sales.Big_SalesOrderHeader e ho utilizzato una variazione di uno script che ho utilizzato nel mio post di partizionamento per caricare i dati nella tabella in batch di circa 25.000 righe. È possibile scaricare lo script per il caricamento dei dati qui. L'ho eseguito quattro volte per ogni variazione e ho anche variato il numero totale di righe inserite. Per la prima serie di test ho inserito 20 milioni di righe e per la seconda serie ho inserito 60 milioni di righe. I dati sulla durata non sono sorprendenti:
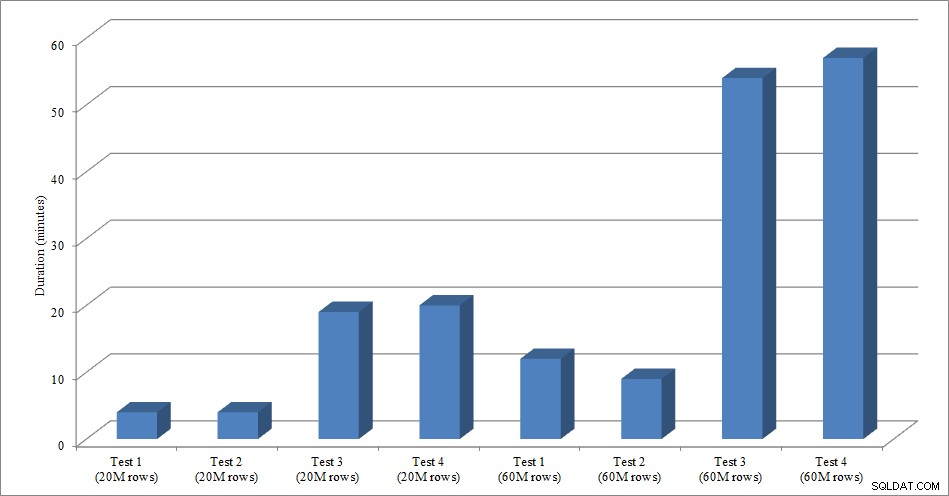
Durata caricamento dati
Il caricamento dei dati, senza gli indici non cluster, è molto più rapido rispetto al caricamento con gli indici non cluster già presenti. Quello che ho trovato interessante è che per il carico di 20 milioni di righe, la durata totale era più o meno la stessa tra il Test 1 e il Test 2, ma il Test 2 è stato più veloce durante il caricamento di 60 milioni di righe. Nel nostro test, la nostra chiave di clustering era SalesOrderID, che è un'identità e quindi una buona chiave di clustering per il nostro carico poiché è ascendente. Se avessimo invece una chiave di clustering che fosse un GUID, il tempo di caricamento potrebbe essere maggiore a causa di inserimenti casuali e divisioni di pagina (un'altra variazione che potremmo testare).
I dati IO imitano l'andamento dei dati di durata? Sì, con le differenze che hanno gli indici già in atto, o meno, ancora più esagerati:
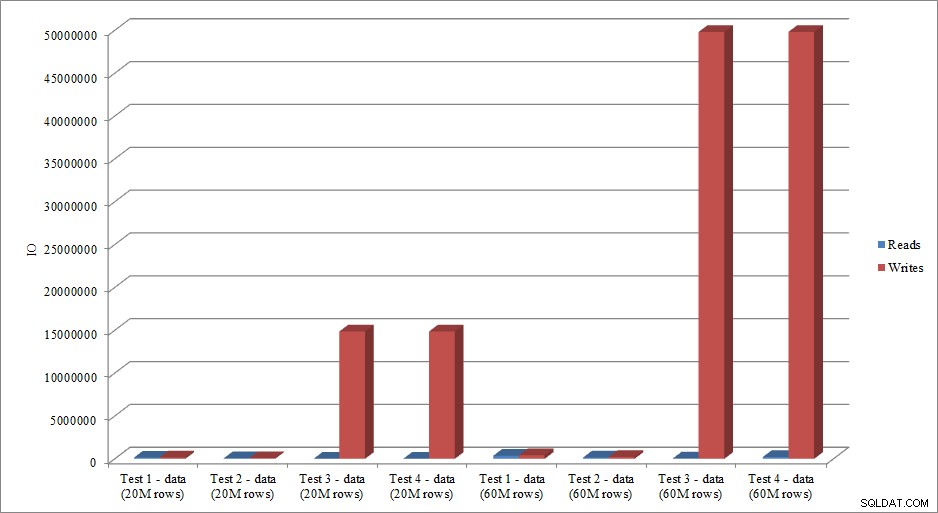
Letture e scritture caricamento dati
Il metodo che ho presentato qui per il test delle prestazioni, o la misurazione dei cambiamenti nelle prestazioni in base alle modifiche al codice, al design, ecc., è solo un'opzione per acquisire le informazioni di base. In alcuni scenari, questo potrebbe essere eccessivo. Se hai una query che stai cercando di ottimizzare, l'impostazione di questo processo per acquisire i dati potrebbe richiedere più tempo di quanto sarebbe necessario per apportare modifiche alla query! Se hai eseguito un po' di ottimizzazione delle query, probabilmente hai l'abitudine di acquisire i dati STATISTICS IO e STATISTICS TIME, insieme al piano di query, e quindi confrontare l'output mentre apporti le modifiche. Lo faccio da anni, ma di recente ho scoperto un modo migliore... SQL Sentry Plan Explorer PRO. In effetti, dopo aver completato tutti i test di carico descritti sopra, ho eseguito ed eseguito nuovamente i test tramite PE e ho scoperto che potevo acquisire le informazioni desiderate, senza dover impostare le tabelle di raccolta dei dati.
In Plan Explorer PRO hai la possibilità di ottenere il piano effettivo:PE eseguirà la query sull'istanza e sul database selezionati e restituirà il piano. E con esso, ottieni tutti gli altri fantastici dati forniti da PE (statistiche temporali, letture e scritture, IO per tabella), nonché le statistiche di attesa, il che è un bel vantaggio. Utilizzando il nostro esempio, ho iniziato con il primo test, creando l'heap, caricando i dati e quindi aggiungendo l'indice cluster e gli indici non cluster, quindi ho eseguito l'opzione Ottieni piano effettivo. Al termine, ho modificato il mio script test 2, ho eseguito nuovamente l'opzione Ottieni piano effettivo. L'ho ripetuto per la terza e la quarta prova e, quando ho finito, ho avuto questo:
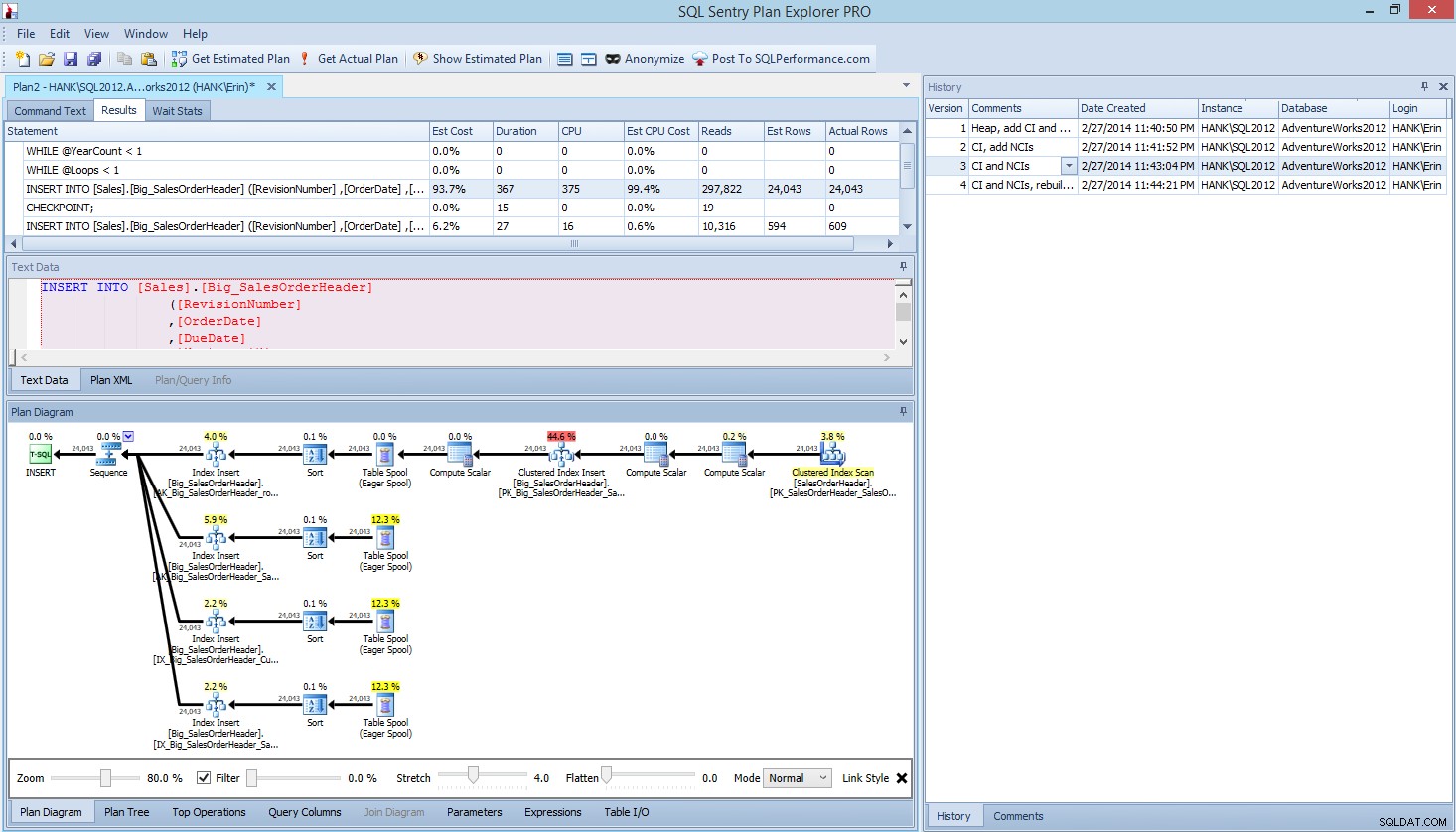
Pianifica la vista di Explorer PRO dopo aver eseguito 4 test
Notare il riquadro della cronologia sul lato destro? Ogni volta che modificavo il mio codice e recuperavo il piano effettivo, salvava una nuova serie di informazioni. Ho la possibilità di salvare questi dati come file .pesession da condividere con un altro membro del mio team, o tornare più tardi e scorrere i diversi test e, se necessario, approfondire le diverse dichiarazioni all'interno del batch, esaminando metriche diverse come come durata, CPU e IO. Nella schermata sopra, ho evidenziato INSERT dal test 3 e il piano di query mostra gli aggiornamenti per tutti e quattro gli indici non cluster.
Riepilogo
Come per molte attività in SQL Server, esistono molti modi per acquisire ed esaminare i dati durante l'esecuzione di test delle prestazioni o l'ottimizzazione. Meno sforzo manuale devi fare, meglio è, poiché lascia più tempo per apportare modifiche, comprenderne l'impatto e quindi passare al tuo prossimo compito. Sia che tu personalizzi uno script per acquisire dati, sia che lo faccia un'utilità di terze parti per te, i passaggi che ho delineato sono ancora validi:
- Definisci cosa vuoi migliorare
- Ambita i tuoi test
- Determina quali dati possono essere utilizzati per misurare il miglioramento
- Decidi come acquisire i dati
- Imposta un metodo automatizzato, ove possibile, per il test e l'acquisizione
- Verifica, valuta e ripeti se necessario
Buon test!