Questa è la tredicesima e ultima puntata di una serie sulle espressioni delle tabelle. Questo mese continuo la discussione iniziata il mese scorso sulle funzioni inline table-valued (iTVF).
Il mese scorso ho spiegato che quando SQL Server integra gli iTVF che vengono interrogati con costanti come input, applica l'ottimizzazione dell'incorporamento dei parametri per impostazione predefinita. L'incorporamento dei parametri significa che SQL Server sostituisce i riferimenti ai parametri nella query con i valori costanti letterali dell'esecuzione corrente e quindi il codice con le costanti viene ottimizzato. Questo processo consente semplificazioni che possono portare a piani di query più ottimali. Questo mese approfondisco l'argomento, coprendo casi specifici per tali semplificazioni come la piegatura costante e il filtraggio e l'ordinamento dinamici. Se hai bisogno di un aggiornamento sull'ottimizzazione dell'incorporamento dei parametri, leggi l'articolo del mese scorso e l'eccellente articolo di Paul White Sniffing, Incorporamento e Opzioni di RICOSTRUZIONE dei parametri.
Nei miei esempi, userò un database di esempio chiamato TSQLV5. Puoi trovare lo script che lo crea e lo popola qui e il suo diagramma ER qui.
Piegatura costante
Durante le prime fasi dell'elaborazione delle query, SQL Server valuta determinate espressioni che coinvolgono costanti, piegandole alle costanti del risultato. Ad esempio, l'espressione 40 + 2 può essere piegata alla costante 42. Puoi trovare le regole per le espressioni ripiegabili e non ripiegabili qui in "Ripiegamento costante e valutazione delle espressioni".
La cosa interessante per quanto riguarda gli iTVF è che, grazie all'ottimizzazione dell'incorporamento dei parametri, le query che coinvolgono gli iTVF in cui si passano costanti come input possono, nelle giuste circostanze, trarre vantaggio dal piegamento costante. Conoscere le regole per le espressioni pieghevoli e non pieghevoli può influenzare il modo in cui implementi i tuoi iTVF. In alcuni casi, applicando modifiche molto sottili alle tue espressioni, puoi abilitare piani più ottimali con un migliore utilizzo dell'indicizzazione.
Ad esempio, considera la seguente implementazione di un iTVF chiamato Sales.MyOrders:
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Invia la seguente query che coinvolge l'iTVF (la chiamerò Query 1):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Il piano per la query 1 è mostrato nella figura 1.
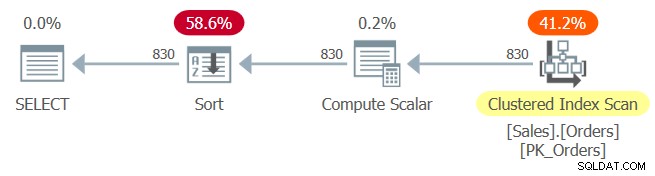 Figura 1:piano per la query 1
Figura 1:piano per la query 1
L'indice cluster PK_Orders è definito con orderid come chiave. Se il piegamento costante fosse avvenuto qui dopo l'incorporamento del parametro, l'espressione di ordinamento orderid + 1 – 10248 sarebbe stata piegata a orderid – 10247. Questa espressione sarebbe stata considerata un'espressione di conservazione dell'ordine rispetto a orderid e come tale avrebbe abilitato il ottimizzatore per fare affidamento sull'ordine dell'indice. Purtroppo, non è così, come è evidente dall'esplicito operatore di ordinamento nel piano. Allora, cos'è successo?
Le regole di piegatura costante sono schizzinose. L'espressione column1 + constant1 – constant2 viene valutata da sinistra a destra per scopi di piegatura costante. La prima parte, colonna1 + costante1 non è piegata. Chiamiamo questa espressione1. La parte successiva che viene valutata viene trattata come expression1 – constant2, che non viene nemmeno piegata. Senza piegare, un'espressione nella forma column1 + constant1 – constant2 non è considerata la conservazione dell'ordine rispetto a column1 e quindi non può fare affidamento sull'ordinamento degli indici anche se si dispone di un indice di supporto su column1. Allo stesso modo, l'espressione constant1 + column1 – constant2 non è pieghevole costante. Tuttavia, l'espressione constant1 – constant2 + column1 è pieghevole. Più precisamente, la prima parte constant1 – constant2 viene ripiegata in un'unica costante (chiamiamola costante3), risultando nell'espressione constant3 + column1. Questa espressione è considerata un'espressione di conservazione dell'ordine rispetto a column1. Quindi, purché ti assicuri di scrivere la tua espressione utilizzando l'ultimo modulo, puoi consentire all'ottimizzatore di fare affidamento sull'ordinamento degli indici.
Considera le seguenti query (le chiamerò Query 2, Query 3 e Query 4) e prima di esaminare i piani di query, verifica se puoi dire quali comporteranno l'ordinamento esplicito nel piano e quali no:
-- Query 2 SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 3 SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 4 SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid;
Ora esamina i piani per queste query come mostrato nella Figura 2.
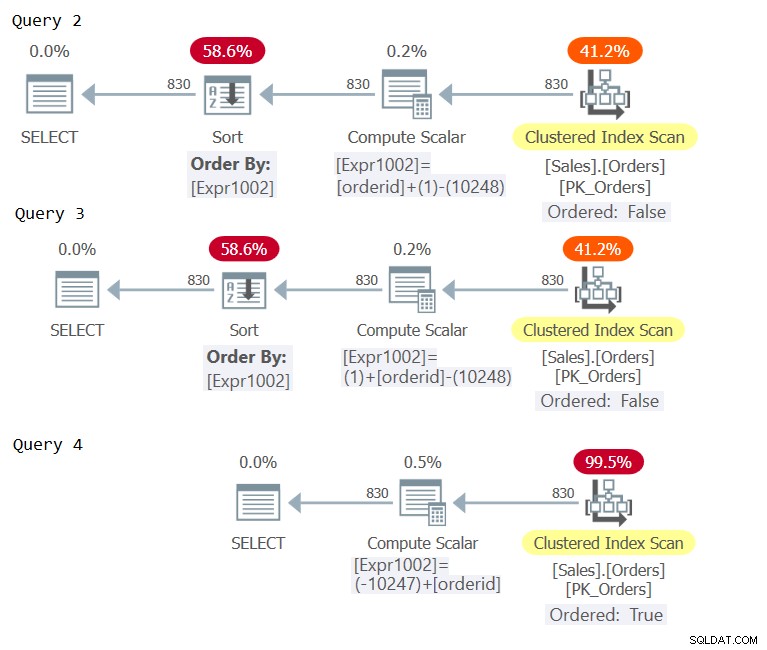 Figura 2:piani per Query 2, Query 3 e Query 4
Figura 2:piani per Query 2, Query 3 e Query 4
Esaminare gli operatori di calcolo scalare nei tre piani. Solo il piano per la query 4 ha subito un ripiegamento costante, risultando in un'espressione di ordinamento considerata di conservazione dell'ordine rispetto a orderid, evitando l'ordinamento esplicito.
Comprendendo questo aspetto della piegatura costante, puoi facilmente correggere l'iTVF cambiando l'espressione orderid + @add – @subtract in @add – @subtract + orderid, in questo modo:
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Interroga nuovamente la funzione (farò riferimento a questo come Query 5):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
Il piano per questa query è mostrato nella Figura 3.
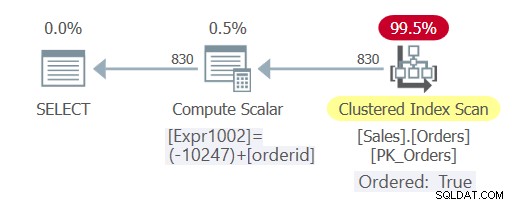 Figura 3:piano per la query 5
Figura 3:piano per la query 5
Come puoi vedere, questa volta la query ha subito un ripiegamento costante e l'ottimizzatore è stato in grado di fare affidamento sull'ordinamento degli indici, evitando l'ordinamento esplicito.
Ho usato un semplice esempio per dimostrare questa tecnica di ottimizzazione, e come tale potrebbe sembrare un po' forzata. Puoi trovare un'applicazione pratica di questa tecnica nell'articolo Soluzioni per la sfida del generatore di serie numeriche – Parte 1.
Filtraggio/ordinamento dinamico
Il mese scorso ho trattato la differenza tra il modo in cui SQL Server ottimizza una query in un iTVF rispetto alla stessa query in una stored procedure. SQL Server in genere applicherà l'ottimizzazione dell'incorporamento dei parametri per impostazione predefinita per una query che coinvolge un iTVF con costanti come input, ma ottimizzerà la forma parametrizzata di una query in una stored procedure. Tuttavia, se si aggiunge OPTION(RECOMPILE) alla query nella stored procedure, SQL Server in genere applicherà l'ottimizzazione dell'incorporamento dei parametri anche in questo caso. I vantaggi nel caso iTVF includono il fatto che puoi coinvolgerlo in una query e, finché passi ripetuti input costanti, c'è la possibilità di riutilizzare un piano precedentemente memorizzato nella cache. Con una stored procedure, non è possibile coinvolgerla in una query e se si aggiunge OPTION(RECOMPILE) per ottenere l'ottimizzazione dell'incorporamento dei parametri, non è possibile riutilizzare il piano. La procedura memorizzata consente molta più flessibilità in termini di elementi di codice che puoi utilizzare.
Vediamo come si svolge tutto questo in una classica attività di incorporamento e ordinamento dei parametri. Di seguito è riportata una stored procedure semplificata che applica il filtraggio dinamico e l'ordinamento simile a quello utilizzato da Paul nel suo articolo:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END; GO
Si noti che l'attuale implementazione della stored procedure non include OPTION(RECOMPILE) nella query.
Considera la seguente esecuzione della procedura memorizzata:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Il piano per questa esecuzione è mostrato nella Figura 4.
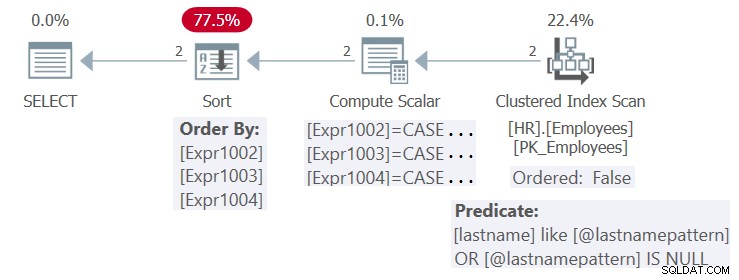 Figura 4:Piano per la procedura HR.GetEmpsP
Figura 4:Piano per la procedura HR.GetEmpsP
C'è un indice definito nella colonna del cognome. Teoricamente, con gli input correnti, l'indice potrebbe essere vantaggioso sia per le esigenze di filtraggio (con una ricerca) che per l'ordinamento (con una scansione ordinata:true range) della query. Tuttavia, poiché per impostazione predefinita SQL Server ottimizza la forma parametrizzata della query e non applica l'incorporamento dei parametri, non applica le semplificazioni necessarie per poter beneficiare dell'indice sia a scopo di filtro che di ordinamento. Quindi, il piano è riutilizzabile, ma non è ottimale.
Per vedere come cambiano le cose con l'ottimizzazione dell'incorporamento dei parametri, modificare la query della procedura memorizzata aggiungendo OPTION(RECOMPILE), in questo modo:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END OPTION(RECOMPILE); GO
Esegui di nuovo la procedura memorizzata con gli stessi input che hai utilizzato prima:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
Il piano per questa esecuzione è mostrato nella Figura 5.
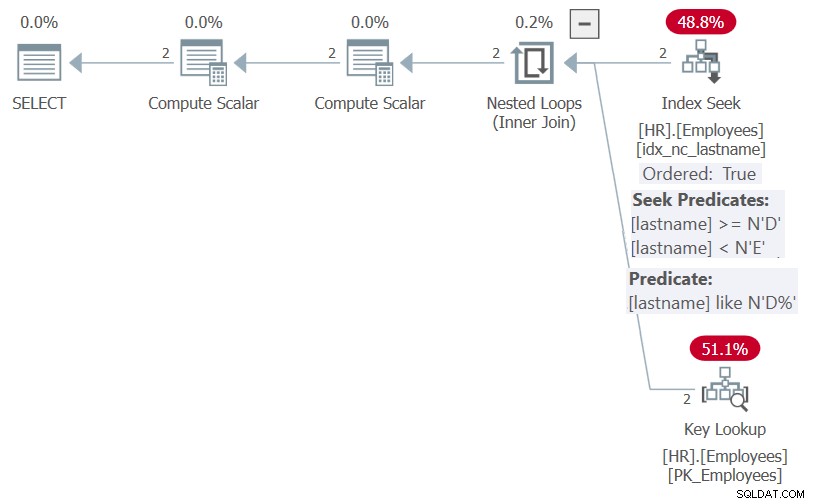 Figura 5:Piano per la procedura HR.GetEmpsP con OPTION(RICIMPILA)
Figura 5:Piano per la procedura HR.GetEmpsP con OPTION(RICIMPILA)
Come puoi vedere, grazie all'ottimizzazione dell'incorporamento dei parametri, SQL Server è stato in grado di semplificare il predicato del filtro sul predicato sargable lastname LIKE N'D%' e l'elenco di ordinamento su NULL, NULL, lastname. Entrambi gli elementi potrebbero beneficiare dell'indice sul cognome, quindi il piano mostra una ricerca nell'indice e nessun ordinamento esplicito.
In teoria, ci si aspetta di poter ottenere una semplificazione simile se si implementa la query in un iTVF, e quindi vantaggi di ottimizzazione simili, ma con la possibilità di riutilizzare i piani memorizzati nella cache quando vengono riutilizzati gli stessi valori di input. Allora, proviamo...
Ecco un tentativo di implementare la stessa query in un iTVF (non eseguire ancora questo codice):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GO Prima di tentare di eseguire questo codice, puoi vedere un problema con questa implementazione? Ricorda che all'inizio di questa serie ho spiegato che un'espressione di tabella è una tabella. Il corpo di una tabella è un insieme (o multiset) di righe e, in quanto tale, non ha ordine. Pertanto, normalmente, una query utilizzata come espressione di tabella non può avere una clausola ORDER BY. Infatti, se provi a eseguire questo codice, ottieni il seguente errore:
Msg 1033, Livello 15, Stato 1, Procedura GetEmps, Riga 16 [Batch Start Line 128]La clausola ORDER BY non è valida in viste, funzioni inline, tabelle derivate, sottoquery ed espressioni di tabelle comuni, a meno che TOP, OFFSET o viene specificato anche FOR XML.
Certo, come dice l'errore, SQL Server farà un'eccezione se si utilizza un elemento di filtro come TOP o OFFSET-FETCH, che si basa sulla clausola ORDER BY per definire l'aspetto dell'ordinamento del filtro. Ma anche se includi una clausola ORDER BY nella query interna grazie a questa eccezione, non ottieni comunque una garanzia per l'ordine del risultato in una query esterna rispetto all'espressione della tabella, a meno che non abbia la propria clausola ORDER BY .
Se desideri comunque implementare la query in un iTVF, puoi fare in modo che la query interna gestisca la parte del filtro dinamico, ma non l'ordinamento dinamico, in questo modo:
CREATE OR ALTER FUNCTION HR.GetEmpsF ( @lastnamepattern AS NVARCHAR(50) ) RETURNS TABLE AS RETURN SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL; GO
Naturalmente, puoi fare in modo che la query esterna gestisca qualsiasi esigenza specifica di ordinazione, come nel codice seguente (la chiamerò Query 6):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY lastname;
Il piano per questa query è mostrato nella Figura 6.
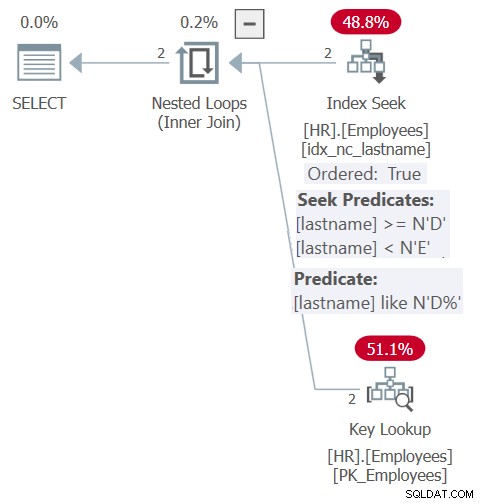 Figura 6:piano per la query 6
Figura 6:piano per la query 6
Grazie all'inline e all'incorporamento dei parametri, il piano è simile a quello mostrato in precedenza per la query della stored procedure nella figura 5. Il piano si basa in modo efficiente sull'indice sia per il filtraggio che per l'ordinamento. Tuttavia, non ottieni la flessibilità dell'input di ordinamento dinamico come avevi con la stored procedure. Devi essere esplicito con l'ordinamento nella clausola ORDER BY nella query sulla funzione.
L'esempio seguente ha una query sulla funzione senza filtri e senza requisiti di ordinamento (la chiamerò Query 7):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(NULL);
Il piano per questa query è mostrato nella Figura 7.
 Figura 7:Piano per la query 7
Figura 7:Piano per la query 7
Dopo l'inline e l'incorporamento dei parametri, la query viene semplificata in modo da non avere predicato di filtro né ordinamento e viene ottimizzata con una scansione completa non ordinata dell'indice cluster.
Infine, interroga la funzione con N'D%' come modello di filtraggio del cognome di input e ordina il risultato in base alla colonna del nome (farò riferimento a questo come Query 8):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY firstname;
Il piano per questa query è mostrato nella Figura 8.
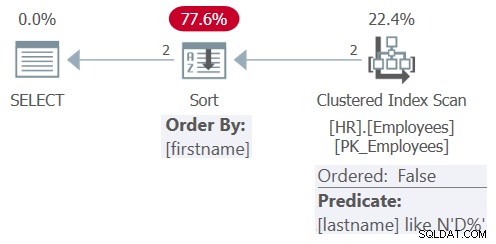 Figura 8:piano per la query 8
Figura 8:piano per la query 8
Dopo la semplificazione, la query coinvolge solo il predicato di filtraggio lastname LIKE N'D%' e l'elemento di ordinamento firstname. Questa volta l'ottimizzatore sceglie di applicare una scansione non ordinata dell'indice cluster, con il cognome del predicato residuo LIKE N'D%', seguito da un ordinamento esplicito. Ha scelto di non applicare una ricerca nell'indice sul cognome perché l'indice non è di copertura, la tabella è così piccola e l'ordinamento dell'indice non è vantaggioso per le attuali esigenze di ordinamento delle query. Inoltre, non c'è un indice definito nella colonna del nome, quindi è necessario applicare comunque un ordinamento esplicito.
Conclusione
L'ottimizzazione predefinita dell'incorporamento dei parametri di iTVF può anche comportare una piegatura costante, consentendo piani più ottimali. Tuttavia, devi essere consapevole delle regole di piegatura costanti per determinare come formulare al meglio le tue espressioni.
L'implementazione della logica in un iTVF presenta vantaggi e svantaggi rispetto all'implementazione della logica in una stored procedure. Se non sei interessato all'ottimizzazione dell'incorporamento dei parametri, l'ottimizzazione delle query con parametri predefinita delle stored procedure può comportare una memorizzazione nella cache del piano e un comportamento di riutilizzo più ottimali. Nei casi in cui sei interessato all'ottimizzazione dell'incorporamento dei parametri, in genere la ottieni per impostazione predefinita con iTVF. Per ottenere questa ottimizzazione con le stored procedure, è necessario aggiungere l'opzione di query RICOMPILE, ma in questo modo non otterrai il riutilizzo del piano. Almeno con iTVF, puoi ottenere il riutilizzo del piano a condizione che vengano ripetuti gli stessi valori dei parametri. Inoltre, hai meno flessibilità con gli elementi della query che puoi utilizzare in un iTVF; ad esempio, non ti è consentito avere una clausola ORDER BY di presentazione.
Tornando all'intera serie sulle espressioni di tabella, trovo che l'argomento sia estremamente importante per i professionisti del database. La serie più completa include le sottoserie sul generatore di serie numeriche, implementato come iTVF. In totale la serie comprende le seguenti 19 parti:
- Fondamenti di espressioni tabellari, Parte 1
- Fondamenti di espressioni di tabella, Parte 2 – Tabelle derivate, considerazioni logiche
- Fondamenti di espressioni di tabella, Parte 3 – Tabelle derivate, considerazioni sull'ottimizzazione
- Fondamenti di espressioni di tabella, parte 4 – Tabelle derivate, considerazioni sull'ottimizzazione, continua
- Fondamenti di espressioni tabellari, Parte 5 – CTE, considerazioni logiche
- Fondamenti di espressioni di tabella, Parte 6 – CTE ricorsive
- Fondamenti di espressioni di tabella, Parte 7 – CTE, considerazioni sull'ottimizzazione
- Fondamenti di espressioni di tabella, Parte 8 – CTE, considerazioni sull'ottimizzazione proseguite
- Nozioni fondamentali sulle espressioni di tabella, Parte 9 – Viste, confrontate con tabelle derivate e CTE
- Nozioni fondamentali sulle espressioni di tabella, Parte 10 – Viste, SELECT * e modifiche DDL
- Nozioni fondamentali sulle espressioni di tabella, parte 11 – Viste, considerazioni sulle modifiche
- Fondamenti di espressioni di tabella, parte 12 – Funzioni con valori di tabella inline
- Nozioni fondamentali sulle espressioni di tabella, parte 13 – Funzioni inline con valori di tabella, continua
- La sfida è iniziata! Chiamata comunitaria per la creazione del generatore di serie di numeri più veloce
- Soluzioni per la sfida dei generatori di serie numeriche – Parte 1
- Soluzioni per la sfida dei generatori di serie numerica – Parte 2
- Soluzioni per la sfida dei generatori di serie numerica – Parte 3
- Soluzioni per la sfida dei generatori di serie numerica – Parte 4
- Soluzioni per la sfida dei generatori di serie numerica – Parte 5