Introdotto per la prima volta in SQL Server 2017 Enterprise Edition, un accesso adattivo abilita una transizione di runtime da un join hash in modalità batch a un join indicizzato a cicli nidificati correlati in modalità riga (applica) in fase di runtime. Per brevità, farò riferimento a un "join indicizzato di loop nidificati correlati" come applicazione per tutto il resto di questo articolo. Se hai bisogno di un aggiornamento sulla differenza tra cicli nidificati e applica, consulta il mio articolo precedente.
La transizione di un join adattivo da un hash join all'applicazione in fase di esecuzione dipende da un valore denominato Righe di soglia adattive nella Partecipazione adattiva operatore del piano di esecuzione. Questo articolo mostra come funziona un join adattivo, include i dettagli del calcolo della soglia e copre le implicazioni di alcune delle scelte progettuali effettuate.
Introduzione
Una cosa che voglio che tu tenga a mente durante questo pezzo è un'unione adattiva sempre inizia l'esecuzione come hash join in modalità batch. Questo è vero anche se il piano di esecuzione indica che il join adattivo prevede di essere eseguito in modalità riga.
Come qualsiasi hash join, un join adattivo legge tutte le righe disponibili nel suo input di build e copia i dati richiesti in una tabella hash. La modalità batch di hash join archivia queste righe in un formato ottimizzato e le partiziona utilizzando una o più funzioni hash. Una volta che l'input di compilazione è stato consumato, la tabella hash è completamente popolata e partizionata, pronta per l'hash join per iniziare a controllare le corrispondenze delle righe lato sonda.
Questo è il punto in cui un join adattivo prende la decisione di procedere con l'hash join in modalità batch o di passare a una modalità riga. Se il numero di righe nella tabella hash è inferiore alla soglia valore, il join passa a un'applicazione; in caso contrario, il join continua come hash join iniziando a leggere le righe dall'input del probe.
Se si verifica una transizione a un join applicato, il piano di esecuzione non rilegge le righe utilizzate per popolare la tabella hash per guidare l'operazione di applicazione. Invece, un componente interno noto come lettore di buffer adattivo espande le righe già archiviate nella tabella hash e le rende disponibili su richiesta all'input esterno dell'operatore apply. C'è un costo associato al lettore di buffer adattivo, ma è molto inferiore al costo di riavvolgere completamente l'input di build.
Scelta di un join adattivo
L'ottimizzazione delle query prevede una o più fasi di esplorazione logica e implementazione fisica di alternative. In ogni fase, quando l'ottimizzatore esplora le opzioni fisiche per un logico join, potrebbe prendere in considerazione l'applicazione di alternative sia in modalità batch che in modalità riga.
Se una di queste opzioni di unione fisica fa parte della soluzione più economica trovata durante la fase corrente, e l'altro tipo di join può fornire le stesse proprietà logiche richieste:l'ottimizzatore contrassegna il gruppo di join logico come potenzialmente adatto per un join adattivo. In caso contrario, la considerazione di un join adattivo termina qui (e non viene attivato alcun evento esteso di join adattivo).
Il normale funzionamento dell'ottimizzatore significa che la soluzione più economica trovata includerà solo una delle opzioni di unione fisica, hash o apply, a seconda di quella con il costo stimato più basso. La prossima cosa che fa l'ottimizzatore è costruire e costare una nuova implementazione del tipo di join che non era scelto come più economico.
Poiché l'attuale fase di ottimizzazione è già terminata con una soluzione più economica trovata, viene eseguito uno speciale ciclo di esplorazione e implementazione a gruppo singolo per il join adattivo. Infine, l'ottimizzatore calcola la soglia adattativa .
Se uno dei lavori precedenti non va a buon fine, l'evento esteso adaptive_join_skipped viene attivato con un motivo.
Se l'elaborazione del join adattivo ha esito positivo, un Concat operatore viene aggiunto al piano interno sopra l'hash e applica alternative con il lettore di buffer adattivo e tutti gli adattatori in modalità batch/riga richiesti. Ricorda, solo una delle alternative di join verrà eseguita in fase di esecuzione, a seconda del numero di righe effettivamente incontrate rispetto alla soglia adattiva.
Il Concat l'operatore e le singole alternative di hash/applica normalmente non vengono mostrate nel piano di esecuzione finale. Ci viene invece presentato un unico Partecipazione adattiva operatore. Questa è solo una decisione di presentazione:il Concat e i join sono ancora presenti nel codice eseguito dal motore di esecuzione di SQL Server. Puoi trovare maggiori dettagli al riguardo nelle sezioni Appendice e Letture correlate di questo articolo.
La soglia adattativa
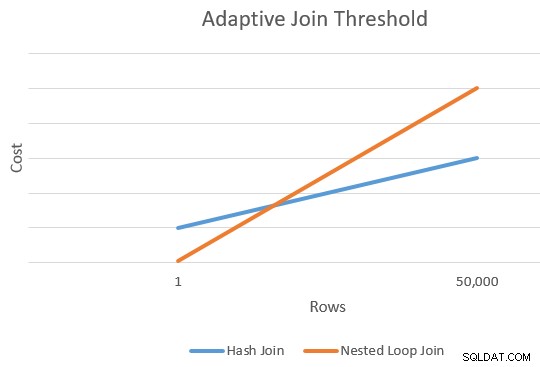
Un'applicazione è generalmente più economica di un hash join per un numero inferiore di righe guida. L'hash join ha un costo di avvio aggiuntivo per creare la sua tabella hash, ma un costo per riga inferiore quando inizia a cercare le corrispondenze.
In genere c'è un punto in cui il costo stimato di un'applicazione e di un hash join sarà uguale. Questa idea è stata ben illustrata da Joe Sack nel suo articolo, Introduzione ai join adattivi in modalità batch:
Calcolo della soglia
A questo punto, l'ottimizzatore ha un'unica stima per il numero di righe che entrano nell'input build dell'hash join e applica alternative. Ha anche il costo stimato dell'hash e applica gli operatori nel loro insieme.
Questo ci dà un singolo punto sul bordo estremo destro delle linee arancione e blu nel diagramma sopra. L'ottimizzatore ha bisogno di un altro punto di riferimento per ogni tipo di unione in modo che possa "tracciare le linee" e trovare l'intersezione (non disegna letteralmente le linee, ma ti viene l'idea).
Per trovare un secondo punto per le linee, l'ottimizzatore chiede ai due join di produrre una nuova stima dei costi basata su una diversa (e ipotetica) cardinalità di input. Se la prima stima della cardinalità era superiore a 100 righe, chiede ai join di stimare i nuovi costi per una riga. Se la cardinalità originale era inferiore o uguale a 100 righe, il secondo punto si basa su una cardinalità di input di 10.000 righe (quindi c'è un intervallo abbastanza decente da estrapolare).
In ogni caso, il risultato sono due diversi costi e conteggi di riga per ogni tipo di join, consentendo di "tracciare" le linee.
La formula dell'intersezione
Trovare l'intersezione di due rette in base a due punti per ciascuna retta è un problema con diverse soluzioni ben note. SQL Server ne usa uno basato su determinanti come descritto su Wikipedia:
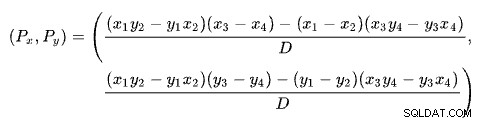
dove:
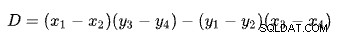
La prima riga è definita dai punti (x1 , y1 ) e (x2 , y2 ). La seconda riga è data dai punti (x3 , y3 ) e (x4 , y4 ). L'intersezione è a (Px , Py ).
Il nostro schema ha il numero di righe sull'asse x e il costo stimato sull'asse y. Ci interessa il numero di righe in cui le linee si intersecano. Questo è dato dalla formula per Px . Se volessimo conoscere il costo stimato all'incrocio, sarebbe Py .
Per Px righe, i costi stimati delle soluzioni apply e hash join sarebbero uguali. Questa è la soglia adattativa di cui abbiamo bisogno.
Un esempio funzionante
Ecco un esempio che utilizza il database di esempio AdventureWorks2017 e il seguente trucco di indicizzazione di Itzik Ben-Gan per ottenere una considerazione incondizionata dell'esecuzione in modalità batch:
-- Itzik's trick
CREATE NONCLUSTERED COLUMNSTORE INDEX BatchMode
ON Sales.SalesOrderHeader (SalesOrderID)
WHERE SalesOrderID = -1
AND SalesOrderID = -2;
-- Test query
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123; Il piano di esecuzione mostra un unione adattiva con una soglia di 1502,07 righe:
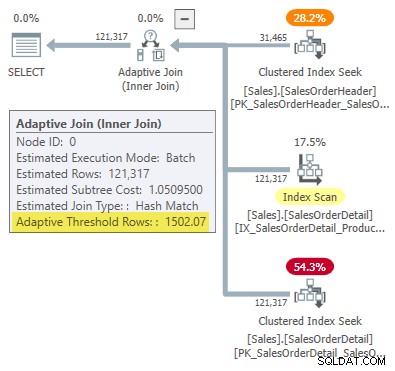
Il numero stimato di righe che guidano il join adattivo è 31.465 .
Costi di adesione
In questo caso semplificato, possiamo trovare i costi stimati del sottoalbero per l'hash e applicare alternative di join usando i suggerimenti:
-- Hash
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (HASH JOIN, MAXDOP 1);

-- Apply
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (LOOP JOIN, MAXDOP 1);
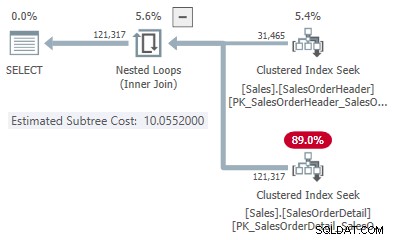
Questo ci dà un punto sulla linea per ogni tipo di unione:
- 31.465 righe
- Costo hash 1,05083
- Applica il costo 10,0552
Il secondo punto sulla linea
Poiché il numero stimato di righe è superiore a 100, i secondi punti di riferimento provengono da stime interne speciali basate su una riga di input di join. Sfortunatamente, non esiste un modo semplice per ottenere i numeri esatti dei costi per questo calcolo interno (ne parlerò di più a breve).
Per ora, ti mostrerò solo i numeri dei costi (usando la precisione interna completa anziché le sei cifre significative presentate nei piani di esecuzione):
- Una riga (calcolo interno)
- Costo hash 0,999027422729
- Applica il costo 0,547927305023
- 31.465 righe
- Costo hash 1.05082787359
- Applica il costo 10.0552890166
Come previsto, l'app join è più economico dell'hash per una cardinalità di input ridotta ma molto più costoso per la cardinalità prevista di 31.465 righe.
Il calcolo dell'intersezione
Inserendo questi numeri di cardinalità e costo nella formula di intersezione di linea ottieni quanto segue:
-- Hash points (x = cardinality; y = cost)
DECLARE
@x1 float = 1,
@y1 float = 0.999027422729,
@x2 float = 31465,
@y2 float = 1.05082787359;
-- Apply points (x = cardinality; y = cost)
DECLARE
@x3 float = 1,
@y3 float = 0.547927305023,
@x4 float = 31465,
@y4 float = 10.0552890166;
-- Formula:
SELECT Threshold =
(
(@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) -
(@x1 - @x2) * (@x3 * @y4 - @y3 * @x4)
)
/
(
(@x1 - @x2) * (@y3 - @y4) -
(@y1 - @y2) * (@x3 - @x4)
);
-- Returns 1502.06521571273 Arrotondato a sei cifre significative, questo risultato corrisponde a 1502,07 righe mostrate nel piano di esecuzione del join adattivo:
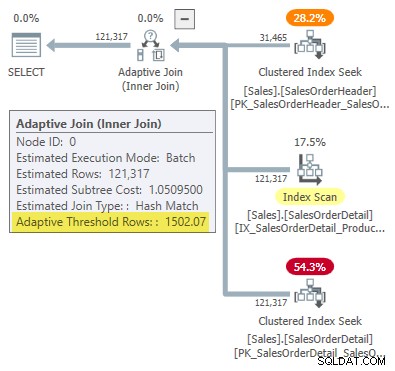
Difetto o design?
Ricorda, SQL Server ha bisogno di quattro punti per "disegnare" il conteggio delle righe rispetto alle righe di costo per trovare la soglia di join adattivo. Nel presente caso, ciò significa trovare stime dei costi per le cardinalità di una riga e 31.465 di riga sia per le implementazioni apply che per l'hash join.
L'ottimizzatore chiama una routine denominata sqllang!CuNewJoinEstimate per calcolare questi quattro costi per un join adattivo. Purtroppo, non ci sono flag di traccia o eventi estesi per fornire una panoramica pratica di questa attività. I normali flag di traccia utilizzati per analizzare il comportamento dell'ottimizzatore e visualizzare i costi non funzionano qui (consulta l'Appendice se sei interessato a maggiori dettagli).
L'unico modo per ottenere le stime dei costi di una riga è collegare un debugger e impostare un punto di interruzione dopo la quarta chiamata a CuNewJoinEstimate nel codice per sqllang!CardSolveForSwitch . Ho usato WinDbg per ottenere questo stack di chiamate su SQL Server 2019 CU12:

A questo punto del codice, i costi in virgola mobile a precisione doppia vengono archiviati in quattro posizioni di memoria a cui puntano gli indirizzi in rsp+b0 , rsp+d0 , rsp+30 e rsp+28 (dove rsp è un registro della CPU e gli offset sono in esadecimale):

I numeri di costo della sottostruttura dell'operatore visualizzati corrispondono a quelli utilizzati nella formula di calcolo della soglia di join adattivo.
Informazioni sulle stime dei costi di una riga
Potresti aver notato che i costi stimati del sottoalbero per i join di una riga sembrano piuttosto elevati per la quantità di lavoro necessaria per unire una riga:
- Una riga
- Costo hash 0,999027422729
- Applica il costo 0,547927305023
Se provi a produrre piani di esecuzione di input di una riga per l'hash join e ad applicare esempi, vedrai molto costi inferiori stimati del sottoalbero al join rispetto a quelli mostrati sopra. Allo stesso modo, l'esecuzione della query originale con un obiettivo di riga di uno (o il numero di righe di output join previste per un input di una riga) produrrà anche un costo stimato modo inferiore a quello mostrato.
Il motivo è il CuNewJoinEstimate la routine stima la una riga caso in un modo che penso che la maggior parte delle persone non troverebbe intuitivo.
Il costo finale è composto da tre componenti principali:
- Il costo della sottostruttura dell'input di compilazione
- Il costo locale dell'adesione
- Il costo della sottostruttura di input della sonda
Gli elementi 2 e 3 dipendono dal tipo di unione. Per un hash join, tengono conto del costo della lettura di tutte le righe dall'input del probe, della corrispondenza (o meno) con una riga nella tabella hash e del passaggio dei risultati all'operatore successivo. Per un'applicazione, i costi coprono una ricerca sull'input inferiore al join, il costo interno del join stesso e la restituzione delle righe corrispondenti all'operatore principale.
Niente di tutto ciò è insolito o sorprendente.
La sorpresa dei costi
La sorpresa arriva dal lato build del join (elemento 1 nell'elenco). Ci si potrebbe aspettare che l'ottimizzatore esegua dei calcoli fantasiosi per ridimensionare il costo della sottostruttura già calcolato per 31.465 righe fino a una riga media o qualcosa del genere.
In effetti, sia l'hash che le stime di join su una riga utilizzano semplicemente l'intero costo della sottostruttura per l'originale stima della cardinalità di 31.465 righe. Nel nostro esempio in esecuzione, questo "sottoalbero" è 0,54456 costo della ricerca dell'indice cluster in modalità batch nella tabella di intestazione:
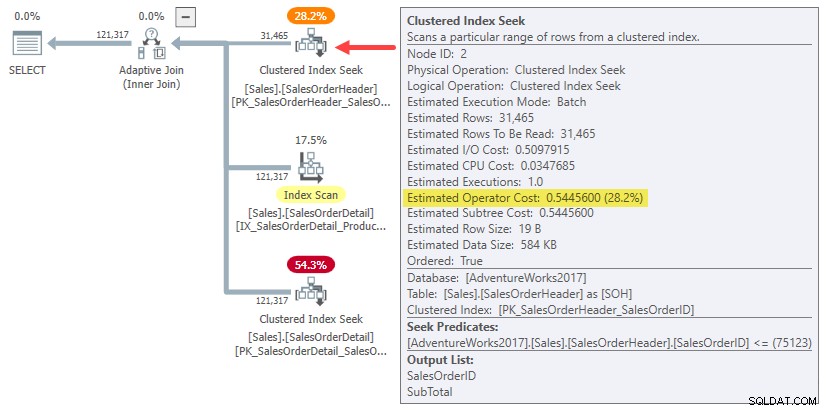
Per essere chiari:i costi stimati lato build per le alternative di join su una riga utilizzano un costo di input calcolato per 31.465 righe. Questo dovrebbe suonarti un po' strano.
Come promemoria, i costi di una riga calcolati da CuNewJoinEstimate erano i seguenti:
- Una riga
- Costo hash 0,999027422729
- Applica il costo 0,547927305023
Puoi vedere che il costo totale dell'applicazione (~0,54793) è dominato da 0,54456 costo del sottoalbero lato build, con un piccolo importo extra per la singola ricerca lato interno, l'elaborazione del numero ridotto di righe risultanti all'interno del join e il loro passaggio all'operatore padre.
Il costo stimato dell'hash join di una riga è maggiore perché il lato probe del piano consiste in un'analisi completa dell'indice, in cui tutte le righe risultanti devono passare attraverso il join. Il costo totale dell'hash join di una riga è leggermente inferiore al costo originale di 1,05095 per l'esempio di 31.465 righe perché ora c'è solo una riga nella tabella hash.
Implicazioni
Ci si aspetterebbe che una stima di join di una riga si basi, in parte, sul costo della fornitura di una riga all'input di guida del join. Come abbiamo visto, questo non è il caso di un join adattivo:sia l'applicazione che l'hash hanno il costo totale stimato di 31.465 righe. Il resto del join ha un costo più o meno come ci si aspetterebbe da un input di build di una riga.
Questa disposizione intuitivamente strana è il motivo per cui è difficile (forse impossibile) mostrare un piano di esecuzione che rispecchi i costi calcolati. Avremmo bisogno di costruire un piano che fornisca 31.465 righe all'input del join superiore ma che costringa il join stesso e il suo input interno come se fosse presente solo una riga. Una domanda difficile.
L'effetto di tutto questo è di alzare il punto più a sinistra del nostro diagramma a linee intersecanti sull'asse y. Ciò influisce sulla pendenza della linea e quindi sul punto di intersezione.
Un altro effetto pratico è che la soglia di unione adattiva calcolata ora dipende dalla stima della cardinalità originale all'input di build hash, come notato da Joe Obbish nel suo post sul blog del 2017. Ad esempio, se cambiamo WHERE clausola nella query di test su SOH.SalesOrderID <= 55000 , la soglia adattiva si riduce da 1502.07 a 1259.8 senza modificare l'hash del piano di query. Stesso piano, soglia diversa.
Ciò è dovuto al fatto che, come abbiamo visto, la stima dei costi interni di una riga dipende dal costo di input di costruzione per la stima della cardinalità originaria. Ciò significa che diverse stime iniziali sul lato build daranno un "boost" sull'asse y diverso alla stima di una riga. A sua volta, la linea avrà una diversa pendenza e un diverso punto di intersezione.
L'intuizione suggerirebbe che la stima di una riga per lo stesso join dovrebbe sempre dare lo stesso valore indipendentemente dall'altra stima di cardinalità sulla linea (dato che lo stesso identico join con le stesse proprietà e dimensioni delle righe ha una relazione quasi lineare tra la guida righe e costo). Questo non è il caso di un join adattivo.
In base alla progettazione?
Posso dirti con una certa sicurezza che cosa SQL Server fa quando si calcola la soglia di unione adattiva. Non ho informazioni particolari sul perché lo fa in questo modo.
Tuttavia, ci sono alcune ragioni per pensare che questa disposizione sia intenzionale e sia nata dopo la debita considerazione e il feedback dei test. Il resto di questa sezione copre alcuni dei miei pensieri su questo aspetto.
Un join adattivo non è una scelta diretta tra una normale applicazione e un hash join in modalità batch. Un join adattivo inizia sempre compilando completamente la tabella hash. Solo una volta completato questo lavoro viene presa la decisione di passare a un'implementazione Applica o meno.
A questo punto, abbiamo già sostenuto costi potenzialmente significativi popolando e partizionando l'hash join in memoria. Questo potrebbe non avere molta importanza per il caso di una riga, ma diventa progressivamente più importante all'aumentare della cardinalità. La "spinta" inaspettata può essere un modo per incorporare queste realtà nel calcolo mantenendo un costo di calcolo ragionevole.
Il modello di costo di SQL Server è stato a lungo un po' sbilanciato rispetto all'unione di cicli nidificati, probabilmente con qualche giustificazione. Anche il caso di applicazione indicizzato ideale può essere lento in pratica se i dati necessari non sono già in memoria e il sottosistema di I/O non è flash, specialmente con un modello di accesso alquanto casuale. Ad esempio, quantità limitate di memoria e I/O lenti non saranno del tutto sconosciuti agli utenti di motori di database basati su cloud di fascia bassa.
È possibile che test pratici in tali ambienti abbiano rivelato che un join adattivo dal costo intuitivo era troppo rapido per passare a un'applicazione. La teoria a volte è eccezionale solo in teoria.
Tuttavia, la situazione attuale non è l'ideale; la memorizzazione nella cache di un piano basato su una stima di cardinalità insolitamente bassa produrrà un join adattivo molto più riluttante a passare a un'applicazione rispetto a quanto sarebbe stato con una stima iniziale più ampia. Questa è una varietà del problema della sensibilità ai parametri, ma sarà una nuova considerazione di questo tipo per molti di noi.
Ora è anche possibile l'utilizzo del costo del sottoalbero di input di build completo per il punto più a sinistra delle linee di costo che si intersecano è semplicemente un errore o una svista non corretti. La mia sensazione è che l'attuale implementazione sia probabilmente un compromesso pratico deliberato, ma avresti bisogno di qualcuno con accesso ai documenti di progettazione e al codice sorgente per saperlo con certezza.
Riepilogo
Un join adattivo consente a SQL Server di passare da un join hash in modalità batch a un'applicazione dopo che la tabella hash è stata completamente popolata. Prende questa decisione confrontando il numero di righe nella tabella hash con una soglia adattiva precalcolata.
La soglia viene calcolata prevedendo dove i costi dell'applicazione e dell'hash join sono uguali. Per trovare questo punto, SQL Server produce una seconda stima dei costi di join interno per una cardinalità di input di build diversa, normalmente una riga.
Sorprendentemente, il costo stimato per la stima di una riga include l'intero costo della sottostruttura lato build per la stima di cardinalità originale (non ridimensionato a una riga). Ciò significa che il valore di soglia dipende dalla stima della cardinalità originale all'input di compilazione.
Di conseguenza, un join adattivo può avere un valore di soglia inaspettatamente basso, il che significa che è molto meno probabile che il join adattivo si allontani da un hash join. Non è chiaro se questo comportamento sia dovuto alla progettazione.
Lettura correlata
- Introduzione ai join adattivi in modalità batch di Joe Sack
- Informazioni sugli Adaptive Join nella documentazione del prodotto
- Adaptive Join Internals di Dima Pilugin
- Come funzionano i join adattivi in modalità batch? su Database Administrators Stack Exchange di Erik Darling
- An Adaptive Join Regression di Joe Obbish
- Se vuoi join adattivi, hai bisogno di indici più ampi e più grande è meglio? di Erik Darling
- Sniffing dei parametri:join adattivi di Brent Ozar
- Domande e risposte sull'elaborazione intelligente delle query di Joe Sack
Appendice
Questa sezione copre un paio di aspetti del join adattivo che erano difficili da includere nel testo principale in modo naturale.
Il piano adattivo esteso
Potresti provare a guardare una rappresentazione visiva del piano interno usando il flag di traccia non documentato 9415, come fornito da Dima Pilugin nel suo eccellente articolo sugli interni adattivi collegati sopra. Con questo flag attivo, il piano di join adattivo per il nostro esempio in esecuzione diventa il seguente:
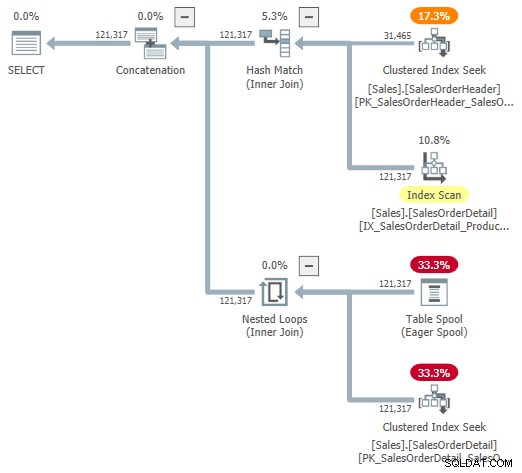
Questa è una rappresentazione utile per aiutare la comprensione, ma non è del tutto accurata, completa o coerente. Ad esempio, Table Spool non esiste:è una rappresentazione predefinita per il lettore buffer adattivo leggere le righe direttamente dalla tabella hash in modalità batch.
Anche le proprietà dell'operatore e le stime di cardinalità sono un po' dappertutto. L'output del lettore di buffer adattivo ("spool") dovrebbe essere 31.465 righe, non 121.317. Il costo della sottostruttura dell'applicazione è erroneamente limitato dal costo dell'operatore padre. Questo è normale per showplan, ma non ha senso in un contesto di join adattivo.
Ci sono anche altre incongruenze, troppe per essere elencate in modo utile, ma ciò può accadere con flag di traccia non documentati. Il piano ampliato mostrato sopra non è destinato all'uso da parte degli utenti finali, quindi forse non è del tutto sorprendente. Il messaggio qui è di non fare troppo affidamento sui numeri e sulle proprietà mostrati in questo modulo non documentato.
Dovrei anche menzionare di passaggio che l'operatore del piano di unione adattivo standard finito non è del tutto privo di problemi di coerenza. Questi derivano praticamente esclusivamente dai dettagli nascosti.
Ad esempio, le proprietà del join adattivo visualizzate provengono da una combinazione di Concat sottostante , Partecipa all'hash e Applica operatori. Puoi vedere un join adattivo che segnala l'esecuzione in modalità batch per i loop nidificati join (che è impossibile) e il tempo trascorso mostrato viene effettivamente copiato dal nascosto Concat , non il particolare join eseguito in fase di esecuzione.
I soliti sospetti
Noi possiamo ottenere alcune informazioni utili dai tipi di flag di traccia non documentati normalmente utilizzati per esaminare l'output dell'ottimizzatore. Ad esempio:
SELECT SOH.SubTotal
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SalesOrderID <= 75123
OPTION (
QUERYTRACEON 3604,
QUERYTRACEON 8607,
QUERYTRACEON 8612); Output (molto modificato per la leggibilità):
*** Albero di output:***PhyOp_ExecutionModeAdapter(BatchToRow) Card=121317 Costo=1,05095
- Carta PhyOp_Concat (batch)=121317 Costo=1.05325
- PhyOp_HashJoinx_jtInner (batch) Card=121317 Costo=1.05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Costo=0,54456
- Carta PhyOp_Filter(batch)=121317 Costo=0,397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Cost=0,338953
- PhyOp_ExecutionModeAdapter(RowToBatch) Card=121317 Costo=10.0798
- PhyOp_Apply Card=121317 Costo=10,0553
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Costo=0.544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cost=0,54456 [** 3 **]
- Carta PhyOp_Filter=3.85562 Costo=9.00356
- PhyOp_Range Sales.SalesOrderDetail Card=3,85562 Costo=8,94533
- PhyOp_ExecutionModeAdapter(BatchToRow) Card=31465 Costo=0.544623
- PhyOp_Apply Card=121317 Costo=10,0553
Ciò fornisce alcune informazioni sui costi stimati per il caso di cardinalità completa con hash e applica alternative senza scrivere query separate e utilizzare suggerimenti. Come menzionato nel testo principale, questi flag di traccia non sono attivi all'interno di CuNewJoinEstimate , quindi non possiamo visualizzare direttamente i calcoli ripetuti per il caso di 31.465 righe o nessuno dei dettagli per le stime di una riga in questo modo.
Unisci unione e unione hash modalità riga
I join adattivi offrono solo una transizione dall'hash join in modalità batch all'applicazione in modalità riga. Per i motivi per cui l'hash join in modalità riga non è supportato, vedere Domande e risposte sull'elaborazione intelligente delle query nella sezione Lettura correlata. In breve, si pensa che gli hash join in modalità riga siano troppo soggetti a regressioni delle prestazioni.
Il passaggio a una modalità riga unione di unione sarebbe un'altra opzione, ma l'ottimizzatore attualmente non lo considera. A quanto ho capito, è improbabile che venga ampliato in questa direzione in futuro.
Alcune delle considerazioni sono le stesse che valgono per l'hash join in modalità riga. Inoltre, i piani di merge join tendono ad essere meno facilmente intercambiabili con l'hash join, anche se ci limitiamo a unire join indicizzato (nessun ordinamento esplicito).
C'è anche una distinzione molto maggiore tra hash e apply rispetto a quella tra hash e merge. Sia l'hash che l'unione sono adatti per input più grandi e apply è più adatto a un input di guida più piccolo. Unisci join non è facilmente parallelizzabile come hash join e non si ridimensiona altrettanto bene con l'aumento del numero di thread.
Dato che la motivazione per i join adattivi è affrontare meglio in modo significativo dimensioni di input variabili e solo l'hash join supporta l'elaborazione in modalità batch:la scelta dell'hash batch rispetto all'applicazione di riga è quella più naturale. Infine, avere tre scelte di join adattive complicherebbe notevolmente il calcolo della soglia con un guadagno potenzialmente ridotto.