Nel post precedente, abbiamo discusso su come verificare che MySQL Replication sia in buone condizioni. Abbiamo anche esaminato alcuni dei problemi tipici. In questo post, daremo un'occhiata ad altri problemi che potresti riscontrare quando hai a che fare con la replica di MySQL.
Voci mancanti o duplicate
Questo è qualcosa che non dovrebbe accadere, eppure succede molto spesso - una situazione in cui un'istruzione SQL eseguita sul master ha successo ma la stessa istruzione eseguita su uno degli slave fallisce. Il motivo principale è la deriva dello slave:qualcosa (solitamente transazioni errate ma anche altri problemi o bug nella replica) fa sì che lo slave differisca dal suo master. Ad esempio, una riga che esisteva sul master non esiste su uno slave e non può essere cancellata o aggiornata. La frequenza con cui si presenta questo problema dipende principalmente dalle impostazioni di replica. In breve, ci sono tre modi in cui MySQL archivia gli eventi di log binari. In primo luogo, "istruzione", significa che SQL è scritto in testo normale, proprio come è stato eseguito su un master. Questa impostazione ha la più alta tolleranza sulla deriva dello slave, ma è anche quella che non può garantire la coerenza dello slave:è difficile consigliarne l'uso in produzione. Il secondo formato, "riga", memorizza il risultato della query anziché l'istruzione della query. Ad esempio, un evento potrebbe essere simile al seguente:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Ciò significa che stiamo aggiornando una riga nella tabella "tab" nello schema "test" in cui la prima colonna ha un valore di 2 e la seconda colonna ha un valore di 5. Impostiamo la prima colonna su 2 (il valore non cambia) e la seconda colonna a 4. Come puoi vedere, non c'è molto spazio per l'interpretazione:è definito con precisione quale riga viene utilizzata e come viene modificata. Di conseguenza, questo formato è ottimo per la coerenza degli schiavi ma, come puoi immaginare, è molto vulnerabile quando si tratta di deriva dei dati. È comunque il modo consigliato per eseguire la replica di MySQL.
Infine, il terzo, "misto", funziona in modo tale che quegli eventi che possono essere scritti in modo sicuro sotto forma di dichiarazioni utilizzino il formato "dichiarazione". Quelli che potrebbero causare la deriva dei dati utilizzeranno il formato "riga".
Come li rilevi?
Come al solito, SHOW SLAVE STATUS ci aiuterà a identificare il problema.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Come puoi vedere, gli errori sono chiari e autoesplicativi (e sono sostanzialmente identici tra MySQL e MariaDB.
Come risolvi il problema?
Questa è, purtroppo, la parte complessa. Prima di tutto, devi identificare una fonte di verità. Quale host contiene i dati corretti? Padrone o schiavo? Di solito daresti per scontato che sia il maestro ma non lo presumi per impostazione predefinita:indaga! Potrebbe essere che dopo il failover, una parte dell'applicazione ancora emessa scriva al vecchio master, che ora funge da slave. Potrebbe essere che read_only non sia stato impostato correttamente su quell'host o forse l'applicazione utilizza il superutente per connettersi al database (sì, l'abbiamo visto negli ambienti di produzione). In tal caso, lo schiavo potrebbe essere la fonte della verità, almeno in una certa misura.
A seconda di quali dati dovrebbero rimanere e quali dovrebbero andare, la migliore linea d'azione sarebbe identificare ciò che è necessario per sincronizzare la replica. Prima di tutto, la replica è interrotta, quindi è necessario occuparsi di questo. Accedi al master e controlla il log binario anche quello che ha causato l'interruzione della replica.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Come puoi vedere, perdiamo un evento:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Controlliamolo nei log binari del master:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Possiamo vedere che era un inserto che imposta la prima colonna su 3 e la seconda su 7. Verifichiamo come appare ora la nostra tabella:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Ora abbiamo due opzioni, a seconda di quali dati dovrebbero prevalere. Se i dati corretti sono sul master, possiamo semplicemente eliminare la riga con id=3 sullo slave. Assicurati solo di disabilitare la registrazione binaria per evitare di introdurre transazioni errate. D'altra parte, se abbiamo deciso che i dati corretti sono sullo slave, dobbiamo eseguire il comando REPLACE sul master per impostare la riga con id=3 per correggere il contenuto di (3, 10) dalla corrente (3, 7). Sullo slave, però, dovremo saltare il GTID corrente (o, per essere più precisi, dovremo creare un evento GTID vuoto) per poter riavviare la replica.
Eliminare una riga su uno slave è semplice:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Inserire un GTID vuoto è quasi altrettanto semplice:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Un altro metodo per risolvere questo particolare problema (a patto che accettiamo il master come fonte di verità) consiste nell'usare strumenti come pt-table-checksum e pt-table-sync per identificare dove lo slave non è coerente con il suo master e cosa SQL deve essere eseguito sul master per riportare lo slave in sincronia. Sfortunatamente, questo metodo è piuttosto pesante:viene aggiunto molto carico al master e un sacco di query vengono scritte nel flusso di replica che potrebbe influire sul ritardo sugli slave e sulle prestazioni generali dell'impostazione della replica. Ciò è particolarmente vero se è presente un numero significativo di righe che devono essere sincronizzate.
Infine, come sempre, puoi ricostruire il tuo slave utilizzando i dati del master:in questo modo puoi essere sicuro che lo slave verrà aggiornato con i dati più recenti e aggiornati. Questa, in realtà, non è necessariamente una cattiva idea:quando si parla di un numero elevato di righe da sincronizzare utilizzando pt-table-checksum/pt-table-sync, ciò comporta un sovraccarico significativo nelle prestazioni di replica, CPU e I/O complessivi carico e ore uomo richieste.
ClusterControl consente di ricostruire uno slave, utilizzando una nuova copia dei dati anagrafici.
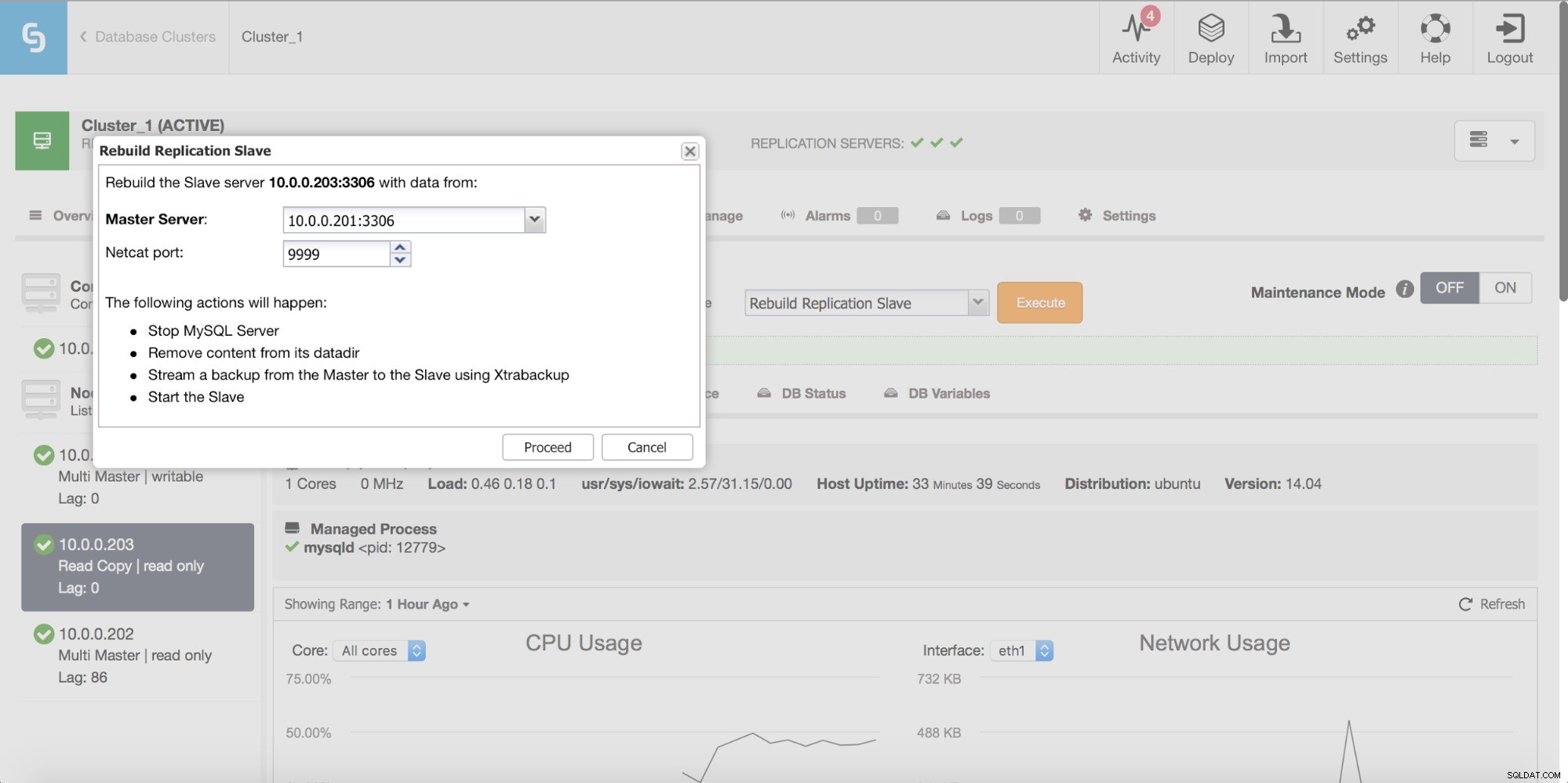
Verifiche di coerenza
Come accennato nel capitolo precedente, la coerenza può diventare un problema serio e causare molti mal di testa agli utenti che eseguono configurazioni di replica MySQL. Vediamo come puoi verificare che i tuoi slave MySQL siano sincronizzati con il master e cosa puoi fare al riguardo.
Come rilevare uno schiavo incoerente
Sfortunatamente, il modo tipico in cui un utente viene a sapere che uno slave è incoerente è imbattersi in uno dei problemi menzionati nel capitolo precedente. Per evitare che sia necessario un monitoraggio proattivo della coerenza degli slave. Vediamo come si può fare.
Utilizzeremo uno strumento di Percona Toolkit:pt-table-checksum. È progettato per eseguire la scansione del cluster di replica e identificare eventuali discrepanze.
Abbiamo costruito uno scenario personalizzato usando sysbench e abbiamo introdotto un po' di incoerenza su uno degli slave. Ciò che è importante (se desideri testarlo come abbiamo fatto noi), devi applicare una patch di seguito per forzare pt-table-checksum a riconoscere lo schema "sbtest" come schema non di sistema:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}All'inizio, eseguiremo pt-table-checksum nel modo seguente:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Un paio di note importanti su come abbiamo invocato lo strumento. Prima di tutto, l'utente che abbiamo impostato deve esistere su tutti gli slave. Se lo desideri, puoi anche utilizzare "--slave-user" per definire altri utenti meno privilegiati per accedere agli slave. Un'altra cosa che vale la pena spiegare:utilizziamo la replica basata su righe che non è completamente compatibile con pt-table-checksum. Se si dispone di una replica basata su righe, ciò che accade è che pt-table-checksum cambierà il formato del registro binario a livello di sessione in "istruzione" poiché questo è l'unico formato supportato. Il problema è che tale modifica funzionerà solo su un primo livello di slave che sono direttamente collegati a un master. Se hai master intermedi (quindi, più di un livello di slave), l'utilizzo di pt-table-checksum potrebbe interrompere la replica. Questo è il motivo per cui, per impostazione predefinita, se lo strumento rileva la replica basata su righe, esce e stampa un errore:
“La replica slave1 ha binlog_format ROW che potrebbe causare l'interruzione della replica da parte di pt-table-checksum. Leggere "Repliche che utilizzano la replica basata su riga" nella sezione LIMITAZIONI della documentazione dello strumento. Se comprendi i rischi, specifica --no-check-binlog-format per disabilitare questo controllo."
Abbiamo utilizzato un solo livello di slave, quindi era sicuro specificare "--no-check-binlog-format" e andare avanti.
Infine, impostiamo il ritardo massimo a 5 secondi. Se questa soglia verrà raggiunta, pt-table-checksum si fermerà per il tempo necessario a riportare il ritardo sotto la soglia.
Come puoi vedere dall'output,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2è stata rilevata un'incoerenza nella tabella sbtest.sbtest2.
Per impostazione predefinita, pt-table-checksum memorizza i checksum nella tabella percona.checksums. Questi dati possono essere utilizzati per un altro strumento di Percona Toolkit, pt-table-sync, per identificare quali parti della tabella devono essere controllate in dettaglio per trovare la differenza esatta nei dati.
Come risolvere lo slave incoerente
Come accennato in precedenza, useremo pt-table-sync per farlo. Nel nostro caso utilizzeremo i dati raccolti da pt-table-checksum sebbene sia anche possibile puntare pt-table-sync a due host (il master e uno slave) e confronterà tutti i dati su entrambi gli host. È sicuramente un processo che richiede più tempo e risorse, quindi, purché tu abbia già i dati da pt-table-checksum, è molto meglio usarlo. Ecco come l'abbiamo eseguito per testare l'output:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Come puoi vedere, di conseguenza è stato generato del codice SQL. Importante da notare è --replicate variabile. Quello che succede qui è che puntiamo pt-table-sync alla tabella generata da pt-table-checksum. Lo indichiamo anche al maestro.
Per verificare se SQL ha senso abbiamo usato l'opzione --print. Tieni presente che l'SQL generato è valido solo nel momento in cui viene generato:non puoi davvero memorizzarlo da qualche parte, esaminarlo e quindi eseguirlo. Tutto quello che puoi fare è verificare se l'SQL ha un senso e, subito dopo, rieseguire lo strumento con --execute flag:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeQuesto dovrebbe riportare lo slave in sincronia con il master. Possiamo verificarlo con pt-table-checksum:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Come puoi vedere, non ci sono più differenze nella tabella sbtest.sbtest2.
Ci auguriamo che tu abbia trovato questo post del blog informativo e utile. Fare clic qui per ulteriori informazioni sulla replica di MySQL. Se hai domande o suggerimenti, non esitare a contattarci tramite i commenti qui sotto.



