La replica è uno dei modi più comuni per ottenere un'elevata disponibilità per MySQL e MariaDB. È diventato molto più robusto con l'aggiunta di GTID ed è stato testato a fondo da migliaia e migliaia di utenti. MySQL Replication non è una proprietà "imposta e dimentica", tuttavia, deve essere monitorata per potenziali problemi e mantenuta in modo che rimanga in buone condizioni. In questo post del blog, vorremmo condividere alcuni suggerimenti e trucchi su come mantenere, risolvere e risolvere i problemi con la replica di MySQL.
Come determinare se la replica MySQL è in buone condizioni?
Questa è senza dubbio l'abilità più importante che chiunque si occupi di una configurazione di replica di MySQL deve possedere. Diamo un'occhiata a dove cercare informazioni sullo stato di replica. C'è una leggera differenza tra MySQL e MariaDB e ne parleremo anche.
MOSTRA LO STATO SLAVE
Questo è senza dubbio il metodo più comune per controllare lo stato della replica su un host slave:è con noi da sempre e di solito è il primo posto in cui andiamo se ci aspettiamo che ci siano problemi con la replica.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Alcuni dettagli possono differire tra MySQL e MariaDB, ma la maggior parte del contenuto avrà lo stesso aspetto. Le modifiche saranno visibili nella sezione GTID poiché MySQL e MariaDB lo fanno in un modo diverso. Da SHOW SLAVE STATUS, puoi ricavare alcune informazioni - quale master viene utilizzato, quale utente e quale porta viene utilizzata per connettersi al master. Abbiamo alcuni dati sull'attuale posizione del log binario (non più così importante poiché possiamo usare GTID e dimenticare i binlog) e lo stato dei thread di replica SQL e I/O. Quindi puoi vedere se e come è configurato il filtro. Puoi anche trovare alcune informazioni su errori, ritardo di replica, impostazioni SSL e GTID. L'esempio sopra viene dallo slave MySQL 5.7 che è in uno stato integro. Diamo un'occhiata ad alcuni esempi in cui la replica è interrotta.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Questo esempio è tratto da MariaDB 10.1, puoi vedere le modifiche nella parte inferiore dell'output per farlo funzionare con i GTID di MariaDB. Ciò che è importante per noi è l'errore:puoi vedere che qualcosa non va nel thread SQL:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Discuteremo questo particolare problema più avanti, per ora è sufficiente vedere come verificare se ci sono errori nella replica utilizzando SHOW SLAVE STATUS.
Un'altra informazione importante che deriva da SHOW SLAVE STATUS è:quanto gravemente è in ritardo il nostro schiavo. Puoi verificarlo nella colonna "Seconds_Behind_Master". Questa metrica è particolarmente importante da monitorare se sai che la tua applicazione è sensibile quando si tratta di letture non aggiornate.
In ClusterControl puoi tenere traccia di questi dati nella sezione "Panoramica":
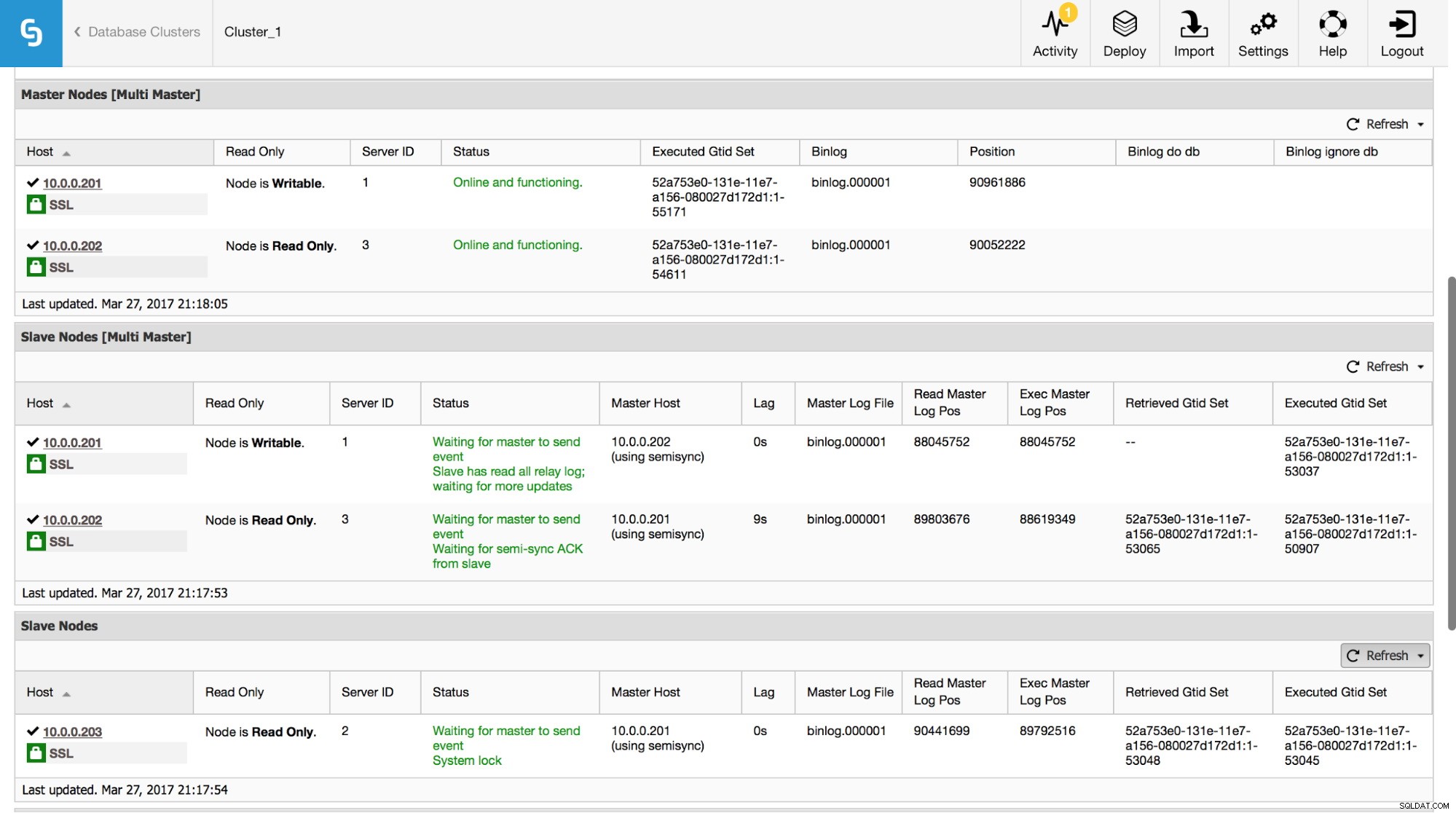
Abbiamo reso visibili tutte le informazioni più importanti dal comando SHOW SLAVE STATUS. È possibile controllare lo stato della replica, chi è il master, se c'è un ritardo di replica o meno, posizioni del log binario. Puoi anche trovare GTID recuperati ed eseguiti.
Schema delle prestazioni
Un altro posto in cui puoi cercare le informazioni sulla replica è performance_schema. Questo vale solo per MySQL 5.7 di Oracle:le versioni precedenti e MariaDB non raccolgono questi dati.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Di seguito puoi trovare alcuni esempi di dati disponibili in alcune di queste tabelle.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Come puoi vedere, possiamo verificare lo stato della replica, l'ultimo errore, il set di transazioni ricevuto e alcuni altri dati. Ciò che è importante:se hai abilitato la replica multi-thread, nella tabella replication_applier_status_by_worker vedrai lo stato di ogni singolo lavoratore:questo ti aiuta a comprendere lo stato della replica per ciascuno dei thread di lavoro.
Ritardo di replica
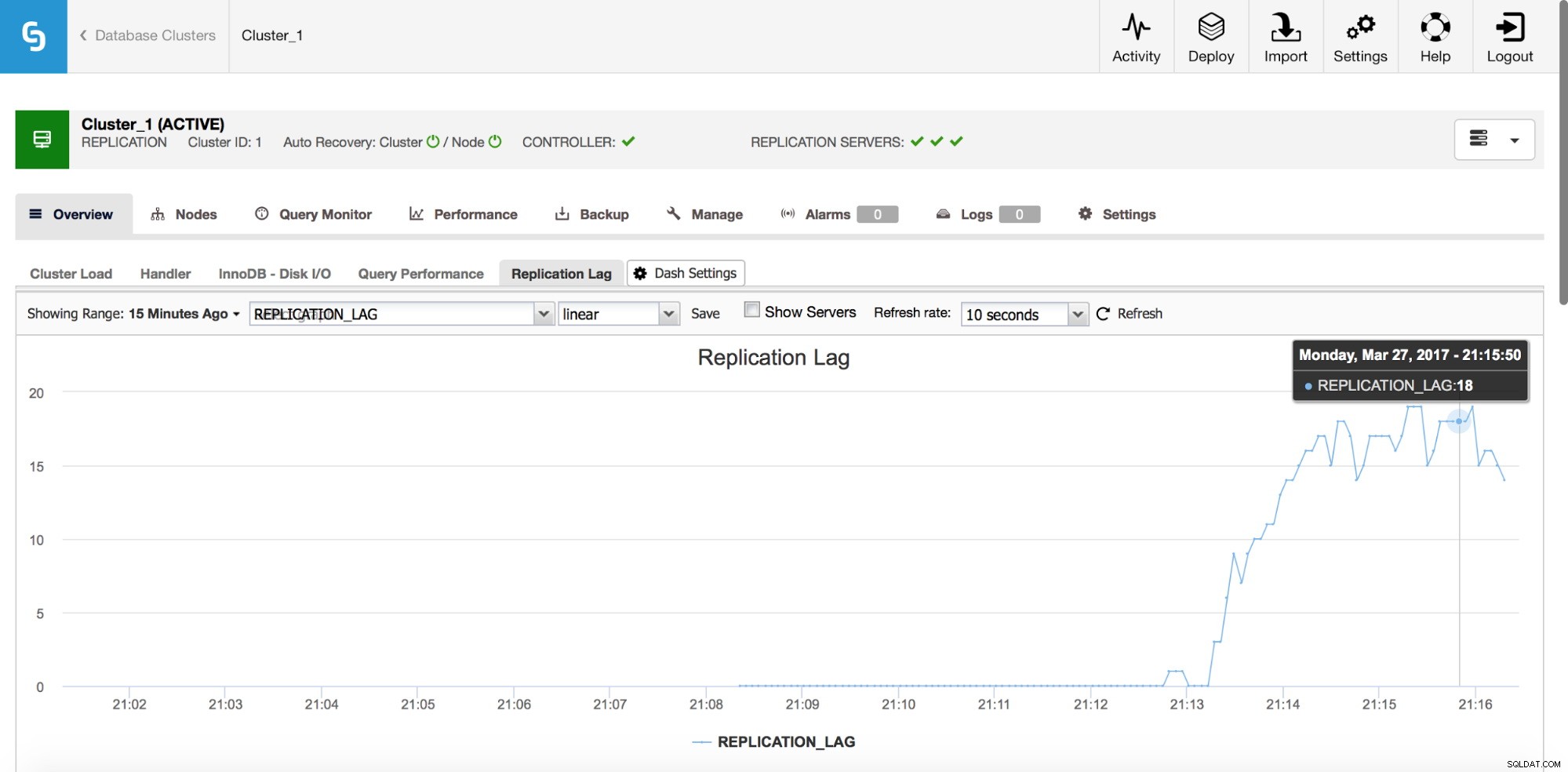
Il ritardo è sicuramente uno dei problemi più comuni che dovrai affrontare quando lavori con la replica di MySQL. Il ritardo di replica si verifica quando uno degli slave non è in grado di tenere il passo con la quantità di operazioni di scrittura eseguite dal master. I motivi potrebbero essere diversi:diversa configurazione hardware, carico più pesante sullo slave, alto grado di parallelizzazione della scrittura sul master che deve essere serializzato (quando si utilizza un thread singolo per la replica) o le scritture non possono essere parallelizzate nella stessa misura in cui ha stato sul master (quando utilizzi la replica multi-thread).
Come rilevarlo?
Esistono due metodi per rilevare il ritardo di replica. Prima di tutto, puoi selezionare "Seconds_Behind_Master" nell'output SHOW SLAVE STATUS - ti dirà se lo slave è in ritardo o meno. Funziona bene nella maggior parte dei casi, ma nelle topologie più complesse, quando si utilizzano master intermedi, su host in un punto basso nella catena di replica, potrebbe non essere preciso. Un'altra soluzione migliore è affidarsi a strumenti esterni come pt-heartbeat. L'idea è semplice:viene creata una tabella con, tra l'altro, una colonna timestamp. Questa colonna viene aggiornata sul master a intervalli regolari. Su uno slave, puoi quindi confrontare il timestamp di quella colonna con l'ora corrente:ti dirà quanto è indietro lo slave.
Indipendentemente dal modo in cui calcoli il ritardo, assicurati che i tuoi host siano sincronizzati nel tempo. Usa ntpd o altri mezzi per sincronizzare il tempo:se c'è una deriva temporale, vedrai un ritardo "falso" sui tuoi slave.
Come ridurre il ritardo?
Questa non è una domanda facile a cui rispondere. In breve, dipende da cosa sta causando il ritardo e da cosa è diventato un collo di bottiglia. Esistono due modelli tipici:lo slave è legato all'I/O, il che significa che il suo sottosistema I/O non è in grado di far fronte alla quantità di operazioni di scrittura e lettura. Secondo:lo slave è vincolato alla CPU, il che significa che il thread di replica utilizza tutta la CPU possibile (un thread può utilizzare solo un core della CPU) e non è ancora sufficiente per gestire tutte le operazioni di scrittura.
Quando la CPU è un collo di bottiglia, la soluzione può essere semplice come utilizzare la replica multi-thread. Aumentare il numero di thread di lavoro per consentire una maggiore parallelizzazione. Tuttavia non è sempre possibile - in tal caso potresti voler giocare un po' con le variabili di commit di gruppo (sia per MySQL che per MariaDB) per ritardare i commit per un leggero periodo di tempo (stiamo parlando di millisecondi qui) e, in questo modo , aumentare la parallelizzazione dei commit.
Se il problema è nell'I/O, il problema è un po' più difficile da risolvere. Ovviamente, dovresti rivedere le tue impostazioni I/O di InnoDB - forse c'è spazio per miglioramenti. Se my.cnf tuning non ti aiuta, non hai molte opzioni:migliora le tue query (ove possibile) o aggiorna il tuo sottosistema I/O a qualcosa di più capace.
La maggior parte dei proxy (ad esempio, tutti i proxy che possono essere distribuiti da ClusterControl:ProxySQL, HAProxy e MaxScale) offrono la possibilità di rimuovere uno slave dalla rotazione se il ritardo di replica supera una soglia predefinita. Questo non è affatto un metodo per ridurre il ritardo, ma può essere utile per evitare letture obsolete e, come effetto collaterale, per ridurre il carico su uno slave che dovrebbe aiutarlo a recuperare il ritardo.
Naturalmente, l'ottimizzazione delle query può essere una soluzione in entrambi i casi:è sempre utile migliorare le query che richiedono un elevato carico di CPU o I/O.
Transazioni errate
Le transazioni errate sono transazioni eseguite solo su uno slave, non sul master. Insomma, fanno uno schiavo incoerente con il padrone. Quando si utilizza la replica basata su GTID, ciò può causare seri problemi se lo slave viene promosso a master. Abbiamo un post approfondito su questo argomento e ti invitiamo a esaminarlo e a familiarizzare con come rilevare e risolvere i problemi con le transazioni errate. Sono state incluse anche informazioni su come ClusterControl rileva e gestisce le transazioni errate.
Nessun file Binlog sul Master
Come identificare il problema?
In alcune circostanze, può accadere che uno slave si connetta a un master e richieda un file di registro binario inesistente. Una delle ragioni potrebbe essere la transazione errata:a un certo punto, una transazione è stata eseguita su uno slave e in seguito questo slave diventa un master. Altri host, che sono configurati per assolvere a quel master, chiederanno la transazione mancante. Se è stato eseguito molto tempo fa, è possibile che i file di registro binari siano già stati eliminati.
Un altro esempio più tipico:si desidera eseguire il provisioning di uno slave utilizzando xtrabackup. Si copia il backup su un host, si applica il registro, si cambia il proprietario della directory dei dati di MySQL:operazioni tipiche che si eseguono per ripristinare un backup. Tu esegui
SET GLOBAL gtid_purged=in base ai dati di xtrabackup_binlog_info ed esegui CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (questo è in MySQL, MariaDB ha un processo leggermente diverso), avvia lo slave e poi finisci con un errore come:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'in MySQL o:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'in MariaDB.
Ciò significa sostanzialmente che il master non ha tutti i registri binari necessari per eseguire tutte le transazioni mancanti. Molto probabilmente, il backup è troppo vecchio e il master ha già eliminato alcuni dei log binari creati tra il momento in cui è stato creato il backup e il momento in cui è stato eseguito il provisioning dello slave.
Come risolvere questo problema?
Sfortunatamente, non c'è molto che puoi fare in questo caso particolare. Se disponi di alcuni host MySQL che memorizzano i log binari per un tempo più lungo rispetto al master, puoi provare a utilizzare quei log per riprodurre le transazioni mancanti sullo slave. Diamo un'occhiata a come si può fare.
Prima di tutto, diamo un'occhiata al GTID più vecchio nei log binari del master:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Quindi, "binlog.000021" è l'ultimo (e unico) file. Controlliamo qual è la prima voce GTID in questo file:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Come possiamo vedere, la voce di log binario più vecchia disponibile è:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Dobbiamo anche verificare qual è l'ultimo GTID coperto nel backup:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
È:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666 quindi mancano due eventi:
5d1e2227-07c6-11e7-8123-080027495a77:1106667-1106668
Vediamo se riusciamo a trovare quelle transazioni su altri slave.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Sembra che "binlog.000003" sia l'ultimo registro binario. Dobbiamo verificare se i nostri GTID mancanti possono essere trovati in esso:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Tieni presente che potresti voler copiare i file binlog al di fuori del server di produzione poiché elaborarli può aggiungere del carico. Dopo aver verificato l'esistenza di tali GTID, possiamo estrarli:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlDopo un rapido scp, possiamo applicare quegli eventi sullo slave
slave1:~# mysql -ppass < to_apply_on_slave1.sqlUna volta fatto, possiamo verificare se quei GTID sono stati applicati esaminando l'output di SHOW SLAVE STATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set sembra buono, quindi possiamo avviare thread slave:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Controlliamo se ha funzionato bene. Useremo, ancora una volta, l'output SHOW SLAVE STATUS:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Sembra buono, è installato e funzionante!
Un altro metodo per risolvere questo problema sarà eseguire un backup ancora una volta ed eseguire nuovamente il provisioning dello slave, utilizzando nuovi dati. Questo sarà molto probabilmente più veloce e sicuramente più affidabile. Non capita spesso di avere politiche di eliminazione binlog diverse su master e slave)
Continueremo a discutere di altri tipi di problemi di replica nel prossimo post del blog.