Per anni, la replica di MySQL si è basata su eventi di log binari:tutto ciò che uno slave sapeva era l'evento esatto e la posizione esatta che aveva appena letto dal master. Qualsiasi singola transazione da un master potrebbe essere terminata in registri binari diversi e in posizioni diverse in questi registri. Era una soluzione semplice con limitazioni:modifiche alla topologia più complesse potevano richiedere a un amministratore di interrompere la replica sugli host coinvolti. Oppure queste modifiche potrebbero causare altri problemi, ad esempio, uno slave non potrebbe essere spostato lungo la catena di replica senza un lungo processo di ricostruzione (non potremmo cambiare facilmente la replica da A -> B -> C ad A -> C -> B senza interrompere la replicazione sia su B che su C). Abbiamo tutti dovuto aggirare queste limitazioni mentre sognavamo un identificatore di transazione globale.
GTID è stato introdotto insieme a MySQL 5.6 e ha portato alcuni importanti cambiamenti nel modo in cui MySQL opera. Innanzitutto, ogni transazione ha un identificatore univoco che la identifica allo stesso modo su ogni server. Non è più importante in quale posizione del log binario è stata registrata una transazione, tutto ciò che devi sapere è il GTID:"966073f3-b6a4-11e4-af2c-080027880ca6:4". GTID è composto da due parti:l'identificatore univoco di un server in cui è stata eseguita una transazione per la prima volta e un numero di sequenza. Nell'esempio sopra, possiamo vedere che la transazione è stata eseguita dal server con server_uuid di "966073f3-b6a4-11e4-af2c-080027880ca6" ed è la 4a transazione eseguita lì. Queste informazioni sono sufficienti per eseguire complesse modifiche alla topologia:MySQL sa quali transazioni sono state eseguite e quindi sa quali transazioni devono essere eseguite successivamente. Dimentica i log binari, è tutto nel GTID.
Allora, dove puoi trovare i GTID? Li troverai in due posti. Su uno slave, in "mostra stato slave;" troverai due colonne:Retrieved_Gtid_Set ed Executed_Gtid_Set. Il primo copre i GTID che sono stati recuperati dal master tramite replica, il secondo informa su tutte le transazioni eseguite su un determinato host, sia tramite replica che eseguite localmente.
Configurare un cluster di replica in modo semplice
La distribuzione del cluster di replica MySQL è molto semplice in ClusterControl (puoi provarlo gratuitamente). L'unico prerequisito è che tutti gli host, che utilizzerai per distribuire i nodi MySQL, siano accessibili dall'istanza ClusterControl utilizzando una connessione SSH senza password.
Quando la connettività è attiva, puoi distribuire un cluster utilizzando l'opzione "Distribuisci". Quando la finestra della procedura guidata è aperta, devi prendere un paio di decisioni:cosa vuoi fare? Distribuire un nuovo cluster? Distribuisci un nodo Postgresql o importa un cluster esistente.
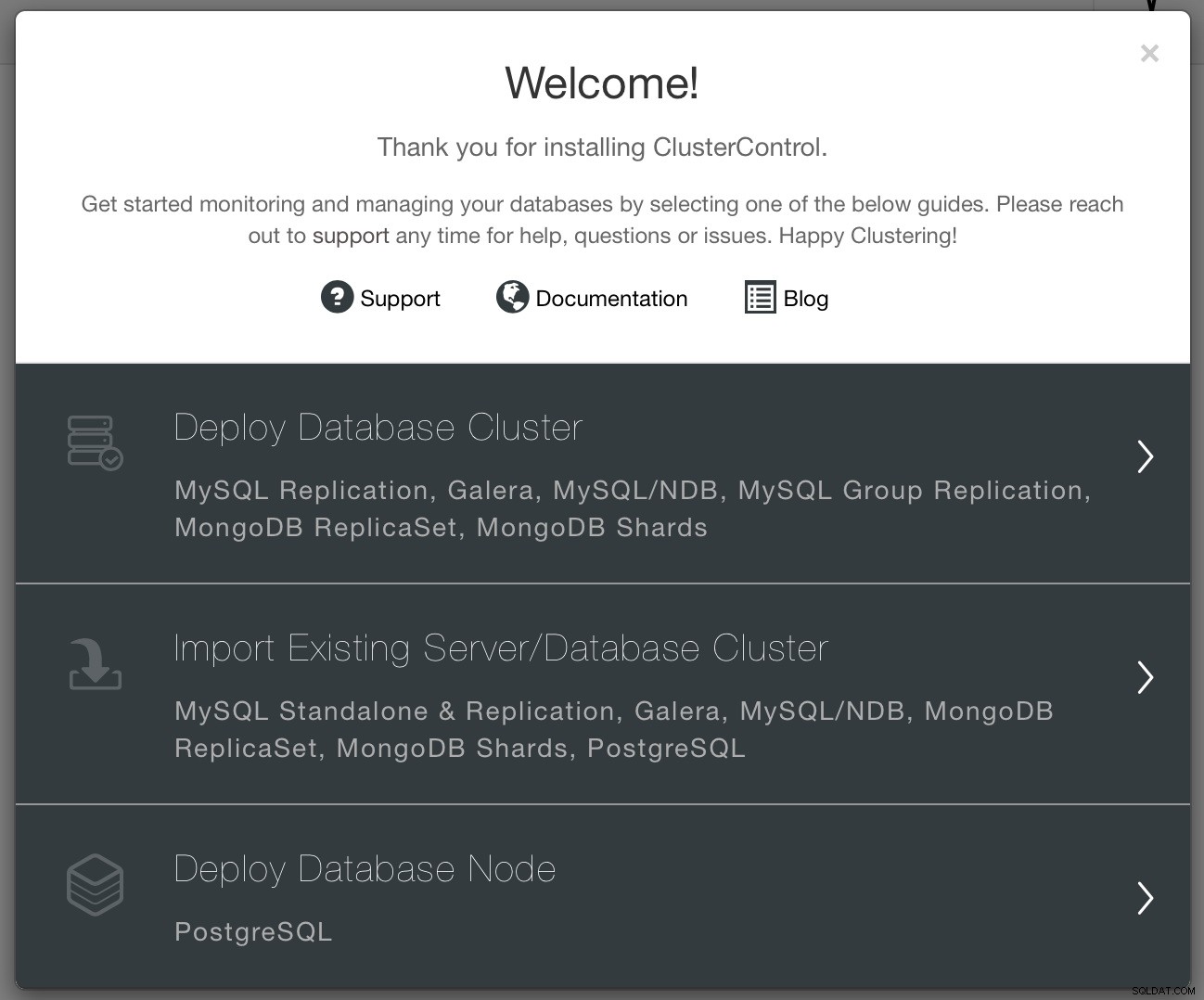
Vogliamo distribuire un nuovo cluster. Ci verrà quindi presentata la schermata seguente in cui dobbiamo decidere quale tipo di cluster vogliamo distribuire. Scegliamo la replica e quindi passiamo i dettagli richiesti sulla connettività ssh.
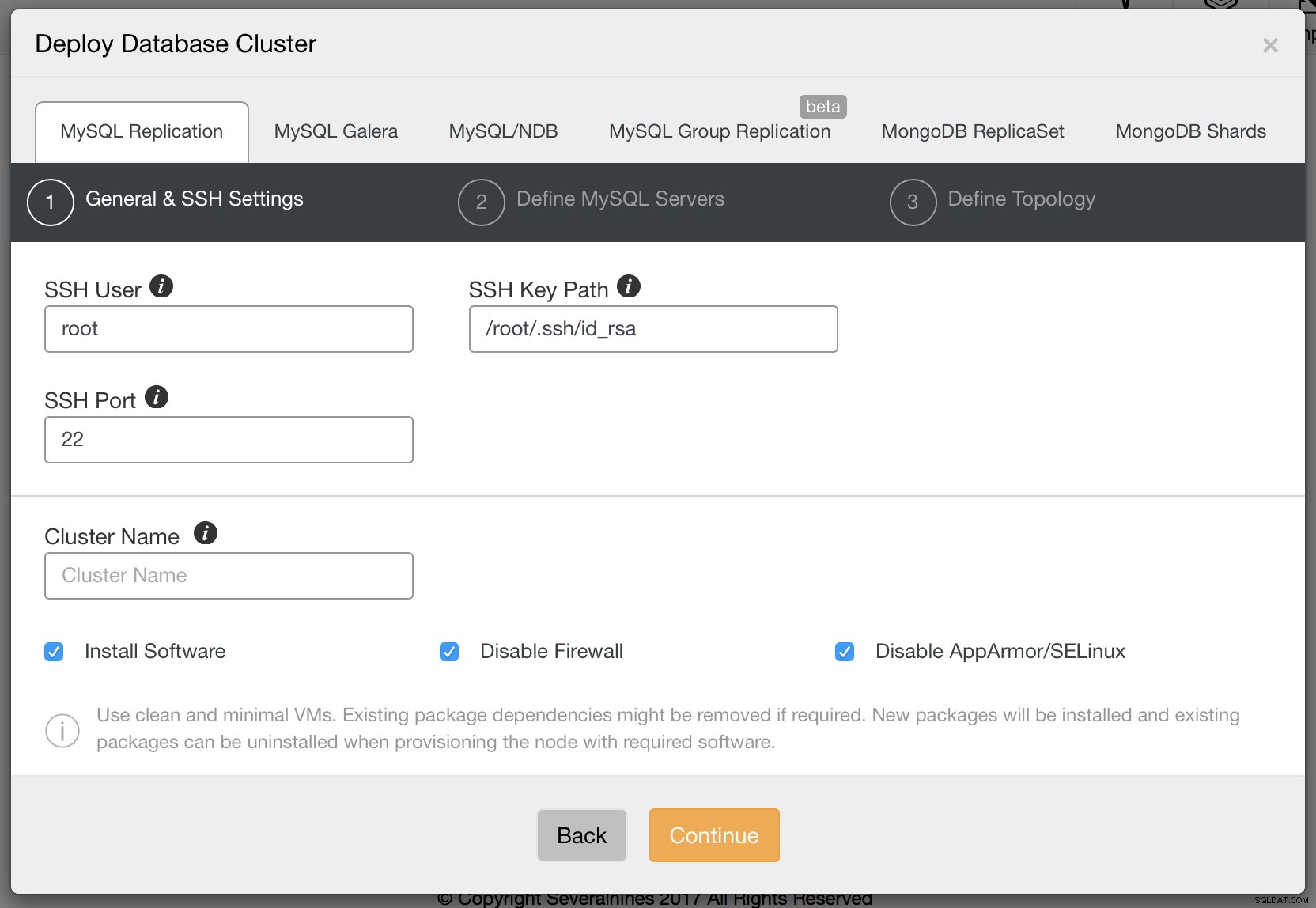
Quando sei pronto, fai clic su Continua. Questa volta dobbiamo decidere quale fornitore di MySQL vorremmo utilizzare, quale versione e un paio di impostazioni di configurazione tra cui, tra le altre, la password per l'account di root in MySQL.
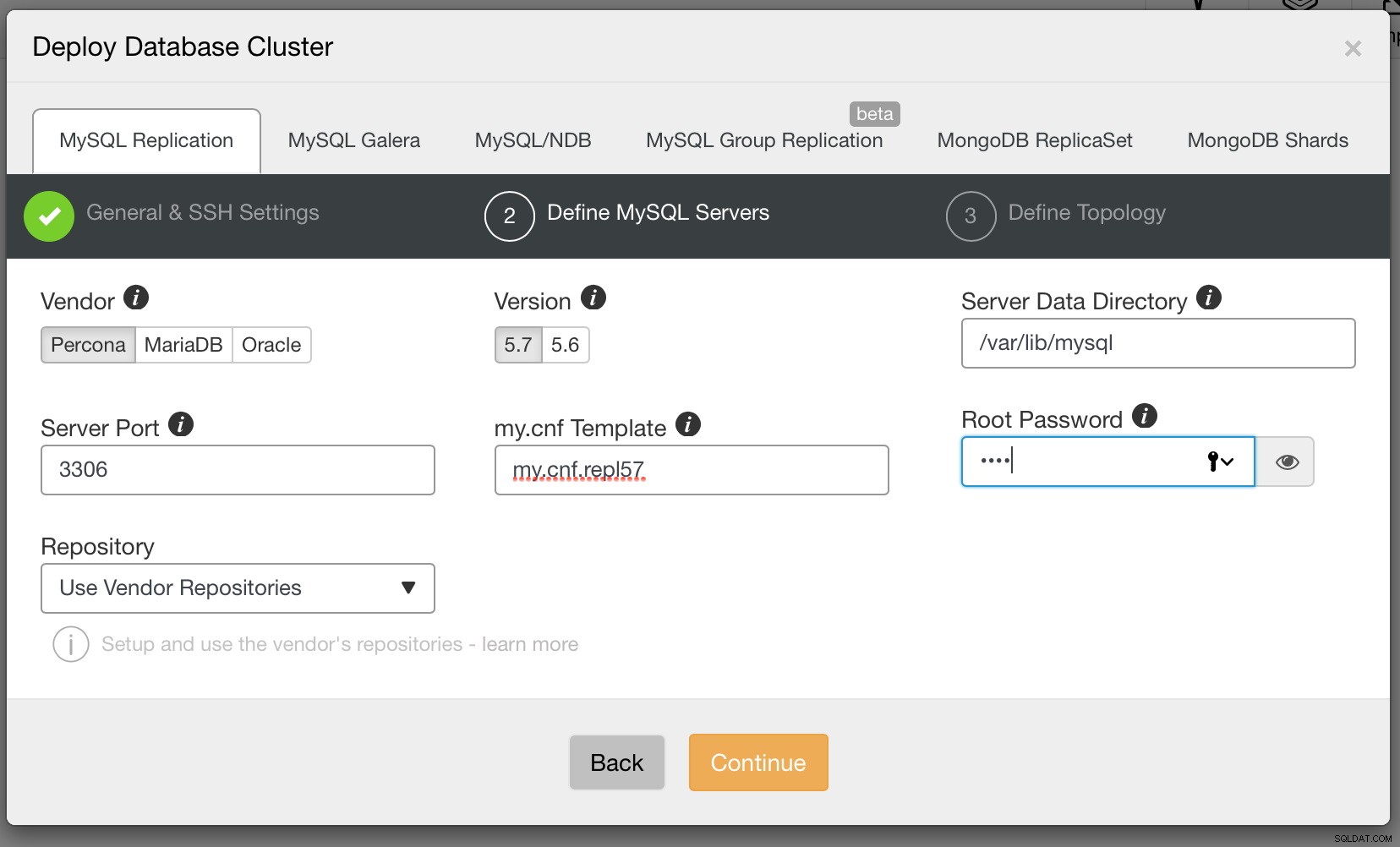
Infine, dobbiamo decidere la topologia di replica:è possibile utilizzare una tipica configurazione master - slave o creare una coppia più complessa, attiva - master in standby - master (+ slave se si desidera aggiungerli). Una volta pronto, fai clic su "Distribuisci" e in un paio di minuti dovresti avere il tuo cluster distribuito.
Al termine, vedrai il tuo cluster nell'elenco dei cluster dell'interfaccia utente di ClusterControl.
Avendo la replica attiva e funzionante, possiamo dare un'occhiata più da vicino a come funziona GTID.
Transazioni errate:qual è il problema?
Come accennato all'inizio di questo post, GTID ha portato un cambiamento significativo nel modo in cui le persone dovrebbero pensare alla replica di MySQL. È tutta una questione di abitudini. Diciamo, per qualche motivo, che un'applicazione ha eseguito una scrittura su uno degli slave. Non sarebbe dovuto succedere ma, sorprendentemente, succede sempre. Di conseguenza, la replica si interrompe con un errore di chiave duplicata. Ci sono un paio di modi per affrontare tale problema. Uno di questi sarebbe eliminare la riga incriminata e riavviare la replica. Un altro sarebbe saltare l'evento del registro binario e quindi riavviare la replica.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Entrambi i metodi dovrebbero ripristinare il funzionamento della replica, ma possono introdurre una deriva dei dati, quindi è necessario ricordare che la coerenza degli slave dovrebbe essere verificata dopo tale evento (pt-table-checksum e pt-table-sync funzionano bene qui).
Se si verifica un problema simile durante l'utilizzo di GTID, noterai alcune differenze. Potrebbe sembrare che l'eliminazione della riga incriminata risolva il problema, la replica dovrebbe essere in grado di iniziare. L'altro metodo, l'utilizzo di sql_slave_skip_counter non funzionerà affatto:restituirà un errore. Ricorda, ora non si tratta di eventi binlog, ma di GTID che viene eseguito o meno.
Perché eliminare la riga solo "sembra" risolvere il problema? Una delle cose più importanti da tenere a mente riguardo a GTID è che uno slave, quando si connette al master, controlla se mancano delle transazioni che sono state eseguite sul master. Queste sono chiamate transazioni errate. Se uno schiavo trova tali transazioni, le eseguirà. Supponiamo di aver eseguito seguendo SQL per cancellare una riga offensiva:
DELETE FROM mytable WHERE id=100;Controlliamo mostra lo stato slave:
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,E guarda da dove viene 84d15910-b6a4-11e4-af2c-080027880ca6:1:
mysql> SHOW VARIABLES LIKE 'server_uuid'\G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)Come puoi vedere, abbiamo 29 transazioni provenienti dal master, UUID di 966073f3-b6a4-11e4-af2c-080027880ca6 e una che è stata eseguita localmente. Diciamo che ad un certo punto facciamo il failover e il master (966073f3-b6a4-11e4-af2c-080027880ca6) diventa uno schiavo. Controllerà il suo elenco di GTID eseguiti e non troverà questo:84d15910-b6a4-11e4-af2c-080027880ca6:1. Di conseguenza, verrà eseguito il relativo SQL:
DELETE FROM mytable WHERE id=100;Questo non è qualcosa che ci aspettavamo... Se, nel frattempo, il binlog contenente questa transazione fosse eliminato dal vecchio slave, il nuovo slave si lamenterà dopo il failover:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'Come rilevare le transazioni errate?
MySQL fornisce due funzioni che sono molto utili quando vuoi confrontare set GTID su host diversi.
GTID_SUBSET() prende due set GTID e controlla se il primo set è un sottoinsieme del secondo.
Diciamo che abbiamo il seguente stato.
Maestro:
mysql> show master status\G
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Schiavo:
mysql> show slave status\G
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4Possiamo verificare se lo slave ha delle transazioni errate eseguendo il seguente SQL:
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subset\G
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)Sembra che ci siano transazioni errate. Come li identifichiamo? Possiamo usare un'altra funzione, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as mising\G
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)I nostri GTID mancanti sono ab8f5793-b907-11e4-bebd-080027880ca6:3-4 - quelle transazioni sono state eseguite sullo slave ma non sul master.
Come risolvere i problemi causati da transazioni errate?
Esistono due modi:iniettare transazioni vuote o escludere transazioni dalla cronologia GTID.
Per iniettare transazioni vuote possiamo usare il seguente SQL:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)Questo deve essere eseguito su ogni host nella topologia di replica che non ha quei GTID eseguiti. Se il master è disponibile, puoi inserire quelle transazioni lì e lasciarle replicare lungo la catena. Se il master non è disponibile (ad esempio, è andato in crash), le transazioni vuote devono essere eseguite su ogni slave. Oracle ha sviluppato uno strumento chiamato mysqlslavetrx progettato per automatizzare questo processo.
Un altro approccio consiste nel rimuovere i GTID dalla cronologia:
Arresta schiavo:
mysql> STOP SLAVE;Stampa Executed_Gtid_Set sullo slave:
mysql> SHOW MASTER STATUS\GReimposta informazioni GTID:
RESET MASTER;Imposta GTID_PURGED su un set GTID corretto. sulla base dei dati di SHOW MASTER STATUS. Dovresti escludere le transazioni errate dal set.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Avvia schiavo.
mysql> START SLAVE\GIn ogni caso, dovresti verificare la coerenza dei tuoi slave usando pt-table-checksum e pt-table-sync (se necessario) - una transazione errata potrebbe causare una deriva dei dati.
Failover in ClusterControl
A partire dalla versione 1.4, ClusterControl ha migliorato i suoi processi di gestione del failover per MySQL Replication. È comunque possibile eseguire un interruttore principale manuale promuovendo uno degli slave a master. Il resto degli slave eseguirà quindi il failover sul nuovo master. Dalla versione 1.4, ClusterControl ha anche la possibilità di eseguire un failover completamente automatizzato in caso di errore del master. Ne abbiamo parlato in modo approfondito in un post sul blog che descrive ClusterControl e il failover automatico. Vorremmo ancora menzionare una caratteristica, direttamente correlata all'argomento di questo post.
Per impostazione predefinita, ClusterControl esegue il failover in "modo sicuro":al momento del failover (o del passaggio, se è l'utente che ha eseguito uno switch principale), ClusterControl seleziona un candidato master e quindi verifica che questo nodo non abbia transazioni errate che avrebbe un impatto sulla replica una volta promossa a master. Se viene rilevata una transazione errata, ClusterControl interromperà il processo di failover e il candidato master non verrà promosso a nuovo master.
Se vuoi essere sicuro al 100% che ClusterControl promuoverà un nuovo master anche se vengono rilevati alcuni problemi (come transazioni errate), puoi farlo usando l'impostazione replication_stop_on_error=0 nella configurazione di cmon. Ovviamente, come abbiamo discusso, potrebbe causare problemi con la replica:gli slave potrebbero iniziare a richiedere un evento di registro binario che non è più disponibile.
Per gestire questi casi, abbiamo aggiunto il supporto sperimentale per la ricostruzione degli schiavi. Se imposti replication_auto_rebuild_slave=1 nella configurazione di cmon e il tuo slave è contrassegnato come inattivo con il seguente errore in MySQL, ClusterControl tenterà di ricostruire lo slave utilizzando i dati del master:
Ho ricevuto l'errore irreversibile 1236 dal master durante la lettura dei dati dal log binario:'Lo slave si sta connettendo utilizzando CHANGE MASTER TO MASTER_AUTO_POSITION =1, ma il master ha eliminato i log binari contenenti GTID richiesti dallo slave.'
Tale impostazione potrebbe non essere sempre appropriata poiché il processo di ricostruzione indurrà un carico maggiore sul master. Potrebbe anche essere che il tuo set di dati sia molto grande e una ricostruzione regolare non sia un'opzione, ecco perché questo comportamento è disabilitato per impostazione predefinita.