Autore ospite:Michael J Swart (@MJSwart)
Dedico molto tempo alla traduzione dei requisiti software in schemi e query. Questi requisiti a volte sono facili da implementare, ma spesso sono difficili. Voglio parlare delle scelte di progettazione dell'interfaccia utente che portano a modelli di accesso ai dati difficili da implementare utilizzando SQL Server.
Ordina per colonna
L'ordinamento per colonna è un modello così familiare che possiamo darlo per scontato. Ogni volta che interagiamo con un software che visualizza una tabella, possiamo aspettarci che le colonne siano ordinabili in questo modo:
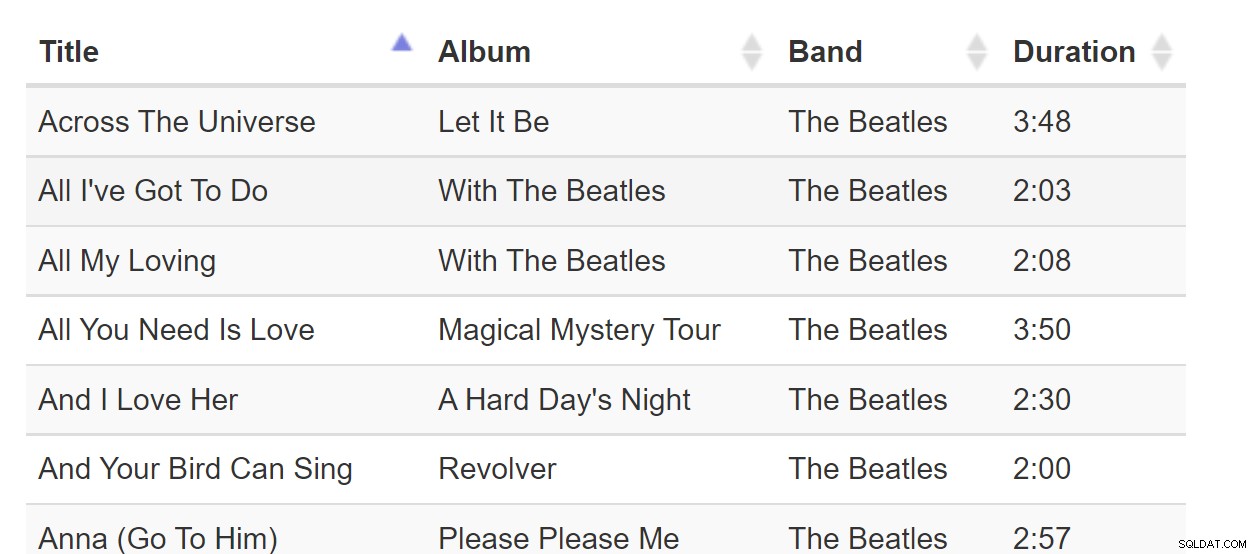
Sort-By-Colunn è un ottimo modello quando tutti i dati possono essere inseriti nel browser. Ma se il set di dati è grande miliardi di righe, ciò può diventare imbarazzante anche se la pagina Web richiede solo una pagina di dati. Considera questa tabella di canzoni:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); E considera queste quattro query ordinate per ogni colonna:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
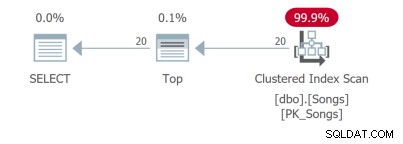
Anche per una query così semplice, esistono diversi piani di query. Le prime due query utilizzano gli indici di copertura:
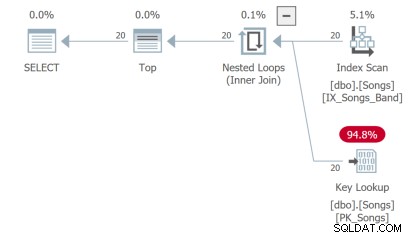
La terza query deve eseguire una ricerca chiave che non è l'ideale:
Ma la cosa peggiore è la quarta query che deve scansionare l'intera tabella ed eseguire un ordinamento per restituire le prime 20 righe:
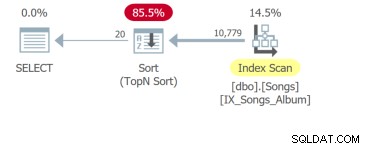
Il punto è che anche se l'unica differenza è la clausola ORDER BY, queste query devono essere analizzate separatamente. L'unità di base dell'ottimizzazione SQL è la query. Quindi, se mi mostri i requisiti dell'interfaccia utente con dieci colonne ordinabili, ti mostrerò dieci query da analizzare.
Quando diventa imbarazzante?
La funzione Ordina per colonna è un ottimo modello dell'interfaccia utente, ma può diventare imbarazzante se i dati provengono da un'enorme tabella in crescita con molte, molte colonne. Potrebbe essere allettante creare indici di copertura su ogni colonna, ma ciò ha altri compromessi. Gli indici Columnstore possono aiutare in alcune circostanze, ma ciò introduce un altro livello di imbarazzo. Non sempre c'è un'alternativa facile.
Risultati impaginati
L'uso dei risultati paginati è un buon modo per non sovraccaricare l'utente con troppe informazioni tutte in una volta. È anche un buon modo per non sovraccaricare i server di database... di solito.
Considera questo design:

I dati alla base di questo esempio richiedono il conteggio e l'elaborazione dell'intero set di dati per riportare il numero di risultati. La query per questo esempio potrebbe utilizzare una sintassi come questa:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
È una sintassi conveniente e la query produce solo 25 righe. Ma solo perché il set di risultati è piccolo, non significa necessariamente che sia economico. Proprio come abbiamo visto con il modello Sort-By-Column, un operatore TOP è economico solo se non ha bisogno di ordinare prima molti dati.
Richieste di pagina asincrone
Mentre un utente naviga da una pagina di risultati all'altra, le richieste Web coinvolte possono essere separate da secondi o minuti. Questo porta a problemi che assomigliano molto alle insidie che si vedono quando si usa NOLOCK. Ad esempio:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Quando viene aggiunta una riga tra le due richieste, l'utente potrebbe visualizzare la stessa riga due volte. E se una riga viene rimossa, l'utente potrebbe perderne una mentre naviga tra le pagine. Questo modello Paged-Results è equivalente a "Dammi righe 26-50". Quando la vera domanda dovrebbe essere "Dammi le prossime 25 righe". La differenza è sottile.
Modelli migliori
Con Paged-Results, quel "OFFSET @N ROWS" potrebbe richiedere sempre più tempo man mano che @N cresce. Considera invece i pulsanti Carica altro o Scorrimento infinito. Con il paging Load-More, c'è almeno la possibilità di utilizzare in modo efficiente un indice. La query sarebbe simile a:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Soffre ancora di alcune delle insidie delle richieste di pagine asincrone, ma a causa del segnalibro, l'utente riprenderà da dove si era interrotto.
Ricerca di testo per sottostringa
La ricerca è ovunque su Internet. Ma quale soluzione dovrebbe essere utilizzata sul back-end? Voglio mettere in guardia contro la ricerca di una sottostringa utilizzando il filtro LIKE di SQL Server con caratteri jolly come questo:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Può portare a risultati imbarazzanti come questo:
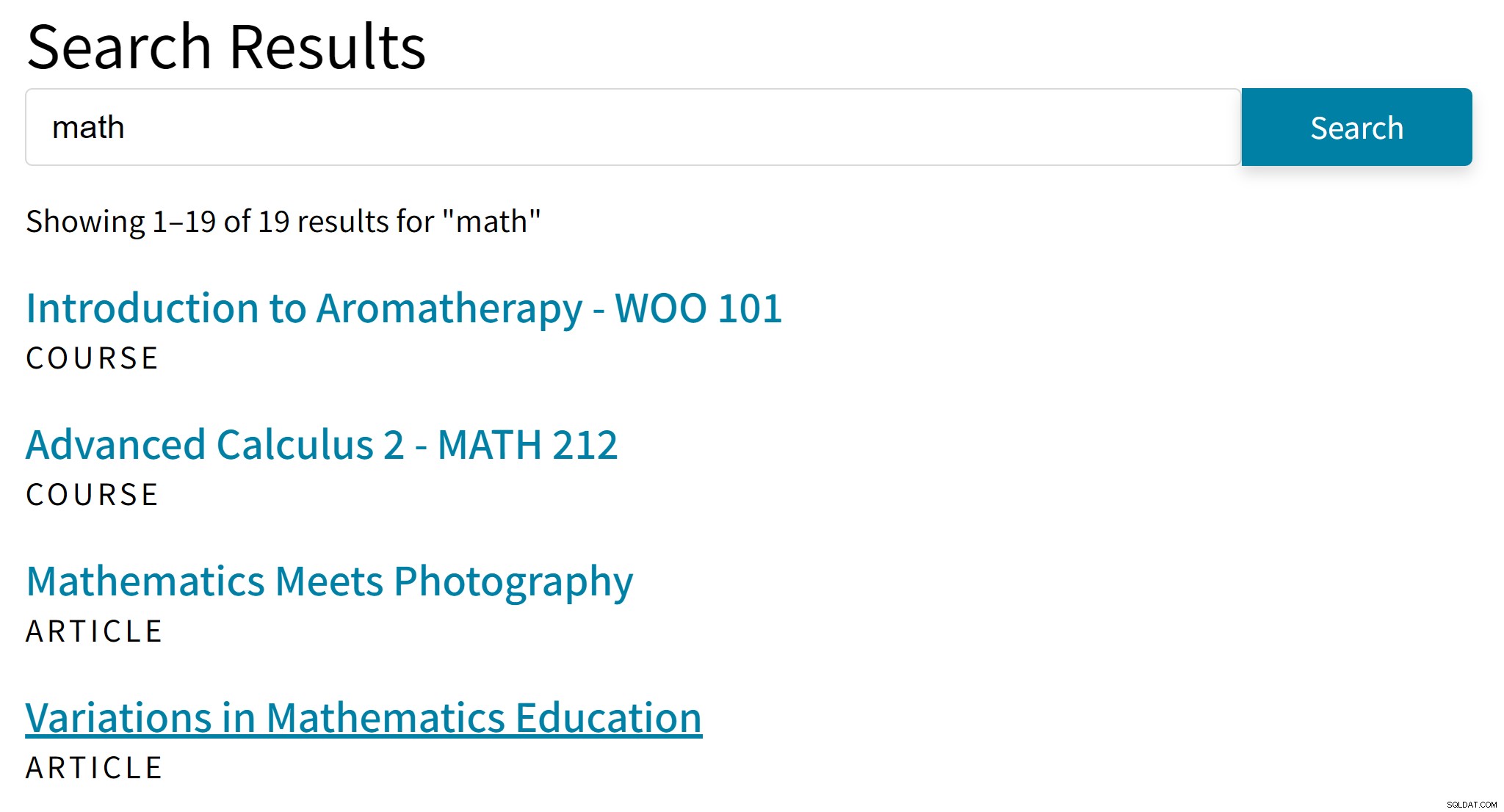
"Aromaterapia" probabilmente non è un buon successo per il termine di ricerca "matematica". Nel frattempo, nei risultati della ricerca mancano articoli che menzionano solo Algebra o Trigonometria.
Può anche essere molto difficile eseguire in modo efficiente utilizzando SQL Server. Non esiste un indice semplice che supporti questo tipo di ricerca. Paul White ha fornito una soluzione complicata con Trigram Wildcard String Search in SQL Server. Ci sono anche difficoltà che possono verificarsi con le regole di confronto e Unicode. Può diventare una soluzione costosa per un'esperienza utente non così buona.
Cosa usare invece
La ricerca full-text di SQL Server sembra che potrebbe aiutare, ma personalmente non l'ho mai usata. In pratica, ho riscontrato il successo solo in soluzioni al di fuori di SQL Server (ad es. Elasticsearch).
Conclusione
Nella mia esperienza ho scoperto che i progettisti di software sono spesso molto ricettivi al feedback che i loro progetti a volte saranno difficili da implementare. Quando non lo sono, ho trovato utile evidenziare le insidie, i costi e i tempi di consegna. Questo tipo di feedback è necessario per aiutare a creare soluzioni scalabili e gestibili.
Informazioni sull'autore
 Michael J Swart è un appassionato professionista di database e blogger che si concentra sullo sviluppo di database e sull'architettura del software. Gli piace parlare di qualsiasi cosa relativa ai dati, contribuendo ai progetti della comunità. Michael scrive sul blog come "Database Whisperer" su michaeljswart.com.
Michael J Swart è un appassionato professionista di database e blogger che si concentra sullo sviluppo di database e sull'architettura del software. Gli piace parlare di qualsiasi cosa relativa ai dati, contribuendo ai progetti della comunità. Michael scrive sul blog come "Database Whisperer" su michaeljswart.com.