SQL Server 2014 CTP1 è uscito da alcune settimane e probabilmente hai visto un po' di stampa su tabelle ottimizzate per la memoria e indici columnstore aggiornabili. Anche se questi sono sicuramente degni di attenzione, in questo post ho voluto esplorare il nuovo miglioramento del parallelismo SELECT … INTO. Il miglioramento è una di quelle modifiche al prêt-à-porter che, a quanto pare, non richiederanno modifiche significative al codice per iniziare a trarne vantaggio. Le mie esplorazioni sono state eseguite utilizzando la versione Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
SELEZIONA in parallelo... IN
SQL Server 2014 introduce SELECT ... INTO abilitato per il parallelo per i database e per testare questa funzionalità ho utilizzato il database AdventureWorksDW2012 e una versione della tabella FactInternetSales che conteneva 61.847.552 righe (ero responsabile dell'aggiunta di quelle righe; non vengono fornite con il database per impostazione predefinita).
Poiché questa funzionalità, a partire da CTP1, richiede il livello di compatibilità del database 110, a scopo di test ho impostato il database sul livello di compatibilità 100 ed ho eseguito la seguente query per il mio primo test:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; La durata dell'esecuzione della query era di 3 minuti e 19 secondi sulla mia macchina virtuale di prova e il piano di esecuzione della query prodotto era il seguente:

SQL Server utilizzava un piano seriale, come mi aspettavo. Si noti inoltre che la mia tabella aveva un indice columnstore non cluster che è stato scansionato (ho creato questo indice columnstore non cluster per l'uso con altri test, ma in seguito mostrerò anche il piano di esecuzione della query dell'indice columnstore cluster). Il piano non utilizzava il parallelismo e la scansione dell'indice Columnstore utilizzava la modalità di esecuzione riga anziché la modalità di esecuzione batch.
Quindi, successivamente, ho modificato il livello di compatibilità del database (e nota che non esiste ancora un livello di compatibilità di SQL Server 2014 in CTP1):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Ho eliminato la tabella FactInternetSales_V2 e quindi ho eseguito nuovamente il mio SELECT ... INTO originale operazione. Questa volta la durata dell'esecuzione della query era di 1 minuto e 7 secondi e il piano di esecuzione della query effettivo era il seguente:
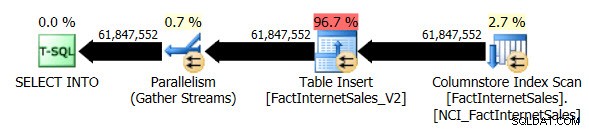
Ora abbiamo un piano parallelo e l'unica modifica che dovevo apportare era il livello di compatibilità del database per AdventureWorksDW2012. La mia macchina virtuale di test ha quattro vCPU allocate e il piano di esecuzione delle query ha distribuito le righe su quattro thread:

La scansione dell'indice Columnstore non in cluster, mentre utilizzava il parallelismo, non utilizzava la modalità di esecuzione batch. Invece ha usato la modalità di esecuzione della riga.
Ecco una tabella per mostrare i risultati del test finora:
| Tipo di scansione | Livello di compatibilità | SELEZIONA in parallelo... IN | Modalità di esecuzione | Durata |
|---|---|---|---|---|
| Scansione indice Columnstore non cluster | 100 | No | Riga | 3:19 |
| Scansione indice Columnstore non cluster | 110 | Sì | Riga | 1:07 |
Quindi, come test successivo, ho eliminato l'indice columnstore non cluster e ho eseguito nuovamente SELECT ... INTO query utilizzando sia il livello di compatibilità del database 100 che 110.
L'esecuzione del test di compatibilità di livello 100 ha richiesto 5 minuti e 44 secondi ed è stato generato il seguente piano:
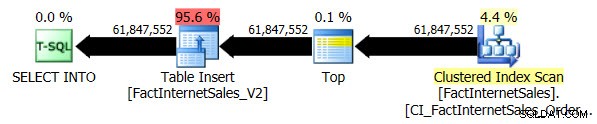
La scansione dell'indice in cluster seriale ha richiesto 2 minuti e 25 secondi in più rispetto alla scansione dell'indice Columnstore seriale non in cluster.
Utilizzando il livello di compatibilità 110, l'esecuzione della query ha richiesto 1 minuto e 55 secondi ed è stato generato il seguente piano:

In modo simile al test Columnstore Index Scan parallelo non cluster, il test parallelo Clustered Index Scan ha distribuito le righe su quattro thread:
La tabella seguente riassume questi due test sopra citati:
| Tipo di scansione | Livello di compatibilità | SELEZIONA in parallelo... IN | Modalità di esecuzione | Durata |
|---|---|---|---|---|
| Scansione indice raggruppata | 100 | No | Riga (N/D) | 5:44 |
| Scansione indice raggruppata | 110 | Sì | Riga (N/D) | 1:55 |
Quindi mi sono chiesto le prestazioni per un indice columnstore cluster (nuovo in SQL Server 2014), quindi ho eliminato gli indici esistenti e creato un indice columnstore cluster nella tabella FactInternetSales. Ho anche dovuto eliminare gli otto diversi vincoli di chiave esterna definiti nella tabella prima di poter creare l'indice columnstore cluster.
La discussione diventa in qualche modo accademica, dal momento che sto confrontando SELECT ... INTO prestazioni a livelli di compatibilità del database che in primo luogo non offrivano indici columnstore cluster, né i test precedenti per indici columnstore non cluster al livello di compatibilità database 100, eppure è interessante vedere e confrontare le caratteristiche delle prestazioni complessive.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
Per inciso, l'operazione per creare l'indice columnstore cluster su una tabella di 61.847.552 milioni di righe ha richiesto 11 minuti e 25 secondi con quattro vCPU disponibili (di cui l'operazione le ha sfruttate tutte), 4 GB di RAM e storage guest virtuale su SSD OCZ Vertex. Durante quel periodo le CPU non sono state agganciate per tutto il tempo, ma piuttosto hanno mostrato picchi e valli (un campionamento di 60 secondi di attività della CPU mostrato di seguito):
Dopo aver creato l'indice columnstore cluster, ho eseguito nuovamente i due SELECT ... INTO prove. Il test del livello di compatibilità 100 ha richiesto 3 minuti e 22 secondi per l'esecuzione e il piano era seriale come previsto (sto mostrando la versione del piano di SQL Server Management Studio dalla scansione dell'indice Columnstore in cluster, a partire da SQL Server 2014 CTP1 , non è ancora completamente riconosciuto da Plan Explorer):

Successivamente ho modificato il livello di compatibilità del database su 110 e ho eseguito nuovamente il test, che questa volta ha richiesto 1 minuto e 11 secondi e aveva il seguente piano di esecuzione effettivo:

Il piano distribuiva le righe su quattro thread e, proprio come l'indice columnstore non cluster, la modalità di esecuzione della scansione indice columnstore cluster era riga e non batch.
La tabella seguente riassume tutti i test all'interno di questo post (in ordine di durata, dal basso verso l'alto):
| Tipo di scansione | Livello di compatibilità | SELEZIONA in parallelo... IN | Modalità di esecuzione | Durata |
|---|---|---|---|---|
| Scansione indice Columnstore non cluster | 110 | Sì | Riga | 1:07 |
| Scansione dell'indice di Columnstore in cluster | 110 | Sì | Riga | 1:11 |
| Scansione indice raggruppata | 110 | Sì | Riga (N/D) | 1:55 |
| Scansione indice Columnstore non cluster | 100 | No | Riga | 3:19 |
| Scansione dell'indice di Columnstore in cluster | 100 | No | Riga | 3:22 |
| Scansione indice raggruppata | 100 | No | Riga (N/D) | 5:44 |
Alcune osservazioni:
- Non sono sicuro della differenza tra un
SELECT ... INTOparallelo l'operazione rispetto a un indice columnstore non cluster rispetto a un indice columnstore cluster è statisticamente significativa. Avrei bisogno di fare più test, ma penso che aspetterei per eseguirli fino a RTM. - Posso tranquillamente affermare che il parallelo
SELECT ... INTOha sovraperformato in modo significativo gli equivalenti seriali su un indice cluster, un columnstore non cluster e i test dell'indice columnstore cluster.
Vale la pena ricordare che questi risultati si riferiscono a una versione CTP del prodotto e che i miei test dovrebbero essere visti come qualcosa che potrebbe cambiare il comportamento di RTM, quindi ero meno interessato alle durate standalone rispetto al modo in cui tali durate venivano confrontate tra seriale e parallelo condizioni.
Alcune caratteristiche delle prestazioni richiedono un refactoring significativo, ma per SELECT ... INTO miglioramento, tutto ciò che dovevo fare era aumentare il livello di compatibilità del database per iniziare a vedere i vantaggi, che è sicuramente qualcosa che apprezzo.