La concatenazione di gruppi è un problema comune in SQL Server, senza funzionalità dirette e intenzionali per supportarlo (come XMLAGG in Oracle, STRING_AGG o ARRAY_TO_STRING(ARRAY_AGG()) in PostgreSQL e GROUP_CONCAT in MySQL). È stato richiesto, ma non ha ancora avuto successo, come evidenziato in questi elementi Connect:
- Connetti #247118:SQL richiede la versione della funzione MySQL group_Concat (posticipata)
- Connect #728969 :Funzioni di set ordinati – Clausola ALL'INTERNO DEL GRUPPO (chiusa perché non si risolve)
** AGGIORNAMENTO gennaio 2017 ** :STRING_AGG() sarà in SQL Server 2017; leggilo qui, qui e qui.
Cos'è la concatenazione raggruppata?
Per chi non lo sapesse, la concatenazione raggruppata è quando si desidera prendere più righe di dati e comprimerle in un'unica stringa (di solito con delimitatori come virgole, tabulazioni o spazi). Alcuni potrebbero chiamarlo "unione orizzontale". Un rapido esempio visivo che mostra come comprimere un elenco di animali domestici appartenenti a ciascun membro della famiglia, dalla fonte normalizzata all'output "appiattito":
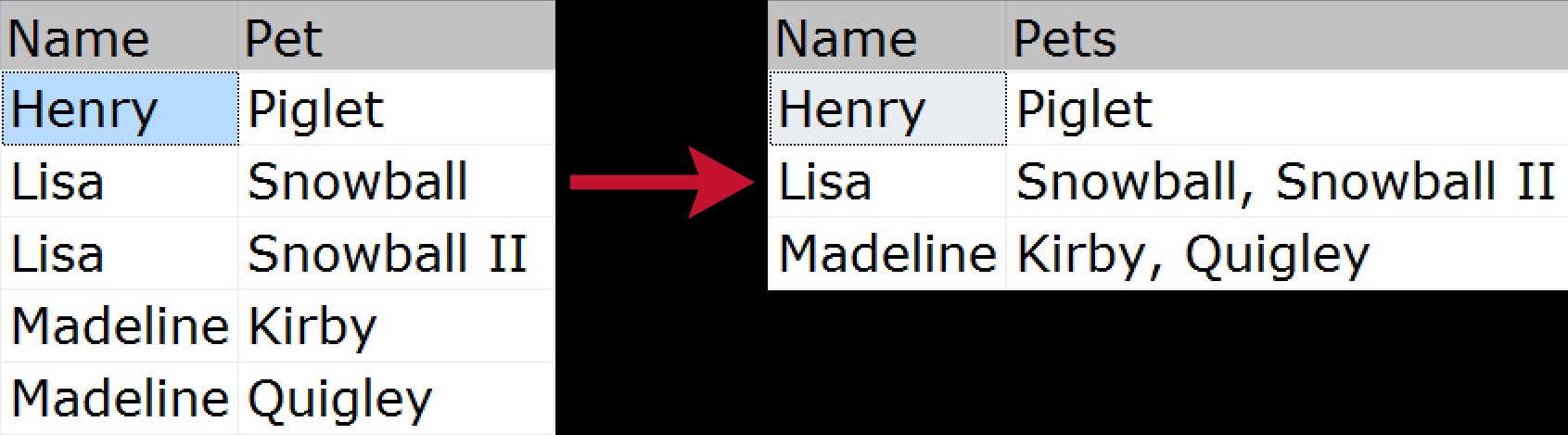
Ci sono stati molti modi per risolvere questo problema nel corso degli anni; eccone solo alcuni, basati sui seguenti dati di esempio:
CREATE TABLE dbo.FamilyMemberPets ( Name SYSNAME, Pet SYSNAME, PRIMARY KEY(Name,Pet) ); INSERT dbo.FamilyMemberPets(Name,Pet) VALUES (N'Madeline',N'Kirby'), (N'Madeline',N'Quigley'), (N'Henry', N'Piglet'), (N'Lisa', N'Snowball'), (N'Lisa', N'Snowball II');
Non dimostrerò un elenco esaustivo di ogni approccio di concatenazione di gruppo mai concepito, poiché voglio concentrarmi su alcuni aspetti del mio approccio consigliato, ma voglio sottolineare alcuni di quelli più comuni:
UDF scalare
CREATE FUNCTION dbo.ConcatFunction
(
@Name SYSNAME
)
RETURNS NVARCHAR(MAX)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @s NVARCHAR(MAX);
SELECT @s = COALESCE(@s + N', ', N'') + Pet
FROM dbo.FamilyMemberPets
WHERE Name = @Name
ORDER BY Pet;
RETURN (@s);
END
GO
SELECT Name, Pets = dbo.ConcatFunction(Name)
FROM dbo.FamilyMemberPets
GROUP BY Name
ORDER BY Name; Nota:c'è un motivo per cui non lo facciamo:
SELECT DISTINCT Name, Pets = dbo.ConcatFunction(Name) FROM dbo.FamilyMemberPets ORDER BY Name;
Con DISTINCT , la funzione viene eseguita per ogni singola riga, quindi i duplicati vengono rimossi; con GROUP BY , i duplicati vengono rimossi per primi.
Common Language Runtime (CLR)
Questo utilizza il GROUP_CONCAT_S funzione trovata su https://groupconcat.codeplex.com/:
SELECT Name, Pets = dbo.GROUP_CONCAT_S(Pet, 1) FROM dbo.FamilyMemberPets GROUP BY Name ORDER BY Name;
CTE ricorsivo
Ci sono diverse variazioni su questa ricorsione; questo tira fuori una serie di nomi distinti come l'ancora:
;WITH x as
(
SELECT Name, Pet = CONVERT(NVARCHAR(MAX), Pet),
r1 = ROW_NUMBER() OVER (PARTITION BY Name ORDER BY Pet)
FROM dbo.FamilyMemberPets
),
a AS
(
SELECT Name, Pet, r1 FROM x WHERE r1 = 1
),
r AS
(
SELECT Name, Pet, r1 FROM a WHERE r1 = 1
UNION ALL
SELECT x.Name, r.Pet + N', ' + x.Pet, x.r1
FROM x INNER JOIN r
ON r.Name = x.Name
AND x.r1 = r.r1 + 1
)
SELECT Name, Pets = MAX(Pet)
FROM r
GROUP BY Name
ORDER BY Name
OPTION (MAXRECURSION 0); Cursore
Non c'è molto da dire qui; i cursori di solito non sono l'approccio ottimale, ma questa potrebbe essere la tua unica scelta se sei bloccato su SQL Server 2000:
DECLARE @t TABLE(Name SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name));
INSERT @t(Name, Pets)
SELECT Name, N''
FROM dbo.FamilyMemberPets GROUP BY Name;
DECLARE @name SYSNAME, @pet SYSNAME, @pets NVARCHAR(MAX);
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR SELECT Name, Pet
FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
OPEN c;
FETCH c INTO @name, @pet;
WHILE @@FETCH_STATUS = 0
BEGIN
UPDATE @t SET Pets += N', ' + @pet
WHERE Name = @name;
FETCH c INTO @name, @pet;
END
CLOSE c; DEALLOCATE c;
SELECT Name, Pets = STUFF(Pets, 1, 1, N'')
FROM @t
ORDER BY Name;
GO Aggiornamento stravagante
Alcune persone *adorano* questo approccio; Non capisco affatto l'attrazione.
DECLARE @Name SYSNAME, @Pets NVARCHAR(MAX);
DECLARE @t TABLE(Name SYSNAME, Pet SYSNAME, Pets NVARCHAR(MAX),
PRIMARY KEY (Name, Pet));
INSERT @t(Name, Pet)
SELECT Name, Pet FROM dbo.FamilyMemberPets
ORDER BY Name, Pet;
UPDATE @t SET @Pets = Pets = COALESCE(
CASE COALESCE(@Name, N'')
WHEN Name THEN @Pets + N', ' + Pet
ELSE Pet END, N''),
@Name = Name;
SELECT Name, Pets = MAX(Pets)
FROM @t
GROUP BY Name
ORDER BY Name; PER PERCORSO XML
Abbastanza facilmente il mio metodo preferito, almeno in parte perché è l'unico modo per *garantire* l'ordine senza usare un cursore o CLR. Detto questo, questa è una versione molto grezza che non risolve un paio di altri problemi intrinseci di cui parlerò più avanti:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N'')), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Ho visto molte persone presumere erroneamente che il nuovo CONCAT() la funzione introdotta in SQL Server 2012 è stata la risposta a queste richieste di funzionalità. Quella funzione ha lo scopo di operare solo su colonne o variabili in una singola riga; non può essere utilizzato per concatenare valori tra righe.
Ulteriori informazioni su FOR XML PATH
FOR XML PATH('') di per sé non è abbastanza buono:ha problemi noti con l'entitizzazione XML. Ad esempio, se aggiorni uno dei nomi degli animali domestici per includere una parentesi HTML o una e commerciale:
UPDATE dbo.FamilyMemberPets SET Pet = N'Qui>gle&y' WHERE Pet = N'Quigley';
Questi vengono tradotti in entità sicure per XML da qualche parte lungo il percorso:
Qui>gle&y
Quindi uso sempre PATH, TYPE).value() , come segue:
SELECT Name, Pets = STUFF((SELECT N', ' + Pet FROM dbo.FamilyMemberPets AS p2 WHERE p2.name = p.name ORDER BY Pet FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.FamilyMemberPets AS p GROUP BY Name ORDER BY Name;
Inoltre uso sempre NVARCHAR , perché non sai mai quando una colonna sottostante conterrà Unicode (o in seguito verrà modificata per farlo).
Potresti vedere le seguenti varietà all'interno di .value() , o anche altri:
... TYPE).value(N'.', ... ... TYPE).value(N'(./text())[1]', ...
Questi sono intercambiabili, tutti in definitiva rappresentano la stessa stringa; le differenze di prestazioni tra di loro (più sotto) erano trascurabili e forse del tutto non deterministiche.
Un altro problema che potresti incontrare sono alcuni caratteri ASCII che non è possibile rappresentare in XML; ad esempio, se la stringa contiene il carattere 0x001A (CHAR(26) ), riceverai questo messaggio di errore:
FOR XML non ha potuto serializzare i dati per il nodo 'NoName' perché contiene un carattere (0x001A) che non è consentito in XML. Per recuperare questi dati utilizzando FOR XML, convertirli in tipo di dati binary, varbinary o image e utilizzare la direttiva BINARY BASE64.
Questo mi sembra piuttosto complicato, ma spero che tu non debba preoccupartene perché non stai archiviando dati come questo o almeno non stai cercando di usarli in concatenazione di gruppi. Se lo sei, potresti dover ricorrere a uno degli altri approcci.
Prestazioni
I dati di esempio sopra riportati rendono facile dimostrare che tutti questi metodi fanno ciò che ci aspettiamo, ma è difficile confrontarli in modo significativo. Quindi ho popolato la tabella con un set molto più grande:
TRUNCATE TABLE dbo.FamilyMemberPets; INSERT dbo.FamilyMemberPets(Name,Pet) SELECT o.name, c.name FROM sys.all_objects AS o INNER JOIN sys.all_columns AS c ON o.[object_id] = c.[object_id] ORDER BY o.name, c.name;
Per me, si trattava di 575 oggetti, con 7.080 righe totali; l'oggetto più largo aveva 142 colonne. Ora, ancora una volta, è vero, non ho deciso di confrontare ogni singolo approccio concepito nella storia di SQL Server; solo i pochi punti salienti che ho postato sopra. Ecco i risultati:
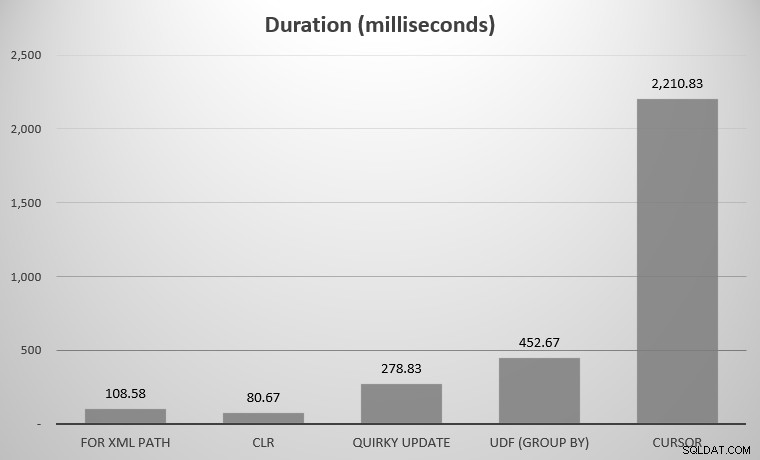
Potresti notare un paio di contendenti mancanti; l'UDF utilizzando DISTINCT e il CTE ricorsivo erano così fuori scala da distorcere la scala. Ecco i risultati di tutti e sette gli approcci in forma tabellare:
| Approccio | Durata (millisecondi) |
|---|---|
| PER PERCORSO XML | 108,58 |
| CLR | 80.67 |
| Aggiornamento stravagante | 278,83 |
| UDF (GRUPPO PER) | 452,67 |
| UDF (DISTINTO) | 5.893,67 |
| Cursore | 2.210,83 |
| CTE ricorsiva | 70.240,58 |
Durata media, in millisecondi, per tutti gli approcci
Si noti inoltre che le variazioni su FOR XML PATH sono stati testati in modo indipendente ma hanno mostrato differenze molto minori, quindi li ho semplicemente combinati per la media. Se vuoi davvero saperlo, il .[1] la notazione ha funzionato più velocemente nei miei test; YMMV.
Conclusione
Se non sei in un negozio in cui CLR è un ostacolo in alcun modo, e soprattutto se non hai a che fare solo con nomi semplici o altre stringhe, dovresti assolutamente prendere in considerazione il progetto CodePlex. Non provare a reinventare la ruota, non provare trucchi e hack non intuitivi per fare CROSS APPLY o altri costrutti funzionano solo un po' più velocemente degli approcci non CLR sopra. Prendi solo ciò che funziona e collegalo. E diamine, dal momento che ottieni anche il codice sorgente, puoi migliorarlo o estenderlo se lo desideri.
Se CLR è un problema, allora FOR XML PATH è probabilmente la tua migliore opzione, ma dovrai comunque fare attenzione ai personaggi difficili. Se sei bloccato su SQL Server 2000, la tua unica opzione fattibile è l'UDF (o codice simile non racchiuso in un UDF).
La prossima volta
Un paio di cose che voglio esplorare in un post successivo:rimuovere i duplicati dall'elenco, ordinare l'elenco in base a qualcosa di diverso dal valore stesso, casi in cui inserire uno di questi approcci in un UDF può essere doloroso e casi d'uso pratici per questa funzionalità.