Nota:questo articolo illustra la migrazione di un modello di database relazionale (RDB) allo schema a stella utilizzando l'IDE Eclipse per Voracity (e i suoi prodotti inclusi), IRI Workbench, dopo un'introduzione a entrambe le architetture. Se sei interessato a migrare il tuo RDB o i tuoi dati a un modello Data Vault 2.0, una nuova procedura guidata di Workbench debutterà al World Wide Data Vault Consortium a maggio 2019; iscriviti al blog IRI per ricevere le istruzioni dettagliate non appena vengono pubblicate!
Un data warehouse (DW) è una raccolta di dati estratti dal sistema operativo o transazionale di un'azienda, trasformati per eliminare le incongruenze e quindi organizzati per supportare analisi e/o report rapidi. Il DW richiede uno schema o una descrizione logica e una rappresentazione grafica del suo database operativo. Questo articolo tocca questi argomenti fornendo una guida pratica per passare da uno schema di database relazionale convenzionale a uno schema DW popolare chiamato schema a stella.
Schema a stelle vs. Relazionale
La maggior parte delle strutture dati relazionali sono illustrate nei diagrammi entità-relazione (ER). Un diagramma ER viene utilizzato nello sviluppo di modelli concettuali per un sistema di gestione del database di elaborazione delle transazioni online (OLTP). È la fonte da cui viene tradotta la struttura della tabella.
Lo schema a stella, tuttavia, è lo standard ampiamente accettato per la struttura della tabella sottostante di un data warehouse. La sua semplice forma a stella (con diagramma ER) mostra la tabella dei fatti (contenente valori o misure di transazione) al centro e le tabelle dimensionali (contenenti valori descrittivi o attributivi) che si irradiano da essa. Di solito, la tabella dei fatti è in terza forma normale (3NF), mentre le tabelle dimensionali sono denormalizzate.
Le differenze fondamentali tra un modello entità-relazionale (ER) e un modello a stella sono queste:
- I modelli ER utilizzano strutture logiche e fisiche per la progettazione di database normalizzati
- I modelli dimensionali utilizzano una struttura fisica per la progettazione denormalizzata del database
Per vedere come il software IRI può de/normalizzare i dati tramite il pivot riga-colonna, fai clic qui.
Sfondo del processo di conversione
In questo articolo, mostro come convertire i dati da un modello relazionale in una stella utilizzando lavori che dovresti definire più o meno manualmente, ma che puoi creare ed eseguire automaticamente e modificare facilmente.
Quello che vedrai qui sono i dati 4GL dell'IRI e le specifiche del lavoro, espressi negli script "SortCL"[1], che mappano i dati nelle tabelle dimensionali e uniscono i dati nella tabella dei fatti centrale. SortCL è il programma di mappatura e manipolazione dei dati di base nella piattaforma di gestione dei dati e ETL di IRI Voracity. Tuttavia, la chiave qui è comprendere la metodologia e le mappature nei miei lavori SortCL, non la sintassi degli script.
La GUI gratuita di Eclipse, IRI Workbench, fornisce un editor SortCL sensibile alla sintassi, oltre a contorni grafici e finestre di dialogo, flussi di lavoro e diagrammi di mappatura e procedure guidate intuitive per creare o modificare automaticamente questi script se non lo desideri a mano. Cordiali saluti, IRI utilizza gli stessi metadati e la stessa GUI per profilare e creare diagrammi di DB, generare dati di test, eseguire ETL, formattare report, mascherare PII, acquisire dati modificati, migrare e replicare dati, pulire e convalidare dati, ecc.
Workbench utilizza una versione avanzata del plug-in Data Tools Platform (DTP) per Eclipse per la connessione ai database su JDBC e per abilitare le operazioni SQL e lo scambio di metadati IRI nella vista Data Source Explorer (DSE). In questo caso, Workbench supporta:
- la creazione e il popolamento di tabelle di test Oracle vincolate (fonte) tramite SortCL (o processi IRI RowGen, secondo questo articolo)
- la mappatura dei dati delle tabelle di entità nelle tabelle delle dimensioni tramite SortCL
- la mappatura degli elementi di fatto come relazione n-aria da associare alla tabella dimensionale principale; ovvero eseguire un join multi-tabella in SortCL per creare la tabella Fact
- Popolazione di tutte le tabelle di destinazione (schema a stella)
- Diagrammi ER degli schemi di origine e di destinazione
I tipi di entità nel mio modello relazionale originale sono:Dept, Emp, Project, Category, Item, Item_Use e Sale:
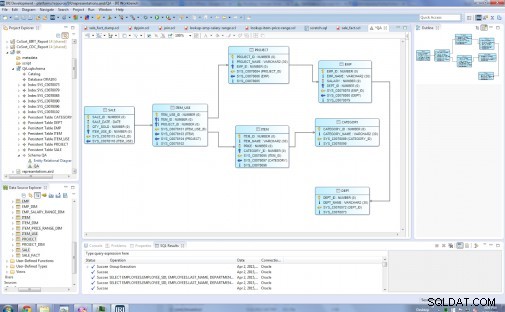
Prima di …
Il diagramma successivo mostra il modello Star finale con otto tabelle dimensionali e una tabella dei fatti. Le tabelle delle dimensioni sono: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. La tabella dei fatti al centro è Sale_Fact, che contiene le chiavi di tutte le tabelle delle dimensioni.

... Dopo
Passaggi di conversione
- Definisci e crea la tabella Fact
La struttura per la tabella Sale_Fact è mostrata in questo documento. La chiave primaria è sale_id e il resto degli attributi sono chiavi esterne ereditate dalle tabelle Dimension. Sto utilizzando un database Oracle (sebbene qualsiasi RDB funzioni) connesso a Workbench DSE (tramite JDBC) e SortCL per la trasformazione e la mappatura dei dati ( tramite ODBC). Ho creato le mie tabelle in script SQL modificati nello scrapbook SQL di DSE ed eseguiti in Workbench.
- Definisci e crea le tabelle dimensionali
Utilizza la stessa tecnica e i metadati collegati in precedenza per creare queste tabelle dimensionali che riceveranno i dati relazionali mappati dai lavori SortCL nel passaggio successivo:Categoria_Dim tabella, Reparto a Dept_Dim, Progetto su Project_Dim, Item su Item_Dim e Emp su Emp_Dim. Puoi eseguire quel programma .SQL con tutta la logica CREATE in una volta per creare le tabelle.
- Sposta i dati della tabella Entity originale nelle tabelle Dimension
Definisci ed esegui i lavori SortCL mostrati qui per mappare i dati (creati da RowGen) dallo schema relazionale alle tabelle Dimension per lo schema Star. In particolare, questi script caricano i dati dalla tabella Categoria alla tabella Dim_Category, da Dept a Dept_Dim, da Project a Project_Dim, da Item a Item_Dim e da Emp a Emp_Dim.
- Compila la tabella dei fatti
Utilizza SortCL per unire i dati dalle tabelle originali Sale, Emp, Project, Item_Use, Item, Category per preparare i dati per la nuova tabella Sale_Fact. Usa qui il secondo script (unisciti al lavoro).
Per migliorare il nostro esempio, useremo anche SortCL per introdurre nuovi dati dimensionali nello schema Star su cui si baserà anche la mia tabella Fact. Puoi vedere queste tabelle aggiuntive nel diagramma a stella sopra che non erano nel mio schema relazionale:Emp_Salary_Range_Dim e Item_Price_Range_Dim. Tali tabelle vengono create nello stesso file .SQL per le tabelle Fact e altre tabelle Dimension.
La tabella Fact necessita dei dati emp_salary_range_id e item_price_range_id di queste tabelle per rappresentare l'intervallo di valori in tali tabelle Dimension. Ad esempio, quando carico i valori dimensionali dei prezzi nel data warehouse, voglio assegnarli a una fascia di prezzo:
| Prezzo_oggetto | Intervallo_ID | Nome_intervallo | Range_End |
|---|---|---|---|
| 1 | Basso | 1 | 100 |
| 2 | Metà | 101 | 500 |
| 3 | Alto | 501 | 999 |
Il modo più semplice per assegnare gli ID intervallo nello script del lavoro (che sta preparando i dati per la mia tabella Sale_Fact) consiste nell'utilizzare un'istruzione IF-THEN-ELSE nella sezione di output. Consulta questo articolo sui valori di bucket per lo sfondo.
Ad ogni modo, ho creato l'intero lavoro con CoSort New Join Job procedura guidata nel banco di lavoro. E una volta eseguito, la mia tabella dei fatti è stata popolata:
 Visualizzazione della tabella Sale_Fact in IRI Workbench DSE
Visualizzazione della tabella Sale_Fact in IRI Workbench DSE
Conclusione
Il principale vantaggio della rappresentazione dei dati dimensionali è la riduzione della complessità della struttura di un database. Ciò semplifica la comprensione del database e la scrittura di query per le persone riducendo al minimo il numero di tabelle e, di conseguenza, il numero di join richiesti. Come accennato in precedenza, i modelli dimensionali ottimizzano anche le prestazioni delle query. Tuttavia, ha debolezza oltre che forza. La struttura fissa dello Star Schema limita le query. Quindi, poiché semplifica la scrittura delle query più comuni, limita anche il modo in cui i dati possono essere analizzati.
La GUI di IRI Workbench per Voracity dispone di un insieme potente e completo di strumenti che semplificano l'integrazione dei dati, inclusa la creazione, la manutenzione e l'espansione dei data warehouse. Con questa interfaccia intuitiva e facile da usare, Voracity facilita la creazione di processi ETL (estrazione, trasformazione, caricamento) end-to-end veloce, flessibile che coinvolge strutture di dati su piattaforme diverse.
Nelle operazioni ETL, i dati vengono estratti da diverse origini, trasformati separatamente e caricati in un Data warehouse ed eventualmente in altri target. La costruzione del processo ETL è, potenzialmente, uno dei compiti più grandi della costruzione di un magazzino; è complesso e richiede tempo. L'approccio ETL di IRI supporta questo processo in modo altamente efficiente e indipendente dal database, eseguendo tutta l'integrazione dei dati e lo staging nel file system.
[1] Se sei un segugio della sintassi, tieni presente che gli script SortCL utilizzati nel prodotto IRI CoSort o nella piattaforma IRI Voracity supportano la stessa sintassi e le stesse definizioni dei dati di IRI RowGen per la generazione dei dati di test, IRI NextForm per la migrazione dei dati e IRI FieldShield per il mascheramento dei dati. Tutti questi strumenti sono tutti supportati nella GUI di IRI Workbench e i relativi metadati possono anche essere condivisi e gestiti dal team per il controllo della versione, la derivazione del lavoro/dati e la sicurezza nel cloud.
[2] Per visualizzare i diagrammi E-R in IRI Workbench:
- Seleziona Nuovo progetto IRI e crea una nuova cartella
- Seleziona quella cartella ed evidenzia tutte le tabelle del database applicabili in Esplora origine dati; quindi fare clic con il pulsante destro del mouse su IRI, Nuovo diagramma ER
- Verrà creato un file (Schema.QA)
- Fai clic con il pulsante destro del mouse su quel file e seleziona Nuova rappresentazione, Nuovo diagramma di relazione di entità.
[3] Gli elementi del diagramma ER che illustrano tali modelli includono:
- tipi di entità definiti
- attributi definiti
- la relazione tra i tipi di entità
- quadro generale o diagramma concettuale
[4] IRI FACT e SQL*Loader sono rispettivamente opzioni di estrazione e caricamento in blocco.