In un post precedente, abbiamo discusso di come assumere il controllo del processo di failover in ClusterControl utilizzando whitelist e blacklist. In questo post parleremo di un concetto simile. Ma questa volta ci concentreremo sulle integrazioni con script e applicazioni esterni attraverso numerosi hook messi a disposizione da ClusterControl.
Gli ambienti infrastrutturali possono essere costruiti in diversi modi, poiché spesso ci sono molte opzioni tra cui scegliere per un dato pezzo del puzzle. Come definiamo su quale nodo del database scrivere? Usi IP virtuale? Usi una sorta di rilevamento dei servizi? Forse vai con le voci DNS e modifichi i record A quando necessario? E il livello proxy? Ti affidi al valore "sola_lettura" per i tuoi proxy per decidere chi scrive, o forse apporti le modifiche richieste direttamente nella configurazione del proxy? In che modo il tuo ambiente gestisce i passaggi? Puoi semplicemente andare avanti ed eseguirlo, o forse devi intraprendere alcune azioni preliminari in anticipo? Ad esempio, interrompere alcuni altri processi prima di poter effettivamente eseguire il passaggio?
Non è possibile preconfigurare un software di failover per coprire tutte le diverse configurazioni che le persone possono creare. Questo è il motivo principale per fornire diversi modi per collegarsi al processo di failover. In questo modo puoi personalizzarlo e rendere possibile la gestione di tutte le sottigliezze della tua configurazione. In questo post del blog, esamineremo come il processo di failover di ClusterControl può essere personalizzato utilizzando diversi script pre e post failover. Discuteremo anche alcuni esempi di cosa si può ottenere con tale personalizzazione.
Integrazione di ClusterControl
ClusterControl fornisce diversi hook che possono essere utilizzati per collegare script esterni. Di seguito troverai un elenco di quelli con qualche spiegazione.
- Replication_onfail_failover_script:questo script viene eseguito non appena viene rilevato che è necessario un failover. Se lo script restituisce un valore diverso da zero, forzerà l'interruzione del failover. Se lo script è definito ma non trovato, il failover verrà interrotto. Vengono forniti quattro argomenti allo script:arg1='all server' arg2='oldmaster' arg3='candidate', arg4='slaves of oldmaster' e passati in questo modo:'scripname arg1 arg2 arg3 arg4'. Lo script deve essere accessibile sul controller ed essere eseguibile.
- Replication_pre_failover_script:questo script viene eseguito prima che si verifichi il failover, ma dopo che un candidato è stato eletto ed è possibile continuare il processo di failover. Se lo script restituisce un valore diverso da zero, forzerà l'interruzione del failover. Se lo script è definito ma non trovato, il failover verrà interrotto. Lo script deve essere accessibile sul controller ed essere eseguibile.
- Replication_post_failover_script:questo script viene eseguito dopo che si è verificato il failover. Se lo script restituisce un valore diverso da zero, verrà scritto un avviso nel registro lavori. Lo script deve essere accessibile sul controller ed essere eseguibile.
- Replication_post_unsuccessful_failover_script - Questo script viene eseguito dopo che il tentativo di failover non è riuscito. Se lo script restituisce un valore diverso da zero, verrà scritto un avviso nel registro lavori. Lo script deve essere accessibile sul controller ed essere eseguibile.
- Replication_failed_reslave_failover_script - questo script viene eseguito dopo che è stato promosso un nuovo master e se la rislavizzazione degli slave al nuovo master non riesce. Se lo script restituisce un valore diverso da zero, verrà scritto un avviso nel registro lavori. Lo script deve essere accessibile sul controller ed essere eseguibile.
- Script_replication_pre_switchover:questo script viene eseguito prima che avvenga il passaggio. Se lo script restituisce un valore diverso da zero, imporrà l'esito negativo del passaggio. Se lo script è definito ma non trovato, il passaggio verrà interrotto. Lo script deve essere accessibile sul controller ed essere eseguibile.
- Replication_post_switchover_script:questo script viene eseguito dopo il passaggio. Se lo script restituisce un valore diverso da zero, verrà scritto un avviso nel registro lavori. Lo script deve essere accessibile sul controller ed essere eseguibile.
Come puoi vedere, gli hook coprono la maggior parte dei casi in cui potresti voler intraprendere alcune azioni, prima e dopo un passaggio, prima e dopo un failover, quando il reslave ha fallito o quando il failover è fallito. Tutti gli script vengono invocati con quattro argomenti (che possono essere gestiti o meno nello script, non è necessario che lo script li utilizzi tutti):tutti i server, hostname (o IP - come definito in ClusterControl) del vecchio master, hostname (o IP - come definito in ClusterControl) del candidato master e il quarto, tutte repliche del vecchio master. Tali opzioni dovrebbero consentire di gestire la maggior parte dei casi.
Tutti questi hook devono essere definiti in un file di configurazione per un determinato cluster (/etc/cmon.d/cmon_X.cnf dove X è l'id del cluster). Un esempio potrebbe essere questo:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shOvviamente, gli script richiamati devono essere eseguibili, altrimenti cmon non sarà in grado di eseguirli. Ora prendiamoci un momento ed esaminiamo il processo di failover in ClusterControl e vediamo quando vengono eseguiti gli script esterni.
Processo di failover in ClusterControl
Abbiamo definito tutti gli hook disponibili:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shSuccessivamente, è necessario riavviare il processo cmon. Una volta terminato, siamo pronti per testare il failover. La topologia originale si presenta così:
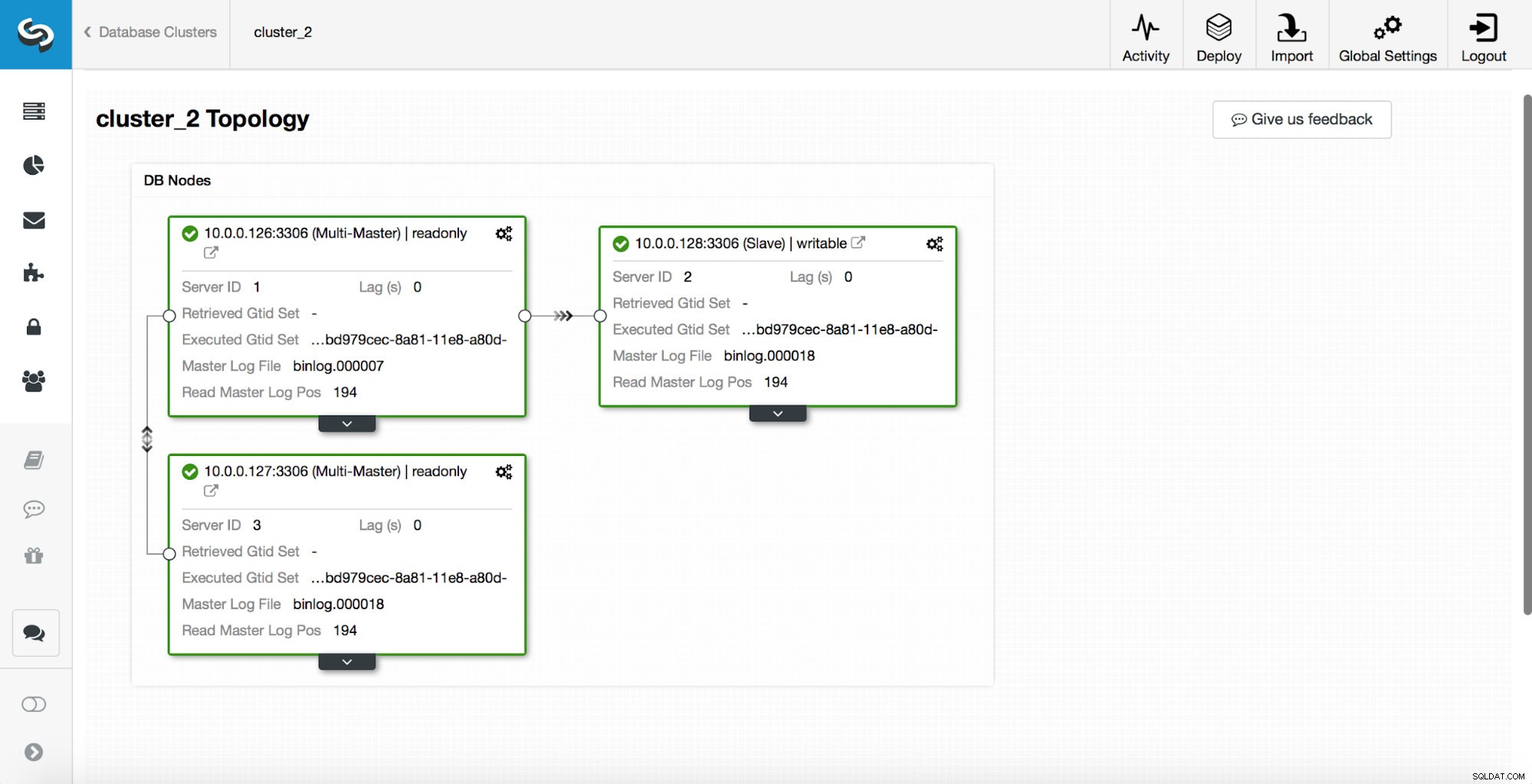
Un master è stato terminato e il processo di failover è stato avviato. Tieni presente che le voci di registro più recenti sono in alto, quindi desideri seguire il failover dal basso verso l'alto.
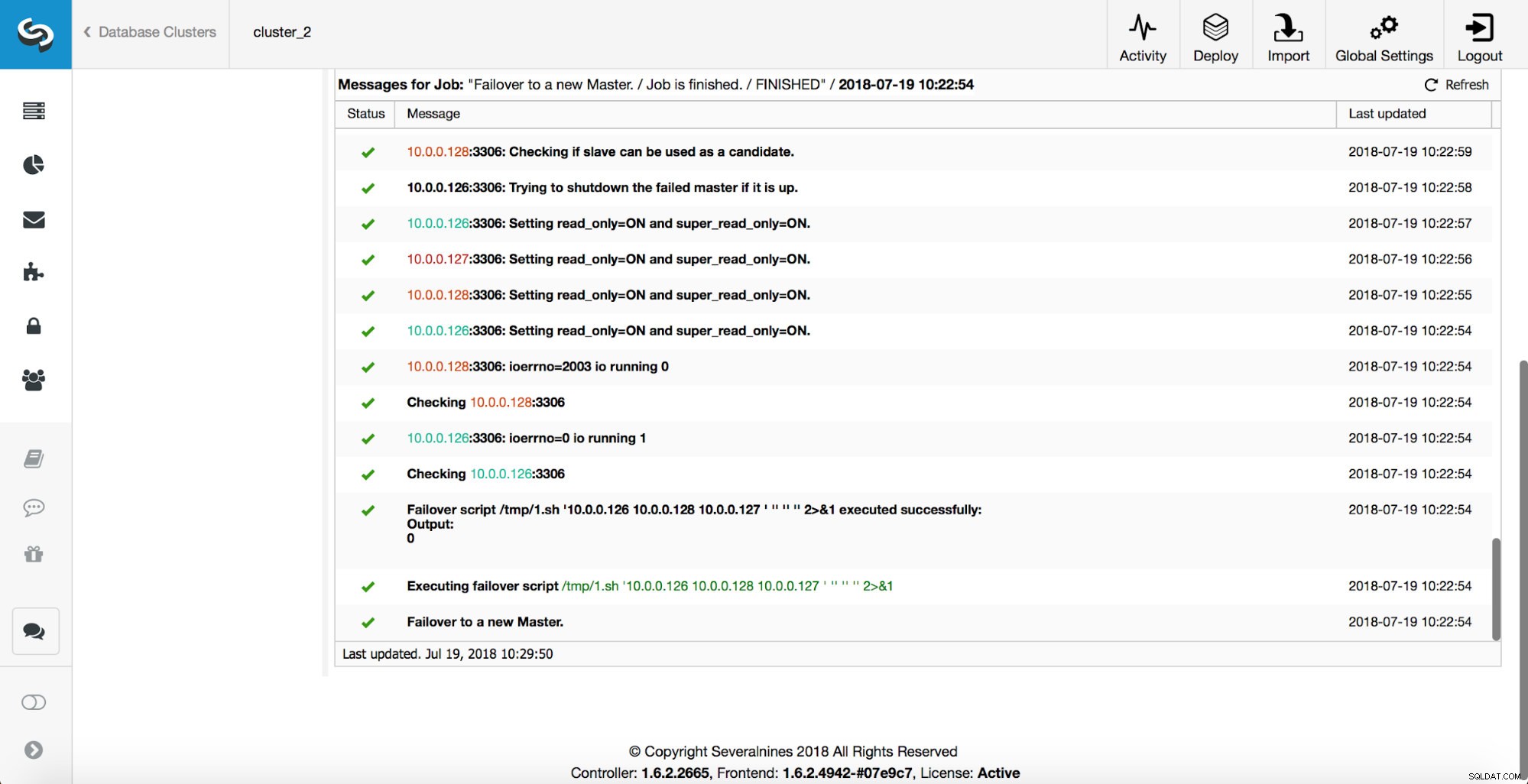
Come puoi vedere, subito dopo l'avvio del processo di failover, viene attivato l'hook "replication_onfail_failover_script". Quindi, tutti gli host raggiungibili vengono contrassegnati come di sola lettura e ClusterControl tenta di impedire l'esecuzione del vecchio master.
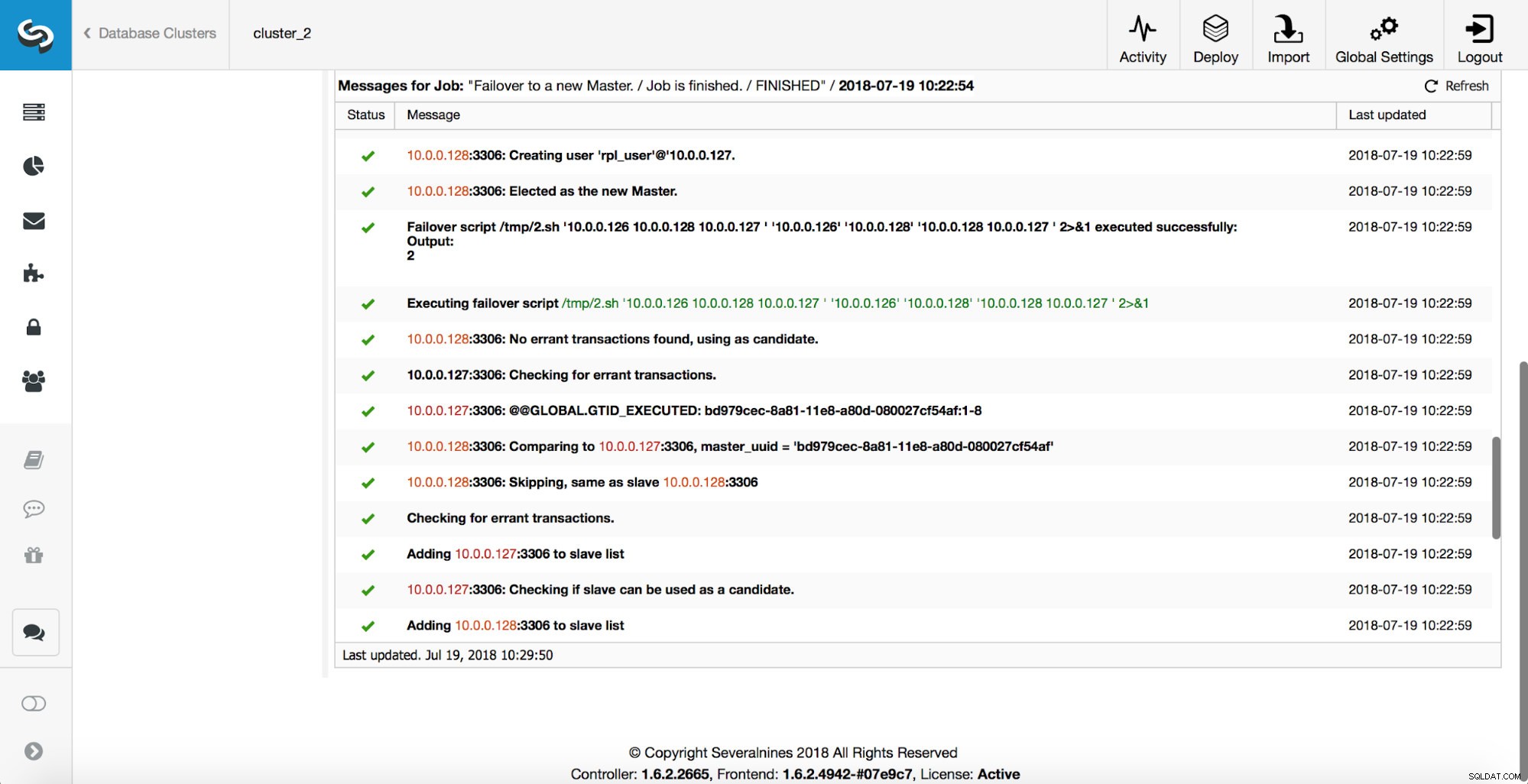
Successivamente, viene selezionato il candidato principale, vengono eseguiti i controlli di integrità. Una volta confermato che il candidato al master può essere utilizzato come nuovo master, viene eseguito il "replication_pre_failover_script".
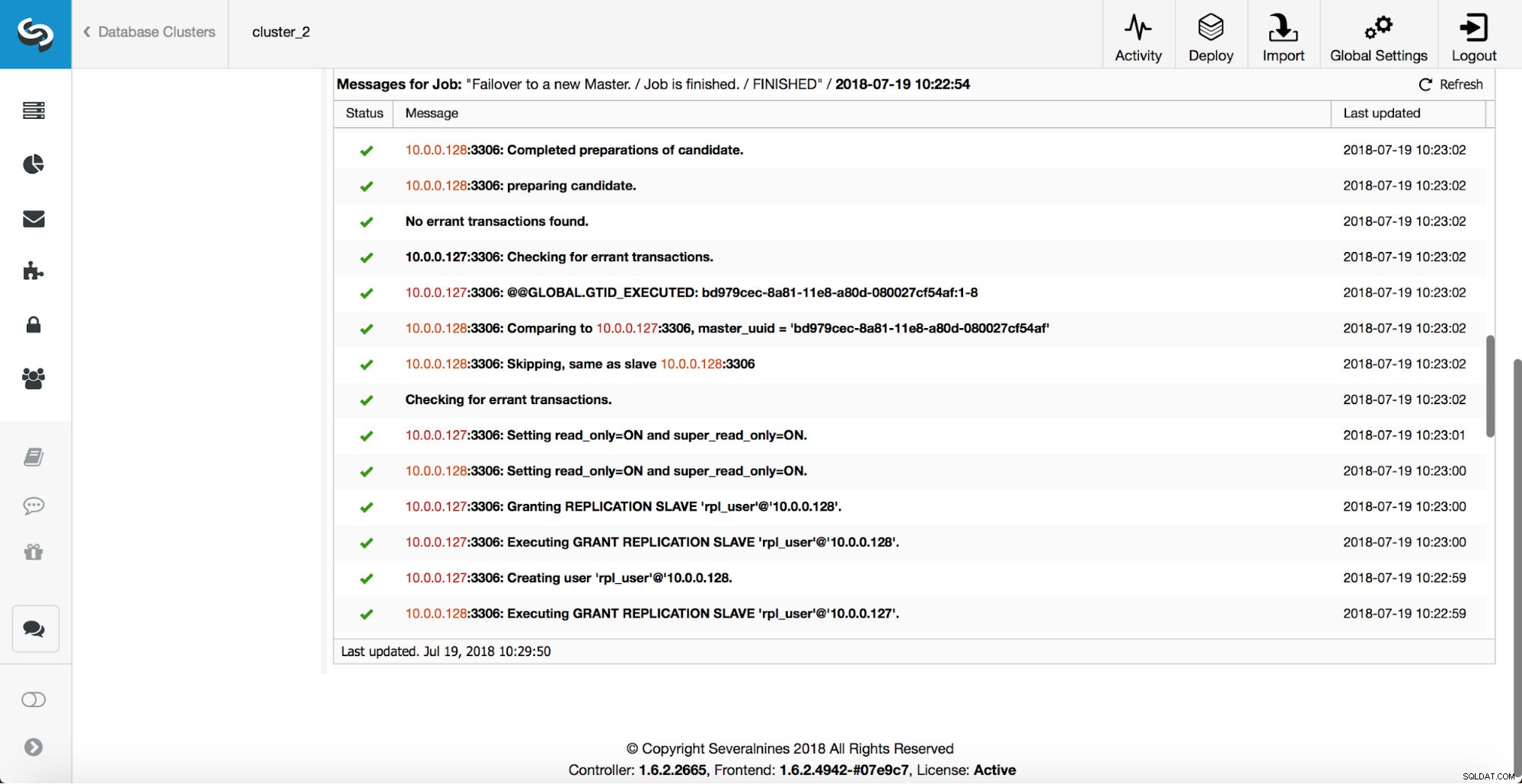
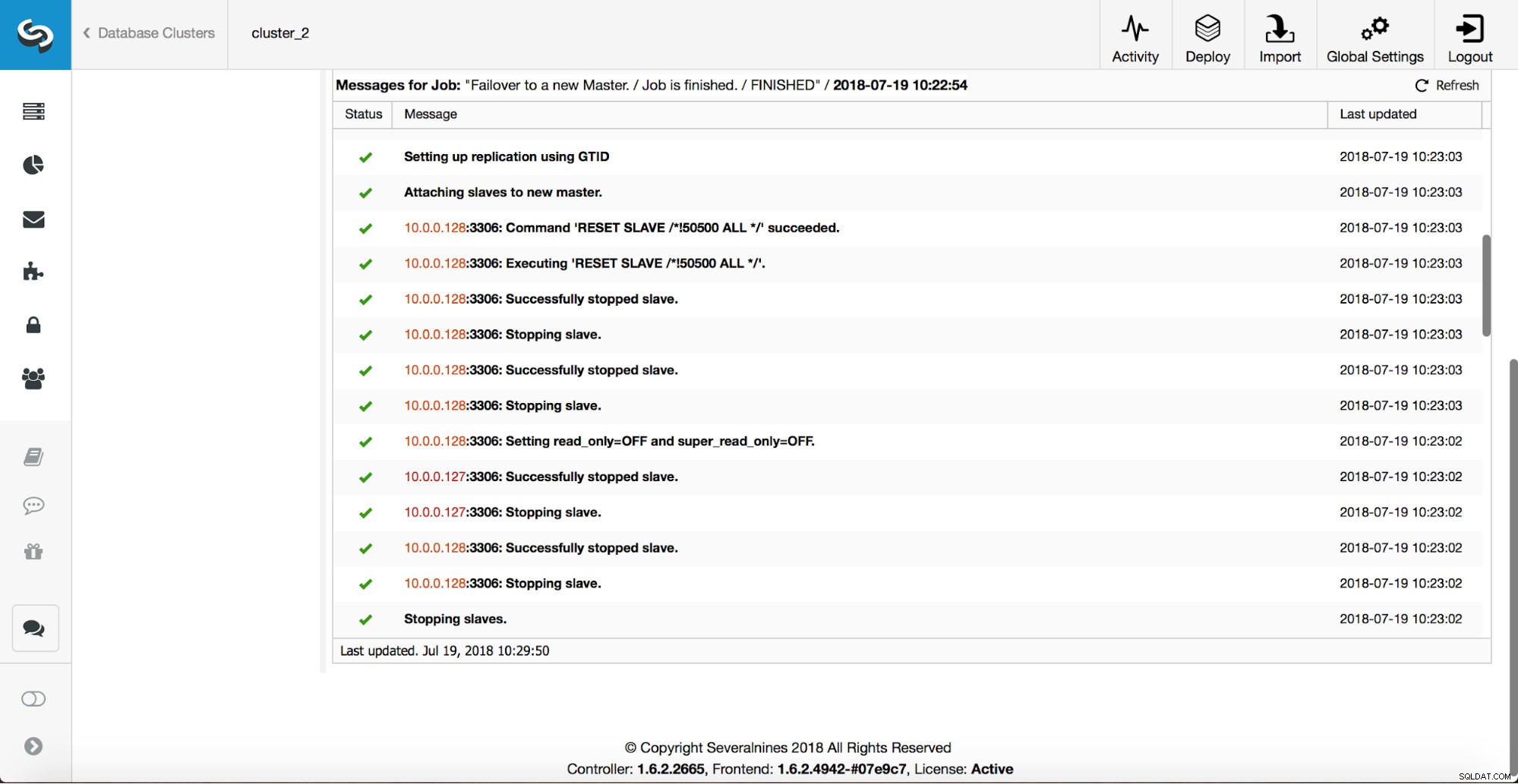
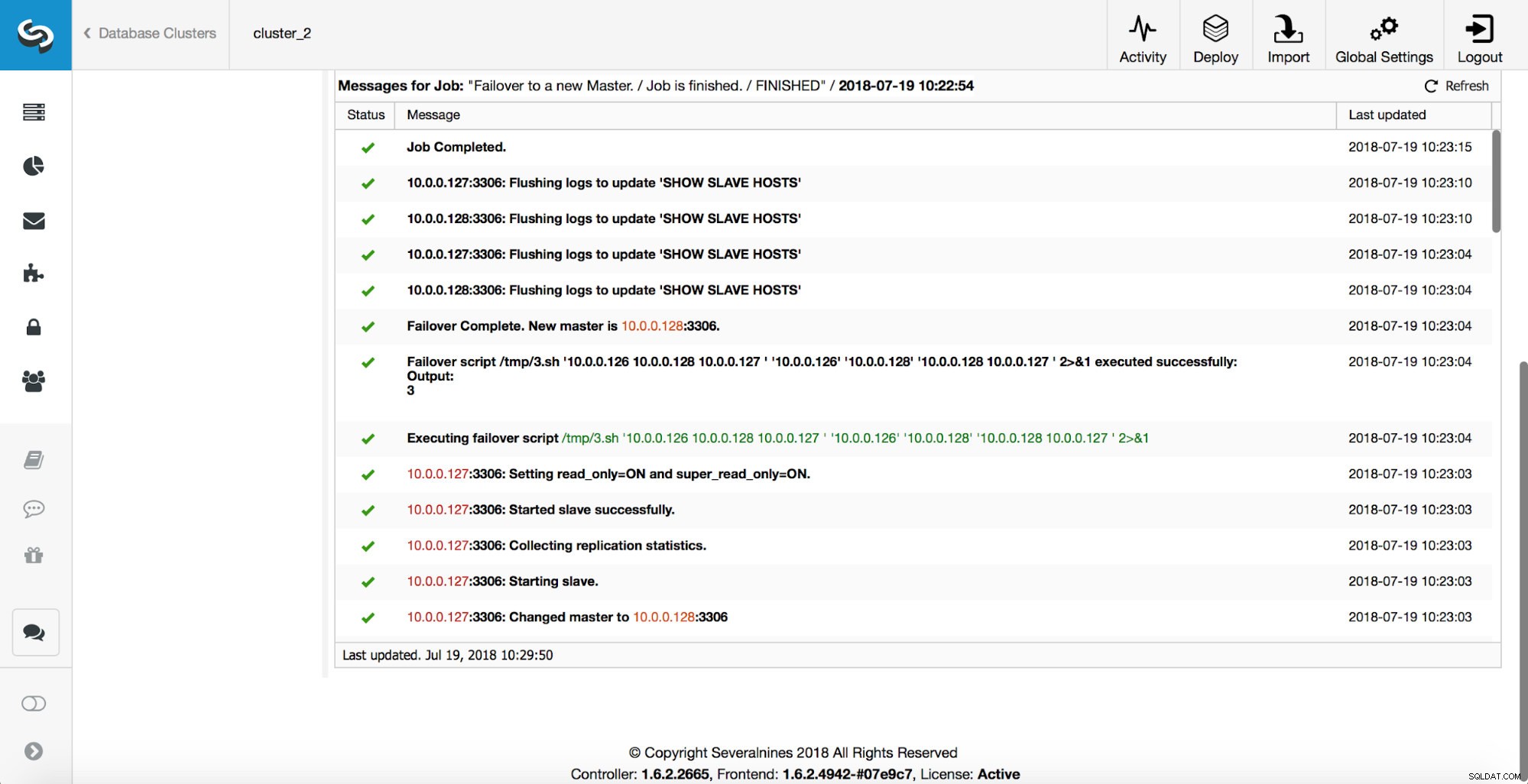
Vengono eseguiti ulteriori controlli, le repliche vengono arrestate e assegnate al nuovo master. Infine, dopo il completamento del failover, viene attivato un hook finale, "replication_post_failover_script".
Quando gli hook possono essere utili?
In questa sezione, esamineremo un paio di casi di esempio in cui potrebbe essere una buona idea implementare script esterni. Non entreremo nei dettagli in quanto sono troppo strettamente legati a un particolare ambiente. Sarà più un elenco di suggerimenti che potrebbero essere utili da implementare.
Sceneggiatura STONITH
Shoot The Other Node In The Head (STONITH) è un processo per assicurarsi che il vecchio maestro, che è morto, rimanga morto (e sì... non ci piacciono gli zombi che vagano nella nostra infrastruttura). L'ultima cosa che probabilmente vuoi è avere un vecchio master che non risponde che poi torna online e, di conseguenza, ti ritroverai con due master scrivibili. Ci sono precauzioni che puoi prendere per assicurarti che il vecchio master non venga utilizzato anche se si presenta di nuovo, ed è più sicuro che rimanga offline. I modi su come assicurarlo differiranno da ambiente a ambiente. Pertanto, molto probabilmente, non ci sarà alcun supporto integrato per STONITH nello strumento di failover. A seconda dell'ambiente, potresti voler eseguire il comando CLI che arresterà (e persino rimuoverà) una VM su cui è in esecuzione il vecchio master. Se disponi di una configurazione in loco, potresti avere un maggiore controllo sull'hardware. Potrebbe essere possibile utilizzare una sorta di gestione remota (Light-out integrato o qualche altro accesso remoto al server). Potresti anche avere accesso a prese di alimentazione gestibili e spegnere l'alimentazione in una di esse per assicurarti che il server non si avvii mai più senza l'intervento umano.
Scoperta del servizio
Abbiamo già accennato un po' alla scoperta dei servizi. Esistono numerosi modi in cui è possibile archiviare informazioni su una topologia di replica e rilevare quale host è un master. Sicuramente, una delle opzioni più popolari è usare etc.d o Consul per memorizzare i dati sulla topologia corrente. Con esso, un'applicazione o un proxy può fare affidamento su questi dati per inviare il traffico al nodo corretto. ClusterControl (proprio come la maggior parte degli strumenti che supportano la gestione del failover) non ha un'integrazione diretta né con etc.d né con Consul. L'attività per aggiornare i dati della topologia è sull'utente. Può utilizzare hook come replication_post_failover_script o replication_post_switchover_script per richiamare alcuni degli script e apportare le modifiche richieste. Un'altra soluzione piuttosto comune consiste nell'utilizzare il DNS per indirizzare il traffico verso le istanze corrette. Se manterrai basso il Time-To-Live di un record DNS, dovresti essere in grado di definire un dominio, che punterà al tuo master (es. writes.cluster1.example.com). Ciò richiede una modifica ai record DNS e, ancora una volta, hook come replication_post_failover_script o replication_post_switchover_script possono essere davvero utili per apportare le modifiche necessarie dopo che si è verificato un failover.
Riconfigurazione proxy
Ogni server proxy utilizzato deve inviare il traffico alle istanze corrette. A seconda del proxy stesso, il modo in cui viene eseguito un rilevamento principale può essere (parzialmente) codificato o può spettare all'utente definire ciò che desidera. Il meccanismo di failover di ClusterControl è progettato in modo da integrarsi bene con i proxy che ha distribuito e configurato. È comunque possibile che siano presenti proxy, che non sono stati installati da ClusterControl e richiedono l'esecuzione di alcune azioni manuali durante l'esecuzione del failover. Tali proxy possono anche essere integrati con il processo di failover ClusterControl tramite script e hook esterni come replication_post_failover_script o replication_post_switchover_script.
Registrazione aggiuntiva
Può succedere che tu voglia raccogliere i dati del processo di failover per scopi di debug. ClusterControl dispone di ampie stampe per assicurarsi che sia possibile seguire il processo e capire cosa è successo e perché. Può comunque succedere che desideri raccogliere alcune informazioni aggiuntive personalizzate. Fondamentalmente tutti gli hook possono essere utilizzati qui:puoi raccogliere lo stato iniziale, prima del failover, puoi monitorare lo stato dell'ambiente in tutte le fasi del failover.