Alcune settimane fa, ho iniziato a configurare un ambiente demo con più configurazioni di gruppi di disponibilità AlwaysOn. Avevo un cluster WSFC a 5 nodi:ogni nodo aveva un'istanza denominata autonoma di SQL Server 2012 e c'erano anche due istanze del cluster di failover (FCI) che erano state impostate su questi nodi. Un rapido diagramma:
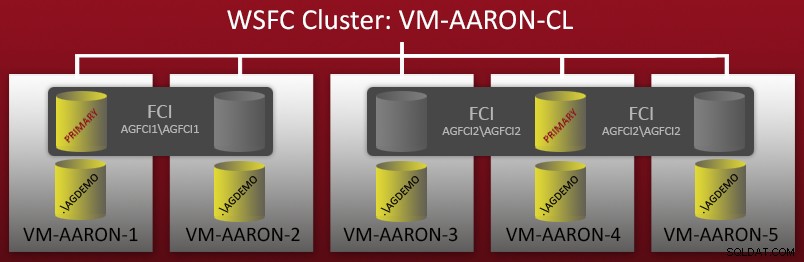
Quindi puoi vedere che ci sono 5 istanze denominate autonome (.\AGDEMO su ciascun nodo), e poi due FCI, una con possibili proprietari VM-AARON-1 e VM-AARON-2 (AGFCI1\AGFCI1 ), e poi uno con possibili proprietari VM-AARON-3, VM-AARON-4 e VM-AARON-5 (AGFCI2\AGFCI2 ). Ora, il diagramma manuale dovrebbe diventare significativamente più complesso (ne parleremo più avanti), quindi lo eviterò per ovvi motivi. In sostanza, il requisito era di avere più tipi di configurazioni AG:
- Principale su una FCI con una replica su una o più istanze standalone
- Principale su una FCI con replica su una FCI diversa
- Principale su un'istanza standalone con una replica su una o più FCI
- Principale su un'istanza autonoma con una replica su una o più istanze autonome
- Principale su un'istanza standalone con repliche sia su istanze standalone che FCI
E poi combinazioni (ove possibile) di commit sincrono e asincrono, failover manuale e automatico e secondari di sola lettura. Ci sono alcune limitazioni tecniche che limiterebbero le permutazioni possibili qui, ad esempio:
- Il failover manuale è necessario con qualsiasi replica che si trova su una FCI
- Nessun nodo WSFC può ospitare, o addirittura essere possibile proprietario di, più istanze, standalone o in cluster, che sono coinvolte nello stesso gruppo di disponibilità. Viene visualizzato questo messaggio di errore:Impossibile creare, unire o aggiungere la replica al gruppo di disponibilità "MyGroup", perché il nodo "VM-AARON-1" è un possibile proprietario sia per la replica "AGFCI1\AGFCI1" che per "VM-AARON-1\ AGDEMO'. Se una replica è un'istanza del cluster di failover, rimuovere il nodo sovrapposto dai suoi possibili proprietari e riprovare. (Microsoft SQL Server, Errore:19405)
La maggior parte degli scenari che stavo cercando di rappresentare non sono pratici negli scenari del mondo reale, ma sono in gran parte e teoricamente possibile . Se non hai ancora indovinato, questo ambiente viene configurato in modo esplicito per testare le nuove funzionalità relative ai gruppi di disponibilità che prevediamo di offrire in una versione futura di SQL Sentry. Abbiamo dato un'anteprima di alcune di queste tecnologie durante il nostro keynote con Fusion-io alla recente conferenza SQL Intersection a Las Vegas.
Ostacolo n. 1
La configurazione dei gruppi di disponibilità utilizzando la procedura guidata in SSMS è piuttosto semplice. A meno che, ad esempio, non si disponga di percorsi di file eterogenei. La procedura guidata dispone di una convalida che garantisce che gli stessi dati e percorsi di registro esistano su tutte le repliche. Questo può essere un problema se stai utilizzando il percorso dati predefinito per due diverse istanze denominate o se hai configurazioni di lettere di unità diverse (cosa che spesso accadrà quando sono coinvolti FCI).
Il controllo della compatibilità del percorso del file di database nella replica secondaria ha generato un errore. (Microsoft.SqlServer.Management.HadrTasks)I seguenti percorsi di cartella non esistono nell'istanza del server che ospita la replica secondaria VM-AARON-1\AGDEMO:
P:\MSSQL11.AGFCI2\MSSQL\DATA;
(Microsoft.SqlServer.Management.HadrTasks)
Ora dovrebbe essere ovvio che non si desidera impostare questo scenario in nessun tipo di ambiente che deve resistere alla prova del tempo. Le cose andranno a sud molto rapidamente se, ad esempio, in seguito aggiungerai un nuovo file a uno dei database. Ma per un ambiente di test/demo, proof of concept o un ambiente che prevedi sia stabile per un tempo considerevole, non preoccuparti:puoi ancora farlo senza la procedura guidata.
Sfortunatamente, per aggiungere la beffa al danno, il mago non ti permette di scriverlo. Non puoi andare oltre l'errore di convalida e non c'è nessun Script pulsante:
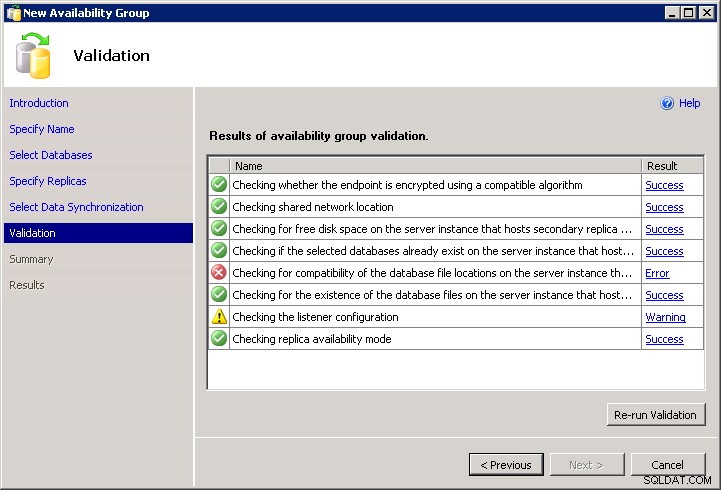
Quindi questo significa che devi codificarlo da solo (poiché il DDL non esegue alcuna convalida "utile" per te). Se hai altre istanze in cui esistono gli stessi percorsi, puoi farlo seguendo la stessa procedura guidata, superando la schermata di convalida e quindi facendo clic su Script invece di Finish , e cambia i nomi dei server e aggiungi con WITH MOVE opzioni per il ripristino iniziale. Oppure puoi semplicemente scrivere il tuo da zero, qualcosa del genere (lo script presuppone che tu abbia già configurato gli endpoint e le autorizzazioni e che tutte le istanze abbiano la funzione Gruppi di disponibilità abilitata):
-- Use SQLCMD mode and uncomment the :CONNECT commands
-- or just run the two segments separately / change connection
-- :CONNECT Server1
CREATE AVAILABILITY GROUP [GroupName]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE [Database1] --, ...
REPLICA ON -- primary:
N'Server1' WITH (ENDPOINT_URL = N'TCP://Server1:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
-- secondary:
N'Server2' WITH (ENDPOINT_URL = N'TCP://Server2:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
ALTER AVAILABILITY GROUP [GroupName]
ADD LISTENER N'ListenerName'
(WITH IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433);
BACKUP DATABASE Database1 TO DISK = '\\Server1\Share\db1.bak'
WITH INIT, COPY_ONLY, COMPRESSION;
BACKUP LOG Database1 TO DISK = '\\Server1\Share\db1.trn'
WITH INIT, COMPRESSION;
-- :CONNECT Server2
ALTER AVAILABILITY GROUP [GroupName] JOIN;
RESTORE DATABASE Database1 FROM DISK = '\\Server1\Share\db1.bak'
WITH REPLACE, NORECOVERY, NOUNLOAD,
MOVE 'data_file_name' TO 'P:\path\file.mdf',
MOVE 'log_file_name' TO 'P:\path\file.ldf';
RESTORE LOG Database1 FROM DISK = '\\Server1\Share\db1.trn'
WITH NORECOVERY, NOUNLOAD;
ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP = [GroupName]; Ostacolo n. 2
Se hai più istanze sullo stesso server, potresti scoprire che entrambe le istanze non possono condividere la porta 5022 per l'endpoint di mirroring del database (che è lo stesso endpoint utilizzato dai gruppi di disponibilità). Ciò significa che dovrai eliminare e ricreare l'endpoint per impostarlo su una porta disponibile.
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE = ALL);
Ora potrei specificare un'istanza con un endpoint su ServerName:5023 .
Ostacolo n. 3
Tuttavia, una volta eseguita questa operazione, quando sono arrivato all'ultimo passaggio dello script sopra, dopo esattamente 48 secondi, ogni volta, ho ricevuto questo messaggio di errore inutile:
Msg 35250, livello 16, stato 7, riga 2La connessione alla replica primaria non è attiva. Impossibile elaborare il comando.
Questo mi ha portato a inseguire tutti i tipi di potenziali problemi:controllare i firewall e SQL Server Configuration Manager, ad esempio, per qualsiasi cosa che avrebbe bloccato le porte tra le istanze. Nada. Ho trovato vari errori nel registro degli errori di SQL Server:
Tentativo di accesso al mirroring del database non riuscito con errore:'Handshake di connessione non riuscito. Non esiste un algoritmo di crittografia compatibile. Stato 22.'.Tentativo di accesso al mirroring del database non riuscito con errore:'Handshake di connessione non riuscito. Una chiamata del sistema operativo non riuscita:(80090303) 0x80090303 (la destinazione specificata è sconosciuta o irraggiungibile). Stato 66.'.
Si è verificato un timeout di connessione durante il tentativo di stabilire una connessione alla replica di disponibilità 'VM-AARON-1\AGDEMO' con ID [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0]. Esiste un problema di rete o firewall oppure l'indirizzo endpoint fornito per la replica non è l'endpoint di mirroring del database dell'istanza del server host.
Si scopre (e grazie a Thomas Stringer (@SQLife)) che questo problema era causato da una combinazione di sintomi:(a) Kerberos non era impostato correttamente e (b) l'algoritmo di crittografia per hadr_endpoint che avevo creato era predefinito a RC4. Ciò andrebbe bene se anche tutte le istanze autonome utilizzassero RC4, ma non lo erano. Per farla breve, ho abbandonato e ricreato gli endpoint di nuovo , su tutte le istanze. Poiché si trattava di un ambiente di laboratorio e non avevo davvero bisogno del supporto di Kerberos (e poiché avevo già investito abbastanza tempo in questi problemi da non voler inseguire anche i problemi di Kerberos), ho impostato tutti gli endpoint per utilizzare Negozia con AES:
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES,
ROLE = ALL); (Ted Krueger (@onpnt) ha recentemente scritto sul blog di un problema simile.)
Ora, finalmente, sono stato in grado di creare gruppi di disponibilità con tutti i vari requisiti che avevo, tra nodi con percorsi di file eterogenei e utilizzando più istanze sullo stesso nodo (solo non nello stesso gruppo). Ecco come apparirà una delle nostre viste di gestione AlwaysOn (fai clic per ingrandire per una panoramica molto migliore):
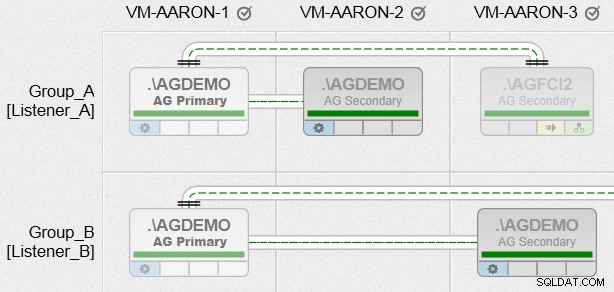
Ora, questa è solo una presa in giro, ed è del tutto intenzionale. Nelle prossime settimane scriverò di più su questa funzionalità!
Conclusione
Quando trascorri abbastanza tempo a guardare un problema, puoi trascurare alcune cose piuttosto ovvie. In questo caso c'erano alcuni problemi evidenti nascosti da alcuni messaggi di errore decisamente non intuitivi. Voglio ringraziare Joe Sack (@JosephSack), Allan Hirt (@SQLHA) e Thomas Stringer (@SQLife) per aver abbandonato tutto per aiutare un altro membro della comunità in difficoltà.