Esistono due abilità complementari molto utili nell'ottimizzazione delle query. Uno è la capacità di leggere e interpretare i piani di esecuzione. Il secondo è conoscere un po' come funziona Query Optimizer per tradurre il testo SQL in un piano di esecuzione. Mettere insieme le due cose può aiutarci a individuare i momenti in cui non è stata applicata un'ottimizzazione prevista, risultando in un piano di esecuzione che non è efficiente come potrebbe essere. Tuttavia, la mancanza di documentazione sulle ottimizzazioni che SQL Server può applicare (e in quali circostanze) significa che gran parte di questo dipende dall'esperienza.
Un esempio
La query di esempio per questo articolo si basa sulla domanda posta dall'MVP di SQL Server Fabiano Amorim alcuni mesi fa, in base a un problema riscontrato nel mondo reale. Lo schema e la query di test di seguito sono una semplificazione della situazione reale, ma conserva tutte le caratteristiche importanti.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Test 1:10.000 righe, SQL Server 2005+
I dati della tabella specifica non contano davvero per questi test. Le seguenti query caricano semplicemente 10.000 righe da una tabella di numeri in ciascuna delle tre tabelle di test:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Con i dati caricati, il piano di esecuzione prodotto per la query di test è:
SELECT MAX(c1) FROM dbo.V1;
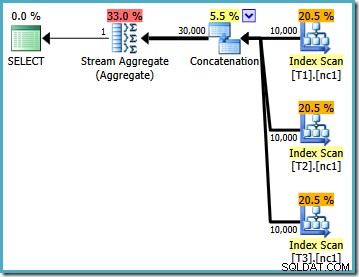
Questo piano di esecuzione è un'implementazione piuttosto diretta della query SQL logica (dopo l'espansione del riferimento di visualizzazione V1). L'ottimizzatore vede la query dopo l'espansione della vista, quasi come se la query fosse stata scritta per intero:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Confrontando il testo espanso con il piano di esecuzione, l'immediatezza dell'implementazione di Query Optimizer è chiara. C'è una scansione dell'indice per ogni lettura delle tabelle di base, un operatore di concatenazione per implementare il UNION ALL e uno Stream Aggregate per il MAX finale aggregato.
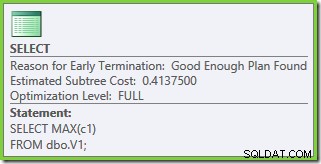
Le proprietà del piano di esecuzione mostrano che è stata avviata l'ottimizzazione basata sui costi (il livello di ottimizzazione è FULL ), ma che è terminato in anticipo perché è stato trovato un piano "abbastanza buono". Il costo stimato del piano selezionato è 0,1016240 unità di ottimizzazione magica.
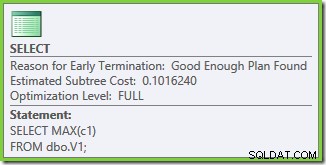
Test 2:50.000 righe, SQL Server 2008 e 2008 R2
Esegui lo script seguente per reimpostare l'ambiente di test in modo che venga eseguito con 50.000 righe:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
Il piano di esecuzione per questo test dipende dalla versione di SQL Server in esecuzione. In SQL Server 2008 e 2008 R2, otteniamo il seguente piano:
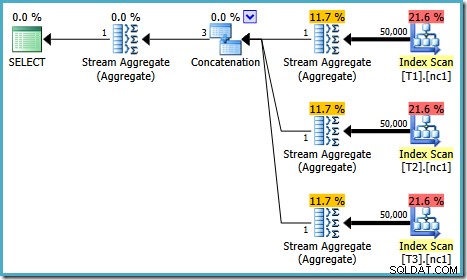
Le proprietà del piano mostrano che l'ottimizzazione basata sui costi è ancora terminata in anticipo per lo stesso motivo di prima. Il costo stimato è superiore a quello precedente a 0,41375 unità ma ciò è previsto a causa della maggiore cardinalità delle tabelle di base.
Test 3:50.000 righe, SQL Server 2005 e 2012
La stessa query eseguita nel 2005 o nel 2012 produce un piano di esecuzione diverso:
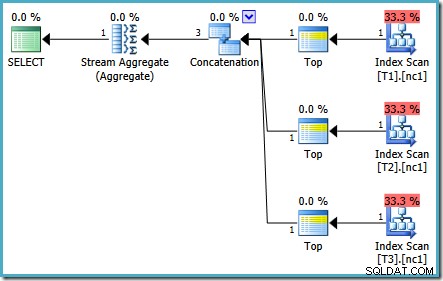
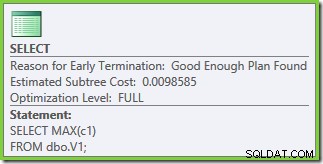
L'ottimizzazione è terminata di nuovo in anticipo, ma il costo del piano stimato per 50.000 righe per tabella di base è sceso a 0,0098585 (da 0,41375 su SQL Server 2008 e 2008 R2).
Spiegazione
Come forse saprai, Query Optimizer di SQL Server separa lo sforzo di ottimizzazione in più fasi, con fasi successive che aggiungono più tecniche di ottimizzazione e consentono più tempo. Le fasi di ottimizzazione sono:
- Piano banale
- Ottimizzazione basata sui costi
- Elaborazione della transazione (ricerca 0)
- Piano rapido (ricerca 1)
- Piano rapido con parallelismo abilitato
- Ottimizzazione completa (ricerca 2)
Nessuno dei test eseguiti qui si qualifica per un piano banale perché l'aggregato e i sindacati hanno molteplici possibilità di implementazione, che richiedono una decisione basata sui costi.
Elaborazione della transazione
La fase Transaction Processing (TP) richiede che una query contenga almeno tre riferimenti a tabelle, altrimenti l'ottimizzazione basata sui costi salta questa fase e passa direttamente a Quick Plan. La fase TP è rivolta alle query di navigazione a basso costo tipiche dei carichi di lavoro OLTP. Prova un numero limitato di tecniche di ottimizzazione e si limita a trovare piani con Nested Loop Join (a meno che non sia necessario un Hash Join per generare un piano valido).
Per alcuni aspetti è sorprendente che la query di test si qualifichi per una fase volta a trovare piani OLTP. Sebbene la query contenga i tre riferimenti di tabella richiesti, non contiene alcun join. Il requisito delle tre tabelle è solo un'euristica, quindi non lavorerò sul punto.
Quali fasi dell'ottimizzatore sono state eseguite?
Esistono diversi metodi, quello documentato consiste nel confrontare il contenuto di sys.dm_exec_query_optimizer_info prima e dopo la compilazione. Questo va bene, ma registra informazioni a livello di istanza, quindi devi fare attenzione che la tua sia l'unica compilazione di query che avviene tra gli snapshot.
Un'alternativa non documentata (ma ragionevolmente nota) che funziona su tutte le versioni attualmente supportate di SQL Server è abilitare i flag di traccia 8675 e 3604 durante la compilazione della query.
Test 1
Questo test produce un output del flag di traccia 8675 simile al seguente:

Il costo stimato di 0,101624 dopo la fase TP è sufficientemente basso da impedire all'ottimizzatore di cercare piani più economici. Il semplice piano con cui ci ritroviamo è abbastanza ragionevole data la cardinalità relativamente bassa delle tabelle di base, anche se non è veramente ottimale.
Test 2
Con 50.000 righe in ogni tabella di base, il flag di traccia rivela informazioni diverse:

Questa volta, il costo stimato dopo la fase TP è 0,428735 (più righe =maggior costo). Questo è sufficiente per incoraggiare l'ottimizzatore nella fase Quick Plan. Con più tecniche di ottimizzazione disponibili, questa fase trova un piano con un costo di 0,41375 . Questo non rappresenta un enorme miglioramento rispetto al piano di test 1, ma è inferiore alla soglia di costo predefinita per il parallelismo e non sufficiente per accedere all'ottimizzazione completa, quindi di nuovo l'ottimizzazione termina in anticipo.
Test 3
Per l'esecuzione di SQL Server 2005 e 2012, l'output del flag di traccia è:

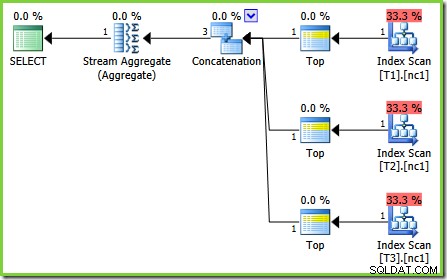
Esistono piccole differenze nel numero di attività eseguite tra le versioni, ma la differenza importante è che in SQL Server 2005 e 2012, la fase Piano rapido trova un piano che costa solo 0,0098543 unità. Questo è il piano che contiene gli operatori Top invece dei tre Stream Aggregate sotto l'operatore di concatenazione visto nei piani di SQL Server 2008 e 2008 R2.
Bug e correzioni non documentate
SQL Server 2008 e 2008 R2 contengono un bug di regressione (rispetto al 2005) che è stato corretto con il flag di traccia 4199, ma non documentato per quanto ne so. Esiste documentazione per TF 4199 che elenca le correzioni rese disponibili con flag di traccia separati prima di essere coperte da 4199, ma come dice l'articolo della Knowledge Base:
Questo flag di traccia unico può essere utilizzato per abilitare tutte le correzioni apportate in precedenza per Query Processor con molti flag di traccia. Inoltre, tutte le future correzioni di Query Processor verranno controllate utilizzando questo flag di traccia.
Il bug in questo caso è una di quelle "correzioni future di Query Processor". Una particolare regola di ottimizzazione, SclarGbAggToTop , non si applica ai nuovi aggregati visti nel piano test 2. Con il flag di traccia 4199 abilitato su build adatte di SQL Server 2008 e 2008 R2, il bug viene corretto e si ottiene il piano ottimale dal test 3:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Conclusione
Una volta che sai che l'ottimizzatore può trasformare uno scalare MIN o MAX aggregare a un TOP (1) su un flusso ordinato, il piano mostrato nel test 2 sembra strano. Gli aggregati scalari sopra una scansione dell'indice (che possono fornire un ordine se richiesto) si distinguono come un'ottimizzazione mancata che verrebbe normalmente applicata.
Questo è il punto che stavo sottolineando nell'introduzione:una volta che hai un'idea del tipo di cose che l'ottimizzatore può fare, può aiutarti a riconoscere i casi in cui qualcosa è andato storto.
La risposta non sarà sempre abilitare il flag di traccia 4199, poiché potresti riscontrare problemi che non sono stati ancora risolti. Potresti anche non volere che le altre correzioni QP coperte dal flag di traccia si applichino in un caso particolare:le correzioni dell'ottimizzatore non migliorano sempre le cose. In tal caso, non sarebbe necessario proteggersi da sfortunate regressioni del piano utilizzando questo flag.
La soluzione in altri casi potrebbe essere formulare la query SQL utilizzando una sintassi diversa, suddividere la query in blocchi più compatibili con l'ottimizzatore o qualcos'altro completamente. Qualunque sia la risposta, vale comunque la pena conoscere un po' gli interni dell'ottimizzatore in modo da poter riconoscere che c'è stato un problema in primo luogo :)