T-SQL Tuesday #78 è ospitato da Wendy Pastrick e la sfida di questo mese è semplicemente "imparare qualcosa di nuovo e bloggarlo". Il suo blurb si orienta verso le nuove funzionalità di SQL Server 2016, ma poiché ho bloggato e presentato molte di queste, ho pensato di esplorare in prima persona qualcos'altro di cui sono sempre stato veramente curioso.
Ho visto più persone affermare che un heap può essere migliore di un indice cluster per determinati scenari. Non posso essere in disaccordo con questo. Uno dei motivi interessanti che ho visto affermato, tuttavia, è che una ricerca RID è più veloce di una ricerca chiave. Sono un grande fan degli indici cluster e non un grande fan degli heap, quindi ho sentito che questo richiedeva alcuni test.
Allora, proviamolo!
Ho pensato che sarebbe stato utile creare un database con due tabelle, identiche tranne per il fatto che una aveva una chiave primaria in cluster e l'altra aveva una chiave primaria non in cluster. Vorrei caricare alcune righe nella tabella, aggiornare un gruppo di righe in un ciclo e selezionare da un indice (forzando una ricerca chiave o RID).
Specifiche di sistema
Questa domanda sorge spesso, quindi per chiarire i dettagli importanti su questo sistema, sono su una VM a 8 core con 32 GB di RAM, supportata da storage PCIe. La versione di SQL Server è 2014 SP1 CU6, senza modifiche speciali alla configurazione o flag di traccia in esecuzione:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)Apr 13 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) su Windows NT 6.3
Il database
Ho creato un database con molto spazio libero sia nei dati che nel file di registro per evitare che eventuali eventi di crescita automatica interferiscano con i test. Ho anche impostato il database sul ripristino semplice per ridurre al minimo l'impatto sul registro delle transazioni.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
I tavoli
Come ho detto, due tabelle, con l'unica differenza se la chiave primaria è in cluster.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Una tabella per acquisire il tempo di esecuzione
Potrei monitorare la CPU e tutto il resto, ma in realtà la curiosità riguarda quasi sempre il runtime. Quindi ho creato una tabella di registrazione per acquisire il runtime di ogni test:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Il test di inserimento
Quindi, quanto tempo ci vuole per inserire 2.000 righe, 100 volte? Sto raccogliendo alcuni dati piuttosto basilari da sys.all_objects e trascinando la definizione per qualsiasi procedura, funzione, ecc.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Il test di aggiornamento
Per il test di aggiornamento, volevo solo testare la velocità di scrittura su un indice cluster rispetto a un heap in modo molto riga per riga. Quindi ho scaricato 200 righe casuali in una tabella #temp, quindi ho creato un cursore attorno ad essa (la tabella #temp garantisce semplicemente che le stesse 200 righe vengano aggiornate in entrambe le versioni della tabella, il che probabilmente è eccessivo).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Il test di selezione
Quindi, sopra hai visto che ho creato un indice con Name come colonna chiave in ogni tabella; per valutare il costo dell'esecuzione di ricerche per una quantità significativa di righe, ho scritto una query che assegna l'output a una variabile (eliminando I/O di rete e tempo di rendering del client), ma forza l'uso dell'indice:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Per questo ho voluto mostrare alcuni aspetti interessanti dei piani prima di confrontare i risultati del test. L'esecuzione individuale testa a testa fornisce queste metriche comparative:

La durata è irrilevante per una singola affermazione, ma guarda quelle letture. Se utilizzi uno storage lento, è una grande differenza che non vedrai su scala ridotta e/o sul tuo SSD di sviluppo locale.
E poi i piani che mostrano le due diverse ricerche, utilizzando SQL Sentry Plan Explorer:

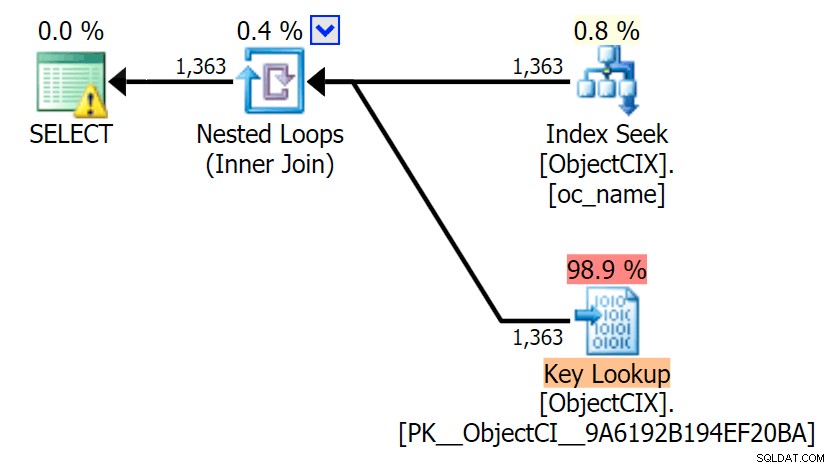
I piani sembrano quasi identici e potresti non notare la differenza nelle letture in SSMS a meno che tu non stia acquisendo Statistics I/O. Anche i costi di I/O stimati per le due ricerche erano simili:1,69 per la ricerca chiave e 1,59 per la ricerca RID. (L'icona di avviso in entrambi i piani è per un indice di copertura mancante.)
È interessante notare che se non forziamo una ricerca e consentiamo a SQL Server di decidere cosa fare, sceglie una scansione standard in entrambi i casi, nessun avviso di indice mancante e guarda quanto sono più vicine le letture:

L'ottimizzatore sa che una scansione sarà molto più economica delle ricerche + ricerche in questo caso. Ho scelto una colonna LOB per l'assegnazione delle variabili solo per effetto, ma i risultati sono stati simili anche utilizzando una colonna non LOB.
I risultati del test
Con la tabella Tempi attiva, sono stato in grado di eseguire facilmente i test più volte (ho eseguito una dozzina di test) e quindi ottenere le medie per i test con la seguente query:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
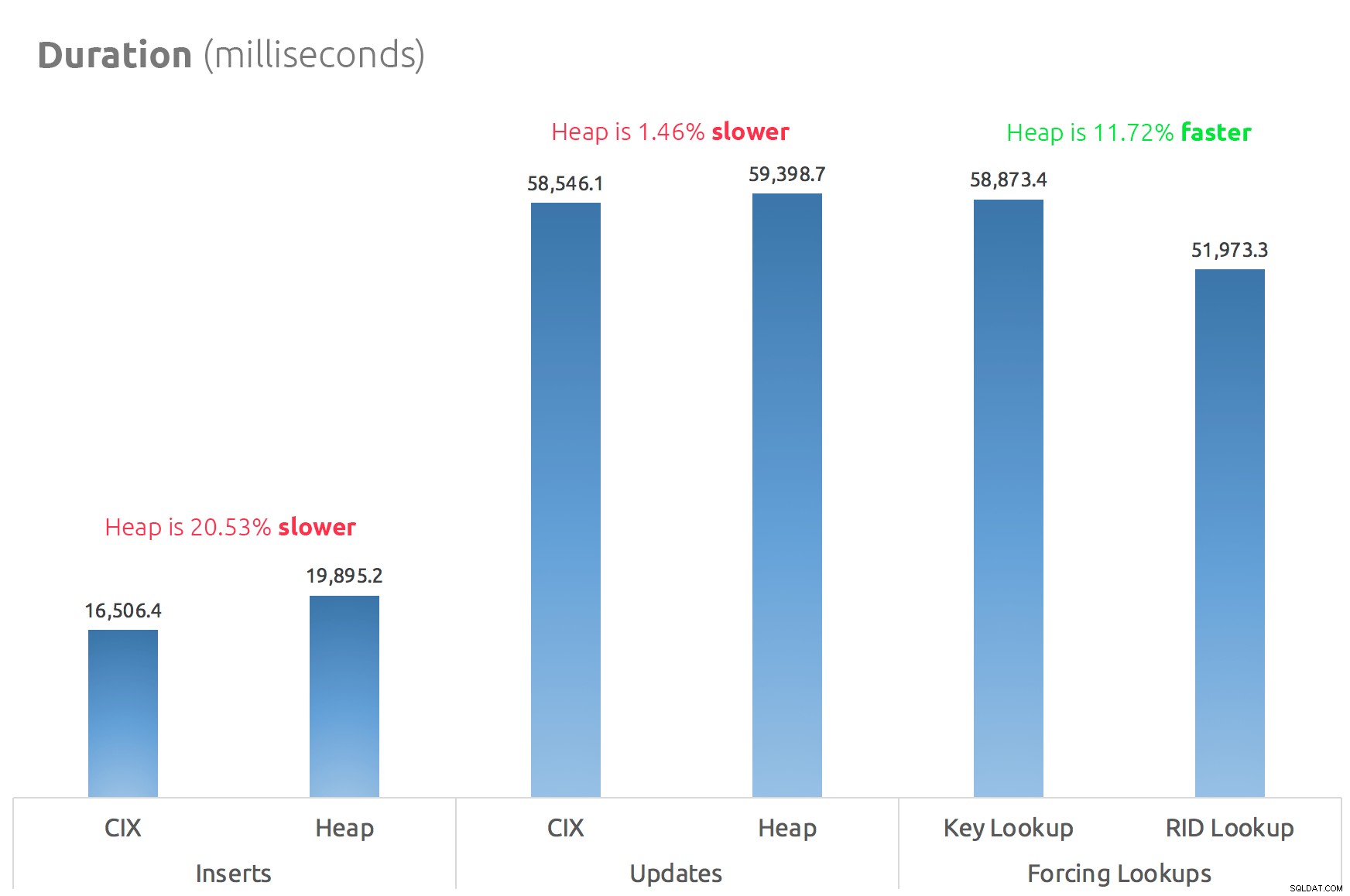
Un semplice grafico a barre mostra come si confrontano:
Conclusione
Quindi, le voci sono vere:almeno in questo caso, una ricerca RID è significativamente più veloce di una ricerca chiave. Andare direttamente su file:page:slot è ovviamente più efficiente in termini di I/O che seguire il b-tree (e se non sei su uno storage moderno, il delta potrebbe essere molto più evidente).
Se vuoi trarne vantaggio e portare con te tutti gli altri aspetti dell'heap, dipenderà dal tuo carico di lavoro:l'heap è leggermente più costoso per le operazioni di scrittura. Ma questo non definitivo:potrebbe variare notevolmente a seconda della struttura della tabella, degli indici e dei modelli di accesso.
Ho testato cose molto semplici qui e, se sei indeciso su questo, consiglio vivamente di testare il tuo carico di lavoro effettivo sul tuo hardware e di confrontare tu stesso (e non dimenticare di testare lo stesso carico di lavoro in cui sono presenti gli indici di copertura; probabilmente otterrai prestazioni complessive molto migliori se puoi semplicemente eliminare del tutto le ricerche). Assicurati di misurare tutte le metriche che sono importanti per te; solo perché mi concentro sulla durata non significa che sia quella a cui devi preoccuparti di più. :-)