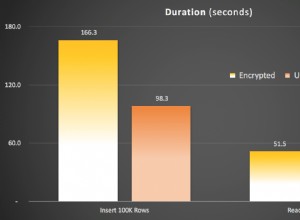
Quando è necessario implementare un sistema di analisi per un'azienda, spesso ci si chiede dove devono essere archiviati i dati. Non sempre esiste un'opzione perfetta per tutti i requisiti e dipende dal budget, dalla quantità di dati e dalle esigenze dell'azienda.
PostgreSQL, in quanto database open source più avanzato, è così flessibile che può fungere da semplice database relazionale, database di serie temporali e persino come soluzione di data warehousing efficiente ea basso costo. Puoi anche integrarlo con diversi strumenti di analisi.
Se stai cercando un data warehouse ampiamente compatibile, a basso costo e performante, la migliore opzione di database potrebbe essere PostgreSQL, ma perché? In questo blog vedremo cos'è un data warehouse, perché è necessario e perché PostgreSQL potrebbe essere l'opzione migliore qui.
Cos'è un Data Warehouse
Un Data Warehouse è un sistema standardizzato, coerente e integrato che contiene dati attuali o storici da una o più fonti utilizzati per il reporting e l'analisi dei dati. È considerata una componente fondamentale della business intelligence, ovvero la strategia e la tecnologia utilizzate da un'azienda per una migliore comprensione del proprio contesto commerciale.
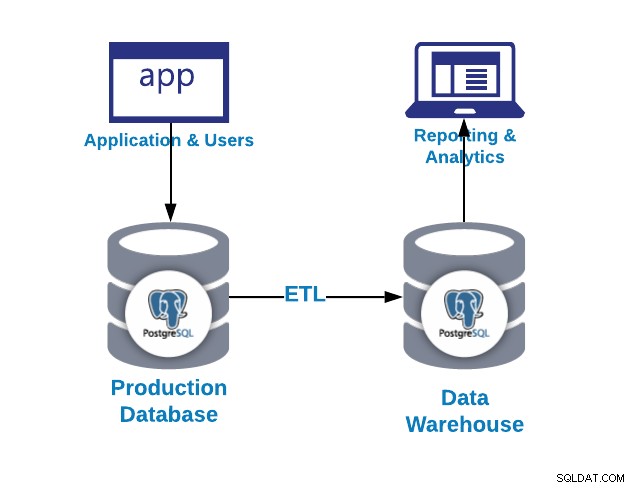
La prima domanda che potresti porre è perché ho bisogno di un data warehouse?
- Integrazione:integra/centralizza i dati da più sistemi/database
- Standardizza:standardizza tutti i dati nello stesso formato
- Analytics:analizza i dati in un contesto storico
Alcuni dei vantaggi di un data warehouse possono essere...
- Integra i dati da più origini in un unico database
- Evita il blocco o il caricamento della produzione a causa di query di lunga durata
- Memorizza informazioni storiche
- Ristruttura i dati per adattarli ai requisiti di analisi
Come abbiamo potuto vedere nell'immagine precedente, possiamo usare PostgreSQL sia per le proposte OLAP che OLTP. Vediamo la differenza.
- OLTP:elaborazione delle transazioni online. In generale, ha un gran numero di brevi transazioni on-line (INSERT, UPDATE, DELETE) generate dall'attività dell'utente. Questi sistemi enfatizzano l'elaborazione delle query molto veloce e il mantenimento dell'integrità dei dati in ambienti ad accesso multiplo. Qui, l'efficacia è misurata dal numero di transazioni al secondo. I database OLTP contengono dati dettagliati e aggiornati.
- OLAP:elaborazione analitica online. In generale, ha un basso volume di transazioni complesse generate da report di grandi dimensioni. Il tempo di risposta è una misura di efficacia. Questi database archiviano dati storici aggregati in schemi multidimensionali. I database OLAP vengono utilizzati per analizzare dati multidimensionali da più fonti e prospettive.
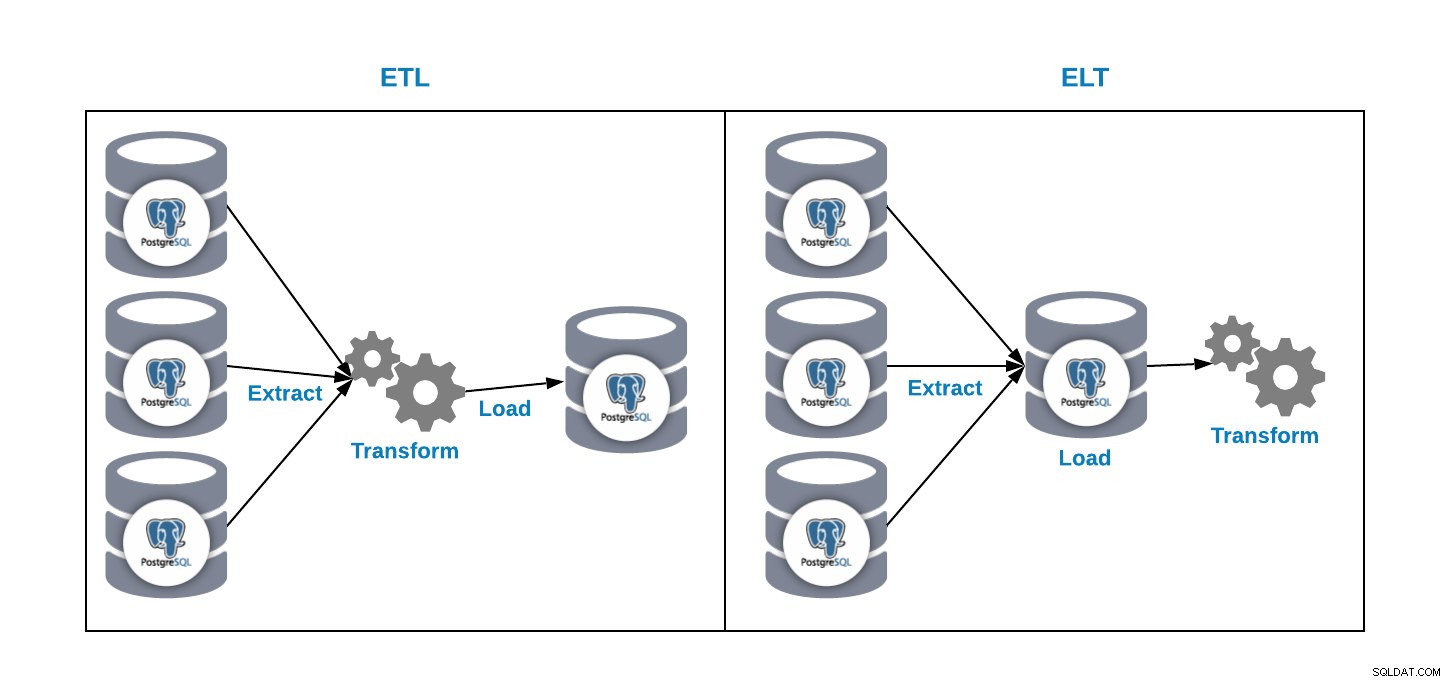
Abbiamo due modi per caricare i dati nel nostro database di analisi:
- ETL:estrai, trasforma e carica. Questo è il modo per generare il nostro data warehouse. Innanzitutto, estrai i dati dal database di produzione, trasforma i dati in base alle nostre esigenze, quindi carica i dati nel nostro data warehouse.
- ELT:estrai, carica e trasforma. Innanzitutto, estrai i dati dal database di produzione, caricali nel database e quindi trasforma i dati. In questo modo si chiama Data Lake ed è un nuovo concetto per gestire i nostri big data.
E ora, la seconda domanda i, perché dovrei usare PostgreSQL per il mio data warehouse?
Vantaggi di PostgreSQL come data warehouse
Diamo un'occhiata ad alcuni dei vantaggi dell'utilizzo di PostgreSQL come data warehouse...
- Costo:se stai utilizzando un ambiente on-premise, il costo del prodotto stesso sarà di $ 0, anche se stai utilizzando un prodotto nel cloud, probabilmente il costo di un prodotto basato su PostgreSQL sarà inferiore a il resto dei prodotti.
- Ridimensionamento:puoi ridimensionare le letture in modo semplice aggiungendo tutti i nodi di replica che desideri.
- Prestazioni:con una configurazione corretta, PostgreSQL ha prestazioni davvero buone in diversi scenari.
- Compatibilità:puoi integrare PostgreSQL con strumenti o applicazioni esterni per data mining, OLAP e reporting.
- Estensibilità:PostgreSQL ha tipi di dati e funzioni definiti dall'utente.
Ci sono anche alcune funzionalità di PostgreSQL che possono aiutarci a gestire le nostre informazioni sul data warehouse...
- Tabelle temporanee:è una tabella di breve durata che esiste per la durata di una sessione di database. PostgreSQL elimina automaticamente le tabelle temporanee al termine di una sessione o di una transazione.
- Procedure memorizzate:puoi usarlo per creare procedure o funzionare su più linguaggi (PL/pgSQL, PL/Perl, PL/Python, ecc.).
- Partizionamento:è molto utile per la manutenzione del database, le query che utilizzano la chiave di partizione e le prestazioni INSERT.
- Vista materializzata:i risultati della query vengono visualizzati come una tabella.
- Tablespaces:puoi modificare la posizione dei dati su un disco diverso. In questo modo avrai accesso al disco parallelizzato.
- Compatibile PITR:puoi creare backup compatibili con il ripristino point-in-time, quindi in caso di errore, puoi ripristinare lo stato del database in un determinato periodo di tempo.
- Community enorme:e, ultimo ma non meno importante, PostgreSQL ha una vasta comunità in cui puoi trovare supporto su molti problemi diversi.
Configurazione di PostgreSQL per l'utilizzo di Data Warehouse
Non esiste una configurazione migliore da utilizzare in tutti i casi e in tutte le tecnologie di database. Dipende da molti fattori come hardware, utilizzo e requisiti di sistema. Di seguito sono riportati alcuni suggerimenti per configurare il database PostgreSQL in modo che funzioni come un data warehouse nel modo corretto.
Basato sulla memoria
- max_connections:come database di data warehouse, non hai bisogno di una quantità elevata di connessioni perché verrà utilizzata per il lavoro di reportistica e analisi, quindi puoi limitare il numero massimo di connessioni utilizzando questo parametro.
- shared_buffers:imposta la quantità di memoria utilizzata dal server di database per i buffer di memoria condivisa. Un valore ragionevole può essere compreso tra il 15% e il 25% della memoria RAM.
- efficace_cache_size:questo valore viene utilizzato dal pianificatore di query per tenere conto dei piani che possono o meno rientrare nella memoria. Questo è preso in considerazione nelle stime dei costi dell'utilizzo di un indice; un valore alto rende più probabile l'utilizzo delle scansioni dell'indice e un valore basso rende più probabile l'utilizzo di scansioni sequenziali. Un valore ragionevole sarebbe circa il 75% della memoria RAM.
- work mem:specifica la quantità di memoria che verrà utilizzata dalle operazioni interne delle tabelle ORDER BY, DISTINCT, JOIN e hash prima di scrivere sui file temporanei su disco. Quando si configura questo valore, dobbiamo tenere conto del fatto che diverse sessioni stanno eseguendo queste operazioni contemporaneamente e ogni operazione potrà utilizzare tutta la memoria specificata da questo valore prima che inizi a scrivere i dati nei file temporanei. Un valore ragionevole può aggirarsi intorno al 2% della memoria RAM.
- maintenance_work_mem:specifica la quantità massima di memoria utilizzata dalle operazioni di manutenzione, ad esempio VACUUM, CREATE INDEX e ALTER TABLE ADD FOREIGN KEY. Un valore ragionevole può aggirarsi intorno al 15% della memoria RAM.
Basato su CPU
- Max_worker_processes:imposta il numero massimo di processi in background che il sistema può supportare. Un valore ragionevole può essere il numero di CPU.
- Max_parallel_workers_per_gather:imposta il numero massimo di lavoratori che possono essere avviati da un singolo nodo Gather o Gather Merge. Un valore ragionevole può essere il 50% del numero di CPU.
- Max_parallel_workers:imposta il numero massimo di lavoratori che il sistema può supportare per le query parallele. Un valore ragionevole può essere il numero di CPU.
Poiché i dati caricati nel nostro data warehouse non dovrebbero cambiare, possiamo anche disattivare Autovacuum per evitare un carico aggiuntivo sul database PostgreSQL. I processi Vacuum e Analyze possono far parte del processo di caricamento batch.
Conclusione
Se stai cercando un data warehouse ampiamente compatibile, a basso costo e ad alte prestazioni, dovresti assolutamente considerare PostgreSQL come un'opzione per il tuo database di data warehouse. PostgreSQL offre molti vantaggi e funzionalità utili per gestire il nostro data warehouse come il partizionamento o le procedure archiviate e altro ancora.