Considerando l'attuale principale caso d'uso di un database relativo al recupero dei dati, diventa molto importante che le sue prestazioni siano molto elevate e possono essere raggiunte solo se i dati vengono recuperati nel modo più efficiente possibile dall'archiviazione. Ci sono state molte invenzioni e implementazioni di successo fatte per ottenere lo stesso risultato. Uno degli approcci ben noti adottati dalla maggior parte dei database consiste nell'avere un indice sul tavolo.
Cos'è un indice di database?
Database Index, come suggerisce il nome, mantiene un indice dei dati effettivi e quindi migliora le prestazioni per recuperare i dati dalla tabella effettiva. In una terminologia più del database, l'indice consente di recuperare la pagina contenente i dati indicizzati in un attraversamento molto minimo poiché i dati vengono ordinati in un ordine specifico. Il vantaggio dell'indice viene al costo di spazio di archiviazione aggiuntivo per scrivere dati aggiuntivi. Gli indici sono specifici della tabella sottostante e sono costituiti da una o più chiavi (ovvero una o più colonne della tabella specificata). Esistono principalmente due tipi di architettura dell'indice
- Indice cluster:i dati dell'indice vengono archiviati insieme ad altre parti di dati e i dati vengono ordinati in base alla chiave dell'indice. Al massimo può esserci un solo indice in questa categoria per una tabella specificata.
- Indice non cluster:i dati dell'indice vengono archiviati separatamente e hanno un puntatore all'archiviazione in cui è archiviata l'altra parte dei dati. Questo è anche noto come indice secondario. Ci possono essere tutti gli indici di questa categoria che vuoi su una tabella specifica.
Esistono varie strutture di dati utilizzate per implementare gli indici, alcune delle ampiamente adottate dalla maggior parte dei database sono B-Tree e Hash.
Cos'è un indice PostgreSQL?
PostgreSQL supporta solo indici non cluster. Ciò significa indicizzare i dati e dati completi (di seguito denominati dati heap ) sono conservati in un archivio separato. Gli indici non raggruppati sono come "Tabella dei contenuti" in qualsiasi documento, in cui prima controlliamo il numero di pagina e quindi controlliamo quei numeri di pagina per leggere l'intero contenuto. Per ottenere i dati completi in base a un indice, mantiene un puntatore ai dati heap corrispondenti. È lo stesso che dopo aver conosciuto il numero di pagina, è necessario andare a quella pagina e ottenere il contenuto effettivo della pagina.
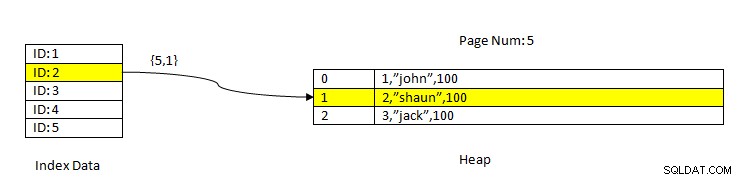 PostgreSQL:lettura dei dati tramite Index
PostgreSQL:lettura dei dati tramite Index Ad esempio, considera una tabella con tre colonne e un indice sulla colonna ID . Per LEGGERE i dati in base alla chiave ID=2, viene innanzitutto ricercato il dato indicizzato con il valore ID 2. Questo contiene un puntatore (denominato Item Pointer) in termini di numero di pagina (cioè numero di blocco) e offset di dati all'interno di quella pagina. Nell'esempio corrente, l'indice punta alla pagina numero 5 e al secondo elemento di riga nella pagina che a sua volta mantiene l'offset rispetto all'intero dato(2,"Shaun",100). Notare che i dati interi contengono anche i dati indicizzati, il che significa che gli stessi dati vengono ripetuti in due archivi.
In che modo INDEX aiuta a migliorare le prestazioni? Bene, per selezionare qualsiasi record INDEX, non esegue la scansione di tutte le pagine in sequenza, ma deve solo eseguire la scansione parziale di alcune pagine utilizzando la struttura dei dati dell'indice sottostante. Ma c'è una svolta, dal momento che ogni record trovato dai dati dell'indice, deve cercare nei dati dell'heap tutti i dati, che causano molti I/O casuali e si ritiene che funzionino più lentamente dell'I/O sequenziale. Quindi, solo se viene selezionata una piccola percentuale di record (che è stato deciso in base al costo dell'ottimizzatore PostgreSQL), solo PostgreSQL sceglie Scansione indice, altrimenti, anche se è presente un indice sul tavolo, continua a utilizzare Scansione sequenziale.
In sintesi, sebbene la creazione dell'indice acceleri le prestazioni, dovrebbe essere scelto con attenzione in quanto ha un sovraccarico in termini di archiviazione e prestazioni INSERT ridotte.
Ora potremmo chiederci, nel caso in cui abbiamo bisogno solo della parte dell'indice dei dati, possiamo recuperare solo dalla pagina di archiviazione dell'indice? Bene, la risposta a questa è direttamente correlata al modo in cui MVCC funziona sullo storage dell'indice, come spiegato di seguito.
Utilizzo di MVCC per l'indicizzazione
Come le pagine Heap, la pagina dell'indice mantiene più versioni della tupla dell'indice ma non mantiene le informazioni sulla visibilità. Come spiegato nel mio precedente MVCC blog, per decidere la versione visibile adatta delle tuple, richiede il confronto delle transazioni. La transazione che ha inserito/aggiornato/eliminato la tupla viene mantenuta insieme alla tupla dell'heap ma lo stesso non viene mantenuto con la tupla dell'indice. Questo viene fatto esclusivamente per risparmiare spazio di archiviazione ed è un compromesso tra spazio e prestazioni.
Ora tornando alla domanda originale, poiché le informazioni sulla visibilità nella tupla dell'indice non sono presenti, è necessario consultare la tupla dell'heap corrispondente per vedere se i dati selezionati sono visibili. Quindi, anche se non sono richieste altre parti dei dati dalla tupla dell'heap, è comunque necessario accedere alle pagine dell'heap per verificarne la visibilità. Ma ancora una volta, c'è una svolta nel caso in cui tutte le tuple su una determinata pagina (pagina puntata dall'indice, ad esempio ItemPointer) siano visibili, quindi non è necessario fare riferimento a ogni elemento della pagina Heap per il "controllo di visibilità" e quindi i dati possono essere restituiti solo dalla pagina Indice. Questo caso speciale è chiamato "Scansione solo indice". Per supportare questo, PostgreSQL mantiene una mappa di visibilità per ogni pagina per verificare la visibilità a livello di pagina.
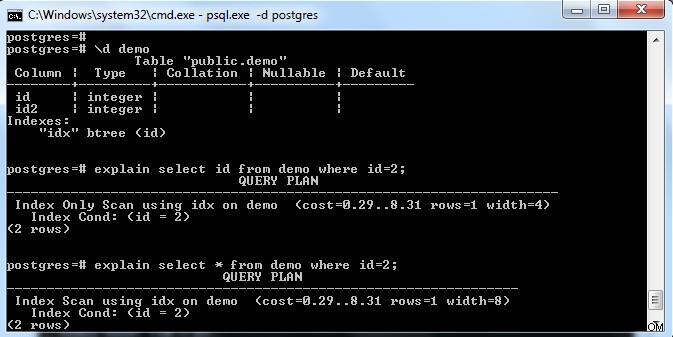
Come mostrato nell'immagine sopra, c'è un indice sulla tabella "demo" con una chiave sulla colonna "id". Se proviamo a selezionare solo il campo indice (cioè id), allora ha scelto "Scansione solo indice" (considerando la pagina di riferimento completamente visibile).
Indice cluster
Non esiste il supporto dell'indice cluster diretto in PostgreSQL, ma esiste un modo indiretto per ottenere parzialmente lo stesso. Ciò si ottiene con i seguenti comandi SQL:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Il primo comando indica al database di raggruppare una tabella (cioè di ordinare la tabella) utilizzando l'indice specificato. Questo indice dovrebbe essere già stato creato. Questo raggruppamento è solo un'operazione una tantum e il suo impatto non rimane dopo l'operazione successiva su questa tabella, ad esempio se vengono inseriti/aggiornati più record, la tabella potrebbe non rimanere ordinata. Se l'utente ha bisogno di mantenere la tabella in cluster (ordinata), può utilizzare il primo comando senza fornire un nome di indice.
Il secondo comando è utile solo per raggruppare nuovamente la tabella (ovvero la tabella che era già raggruppata utilizzando alcuni indici). Questo comando riordina tutte le tabelle nel database corrente visibili all'utente connesso corrente.
Ad esempio, nella figura seguente, il primo SELECT restituisce i record in ordine non ordinato poiché non esiste un indice cluster. Anche se esiste già un indice non cluster, i record vengono selezionati dall'area dell'heap in cui i record non sono ordinati.
Il secondo SELECT restituisce i record ordinati per colonna "id" poiché è stato raggruppato utilizzando l'indice contenente la colonna "id".
Il terzo SELECT restituisce i record parziali in ordine ma i record appena inseriti non vengono ordinati. Il quarto SELECT restituisce nuovamente tutti i record in ordine poiché la tabella è stata nuovamente raggruppata
 Comando del cluster PostgreSQL
Comando del cluster PostgreSQL Tipo di indice
PostgreSQL fornisce diversi tipi di indici come di seguito:
- B-Albero
- Hash
- GiST
- GIN
- BRIN
Ogni tipo di indice implementa diversi tipi di struttura dei dati sottostante, che è più adatta per diversi tipi di query. Per impostazione predefinita viene creato l'indice B-Tree, che è un indice ampiamente utilizzato. I dettagli di ciascun tipo di indice verranno trattati in un blog futuro.
Varie:Indice parziale ed espressione
Abbiamo discusso solo degli indici su una o più colonne di una tabella, ma ci sono altri due modi per creare indici su PostgreSQL
- Indice parziale: Indice parziale è un indice creato utilizzando il sottoinsieme di una colonna chiave per una tabella particolare. Il sottoinsieme è definito dall'espressione condizionale fornita durante la creazione dell'indice. Quindi, con l'indice parziale, viene salvato lo spazio di archiviazione per la memorizzazione dei dati dell'indice. Quindi l'utente dovrebbe scegliere la condizione in modo tale che quelli non siano valori molto comuni, poiché per valori più frequenti (comuni) comunque non verrà scelta la scansione dell'indice. Il resto della funzionalità rimane la stessa di un indice normale. Esempio:indice parziale
- Indice di espressione: Gli indici di espressione offrono un altro tipo di flessibilità in PostgreSQL. Tutti gli indici discussi fino ad ora, inclusi gli indici parziali, sono su un particolare insieme di colonne. Ma cosa succede se una query prevede l'accesso a una tabella in base all'espressione (espressione che coinvolge una o più colonne), senza un indice di espressione non sceglierà la scansione dell'indice. Quindi, per accedere rapidamente a questo tipo di query, PostgreSQL consente di creare un indice su un'espressione. Il resto della funzionalità rimane la stessa di un indice normale.
 Esempio:indice di espressione
Esempio:indice di espressione
Archiviazione dell'indice in InnoDB
L'utilizzo e la funzionalità di Index sono per lo più gli stessi di PostgreSQL con una grande differenza in termini di Clustered Index.
InnoDB supporta due categorie di indici:
- Indice cluster
- Indice secondario
Indice cluster
Clustered Index è un tipo speciale di indice in InnoDB. Qui i dati indicizzati non vengono archiviati separatamente, ma fanno parte dell'intera riga di dati. In altre parole, l'indice cluster forza semplicemente l'ordinamento fisico dei dati della tabella utilizzando la colonna chiave dell'indice. Può essere considerato come “Dizionario”, dove i dati sono ordinati in base all'alfabeto.
Poiché l'indice cluster ordina le righe utilizzando una chiave di indice, può esserci un solo indice cluster. Inoltre, deve esserci un indice cluster poiché InnoDB lo utilizza per manipolare in modo ottimale i dati durante varie operazioni sui dati.
Gli indici raggruppati vengono creati automaticamente (come parte della creazione della tabella) utilizzando una delle colonne della tabella secondo la priorità seguente:
- Utilizzo della chiave primaria se la chiave primaria è menzionata come parte della creazione della tabella.
- Sceglie qualsiasi colonna univoca in cui tutte le colonne chiave NON sono NULL.
- Altrimenti genera internamente un indice cluster nascosto su una colonna di sistema che contiene l'ID riga di ogni riga.
A differenza dell'indice non cluster di PostgreSQL, InnoDB accede a una riga utilizzando l'indice cluster più velocemente perché la ricerca dell'indice porta direttamente alla pagina con tutti i dati della riga e quindi evita I/O casuali.
Anche ottenere i dati della tabella in ordine utilizzando l'indice cluster è molto veloce poiché tutti i dati sono già ordinati e sono disponibili anche dati interi.
Indice secondario
L'indice creato in modo esplicito in InnoDB è considerato un indice secondario, che è simile all'indice non cluster di PostgreSQL. Ogni record nell'archivio dell'indice secondario contiene colonne di chiave primaria delle righe (che sono state utilizzate per creare l'indice cluster) e anche le colonne specificate per creare un indice secondario.
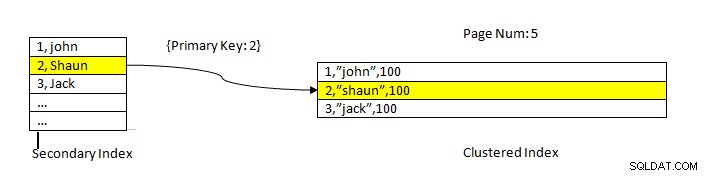 InnoDB:lettura dei dati utilizzando l'indice
InnoDB:lettura dei dati utilizzando l'indice Il recupero dei dati utilizzando un indice secondario è simile a quello di PostgreSQL, tranne per il fatto che la ricerca nell'indice secondario InnoDB fornisce una chiave primaria come puntatore per recuperare i dati rimanenti dall'indice cluster.
Ad esempio, come mostrato nell'immagine sopra, l'indice raggruppato si trova nella colonna ID, quindi i dati della tabella sono ordinati allo stesso modo. L'indice secondario si trova nella colonna "nome ”, quindi come possiamo vedere l'indice secondario ha sia ID che name. Dopo aver cercato utilizzando l'indice secondario, trova lo slot appropriato con il valore chiave corrispondente. Quindi la chiave primaria corrispondente viene utilizzata per fare riferimento alla parte rimanente dei dati dall'indice cluster.
MVCC per Indice
L'indice cluster MVCC utilizza il tradizionale modello di annullamento InnoDB (in realtà lo stesso dell'MVCC di dati interi, poiché l'indice cluster non è altro che dati interi).
Ma l'indice MVCC secondario utilizza un approccio leggermente diverso per mantenere MVCC. All'aggiornamento dell'indice secondario, la vecchia voce dell'indice viene contrassegnata come eliminazione e i nuovi record vengono inseriti nella stessa memoria, ovvero UPDATE non è presente. Infine, le vecchie voci dell'indice vengono eliminate. A questo punto potresti aver notato che l'indice secondario InnoDB MVCC è quasi uguale a quello del modello MVCC di PostgreSQL.
Tipo di indice
InnoDB supporta solo il tipo di indice B-Tree e quindi non è necessario specificare durante la creazione dell'indice.
Varie:indici hash adattivi
Come accennato nella sezione precedente, solo l'indice di tipo B-Tree è supportato da InnoDB ma c'è una svolta. InnoDB ha la funzionalità per rilevare automaticamente se la query può trarre vantaggio dalla creazione di un indice hash e anche interi dati della tabella possono essere inseriti nella memoria, quindi lo fa automaticamente.
L'indice hash viene creato utilizzando l'indice B-Tree esistente a seconda della query. Se sono presenti più indici B-Tree secondari, sceglierà quello che si qualifica secondo la query. L'indice hash creato non è completo, crea solo un indice parziale secondo il modello di utilizzo dei dati.
Questa è una delle funzionalità davvero potenti per migliorare dinamicamente le prestazioni delle query.
Conclusione
L'uso di qualsiasi indice in qualsiasi database è davvero utile per migliorare le prestazioni di READ ma allo stesso tempo degrada le prestazioni di INSERT/UPDATE poiché ha bisogno di scrivere dati aggiuntivi. Quindi l'indice dovrebbe essere scelto molto saggiamente e dovrebbe essere creato solo se le chiavi dell'indice vengono utilizzate come predicato per recuperare i dati.
InnoDB fornisce un'ottima funzionalità in termini di indice cluster, che potrebbe essere molto utile a seconda dei casi d'uso. Inoltre, la sua indicizzazione hash adattiva è molto potente.
Considerando che PostgreSQL fornisce vari tipi di indici, che possono davvero offrire opzioni di copertura delle funzionalità e uno o tutti possono essere utilizzati a seconda del caso d'uso aziendale. Anche gli indici parziali e di espressione sono abbastanza utili a seconda del caso d'uso.